







本文主要从vector的基础用法、vector作为函数返回值、vector作为函数参数三个方面进行介绍,有任何不当之处,欢迎指教。
一、vector基础用法
vector是C++标准模板库中的部分内容,它是一个多功能的,能够操作多种数据结构和算法的模板类和函数库。vector之所以被认为是一个容器,是因为它能够像容器一样存放各种类型的对象,简单地说,vector是一个能够存放任意类型的动态数组,能够增加和压缩数据。,使用时需包含头文件:
#include <vector>
vector属于std命名域的,因此需要通过命名限定,如下完成你的代码:
using std::vector;
vector<int> vInts;或者连在一起,使用全名:
std::vector<int> vInts;建议使用全局的命名域方式:
using namespace std;在后面的操作中全局的命名域方式会造成一些问题。vector容器提供了很多接口,在下面的表中列出vector的成员函数和操作,c为vector对象。
| 函数 | 表述 |
|---|---|
| c.assign(b.begin(), b.begin()+3) | b为向量,将b的0~2个元素构成的向量赋给c,即[beg; end)区间 |
| c.assign(n,elem) | 将n个elem的拷贝赋值给c |
| c.at(idx) | 传回索引idx所指的数据,如果idx越界,抛出out_of_range |
| c.back() | 传回最后一个数据,不检查这个数据是否存在 |
| c.front() | 返回c的第一个元素 |
| c[i] | 返回c的第i个元素,当且仅当c[i]存在 |
| c.clear() | 清空c中的元素 |
| c.empty() | 判断c是否为空,空则返回ture,不空则返回false |
| c.pop_back() | 删除c向量的最后一个元素 |
| c.erase(pos) | 删除pos位置的数据,传回下一个数据的位置 |
| c.erase(beg,end) | 删除[beg,end)区间的数据,传回下一个数据的位置 |
| c.push_back(5) | 在c的最后一个向量后插入一个元素,其值为5 |
| c.insert(pos,elem) | 在pos位置插入一个elem拷贝,传回新数据位置 |
| c.insert(pos,n,elem) | 在pos位置插入n个elem数据,无返回值 |
| c.insert(pos,b.begin(),b.end()) | 在pos位置插入在[beg,end)区间的数据,无返回值 |
| c.size() | 返回c中元素的个数 |
| c.capacity() | 返回c在内存中总共可以容纳的元素个数 |
| c.resize(10) | 将c的现有元素个数调至10个,多则删,少则补,其值随机 |
| c.resize(10,2) | 将c的现有元素个数调至10个,多则删,少则补,其值为2 |
| c.reserve(100) | 将c的容量(capacity)扩充至100,也就是说现在测试c.capacity();的时候返回值是100.这种操作只有在需要给c添加大量数据的时候才显得有意义,因为这将避免内存多次容量扩充操作(当c的容量不足时电脑会自动扩容,当然这必然降低性能) |
| c.swap(b) | b为向量,将c中的元素和b中的元素进行整体性交换 |
| swap(c,b) | 同上 |
| a==b | b为向量,向量的比较操作还有!=,>=,<=,>,< |
vector的初始化,可以有五种方式,举例如下:
(1)vector<Elem> c 创建一个空的vector
(2)vector <Elem> c(n) 创建一个vector,含有n个数据,数据均已缺省构造产生
(3)vector <Elem> c1(c2) 复制一个vector
(4)vector <Elem> c(n, elem) 创建一个含有n个elem值的vector
(5)vector <Elem> c(beg,end) 创建一个以[beg;end)区间的vector
(6)intb[7]={1,2,3,4,5,9,8};vector<int> a(b,b+7) 从数组中获得初值
vector的销毁,方法如下:
c.~ vector <Elem>() 销毁所有数据,释放内存
顺序访问vector的几种方式:
1、向向量a中添加元素
vector<int> a;
for(int i=0;i<10;i++)
a.push_back(i);2、从数组中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector<int> b;
for(int i=1;i<=4;i++)
b.push_back(a[i]);3、从现有向量中选择元素向向量中添加
itn a[6] = {1,2,3,4,5,6};
vector<int> b;
vector<int> c(a,a+4);
for(vector<int>::iterator it=c.begin();it<c.end();it++)
b.push_back(*it);4、从文件中读取元素向向量中添加
ifstream in("data.txt");
vector<int> a;
for(int i; in>>i)
a.push_back(i);5、易犯错误
vector<int> a;
for(int i=0;i<10;i++)
a[i]=i;
//这种做法以及类似的做法都是错误的。下标只能用于获取已存在的元素,而现在的a[i]还是空的对象从向量中读取元素
1、通过at()函数读取,at()进行了边界检查,如果访问超过了vector的范围,将抛出一个异常
vector<int> v;
v.reserve(10);
for(int i=0; i<7; i++)
v.push_back(i);
try
{
int iVal1 = v[7]; // not bounds checked - will not throw
int iVal2 = v.at(7); // bounds checked - will throw if out of range
}
catch(const exception& e)
{
cout << e.what();
}2、通过遍历器方式读取
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(vector<int>::iterator it=b.begin();it!=b.end();it++)
cout<<*it<<" ";3、通过下标方式读取,operator[]不会进行边界检查
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(int i=0;i<=b.size()-1;i++)
cout<<b[i]<<" ";类和结构体存vector入实例:由于vector只允许一个占位,所以才将struct塞进vector,以弥补vector的不足
#include "stdafx.h"
#include <vector>
#include <string>
using namespace std;
class AClass
{
public:
int num;
string name;
};
struct AStruct
{
int num;
string name;
};
void TestStruct()
{
//类的使用
AClass Ac;
vector<AClass> vc;
Ac.num=10;
Ac.name="name";
vc.push_back(Ac);
AClass d;
for (vector<AClass>::iterator it=vc.begin();it<vc.end();++it)
{
d=*it;
cout<<d.num<<endl;
}
//结构体的使用
AStruct As;
vector<AStruct> vs;
As.num=10;
As.name="name";
vs.push_back(As);
AStruct ds;
for (vector<AStruct>::iterator it=vs.begin();it<vs.end();++it)
{
ds=*it;
cout<<ds.num<<endl;
}
}
void TestPoint()
{
//类的使用
AClass *Ac=new AClass;
vector<AClass *> vc;
Ac->num=10;
Ac->name="name";
vc.push_back(Ac);
AClass *d;
for (vector<AClass*>::iterator it=vc.begin();it<vc.end();++it)
{
d=*it;
cout<<d->num<<endl;
}
}
int _tmain(int argc, _TCHAR* argv[])
{
TestStruct();
TestPoint();
int n;
cin>>n;
return 0;
}C++中将两个vector中的值整合到另一个vector中,vecB和vecA中有相同的struct个数,现在想将每个vecA中的每个a的值传给vecC中c1,每个vecB中的每个b的值传给vecC中c2,也就是将两个容器中的内容整合到新的容器C中
struct A
{
int a;
};
vector<A> vecA;
struct B
{
int b;
};
vector<B> vecB;
struct C
{
int c1;
int c2;
};
vector<C> vecC;容器C和A、B中元素类型不同,迭代器类型就不同,所以不能用容器算法,使用迭代器遍历赋值,合并代码如下:
第一种方法:
for(vecA::const_iterator itA = vecA.begin(), VecB::const_iterator itB = vecB.begin();
itA != vecA.end() && itB != vecB.end(); itA++, itB++){
C c;
c.c1 = (*itA).a;
c.c2 = (*itB).b;
vecC.push_back(c);
}第二种方法:
void MergeVector(vector<A> &vectorA,vector<B> &vectorB,vector<C> &vectorC)
{
vector<A>::iterator pva;
vector<B>::iterator pvb;
vector<C>::iterator pvc;
pva = vectorA.begin();
pvb = vectorB.begin();
pvc = vectorC.begin();
while(pva!=vectorA.end())
{
*pvc->c1 = *pva->a;
*pvc->c2 = *pvb->b;
pva++;
pvb++;
pvc++;
}
}建立两个int类型的向量vector,利用merge算法合并,再用sort算法对合并后算法排序
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> merge(vector<int> ,vector<int> );
int main()
{
vector<int> v1;
v1.push_back(4);
v1.push_back(6);
v1.push_back(2);
vector<int> v2;
v2.push_back(3);
v2.push_back(1);
v2.push_back(5);
vector<int> v3=merge(v1,v2);
sort(v3.begin(),v3.end());
for(vector<int>::iterator it=v3.begin();it!=v3.end();++it){
cout<<*it<<endl;
}
}
vector<int> merge(vector<int> v1,vector<int> v2)
{
v1.insert(v1.end(),v2.begin(),v2.end());
return v1;
}
压缩一个臃肿的vector
很多时候大量的删除数据,或者通过使用reserve(),结果vector的空间远远大于实际需要的。所有需要压缩vector到它实际的大小。resize()能够增加vector的大小。Clear()仅仅能够改变缓存的大小,所有的这些对于vector释放内存等九非常重要了。
我们可以通过一个vector创建另一个vector。让我们看看这将发生什么。假定我们已经有一个vector v,它的内存大小为1000,当我们调用size()的时候,它的大小仅为7。我们浪费了大量的内存。让我们在它的基础上创建一个vector。
std::vector<CString> vNew(v);
cout << vNew.capacity();vNew.capacity()返回的是7。这说明新创建的只是根据实际大小来分配的空间。现在我们不想释放v,因为我们要在其它地方用到它,我们可以使用swap()将v和vNew互相交换一下?
vNew.swap(v);
cout << vNew.capacity();
cout << v.capacity();有趣的是:vNew.capacity()是1000,而v.capacity()是7。
现在是达到我的目的了,但是并不是很好的解决方法,我们可以像下面这么写:
std::vector<CString>(v).swap(v);你可以看到我们做了什么?我们创建了一个临时变量代替那个命名的,然后使用swap(),这样我们就去掉了不必要的空间,得到实际大小的v。
二、vector作为函数返回值用法
在实际应用过程中,我们经常需要保存一系列的数据,有可能是一个值,点等,这时我们会用到vector。 有时候我们需要将vector作为一个函数的返回值,使用方法如下所示:
在被调用函数中声明一个vector变量,函数结束的时候返回vector变量。
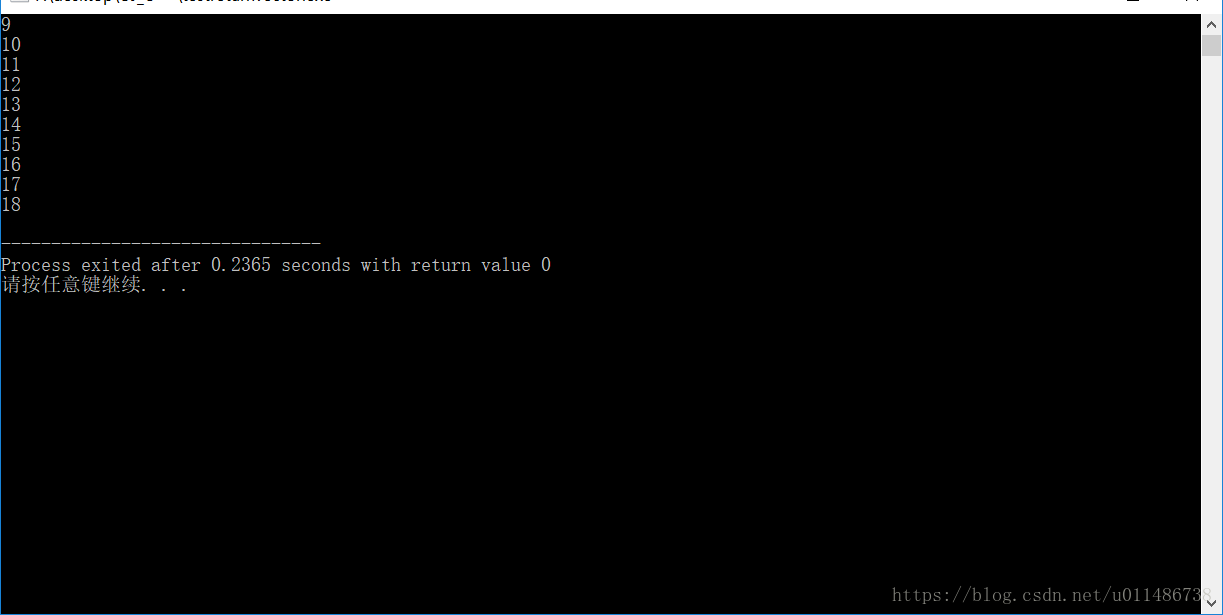
vector<int> getSequence(int num){
vector<int> sequence;
for(int i=0;i<10;i++){
sequence.push_back(i+num);
}
return sequence;
}
int main(){
int num=9;
vector<int> sequence;
//在主调函数这边,只传入num
sequence=getSequence(num);
//访问该vector的值的时候,也是直接访问即可
for(vector<int>::iterator it=sequence.begin();it!=sequence.end();it++){
cout<<*it<<endl;
}
}
三、使用vector的引用在函数间传递
下面是一个例子,假设我要传入一个数,我的函数的功能是返回这个数后面十个数的序列:
我们将函数返回值设定为bool类型,vector作为函数的参数,添加引用,保存数据
#include<iostream>
#include<vector>
using namespace std;
/*
输入一个数,返回这个数后面的十个数字序列
注意参数的这个 & 符号不能省略
*/
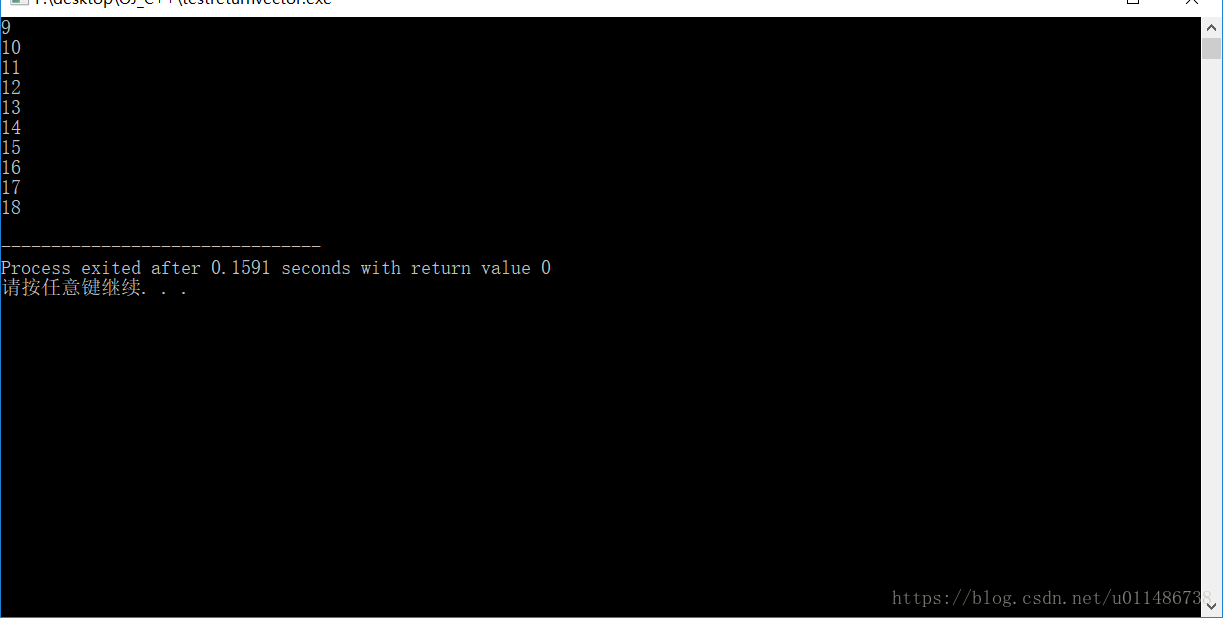
bool getSequence(int num,vector<int>& sequence){
for(int i=0;i<10;i++){
sequence.push_back(i+num);
}
return true;
}
int main(){
int num=9;
vector<int> sequence;
//在主调函数这边,直接传入该vector变量
getSequence(num,sequence);
//访问该vector的值的时候,也是直接访问即可
for(vector<int>::iterator it=sequence.begin();it!=sequence.end();it++){
cout<<*it<<endl;
}
}
四、几种重要的算法,使用时需要包含头文件: #include <algorithm>
(1)sort(a.begin(),a.end()); //对a中的从a.begin()(包括它)到a.end()(不包括它)的元素进行从小到大排列
(2)reverse(a.begin(),a.end()); //对a中的从a.begin()(包括它)到a.end()(不包括它)的元素倒置,但不排列,如a中元素为1,3,2,4,倒置后为4,2,3,1
(3)copy(a.begin(),a.end(),b.begin()+1); //把a中的从a.begin()(包括它)到a.end()(不包括它)的元素复制到b中,从b.begin()+1的位置(包括它)开始复制,覆盖掉原有元素
(4)find(a.begin(),a.end(),10); //在a中的从a.begin()(包括它)到a.end()(不包括它)的元素中查找10,若存在返回其在向量中的位置















 3314
3314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









