







使用tree命令查看hadoop的目录机构:tree -d -L 3 hadoop-3.1.2/
-d 表示查看的是文件夹
-L 表示查看深度
hadoop-3.1.2 具体查看那个目录
也可以用tree命令直接查看,但是由于hadoop目录太深且文件较多所以展开不太现实
然后我们就看一下hadoop的结构目录:

hadoop本地模式没有Hdfs功能没有Mapreduce功能,所以它修改特别方便
只需etc目录下的hadoop-env.sh中的:

默认export JAVA_HOME是被注释掉的,我们放开并把它附上我们之前配置好的java的全路径也行,配置它的环境变量也行
这里注意了,需要配置JAVA_HOME的全路径,它的环境变量不行我以为可以获取到,但是在我配置伪分布后启动的时候这里
就报错了
[root@bigdata111 ~]# start-all.sh
Starting namenodes on [bigdata111]
上一次登录:五 3月 20 12:45:07 CST 2020从 192.168.112.111pts/1 上
bigdata111: ERROR: JAVA_HOME is not set and could not be found.
Starting datanodes
上一次登录:五 3月 20 12:52:09 CST 2020pts/0 上
localhost: ERROR: JAVA_HOME is not set and could not be found.
Starting secondary namenodes [bigdata111]
上一次登录:五 3月 20 12:52:10 CST 2020pts/0 上
bigdata111: ERROR: JAVA_HOME is not set and could not be found.
Starting resourcemanager
上一次登录:五 3月 20 12:52:13 CST 2020pts/0 上
resourcemanager is running as process 12903. Stop it first.
Starting nodemanagers
上一次登录:五 3月 20 12:52:20 CST 2020pts/0 上
localhost: ERROR: JAVA_HOME is not set and could not be found.
然后我们测试一下这个hadoop,我们就是用hadoop提供的一个wordcount的mapreduce程序测试

首先准备一个文件在/root/temp/input/data.txt
文件内容:
I love Beijing
I love China
Beijing of the capital of china
我们先看一下这个目录中有哪些程序,使用hadoop jar hadoop-mapreduce-examples-3.1.2.jar

我们就是用图中那个wordcount的例子 ,执行如下命令
hadoop jar hadoop-mapreduce-examples-3.1.2.jar wordcount /root/temp/input/ /root/temp/output/wc
/root/temp/input/ :表示输入程序的位置,可以是文件夹,也可以是具体某个文件,如果是文件夹的或那表示这个文件夹下的所有文件
/root/temp/ountput/wc :表示计算结果输出目录,最后一级不能事先存在
如果存在了他会把一个错误

如果正常执行那么就在你的输出文件夹生成俩个文件,
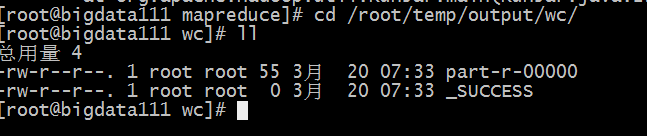
—SUCCESS 是一个状态文件表示成功
part-r-00000就是计算结果文件
最后我们查看这个文件会得到如下结果,说明你就搭建完成了,不过本地默认一般没有什么作用


















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











