






VCED项目实战1
介绍
VCED(Video Clip Extraction by description)VCED 可以通过你的文字描述来自动识别视频中相符合的片段进行视频剪辑。该项目基于跨模态搜索与向量检索技术搭建,通过前后端分离的模式,帮助你快速的接触新一代搜索技术。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tzGXsVd9-1668350681121)(https://github.com/datawhalechina/vced/raw/main/pics/demo.gif)]
前期准备
-
本项目在WSL中搭建,需要预先配置WSL
-
创建虚拟环境
-
#cd project 项目路径 python -m venv venv # 启动虚拟环境 source ./venv/bin/activate
-
-
-
# rust curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -
# ffmpeg sudo apt install ffmpeg ffmpeg -version -
# jina pip install -U jina
-
-
安装clip
-
pip install git+https://github.com/openai/CLIP.git
-
-
clone项目
-
git clone https://github.com/datawhalechina/vced.git
-
启动sever
# 进入 server 文件夹
cd code/service
# 安装相关依赖
pip install -r requirements.txt
# 启动服务端
python app.py
启动后会有如下画面
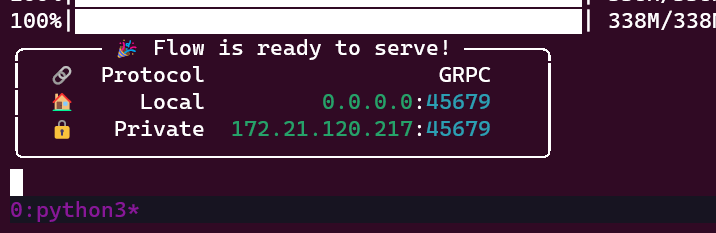
启动 web
前端我们通过 Streamlit 搭建。Streamlit 是一个 Python Web 应用框架,但和常规 Web 框架,如 Flask/Django 的不同之处在于,它不需要你去编写任何客户端代码(HTML/CSS/JS),只需要编写普通的 Python 模块,就可以在很短的时间内创建美观并具备高度交互性的界面。
# 进入 web 文件夹
cd code/web
# 安装相关依赖
pip install -r requirements.txt
# 启动服务端
streamlit run app.py
Streamlit默认启动的端口为8501,也可以通过 localhost:8501 进行访问
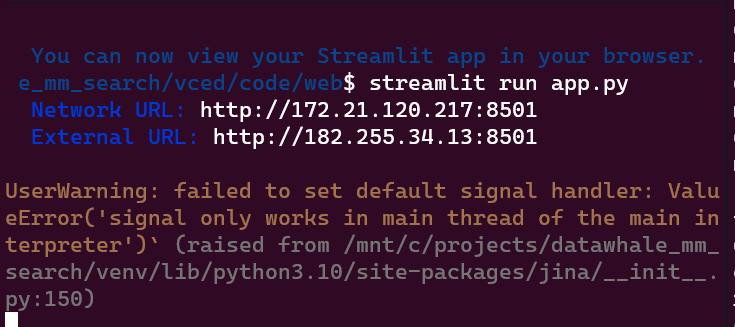
启动后在浏览器打开相应的url
项目结构
├── code/service
├── customClipImage (通过 CLIP 模型处理上传的视频)
├── customClipText (通过 CLIP 模型处理输入的文字)
├── customIndexer (创建向量数据的索引)
├── videoLoader (对上传的视频进行处理)
├── workspace (用于存储生成的向量数据)
├── app.py (后端主程序)
├── code/web
├── data (用于存储上传的视频)
│ ├── videos (用于存储简介好的视频片段)
├── app.py (前端主程序)
├── Dockerfile
├── requirements.txt















 745
745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









