







文章目录
1.Linux CGroup
(1)为什么需要 CGroup
Linux Namespace 为容器(进程)提供了环境上的隔离,它的行为类似 chroot 这个命令,将某个用户jail 到一个特定的环境下,与外界隔离。但是在之前介绍 Namespace 的文章中我们也提到过,虽然 Namespace 提供的隔离机制有很多,但实际上我们操作的一些资源仍然是全局的,并且基本上是没有什么限制的,如:内存,CPU,硬盘等。一些在已经「隔离」了的进程中做的操作还是会影响到其他进程的。
所以,Linux 在内核中以文件系统的形式为我们实现了一种资源隔离的机制:Linux CGroup,位于 /sys/fs/cgroup 目录 。它用来限制,控制一个进程群组的资源。
- 工作方式类似于:先对计算机的某个资源设置了一些限制规则,如只能使用 CPU 的20%。然后,如果我们想一些进程去遵守这个使用 CPU 资源的限制的话,就将它加入到这个规则所绑定的进程组中,之后,相应的限制就会对其生效。
总的来说,使用 CGroup,可以以控制组为单位,对其使用的操作系统的资源做更精细的控制。
先来看下 cgroup 的文件系统下都提供了对那些资源的隔离:
xr@xr-lab:/sys/fs/cgroup$ ll
total 0
drwxr-xr-x 15 root root 380 10月 24 14:35 ./
drwxr-xr-x 11 root root 0 10月 24 19:33 ../
dr-xr-xr-x 4 root root 0 10月 24 19:33 blkio/
lrwxrwxrwx 1 root root 11 10月 24 14:35 cpu -> cpu,cpuacct/
lrwxrwxrwx 1 root root 11 10月 24 14:35 cpuacct -> cpu,cpuacct/
dr-xr-xr-x 5 root root 0 10月 24 19:39 cpu,cpuacct/
dr-xr-xr-x 2 root root 0 10月 24 19:33 cpuset/
dr-xr-xr-x 4 root root 0 10月 24 19:33 devices/
dr-xr-xr-x 2 root root 0 10月 24 19:33 freezer/
dr-xr-xr-x 2 root root 0 10月 24 19:33 hugetlb/
dr-xr-xr-x 4 root root 0 10月 24 19:33 memory/
lrwxrwxrwx 1 root root 16 10月 24 14:35 net_cls -> net_cls,net_prio/
dr-xr-xr-x 2 root root 0 10月 24 19:33 net_cls,net_prio/
lrwxrwxrwx 1 root root 16 10月 24 14:35 net_prio -> net_cls,net_prio/
dr-xr-xr-x 2 root root 0 10月 24 19:33 perf_event/
dr-xr-xr-x 4 root root 0 10月 24 19:33 pids/
dr-xr-xr-x 2 root root 0 10月 24 19:33 rdma/
dr-xr-xr-x 5 root root 0 10月 24 19:33 systemd/
dr-xr-xr-x 5 root root 0 10月 24 19:33 unified/
其中 cpu 和 memory 我们都是比较熟悉的,而 blkio 代表了用于 I/O 的块设备,姑且可以将它当做是硬盘资源吧。
例子:
假设我们现在有一个核心逻辑为「死循环」的程序:
int main(void)
{
int i = 0;
for(;;) i++;
return 0;
}
启动了该程序后,可以通过 top命令看到其 CPU 占用率已经到达了100%
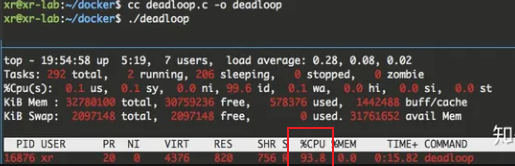
改进:使用CGroup显示其CPU
- 父进程启动后且创建子进程之前在 /sys/fs/cgroup/cpu 目录下再新建一个目录,作为一个我们自定义的进程组。
- 并且对这个进程组使用的 CPU 资源写入一个限制规则:只能使用 CPU 的50%
创建一个子进程并将其加入到我们已经创建好的进程组中,然后执行「死循环」逻辑
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#include <stdlib.h>
#define STACK_SIZE (1024 * 1024)
int pipefd[2];
static char container_stack[STACK_SIZE];
int container_main(void* arg)
{
char ch;
int i = 0;
close(pipefd[1]);
read(pipefd[0], &ch, 1);
printf("start\n");
for(;;)i++;
return 1;
}
int main()
{
printf("Parent - start a container!\n");
/* 设置CPU利用率为50% */
mkdir("/sys/fs/cgroup/cpu/deadloop", 755);
system("echo 50000 > /sys/fs/cgroup/cpu/deadloop/cpu.cfs_quota_us");
pipe(pipefd);
/* 调用clone函数,其中传出一个函数,还有一个栈空间的(为什么传尾指针,因为栈是反着的) */
int container_pid = clone(container_main, container_stack+STACK_SIZE, SIGCHLD ,NULL);
char cmd[128];
sprintf(cmd, "echo %d >> /sys/fs/cgroup/cpu/deadloop/tasks",container_pid);
system(cmd);
//向管道写入EOF
close(pipefd[1]);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
在上面的例子中,我使用了一个 pipe 做父子进程间的同步,确保父进程把子进程 id 写入到名为 deadloop 的进程组之后再唤醒子进程执行死循环的逻辑。编译执行后,可以通过 top 命令看到,子进程的 CPU 利用率已经被限制到了50%。(使用sudo或者root用户进行运行)
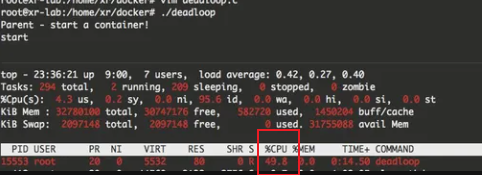
除了对 CPU 限制之外,对 MEM,硬盘容量都可以做限制,甚至对某个块设备的读写速率也是可以限制的。
(2)重要概念
子系统
在 CGroup 中,有很多子系统。一个子系统就代表一个资源控制器。sys/fs/cgroup 目录下的项目就是目前操作系统提供的全部子系统。
控制组 (Control Group)
一个控制组包含多个进程,而资源的限制也是定义在控制组上的。若一个进程加入到某一个控制组,则自动会受到定义在这个控制组上面的限制规则的影响。
层级
一个子系统下面的控制组,可以进行嵌套,最终形成一个树形的结构。子节点控制组会继承父节点控制组上对于资源的限制规则。若在子节点的控制组重定义了和父节点中相同资源的规则,则会发生覆盖(子覆盖父)
(3)基本概念
Cgroup 是 Linux kernel 的一项功能:它是在一个系统中运行的层级制进程组,你可对其进行资源分配(如 CPU 时间、系统内存、网络带宽或者这些资源的组合)。
- 通过使用 cgroup,系统管理员在分配、排序、拒绝、管理和监控系统资源等方面,可以进行精细化控制。硬件资源可以在应用程序和用户间智能分配,从而增加整体效率。
cgroup 和 namespace 类似,也是将进程进行分组,但它的目的和 namespace 不一样
- namespace 是为了隔离进程组之间的资源
- cgroup 是为了对一组进程进行统一的资源监控和限制。
cgroup 分 v1 和 v2 两个版本
- v1 实现较早,功能比较多,但是它里面的功能都是零散的,不太方便使用和维护
- 在最新的 4.5 内核中,cgroup v2 声称已经可以用于生产环境了,但它所支持的功能还很有限,随着 v2 一起引入内核的还有 cgroup namespace。
为什么需要 cgroup
- 在 Linux 里,一直以来就有对进程进行分组的概念和需求,比如 session group, progress group 等,后来随着人们对这方面的需求越来越多,比如需要追踪一组进程的内存和 IO 使用情况等,于是出现了 cgroup,用来统一将进程进行分组,并在分组的基础上对进程进行监控和资源控制管理等。
什么是 cgroup
- 术语 cgroup 在不同的上下文中代表不同的意思,可以指整个 Linux 的 cgroup 技术,也可以指一个具体进程组。
- cgroup 是 Linux 下的一种将进程按组进行管理的机制,在用户层看来,cgroup 技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个 subsystem 关联,树的作用是将进程分组,而 subsystem 的作用就是对这些组进行操作。
- cgroup 主要包括下面两部分:
(1)subsystem :
一个 subsystem 就是一个内核模块,他被关联到一颗cgroup树之后,就会在树的每个节点(进程组)上做具体的操作。
subsystem 经常被称作 resource controller,因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如 perf_event subsystem。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU 的使用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等
(2)hierarchy :
一个 hierarchy 可以理解为一棵 cgroup 树,树的每个节点就是一个进程组,每棵树都会与零到多个 subsystem 关联。
在一颗树里面,会包含 Linux 系统中的所有进程,但每个进程只能属于一个节点(进程组)。
系统中可以有很多颗 cgroup 树,每棵树都和不同的 subsystem 关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,只是这些进程组和不同的 subsystem 关联。
目前 Linux 支持 12 种 subsystem,如果不考虑不与任何 subsystem 关联的情况(systemd 就属于这种情况),Linux 里面最多可以建 12 颗 cgroup 树,每棵树关联一个 subsystem,当然也可以只建一棵树,然后让这棵树关联所有的 subsystem。
当一颗 cgroup 树不和任何 subsystem 关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定,systemd 就是一个这样的例子。
将资源看作一块饼
- 在 CentOS 7 系统中,通过将 cgroup 层级系统与 systemd单位树捆绑,可以把资源管理设置从进程级别移至应用程序级别。
- 默认情况下,systemd 会自动创建 slice、scope 和 service 单位的层级,来为 cgroup 树提供统一结构。
- 可以通过 systemctl 命令创建自定义 slice 进一步修改此结构。
如果我们将系统的资源看成一块馅饼,那么所有资源默认会被划分为3 个 cgroup:System, User 和 Machine。
- 每一个 cgroup 都是一个 slice,每个 slice 都可以有自己的子 slice
- 如下图所示:
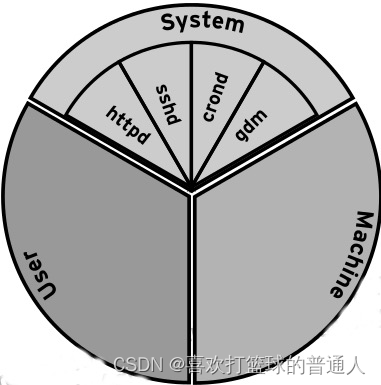
下面我们以 CPU 资源为例,来解释一下上图中出现的一些关键词。
- 如上图所示,系统默认创建了 3 个顶级 slice(每个slice将资源划分为3个cgroup:System, User 和 Machine,所以三种不同的slice)
- 每个 slice 都会获得相同的 CPU 使用时间(仅在 CPU 繁忙时生效),如果 user.slice 想获得 100% 的 CPU 使用时间,而此时 CPU 比较空闲,那么 user.slice 就能够如愿以偿。
- 这三种顶级 slice 的含义如下:
system.slice —— 所有系统 service 的默认位置
user.slice —— 所有用户会话的默认位置。
每个用户会话都会在该 slice 下面创建一个子 slice,如果同一个用户多次登录该系统,仍然会使用相同的子 slice。
machine.slice —— 所有虚拟机和 Linux 容器的默认位置
控制 CPU 资源使用的其中一种方法是 shares。
- shares 用来设置 CPU 的相对值(你可以理解为权重),并且是针对所有的 CPU(内核),默认值是 1024。
- 因此在上图中,httpd, sshd, crond 和 gdm 的 CPU shares 均为 1024,System, User 和 Machine 的 CPU shares 也是 1024。
假设该系统上运行了 4 个 service,登录了两个用户,还运行了一个虚拟机。同时假设每个进程都要求使用尽可能多的 CPU 资源(每个进程都很繁忙)。
system.slice 会获得 33.333% 的 CPU 使用时间,其中每个 service 都会从 system.slice 分配的资源中获得 1/4 的
CPU 使用时间,即 8.25% 的 CPU 使用时间。
user.slice 会获得 33.333% 的 CPU 使用时间,其中每个登录的用户都会获得 16.5% 的 CPU 使用时间。
假设有两个用户:tom 和 jack,如果 tom 注销登录或者杀死该用户会话下的所有进程,jack 就能够使用 33.333% 的 CPU 使用时间。
machine.slice 会获得 33.333% 的 CPU 使用时间,
如果虚拟机被关闭或处于 idle 状态,那么 system.slice 和 user.slice 就会从这 33.333% 的 CPU 资源里分别获得 50% 的 CPU 资源,然后均分给它们的子 slice。
如果想严格控制 CPU 资源,设置 CPU 资源的使用上限,即不管 CPU 是否繁忙,对 CPU 资源的使用都不能超过这个上限。
- 可以通过以下两个参数来设置:
cpu.cfs_period_us = 统计CPU使用时间的周期,单位是微秒(us)
cpu.cfs_quota_us = 周期内允许占用的CPU时间(指单核的时间,多核则需要在设置时累加)
systemctl 可以通过 CPUQuota 参数来设置 CPU 资源的使用上限。例如,如果你想将用户 tom 的 CPU 资源使用上限设置为 20%,
- 可以执行以下命令:
systemctl set-property user-1000.slice CPUQuota=20%
在使用命令 systemctl set-property 时,可以使用 tab 补全:
systemctl set-property user-1000.slice
AccuracySec= CPUAccounting= Environment= LimitCPU= LimitNICE= LimitSIGPENDING= SendSIGKILL=
BlockIOAccounting= CPUQuota= Group= LimitDATA= LimitNOFILE= LimitSTACK= User=
BlockIODeviceWeight= CPUShares= KillMode= LimitFSIZE= LimitNPROC= MemoryAccounting= WakeSystem=
BlockIOReadBandwidth= DefaultDependencies= KillSignal= LimitLOCKS= LimitRSS= MemoryLimit=
BlockIOWeight= DeviceAllow= LimitAS= LimitMEMLOCK= LimitRTPRIO= Nice=
BlockIOWriteBandwidth= DevicePolicy= LimitCORE= LimitMSGQUEUE= LimitRTTIME= SendSIGHUP=
这里有很多属性可以设置,但并不是所有的属性都是用来设置 cgroup 的,我们只需要关注 Block, CPU 和 Memory。
如果你想通过配置文件来设置 cgroup
- service 可以直接在 /etc/systemd/system/xxx.service.d 目录下面创建相应的配置文件
- slice 可以直接在 /run/systemd/system/xxx.slice.d 目录下面创建相应的配置文件。
- 事实上通过 systemctl 命令行工具设置 cgroup 也会写到该目录下的配置文件中:
cat /run/systemd/system/user-1000.slice.d/50-CPUQuota.conf
[Slice]
CPUQuota=20%
- 查看对应的 cgroup 参数:
cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user-1000.slice/cpu.cfs_period_us
100000
cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user-1000.slice/cpu.cfs_quota_us
20000
这表示用户 tom 在一个使用周期内(100 毫秒)可以使用 20 毫秒的 CPU 时间。
不管 CPU 是否空闲,该用户使用的 CPU 资源都不会超过这个限制。
- CPUQuota 的值可以超过 100%,例如:如果系统的 CPU 是多核,且 CPUQuota 的值为 200%,那么该 slice 就能够使用 2 核的 CPU 时间。
2.Linux CGroup之CPU
查看当前 cgroup 信息
有两种方法来查看系统的当前 cgroup 信息。
- 第一种方法是通过 systemd-cgls 命令来查看,它会返回系统的整体 cgroup 层级,cgroup 树的最高层由 slice 构成,如下所示:
systemd-cgls 命令提供的只是 cgroup 层级的静态信息快照
systemd-cgls --no-page
├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
├─user.slice
│ ├─user-1000.slice
│ │ └─session-11.scope
│ │ ├─9507 sshd: tom [priv]
│ │ ├─9509 sshd: tom@pts/3
│ │ └─9510 -bash
│ └─user-0.slice
│ └─session-1.scope
│ ├─ 6239 sshd: root@pts/0
│ ├─ 6241 -zsh
│ └─11537 systemd-cgls --no-page
└─system.slice
├─rsyslog.service
│ └─5831 /usr/sbin/rsyslogd -n
├─sshd.service
│ └─5828 /usr/sbin/sshd -D
├─tuned.service
│ └─5827 /usr/bin/python2 -Es /usr/sbin/tuned -l -P
├─crond.service
│ └─5546 /usr/sbin/crond -n
-
可以看到系统 cgroup 层级的最高层由 user.slice 和 system.slice 组成。因为系统中没有运行虚拟机和容器,所以没有 machine.slice,所以当 CPU 繁忙时,user.slice 和 system.slice 会各获得 50% 的 CPU 使用时间。
-
user.slice 下面有两个子 slice:user-1000.slice 和 user-0.slice,每个子 slice 都用 User ID (UID) 来命名,因此我们很容易识别出哪个 slice 属于哪个用户。
例如:从上面的输出信息中可以看出 user-1000.slice 属于用户 tom,user-0.slice 属于用户 root -
第二种方法
查看 cgroup 层级的动态信息,可以通过 systemd-cgtop 命令查看:
systemd-cgtop
Path Tasks %CPU Memory Input/s Output/s
/ 161 1.2 161.0M - -
/system.slice - 0.1 - - -
systemd-cgtop 提供的统计数据和控制选项与 top 命令类似,但该命令只显示那些开启了资源统计功能的 service 和 slice。
- 比如:如果你想开启 sshd.service 的资源统计功能,可以进行如下操作:
systemctl set-property sshd.service CPUAccounting=true MemoryAccounting=true
- 该命令会在 /etc/systemd/system/sshd.service.d/ 目录下创建相应的配置文件:
ll /etc/systemd/system/sshd.service.d/
总用量 8
4 -rw-r--r-- 1 root root 28 5月 31 02:24 50-CPUAccounting.conf
4 -rw-r--r-- 1 root root 31 5月 31 02:24 50-MemoryAccounting.conf
cat /etc/systemd/system/sshd.service.d/50-CPUAccounting.conf
[Service]
CPUAccounting=yes
cat /etc/systemd/system/sshd.service.d/50-MemoryAccounting.conf
[Service]
MemoryAccounting=yes
- 这时再重新运行 systemd-cgtop 命令,就能看到 sshd 的资源使用统计了:

- 开启资源使用量统计功能可能会增加系统的负载,因为资源统计也要消耗 CPU 和内存,大多数情况下使用 top 命令来查看就足够了。
(1)分配 CPU 相对使用时间,以单核为例(多核不同)
- eg:测试对象是 1 个 service 和两个普通用户,其中用户 tom 的 UID 是 1000,可以通过以下命令查看:
$ cat /etc/passwd|grep tom
tom❌1000:1000::/home/tom:/bin/bash
或者
id tom
- 创建一个 foo.service
通过systemd-cgls --no-pager命令可以看到,其在system.slice下
$ cat /etc/systemd/system/foo.service
[Unit]
Description=The foo service that does nothing useful
After=remote-fs.target nss-lookup.target
[Service]
ExecStart=/usr/bin/sha1sum /dev/zero
ExecStop=/bin/kill -WINCH ${MAINPID}
[Install]
WantedBy=multi-user.target
- /dev/zero 在 linux 系统中是一个特殊的设备文件,当你读它的时候,它会提供无限的空字符,因此 foo.service 会不断地消耗 CPU 资源。
- 现在我们将 foo.service 的 CPU shares 改为 2048
$ mkdir /etc/systemd/system/foo.service.d
$ cat << EOF > /etc/systemd/system/foo.service.d/50-CPUShares.conf
[Service]
CPUShares=2048
EOF
-
由于系统默认的 CPU shares 值为 1024,所以设置成 2048 后,在 CPU 繁忙的情况下,foo.service 会尽可能获取 system.slice 的所有 CPU 使用时间。
-
现在通过 systemctl start foo.service 启动 foo 服务,并使用 top 命令查看 CPU 使用情况
-
目前没有其他进程在消耗 CPU,所以 foo.service 可以使用几乎 100% 的 CPU。
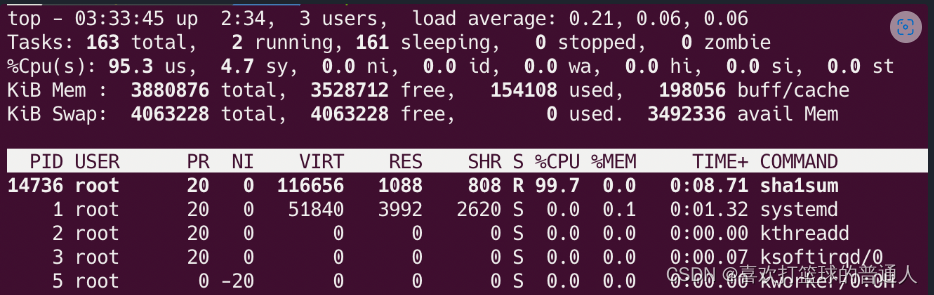
-
现在我们让用户 tom 也参与进来,先将 user-1000.slice 的 CPU shares 设置为 256:
$ systemctl set-property user-1000.slice CPUShares=256
使用用户 tom 登录该系统,然后执行命令 sha1sum /dev/zero,再次查看 CPU 使用情况
sha1sum /dev/zero
- 现在是不是感到有点迷惑了?
foo.service 的 CPU shares 是 2048,而用户 tom 的 CPU shares 只有 256,难道用户 tom 不是应该只能使用 10% 的 CPU 吗? - 回忆一下我在上一节提到的,当 CPU 繁忙时,user.slice 和 system.slice 会各获得 50% 的 CPU 使用时间。
而这里恰好就是这种场景,同时 user.slice 下面只有 sha1sum 进程比较繁忙,所以会获得 50% 的 CPU 使用时间。
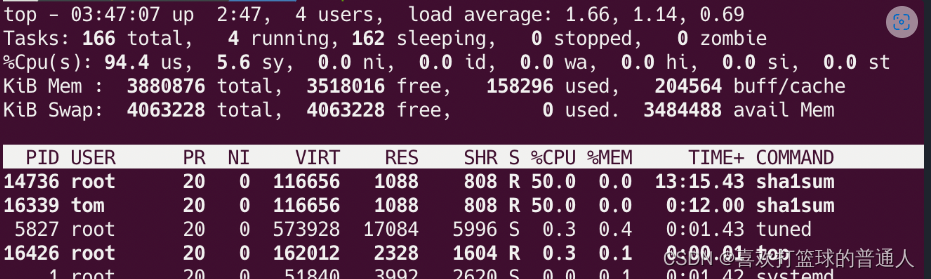
- 最后让用户 jack 也参与进来,他的 CPU shares 是默认值 1024。
使用用户 jack 登录该系统,然后执行命令 sha1sum /dev/zero,再次查看 CPU 使用情况:
- 上面我们已经提到,这种场景下 user.slice 和 system.slice 会各获得 50% 的 CPU 使用时间。
用户 tom 的 CPU shares 是 256,而用户 jack 的 CPU shares 是 1024,因此用户 jack 获得的 CPU 使用时间是用户 tom 的 4 倍
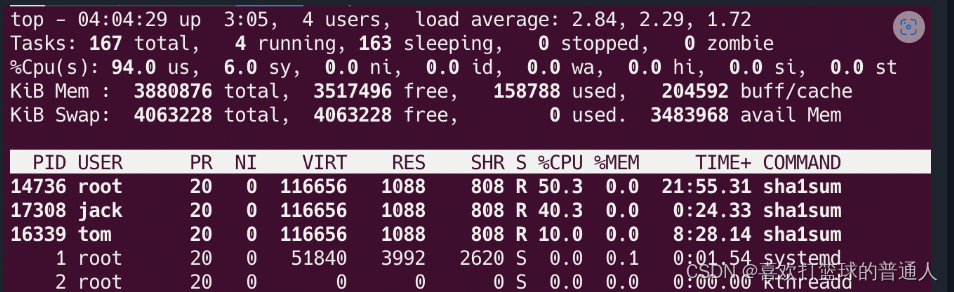
(2)分配 CPU 绝对使用时间
- 如果想严格控制 CPU 资源,设置 CPU 资源的使用上限,即不管 CPU 是否繁忙,对 CPU 资源的使用都不能超过这个上限,可以通过 CPUQuota 参数来设置。
- 下面我们将用户 tom 的 CPUQuota 设置为 5%:
systemctl set-property user-1000.slice CPUQuota=5%
- 这时你会看到用户 tom 的 sha1sum 进程只能获得 5% 左右的 CPU 使用时间。
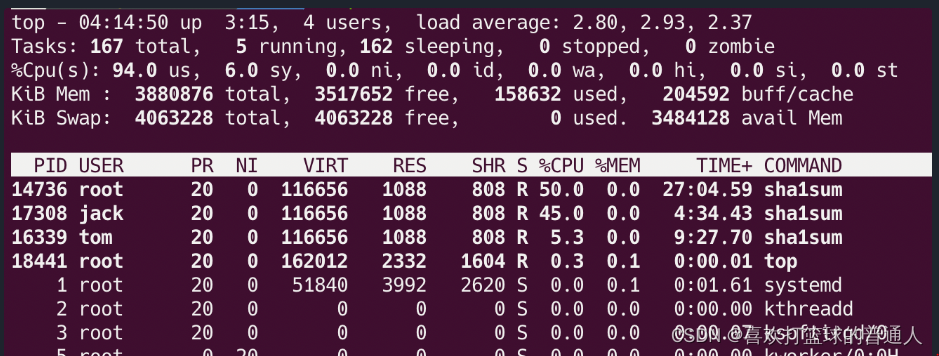
- 如果此时停止 foo.service,关闭用户 jack 的 sha1sum 进程,你会看到用户 tom 的 sha1sum 进程仍然只能获得 5% 左右的 CPU 使用时间。
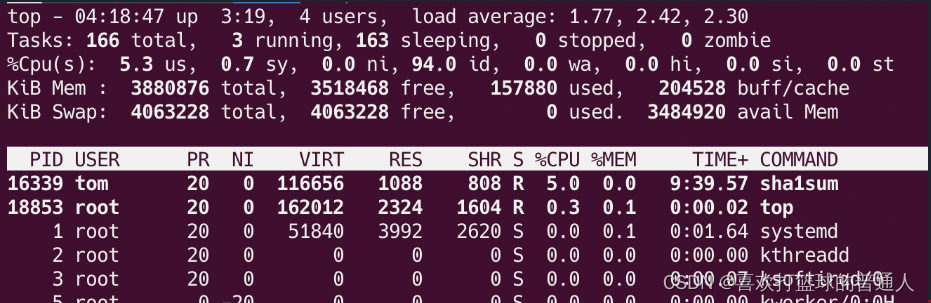
如果某个非核心服务很消耗 CPU 资源,你可以通过这种方法来严格限制它对 CPU 资源的使用,防止对系统中其他重要的服务产生影响。
动态设置 cgroup
- cgroup 相关的所有操作都是基于内核中的 cgroup virtual filesystem,使用 cgroup 很简单,挂载这个文件系统就可以了。
- 系统默认情况下都是挂载到 /sys/fs/cgroup 目录下,当 service 启动时,会将自己的 cgroup 挂载到这个目录下的子目录。
先进入 system.slice 的 CPU 子系统:
cd /sys/fs/cgroup/cpu,cpuacct/system.slice
查看 foo.service 的 cgroup 目录:
ls foo.*
zsh: no matches found: foo.*
因为 foo.service 没有启动,所以没有挂载 cgroup 目录,现在启动 foo.service(systemctl start foo.service),再次查看它的 cgroup 目录:
ls foo.serice
cgroup.clone_children cgroup.procs cpuacct.usage cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.event_control cpuacct.stat cpuacct.usage_percpu cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
也可以查看它的 PID 和 CPU shares:
cat foo.service/tasks
20225
cat foo.service/cpu.shares
2048
注意:
- 理论上我们可以在 /sys/fs/cgroup 目录中动态改变 cgroup 的配置,但我不建议你在生产环境中这么做。
- 如果你想通过实验来深入理解 cgroup,可以多折腾折腾这个目录。
(3)如果是多核 CPU 呢?
- 以 2 个 CPU 为例。
- 首先来说一下 CPU shares,
shares 只能针对单核 CPU 进行设置,也就是说,无论你的 shares 值有多大,该 cgroup 最多只能获得 100% 的 CPU 使用时间(即 1 核 CPU)。
将 foo.service 的 CPU shares 设置为 2048,启动 foo.service,这时你会看到 foo.service 仅仅获得了 100% 的 CPU 使用时间,并没有完全使用两个 CPU 核:
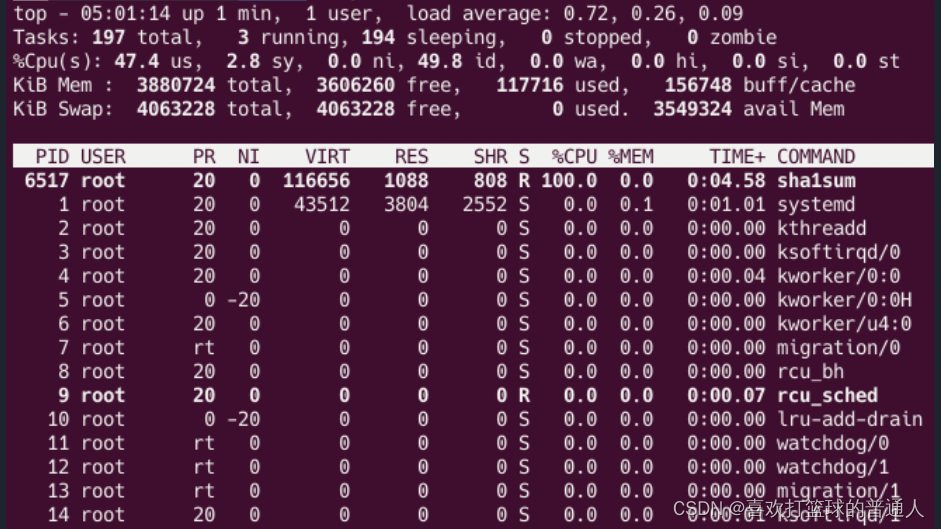
- 再使用用户 tom 登录系统,执行命令 sha1sum /dev/zero,你会发现用户 tom 的 sha1sum 进程和 foo.service 各使用 1 个 CPU 核:
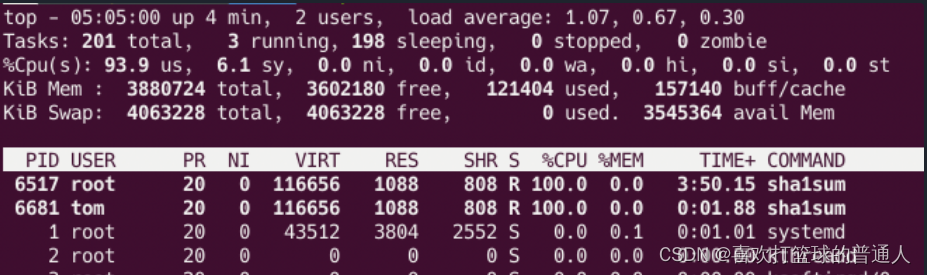
CPUQuota - 如要让一个 cgroup 完全使用两个 CPU 核,可以通过 CPUQuota 参数来设置。(测试发现,仅能配置一个核)
systemctl set-property foo.service CPUQuota=200%
3.Linux CGroup之内存
(1)默认开启的swap
CPU controller 提供了两种方法来限制 CPU 使用时间,其中 CPUShares 用来设置相对权重,CPUQuota 用来限制 user、service 或 VM 的 CPU 使用时间百分比。
- 例如:如果一个 user 同时设置了 CPUShares 和 CPUQuota,假设 CPUQuota 设置成 50%,那么在该 user 的 CPU 使用量达到 50% 之前,可以一直按照 CPUShares 的设置来使用 CPU。
对于内存而言,在 CentOS 7 中,systemd 已经帮我们将 memory 绑定到了 /sys/fs/cgroup/memory。
- systemd 只提供了一个参数 MemoryLimit 来对其进行控制,该参数表示某个 user 或 service 所能使用的物理内存总量。
- 拿之前的用户 tom 举例, 它的 UID 是 1000,可以通过以下命令来设置:
$ systemctl set-property user-1000.slice MemoryLimit=200M
现在使用用户 tom 登录该系统,通过 stress 命令产生 8 个子进程,每个进程分配 256M 内存:
$ stress --vm 8 --vm-bytes 256M
按照预想,stress 进程的内存使用量已经超出了限制,此时应该会触发 oom-killer,但实际上进程仍在运行,这是为什么呢?
我们来看一下目前占用的内存:
$ cd /sys/fs/cgroup/memory/user.slice/user-1000.slice
$ cat memory.usage_in_bytes
209661952
奇怪,占用的内存还不到 200M,剩下的内存都跑哪去了呢?
linux 系统中的内存使用除了包括物理内存,还包括交换分区,也就是 swap,我们来看看是不是 swap 搞的鬼。
先停止刚刚的 stress 进程,稍等 30 秒,观察一下 swap 空间的占用情况:
$ free -h
total used free shared buff/cache available
Mem: 3.7G 180M 3.2G 8.9M 318M 3.3G
Swap: 3.9G 512K 3.9G
重新运行 stress 进程:
$ stress --vm 8 --vm-bytes 256M
查看内存使用情况:
$ cat memory.usage_in_bytes
209637376
发现内存占用刚好在 200M 以内。
再看 swap 空间占用情况:
$ free
total used free shared buff/cache available
Mem: 3880876 407464 3145260 9164 328152 3220164
Swap: 4063228 2031360 2031868
和刚刚相比,多了 2031360-512=2030848k,现在基本上可以确定当进程的使用量达到限制时,内核会尝试将物理内存中的数据移动到 swap 空间中,从而让内存分配成功。
我们可以精确计算出 tom 用户使用的物理内存+交换空间总量,
首先需要分别查看 tom 用户的物理内存和交换空间使用量:
$ egrep "swap|rss" /sys/fs/cgroup/memory/user.slice/user-1000.slice/memory.stat
rss 209637376
rss_huge 0
swap 1938804736
total_rss 209637376
total_rss_huge 0
total_swap 1938804736
可以看到物理内存使用量为 209637376 字节,swap 空间使用量为 1938804736 字节,总量为 (209637376+1938804736)/1024/1024=2048 M。
stress 进程需要的内存总量为 256*8=2048 M,两者相等
这个时候如果你每隔几秒就查看一次 memory.failcnt 文件,就会发现这个文件里面的数值一直在增长:
cat /sys/fs/cgroup/memory/user.slice/user-1000.slice/memory.failcnt
59390293
结论:
- 从上面的结果可以看出,当物理内存不够时,就会触发 memory.failcnt 里面的数量加 1,但此时进程不一定会被杀死,内核会尽量将物理内存中的数据移动到 swap 空间中。
(3)关闭 swap
为了更好地观察 cgroup 对内存的控制,我们可以用户 tom 不使用 swap 空间,实现方法有以下几种:
- 方式1:将 memory.swappiness 文件的值修改为 0:
$ echo 0 > /sys/fs/cgroup/memory/user.slice/user-1000.slice/memory.swappiness
如果你既不想关闭系统的交换空间,又想让 tom 不使用 swap 空间,上面给出的方法是有问题的:
你只能在 tom 用户登录的时候修改 memory.swappiness 文件的值,因为如果 tom 用户没有登录,当前的 cgroup 就会消失。
即使你修改了 memory.swappiness 文件的值,也会在重新登录后失效
- 方式2:直接关闭系统的交换空间:
$ swapoff -a
- 如果想永久生效,还要注释掉 /etc/fstab 文件中的 swap。
方式3:Linux PAM( Pluggable Authentication Modules) 是一个系统级用户认证框架
PAM将程序开发与认证方式进行分离,程序在运行时调用附加的“认证”模块完成自己的工作。
- 本地系统管理员通过配置选择要使用哪些认证模块,其中 /etc/pam.d/ 目录专门用于存放 PAM 配置,用于为具体的应用程序设置独立的认证方式。
- 例如,在用户通过 ssh 登录时,将会加载 /etc/pam.d/sshd 里面的策略。
从 /etc/pam.d/sshd 入手,我们可以先创建一个 shell 脚本:
$ cat /usr/local/bin/tom-noswap.sh
#!/bin/bash
if [ $PAM_USER == 'tom' ]
then
echo 0 > /sys/fs/cgroup/memory/user.slice/user-1000.slice/memory.swappiness
fi
然后在 /etc/pam.d/sshd 中通过 pam_exec 调用该脚本,在 /etc/pam.d/sshd 的末尾添加一行,内容如下:
$ session optional pam_exec.so seteuid /usr/local/bin/tom-noswap.sh
现在再使用 tom 用户登录,就会发现 memory.swappiness 的值变成了 0。
注意:
- 这里需要注意一个前提:至少有一个用户 tom 的登录会话,且通过 systemctl set-property user-1000.slice MemoryLimit=200M 命令设置了 limit,/sys/fs/cgroup/memory/user.slice/user-1000.slice 目录才会存在。
- 所以上面的所有操作,一定要保证至少保留一个用户 tom 的登录会话。
(3)控制内存使用
关闭了 swap 之后,我们就可以严格控制进程的内存使用量了。
- 还是使用开头提到的例子,使用用户 tom 登录该系统,先在第一个 shell 窗口运行以下命令:
$ journalctl -f
- 打开第二个 shell 窗口(还是 tom 用户),通过 stress 命令产生 8 个子进程,每个进程分配 256M 内存:
$ stress --vm 8 --vm-bytes 256M
stress: info: [30150] dispatching hogs: 0 cpu, 0 io, 8 vm, 0 hdd
stress: FAIL: [30150] (415) <-- worker 30152 got signal 9
stress: WARN: [30150] (417) stress: FAIL: [30150] (415) <-- worker 30151 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (415) <-- worker 30154 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (415) <-- worker 30157 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (415) <-- worker 30158 got signal 9
stress: WARN: [30150] (417) now reaping child worker processes
stress: FAIL: [30150] (451) failed run completed in 0s
-
现在可以看到 stress 进程很快被 kill 掉了,回到第一个 shell 窗口,会输出以下信息:
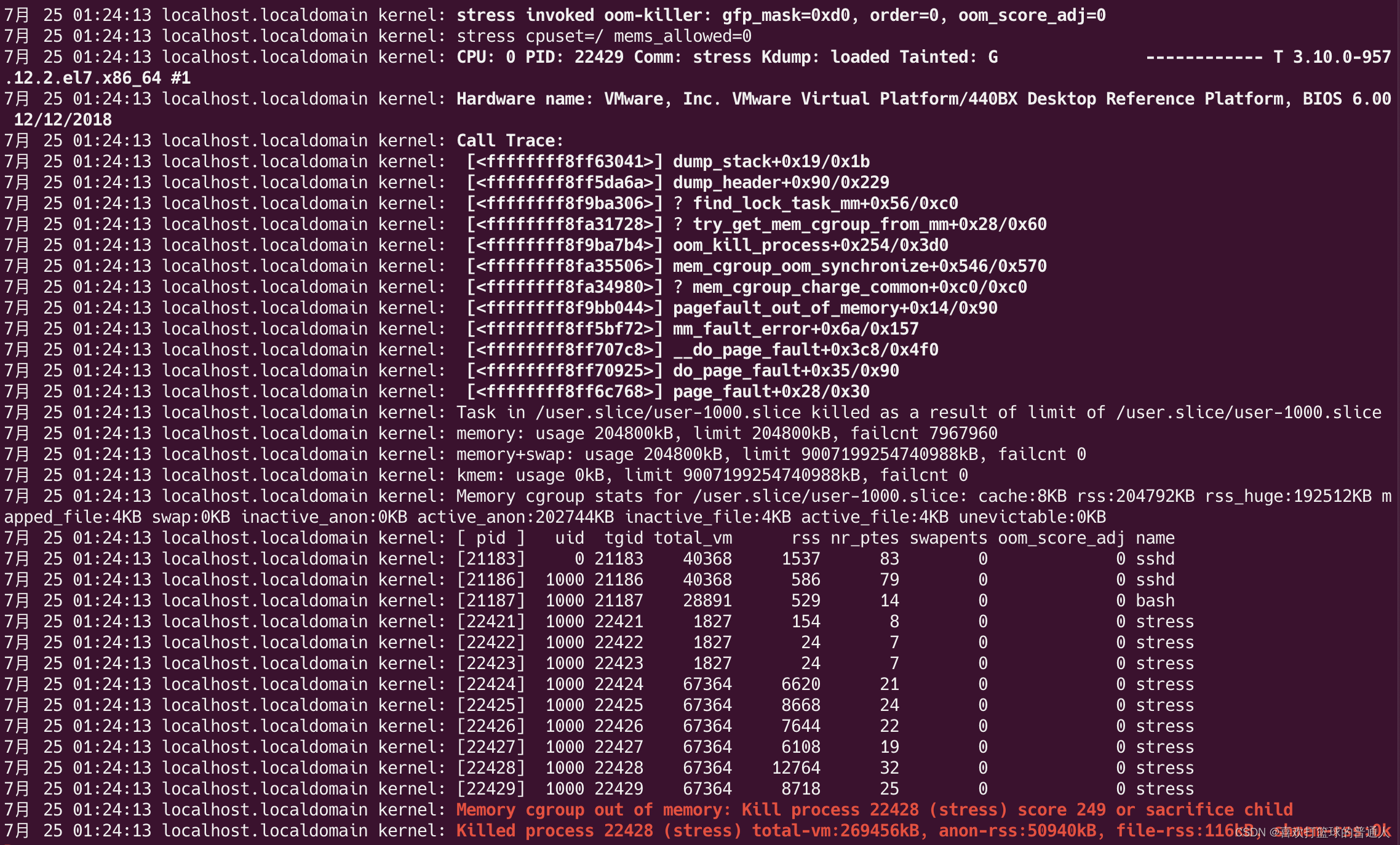
-
如果你想获取更多关于 cgroup 的文档,可以通过 yum 安装 kernel-doc 包。安装完成后,你就可以进入 /usr/share/docs 的子目录,查看每个 cgroup controller 的详细文档。
$ cd /usr/share/doc/kernel-doc-3.10.0/Documentation/cgroups
$ ll
总用量 172
4 -r--r--r-- 1 root root 918 6月 14 02:29 00-INDEX
16 -r--r--r-- 1 root root 16355 6月 14 02:29 blkio-controller.txt
28 -r--r--r-- 1 root root 27027 6月 14 02:29 cgroups.txt
4 -r--r--r-- 1 root root 1972 6月 14 02:29 cpuacct.txt
40 -r--r--r-- 1 root root 37225 6月 14 02:29 cpusets.txt
8 -r--r--r-- 1 root root 4370 6月 14 02:29 devices.txt
8 -r--r--r-- 1 root root 4908 6月 14 02:29 freezer-subsystem.txt
4 -r--r--r-- 1 root root 1714 6月 14 02:29 hugetlb.txt
16 -r--r--r-- 1 root root 14124 6月 14 02:29 memcg_test.txt
36 -r--r--r-- 1 root root 36415 6月 14 02:29 memory.txt
4 -r--r--r-- 1 root root 1267 6月 14 02:29 net_cls.txt
4 -r--r--r-- 1 root root 2513 6月 14 02:29 net_prio.txt


















 1400
1400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











