<!-- TOC -->
- [Collections 工具类和 Arrays 工具类常见方法](#collections-工具类和-arrays-工具类常见方法)
- [Collections](#collections)
- [排序操作](#排序操作)
- [查找,替换操作](#查找替换操作)
- [同步控制](#同步控制)
- [Arrays类的常见操作](#arrays类的常见操作)
- [排序 : `sort()`](#排序--sort)
- [查找 : `binarySearch()`](#查找--binarysearch)
- [比较: `equals()`](#比较-equals)
- [填充 : `fill()`](#填充--fill)
- [转列表 `asList()`](#转列表-aslist)
- [转字符串 `toString()`](#转字符串-tostring)
- [复制 `copyOf()`](#复制-copyof)
<!-- /TOC -->
# Collections 工具类和 Arrays 工具类常见方法
## Collections
Collections 工具类常用方法:
1. 排序
2. 查找,替换操作
3. 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
### 排序操作
```java
void reverse(List list)//反转
void shuffle(List list)//随机排序
void sort(List list)//按自然排序的升序排序
void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j)//交换两个索引位置的元素
void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
```
**示例代码:**
```java
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
System.out.println("原始数组:");
System.out.println(arrayList);
// void reverse(List list):反转
Collections.reverse(arrayList);
System.out.println("Collections.reverse(arrayList):");
System.out.println(arrayList);
Collections.rotate(arrayList, 4);
System.out.println("Collections.rotate(arrayList, 4):");
System.out.println(arrayList);
// void sort(List list),按自然排序的升序排序
Collections.sort(arrayList);
System.out.println("Collections.sort(arrayList):");
System.out.println(arrayList);
// void shuffle(List list),随机排序
Collections.shuffle(arrayList);
System.out.println("Collections.shuffle(arrayList):");
System.out.println(arrayList);
// void swap(List list, int i , int j),交换两个索引位置的元素
Collections.swap(arrayList, 2, 5);
System.out.println("Collections.swap(arrayList, 2, 5):");
System.out.println(arrayList);
// 定制排序的用法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
System.out.println("定制排序后:");
System.out.println(arrayList);
```
### 查找,替换操作
```java
int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素。
int frequency(Collection c, Object o)//统计元素出现次数
int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素
```
**示例代码:**
```java
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
ArrayList<Integer> arrayList2 = new ArrayList<Integer>();
arrayList2.add(-3);
arrayList2.add(-5);
arrayList2.add(7);
System.out.println("原始数组:");
System.out.println(arrayList);
System.out.println("Collections.max(arrayList):");
System.out.println(Collections.max(arrayList));
System.out.println("Collections.min(arrayList):");
System.out.println(Collections.min(arrayList));
System.out.println("Collections.replaceAll(arrayList, 3, -3):");
Collections.replaceAll(arrayList, 3, -3);
System.out.println(arrayList);
System.out.println("Collections.frequency(arrayList, -3):");
System.out.println(Collections.frequency(arrayList, -3));
System.out.println("Collections.indexOfSubList(arrayList, arrayList2):");
System.out.println(Collections.indexOfSubList(arrayList, arrayList2));
System.out.println("Collections.binarySearch(arrayList, 7):");
// 对List进行二分查找,返回索引,List必须是有序的
Collections.sort(arrayList);
System.out.println(Collections.binarySearch(arrayList, 7));
```
### 同步控制
Collections提供了多个`synchronizedXxx()`方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
我们知道 HashSet,TreeSet,ArrayList,LinkedList,HashMap,TreeMap 都是线程不安全的。Collections提供了多个静态方法可以把他们包装成线程同步的集合。
**最好不要用下面这些方法,效率非常低,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合。**
方法如下:
```java
synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(线程安全的)collection。
synchronizedList(List<T> list)//返回指定列表支持的同步(线程安全的)List。
synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)Map。
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。
```
### Collections还可以设置不可变集合,提供了如下三类方法:
```java
emptyXxx(): 返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
singletonXxx(): 返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是:List,Set,Map。
unmodifiableXxx(): 返回指定集合对象的不可变视图,此处的集合可以是:List,Set,Map。
上面三类方法的参数是原有的集合对象,返回值是该集合的”只读“版本。
```
**示例代码:**
```java
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
HashSet<Integer> integers1 = new HashSet<>();
integers1.add(1);
integers1.add(3);
integers1.add(2);
Map scores = new HashMap();
scores.put("语文" , 80);
scores.put("Java" , 82);
//Collections.emptyXXX();创建一个空的、不可改变的XXX对象
List<Object> list = Collections.emptyList();
System.out.println(list);//[]
Set<Object> objects = Collections.emptySet();
System.out.println(objects);//[]
Map<Object, Object> objectObjectMap = Collections.emptyMap();
System.out.println(objectObjectMap);//{}
//Collections.singletonXXX();
List<ArrayList<Integer>> arrayLists = Collections.singletonList(arrayList);
System.out.println(arrayLists);//[[-1, 3, 3, -5, 7, 4, -9, -7]]
//创建一个只有一个元素,且不可改变的Set对象
Set<ArrayList<Integer>> singleton = Collections.singleton(arrayList);
System.out.println(singleton);//[[-1, 3, 3, -5, 7, 4, -9, -7]]
Map<String, String> nihao = Collections.singletonMap("1", "nihao");
System.out.println(nihao);//{1=nihao}
//unmodifiableXXX();创建普通XXX对象对应的不可变版本
List<Integer> integers = Collections.unmodifiableList(arrayList);
System.out.println(integers);//[-1, 3, 3, -5, 7, 4, -9, -7]
Set<Integer> integers2 = Collections.unmodifiableSet(integers1);
System.out.println(integers2);//[1, 2, 3]
Map<Object, Object> objectObjectMap2 = Collections.unmodifiableMap(scores);
System.out.println(objectObjectMap2);//{Java=82, 语文=80}
//添加出现异常:java.lang.UnsupportedOperationException
// list.add(1);
// arrayLists.add(arrayList);
// integers.add(1);
```
## Arrays类的常见操作
1. 排序 : `sort()`
2. 查找 : `binarySearch()`
3. 比较: `equals()`
4. 填充 : `fill()`
5. 转列表: `asList()`
6. 转字符串 : `toString()`
7. 复制: `copyOf()`
### 排序 : `sort()`
```java
// *************排序 sort****************
int a[] = { 1, 3, 2, 7, 6, 5, 4, 9 };
// sort(int[] a)方法按照数字顺序排列指定的数组。
Arrays.sort(a);
System.out.println("Arrays.sort(a):");
for (int i : a) {
System.out.print(i);
}
// 换行
System.out.println();
// sort(int[] a,int fromIndex,int toIndex)按升序排列数组的指定范围
int b[] = { 1, 3, 2, 7, 6, 5, 4, 9 };
Arrays.sort(b, 2, 6);
System.out.println("Arrays.sort(b, 2, 6):");
for (int i : b) {
System.out.print(i);
}
// 换行
System.out.println();
int c[] = { 1, 3, 2, 7, 6, 5, 4, 9 };
// parallelSort(int[] a) 按照数字顺序排列指定的数组(并行的)。同sort方法一样也有按范围的排序
Arrays.parallelSort(c);
System.out.println("Arrays.parallelSort(c):");
for (int i : c) {
System.out.print(i);
}
// 换行
System.out.println();
// parallelSort给字符数组排序,sort也可以
char d[] = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
Arrays.parallelSort(d);
System.out.println("Arrays.parallelSort(d):");
for (char d2 : d) {
System.out.print(d2);
}
// 换行
System.out.println();
```
在做算法面试题的时候,我们还可能会经常遇到对字符串排序的情况,`Arrays.sort()` 对每个字符串的特定位置进行比较,然后按照升序排序。
```java
String[] strs = { "abcdehg", "abcdefg", "abcdeag" };
Arrays.sort(strs);
System.out.println(Arrays.toString(strs));//[abcdeag, abcdefg, abcdehg]
```
### 查找 : `binarySearch()`
```java
// *************查找 binarySearch()****************
char[] e = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
// 排序后再进行二分查找,否则找不到
Arrays.sort(e);
System.out.println("Arrays.sort(e)" + Arrays.toString(e));
System.out.println("Arrays.binarySearch(e, 'c'):");
int s = Arrays.binarySearch(e, 'c');
System.out.println("字符c在数组的位置:" + s);
```
### 比较: `equals()`
```java
// *************比较 equals****************
char[] e = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
char[] f = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
/*
* 元素数量相同,并且相同位置的元素相同。 另外,如果两个数组引用都是null,则它们被认为是相等的 。
*/
// 输出true
System.out.println("Arrays.equals(e, f):" + Arrays.equals(e, f));
```
### 填充 : `fill()`
```java
// *************填充fill(批量初始化)****************
int[] g = { 1, 2, 3, 3, 3, 3, 6, 6, 6 };
// 数组中所有元素重新分配值
Arrays.fill(g, 3);
System.out.println("Arrays.fill(g, 3):");
// 输出结果:333333333
for (int i : g) {
System.out.print(i);
}
// 换行
System.out.println();
int[] h = { 1, 2, 3, 3, 3, 3, 6, 6, 6, };
// 数组中指定范围元素重新分配值
Arrays.fill(h, 0, 2, 9);
System.out.println("Arrays.fill(h, 0, 2, 9);:");
// 输出结果:993333666
for (int i : h) {
System.out.print(i);
}
```
### 转列表 `asList()`
```java
// *************转列表 asList()****************
/*
* 返回由指定数组支持的固定大小的列表。
* (将返回的列表更改为“写入数组”。)该方法作为基于数组和基于集合的API之间的桥梁,与Collection.toArray()相结合 。
* 返回的列表是可序列化的,并实现RandomAccess 。
* 此方法还提供了一种方便的方式来创建一个初始化为包含几个元素的固定大小的列表如下:
*/
List<String> stooges = Arrays.asList("Larry", "Moe", "Curly");
System.out.println(stooges);
```
### 转字符串 `toString()`
```java
// *************转字符串 toString()****************
/*
* 返回指定数组的内容的字符串表示形式。
*/
char[] k = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
System.out.println(Arrays.toString(k));// [a, f, b, c, e, A, C, B]
```
### 复制 `copyOf()`
```java
// *************复制 copy****************
// copyOf 方法实现数组复制,h为数组,6为复制的长度
int[] h = { 1, 2, 3, 3, 3, 3, 6, 6, 6, };
int i[] = Arrays.copyOf(h, 6);
System.out.println("Arrays.copyOf(h, 6);:");
// 输出结果:123333
for (int j : i) {
System.out.print(j);
}
// 换行
System.out.println();
// copyOfRange将指定数组的指定范围复制到新数组中
int j[] = Arrays.copyOfRange(h, 6, 11);
System.out.println("Arrays.copyOfRange(h, 6, 11):");
// 输出结果66600(h数组只有9个元素这里是从索引6到索引11复制所以不足的就为0)
for (int j2 : j) {
System.out.print(j2);
}
// 换行
System.out.println();
```
<!-- MarkdownTOC -->
- [final,static,this,super 关键字总结](#finalstaticthissuper-关键字总结)
- [final 关键字](#final-关键字)
- [static 关键字](#static-关键字)
- [this 关键字](#this-关键字)
- [super 关键字](#super-关键字)
- [参考](#参考)
- [static 关键字详解](#static-关键字详解)
- [static 关键字主要有以下四种使用场景](#static-关键字主要有以下四种使用场景)
- [修饰成员变量和成员方法\(常用\)](#修饰成员变量和成员方法常用)
- [静态代码块](#静态代码块)
- [静态内部类](#静态内部类)
- [静态导包](#静态导包)
- [补充内容](#补充内容)
- [静态方法与非静态方法](#静态方法与非静态方法)
- [static{}静态代码块与{}非静态代码块\(构造代码块\)](#static静态代码块与非静态代码块构造代码块)
- [参考](#参考-1)
<!-- /MarkdownTOC -->
# final,static,this,super 关键字总结
## final 关键字
**final关键字主要用在三个地方:变量、方法、类。**
1. **对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。**
2. **当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。**
3. 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
## static 关键字
**static 关键字主要有以下四种使用场景:**
1. **修饰成员变量和成员方法:** 被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用。被static 声明的成员变量属于静态成员变量,静态变量 存放在 Java 内存区域的方法区。调用格式:`类名.静态变量名` `类名.静态方法名()`
2. **静态代码块:** 静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块—>非静态代码块—>构造方法)。 该类不管创建多少对象,静态代码块只执行一次.
3. **静态内部类(static修饰类的话只能修饰内部类):** 静态内部类与非静态内部类之间存在一个最大的区别: 非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着:1. 它的创建是不需要依赖外围类的创建。2. 它不能使用任何外围类的非static成员变量和方法。
4. **静态导包(用来导入类中的静态资源,1.5之后的新特性):** 格式为:`import static` 这两个关键字连用可以指定导入某个类中的指定静态资源,并且不需要使用类名调用类中静态成员,可以直接使用类中静态成员变量和成员方法。
## this 关键字
this关键字用于引用类的当前实例。 例如:
```java
class Manager {
Employees[] employees;
void manageEmployees() {
int totalEmp = this.employees.length;
System.out.println("Total employees: " + totalEmp);
this.report();
}
void report() { }
}
```
在上面的示例中,this关键字用于两个地方:
- this.employees.length:访问类Manager的当前实例的变量。
- this.report():调用类Manager的当前实例的方法。
此关键字是可选的,这意味着如果上面的示例在不使用此关键字的情况下表现相同。 但是,使用此关键字可能会使代码更易读或易懂。
## super 关键字
super关键字用于从子类访问父类的变量和方法。 例如:
```java
public class Super {
protected int number;
protected showNumber() {
System.out.println("number = " + number);
}
}
public class Sub extends Super {
void bar() {
super.number = 10;
super.showNumber();
}
}
```
在上面的例子中,Sub 类访问父类成员变量 number 并调用其其父类 Super 的 `showNumber()` 方法。
**使用 this 和 super 要注意的问题:**
- 在构造器中使用 `super()` 调用父类中的其他构造方法时,该语句必须处于构造器的首行,否则编译器会报错。另外,this 调用本类中的其他构造方法时,也要放在首行。
- this、super不能用在static方法中。
**简单解释一下:**
被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享。而 this 代表对本类对象的引用,指向本类对象;而 super 代表对父类对象的引用,指向父类对象;所以, **this和super是属于对象范畴的东西,而静态方法是属于类范畴的东西**。
## 参考
- https://www.codejava.net/java-core/the-java-language/java-keywords
- https://blog.csdn.net/u013393958/article/details/79881037
# static 关键字详解
## static 关键字主要有以下四种使用场景
1. 修饰成员变量和成员方法
2. 静态代码块
3. 修饰类(只能修饰内部类)
4. 静态导包(用来导入类中的静态资源,1.5之后的新特性)
### 修饰成员变量和成员方法(常用)
被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用。被static 声明的成员变量属于静态成员变量,静态变量 存放在 Java 内存区域的方法区。
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
HotSpot 虚拟机中方法区也常被称为 “永久代”,本质上两者并不等价。仅仅是因为 HotSpot 虚拟机设计团队用永久代来实现方法区而已,这样 HotSpot 虚拟机的垃圾收集器就可以像管理 Java 堆一样管理这部分内存了。但是这并不是一个好主意,因为这样更容易遇到内存溢出问题。
调用格式:
- 类名.静态变量名
- 类名.静态方法名()
如果变量或者方法被 private 则代表该属性或者该方法只能在类的内部被访问而不能在类的外部被访问。
测试方法:
```java
public class StaticBean {
String name;
静态变量
static int age;
public StaticBean(String name) {
this.name = name;
}
静态方法
static void SayHello() {
System.out.println(Hello i am java);
}
@Override
public String toString() {
return StaticBean{ +
name=' + name + ''' + age + age +
'}';
}
}
```
```java
public class StaticDemo {
public static void main(String[] args) {
StaticBean staticBean = new StaticBean(1);
StaticBean staticBean2 = new StaticBean(2);
StaticBean staticBean3 = new StaticBean(3);
StaticBean staticBean4 = new StaticBean(4);
StaticBean.age = 33;
StaticBean{name='1'age33} StaticBean{name='2'age33} StaticBean{name='3'age33} StaticBean{name='4'age33}
System.out.println(staticBean+ +staticBean2+ +staticBean3+ +staticBean4);
StaticBean.SayHello();Hello i am java
}
}
```
### 静态代码块
静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块—非静态代码块—构造方法)。 该类不管创建多少对象,静态代码块只执行一次.
静态代码块的格式是
```
static {
语句体;
}
```
一个类中的静态代码块可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会执行这些静态的代码块,如果静态代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。
静态代码块对于定义在它之后的静态变量,可以赋值,但是不能访问.
### 静态内部类
静态内部类与非静态内部类之间存在一个最大的区别,我们知道非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着:
1. 它的创建是不需要依赖外围类的创建。
2. 它不能使用任何外围类的非static成员变量和方法。
Example(静态内部类实现单例模式)
```java
public class Singleton {
声明为 private 避免调用默认构造方法创建对象
private Singleton() {
}
声明为 private 表明静态内部该类只能在该 Singleton 类中被访问
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getUniqueInstance() {
return SingletonHolder.INSTANCE;
}
}
```
当 Singleton 类加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance() `方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
这种方式不仅具有延迟初始化的好处,而且由 JVM 提供了对线程安全的支持。
### 静态导包
格式为:import static
这两个关键字连用可以指定导入某个类中的指定静态资源,并且不需要使用类名调用类中静态成员,可以直接使用类中静态成员变量和成员方法
```java
Math. --- 将Math中的所有静态资源导入,这时候可以直接使用里面的静态方法,而不用通过类名进行调用
如果只想导入单一某个静态方法,只需要将换成对应的方法名即可
import static java.lang.Math.;
换成import static java.lang.Math.max;具有一样的效果
public class Demo {
public static void main(String[] args) {
int max = max(1,2);
System.out.println(max);
}
}
```
## 补充内容
### 静态方法与非静态方法
静态方法属于类本身,非静态方法属于从该类生成的每个对象。 如果您的方法执行的操作不依赖于其类的各个变量和方法,请将其设置为静态(这将使程序的占用空间更小)。 否则,它应该是非静态的。
Example
```java
class Foo {
int i;
public Foo(int i) {
this.i = i;
}
public static String method1() {
return An example string that doesn't depend on i (an instance variable);
}
public int method2() {
return this.i + 1; Depends on i
}
}
```
你可以像这样调用静态方法:`Foo.method1()`。 如果您尝试使用这种方法调用 method2 将失败。 但这样可行:`Foo bar = new Foo(1);bar.method2();`
总结:
- 在外部调用静态方法时,可以使用”类名.方法名”的方式,也可以使用”对象名.方法名”的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
- 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制
### static{}静态代码块与{}非静态代码块(构造代码块)
相同点: 都是在JVM加载类时且在构造方法执行之前执行,在类中都可以定义多个,定义多个时按定义的顺序执行,一般在代码块中对一些static变量进行赋值。
不同点: 静态代码块在非静态代码块之前执行(静态代码块—非静态代码块—构造方法)。静态代码块只在第一次new执行一次,之后不再执行,而非静态代码块在每new一次就执行一次。 非静态代码块可在普通方法中定义(不过作用不大);而静态代码块不行。
一般情况下,如果有些代码比如一些项目最常用的变量或对象必须在项目启动的时候就执行的时候,需要使用静态代码块,这种代码是主动执行的。如果我们想要设计不需要创建对象就可以调用类中的方法,例如:Arrays类,Character类,String类等,就需要使用静态方法, 两者的区别是 静态代码块是自动执行的而静态方法是被调用的时候才执行的.
Example
```java
public class Test {
public Test() {
System.out.print(默认构造方法!--);
}
非静态代码块
{
System.out.print(非静态代码块!--);
}
静态代码块
static {
System.out.print(静态代码块!--);
}
public static void test() {
System.out.print(静态方法中的内容! --);
{
System.out.print(静态方法中的代码块!--);
}
}
public static void main(String[] args) {
Test test = new Test();
Test.test();静态代码块!--静态方法中的内容! --静态方法中的代码块!--
}
```
当执行 `Test.test();` 时输出:
```
静态代码块!--静态方法中的内容! --静态方法中的代码块!--
```
当执行 `Test test = new Test();` 时输出:
```
静态代码块!--非静态代码块!--默认构造方法!--
```
非静态代码块与构造函数的区别是: 非静态代码块是给所有对象进行统一初始化,而构造函数是给对应的对象初始化,因为构造函数是可以多个的,运行哪个构造函数就会建立什么样的对象,但无论建立哪个对象,都会先执行相同的构造代码块。也就是说,构造代码块中定义的是不同对象共性的初始化内容。
### 参考
- httpsblog.csdn.netchen13579867831articledetails78995480
- httpwww.cnblogs.comchenssyp3388487.html
- httpwww.cnblogs.comQian123p5713440.html
<!-- MarkdownTOC -->
- [ArrayList简介](#arraylist简介)
- [ArrayList核心源码](#arraylist核心源码)
- [ArrayList源码分析](#arraylist源码分析)
- [System.arraycopy\(\)和Arrays.copyOf\(\)方法](#systemarraycopy和arrayscopyof方法)
- [两者联系与区别](#两者联系与区别)
- [ArrayList核心扩容技术](#arraylist核心扩容技术)
- [内部类](#内部类)
- [ArrayList经典Demo](#arraylist经典demo)
<!-- /MarkdownTOC -->
### ArrayList简介
ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用`ensureCapacity`操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。
它继承于 **AbstractList**,实现了 **List**, **RandomAccess**, **Cloneable**, **java.io.Serializable** 这些接口。
在我们学数据结构的时候就知道了线性表的顺序存储,插入删除元素的时间复杂度为**O(n)**,求表长以及增加元素,取第 i 元素的时间复杂度为**O(1)**
ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
ArrayList 实现了**RandomAccess 接口**, RandomAccess 是一个标志接口,表明实现这个这个接口的 List 集合是支持**快速随机访问**的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
ArrayList 实现了**Cloneable 接口**,即覆盖了函数 clone(),**能被克隆**。
ArrayList 实现**java.io.Serializable 接口**,这意味着ArrayList**支持序列化**,**能通过序列化去传输**。
和 Vector 不同,**ArrayList 中的操作不是线程安全的**!所以,建议在单线程中才使用 ArrayList,而在多线程中可以选择 Vector 或者 CopyOnWriteArrayList。
### ArrayList核心源码
```java
package java.util;
import java.util.function.Consumer;
import java.util.function.Predicate;
import java.util.function.UnaryOperator;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 空数组(用于空实例)。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
//用于默认大小空实例的共享空数组实例。
//我们把它从EMPTY_ELEMENTDATA数组中区分出来,以知道在添加第一个元素时容量需要增加多少。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 保存ArrayList数据的数组
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 所包含的元素个数
*/
private int size;
/**
* 带初始容量参数的构造函数。(用户自己指定容量)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
*默认构造函数,DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection<? extends E> c) {
//
elementData = c.toArray();
//如果指定集合元素个数不为0
if ((size = elementData.length) != 0) {
// c.toArray 可能返回的不是Object类型的数组所以加上下面的语句用于判断,
//这里用到了反射里面的getClass()方法
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
* 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
//下面是ArrayList的扩容机制
//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
/**
* 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取默认的容量和传入参数的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//比较minCapacity和 MAX_ARRAY_SIZE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
*返回此列表中的元素数。
*/
public int size() {
return size;
}
/**
* 如果此列表不包含元素,则返回 true 。
*/
public boolean isEmpty() {
//注意=和==的区别
return size == 0;
}
/**
* 如果此列表包含指定的元素,则返回true 。
*/
public boolean contains(Object o) {
//indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
return indexOf(o) >= 0;
}
/**
*返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
//equals()方法比较
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。.
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
//Arrays.copyOf功能是实现数组的复制,返回复制后的数组。参数是被复制的数组和复制的长度
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// 这不应该发生,因为我们是可以克隆的
throw new InternalError(e);
}
}
/**
*以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
*返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
*因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
*/
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
/**
* 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
*返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
*否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
*如果列表适用于指定的数组,其余空间(即数组的列表数量多于此元素),则紧跟在集合结束后的数组中的元素设置为null 。
*(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// 新建一个运行时类型的数组,但是ArrayList数组的内容
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
//调用System提供的arraycopy()方法实现数组之间的复制
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* 返回此列表中指定位置的元素。
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
/**
* 用指定的元素替换此列表中指定位置的元素。
*/
public E set(int index, E element) {
//对index进行界限检查
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
//返回原来在这个位置的元素
return oldValue;
}
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
//这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
/**
* 在此列表中的指定位置插入指定的元素。
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()这个实现数组之间复制的方法一定要看一下,下面就用到了arraycopy()方法实现数组自己复制自己
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
/**
* 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
//从列表中删除的元素
return oldValue;
}
/**
* 从列表中删除指定元素的第一个出现(如果存在)。 如果列表不包含该元素,则它不会更改。
*返回true,如果此列表包含指定的元素
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
/**
* 从列表中删除所有元素。
*/
public void clear() {
modCount++;
// 把数组中所有的元素的值设为null
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
/**
* 按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
/**
* 将指定集合中的所有元素插入到此列表中,从指定的位置开始。
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
/**
* 从此列表中删除所有索引为fromIndex (含)和toIndex之间的元素。
*将任何后续元素移动到左侧(减少其索引)。
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 检查给定的索引是否在范围内。
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* add和addAll使用的rangeCheck的一个版本
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 返回IndexOutOfBoundsException细节信息
*/
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
/**
* 从此列表中删除指定集合中包含的所有元素。
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
//如果此列表被修改则返回true
return batchRemove(c, false);
}
/**
* 仅保留此列表中包含在指定集合中的元素。
*换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
/**
* 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
*指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
*返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
/**
*返回列表中的列表迭代器(按适当的顺序)。
*返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator() {
return new ListItr(0);
}
/**
*以正确的顺序返回该列表中的元素的迭代器。
*返回的迭代器是fail-fast 。
*/
public Iterator<E> iterator() {
return new Itr();
}
```
### <font face="楷体" id="1" id="5">ArrayList源码分析</font>
#### System.arraycopy()和Arrays.copyOf()方法
通过上面源码我们发现这两个实现数组复制的方法被广泛使用而且很多地方都特别巧妙。比如下面<font color="red">add(int index, E element)</font>方法就很巧妙的用到了<font color="red">arraycopy()方法</font>让数组自己复制自己实现让index开始之后的所有成员后移一个位置:
```java
/**
* 在此列表中的指定位置插入指定的元素。
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()方法实现数组自己复制自己
//elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
```
又如toArray()方法中用到了copyOf()方法
```java
/**
*以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
*返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
*因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
*/
public Object[] toArray() {
//elementData:要复制的数组;size:要复制的长度
return Arrays.copyOf(elementData, size);
}
```
##### 两者联系与区别
**联系:**
看两者源代码可以发现`copyOf()`内部调用了`System.arraycopy()`方法
**区别:**
1. arraycopy()需要目标数组,将原数组拷贝到你自己定义的数组里,而且可以选择拷贝的起点和长度以及放入新数组中的位置
2. copyOf()是系统自动在内部新建一个数组,并返回该数组。
#### ArrayList 核心扩容技术
```java
//下面是ArrayList的扩容机制
//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
/**
* 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取默认的容量和传入参数的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
//判断是否需要扩容,上面两个方法都要调用
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 如果说minCapacity也就是所需的最小容量大于保存ArrayList数据的数组的长度的话,就需要调用grow(minCapacity)方法扩容。
//这个minCapacity到底为多少呢?举个例子在添加元素(add)方法中这个minCapacity的大小就为现在数组的长度加1
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
```
```java
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
//elementData为保存ArrayList数据的数组
///elementData.length求数组长度elementData.size是求数组中的元素个数
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
```
扩容机制代码已经做了详细的解释。另外值得注意的是大家很容易忽略的一个运算符:**移位运算符**
**简介**:移位运算符就是在二进制的基础上对数字进行平移。按照平移的方向和填充数字的规则分为三种:<font color="red"><<(左移)</font>、<font color="red">>>(带符号右移)</font>和<font color="red">>>>(无符号右移)</font>。
**作用**:**对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源**
比如这里:int newCapacity = oldCapacity + (oldCapacity >> 1);
右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。
**另外需要注意的是:**
1. java 中的**length 属性**是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
2. java 中的**length()方法**是针对字 符串String说的,如果想看这个字符串的长度则用到 length()这个方法.
3. .java 中的**size()方法**是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
#### 内部类
```java
(1)private class Itr implements Iterator<E>
(2)private class ListItr extends Itr implements ListIterator<E>
(3)private class SubList extends AbstractList<E> implements RandomAccess
(4)static final class ArrayListSpliterator<E> implements Spliterator<E>
```
ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**, **next()**, **remove()** 等方法;其中的**ListItr** 继承 **Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**, **nextIndex()**, **previousIndex()**, **previous()**, **set(E e)**, **add(E e)** 等方法,所以这也可以看出了 **Iterator和ListIterator的区别:** ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
### <font face="楷体" id="6"> ArrayList经典Demo</font>
```java
package list;
import java.util.ArrayList;
import java.util.Iterator;
public class ArrayListDemo {
public static void main(String[] srgs){
ArrayList<Integer> arrayList = new ArrayList<Integer>();
System.out.printf("Before add:arrayList.size() = %d\n",arrayList.size());
arrayList.add(1);
arrayList.add(3);
arrayList.add(5);
arrayList.add(7);
arrayList.add(9);
System.out.printf("After add:arrayList.size() = %d\n",arrayList.size());
System.out.println("Printing elements of arrayList");
// 三种遍历方式打印元素
// 第一种:通过迭代器遍历
System.out.print("通过迭代器遍历:");
Iterator<Integer> it = arrayList.iterator();
while(it.hasNext()){
System.out.print(it.next() + " ");
}
System.out.println();
// 第二种:通过索引值遍历
System.out.print("通过索引值遍历:");
for(int i = 0; i < arrayList.size(); i++){
System.out.print(arrayList.get(i) + " ");
}
System.out.println();
// 第三种:for循环遍历
System.out.print("for循环遍历:");
for(Integer number : arrayList){
System.out.print(number + " ");
}
// toArray用法
// 第一种方式(最常用)
Integer[] integer = arrayList.toArray(new Integer[0]);
// 第二种方式(容易理解)
Integer[] integer1 = new Integer[arrayList.size()];
arrayList.toArray(integer1);
// 抛出异常,java不支持向下转型
//Integer[] integer2 = new Integer[arrayList.size()];
//integer2 = arrayList.toArray();
System.out.println();
// 在指定位置添加元素
arrayList.add(2,2);
// 删除指定位置上的元素
arrayList.remove(2);
// 删除指定元素
arrayList.remove((Object)3);
// 判断arrayList是否包含5
System.out.println("ArrayList contains 5 is: " + arrayList.contains(5));
// 清空ArrayList
arrayList.clear();
// 判断ArrayList是否为空
System.out.println("ArrayList is empty: " + arrayList.isEmpty());
}
}
```
## 一 先从 ArrayList 的构造函数说起
**ArrayList有三种方式来初始化,构造方法源码如下:**
```java
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
*默认构造函数,使用初始容量10构造一个空列表(无参数构造)
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 带初始容量参数的构造函数。(用户自己指定容量)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {//初始容量大于0
//创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//初始容量等于0
//创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {//初始容量小于0,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
*构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
*如果指定的集合为null,throws NullPointerException。
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
```
细心的同学一定会发现 :**以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
## 二 一步一步分析 ArrayList 扩容机制
这里以无参构造函数创建的 ArrayList 为例分析
### 1. 先来看 `add` 方法
```java
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
//添加元素之前,先调用ensureCapacityInternal方法
ensureCapacityInternal(size + 1); // Increments modCount!!
//这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
```
### 2. 再来看看 `ensureCapacityInternal()` 方法
可以看到 `add` 方法 首先调用了`ensureCapacityInternal(size + 1)`
```java
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取默认的容量和传入参数的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
```
**当 要 add 进第1个元素时,minCapacity为1,在Math.max()方法比较后,minCapacity 为10。**
### 3. `ensureExplicitCapacity()` 方法
如果调用 `ensureCapacityInternal()` 方法就一定会进过(执行)这个方法,下面我们来研究一下这个方法的源码!
```java
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
```
我们来仔细分析一下:
- 当我们要 add 进第1个元素到 ArrayList 时,elementData.length 为0 (因为还是一个空的 list),因为执行了 `ensureCapacityInternal()` 方法 ,所以 minCapacity 此时为10。此时,`minCapacity - elementData.length > 0 `成立,所以会进入 `grow(minCapacity)` 方法。
- 当add第2个元素时,minCapacity 为2,此时e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,`minCapacity - elementData.length > 0 ` 不成立,所以不会进入 (执行)`grow(minCapacity)` 方法。
- 添加第3、4···到第10个元素时,依然不会执行grow方法,数组容量都为10。
直到添加第11个元素,minCapacity(为11)比elementData.length(为10)要大。进入grow方法进行扩容。
### 4. `grow()` 方法
```java
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
```
**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍!(JDK1.6版本以后)** JDk1.6版本时,扩容之后容量为 1.5 倍+1!详情请参考源码
> ">>"(移位运算符):>>1 右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
**我们再来通过例子探究一下`grow()` 方法 :**
- 当add第1个元素时,oldCapacity 为0,经比较后第一个if判断成立,newCapacity = minCapacity(为10)。但是第二个if判断不会成立,即newCapacity 不比 MAX_ARRAY_SIZE大,则不会进入 `hugeCapacity` 方法。数组容量为10,add方法中 return true,size增为1。
- 当add第11个元素进入grow方法时,newCapacity为15,比minCapacity(为11)大,第一个if判断不成立。新容量没有大于数组最大size,不会进入hugeCapacity方法。数组容量扩为15,add方法中return true,size增为11。
- 以此类推······
**这里补充一点比较重要,但是容易被忽视掉的知识点:**
- java 中的 `length `属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
- java 中的 `length()` 方法是针对字符串说的,如果想看这个字符串的长度则用到 `length()` 这个方法.
- java 中的 `size()` 方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
### 5. `hugeCapacity()` 方法。
从上面 `grow()` 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
```java
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//对minCapacity和MAX_ARRAY_SIZE进行比较
//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
```
## 三 `System.arraycopy()` 和 `Arrays.copyOf()`方法
阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及`add(int index, E element)`、`toArray()` 等方法中都用到了该方法!
### 3.1 `System.arraycopy()` 方法
```java
/**
* 在此列表中的指定位置插入指定的元素。
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()方法实现数组自己复制自己
//elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
```
我们写一个简单的方法测试以下:
```java
public class ArraycopyTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] a = new int[10];
a[0] = 0;
a[1] = 1;
a[2] = 2;
a[3] = 3;
System.arraycopy(a, 2, a, 3, 3);
a[2]=99;
for (int i = 0; i < a.length; i++) {
System.out.println(a[i]);
}
}
}
```
结果:
```
0 1 99 2 3 0 0 0 0 0
```
### 3.2 `Arrays.copyOf()`方法
```java
/**
以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。
*/
public Object[] toArray() {
//elementData:要复制的数组;size:要复制的长度
return Arrays.copyOf(elementData, size);
}
```
个人觉得使用 `Arrays.copyOf()`方法主要是为了给原有数组扩容,测试代码如下:
```java
public class ArrayscopyOfTest {
public static void main(String[] args) {
int[] a = new int[3];
a[0] = 0;
a[1] = 1;
a[2] = 2;
int[] b = Arrays.copyOf(a, 10);
System.out.println("b.length"+b.length);
}
}
```
结果:
```
10
```
### 3.3 两者联系和区别
**联系:**
看两者源代码可以发现 copyOf() 内部实际调用了 `System.arraycopy()` 方法
**区别:**
`arraycopy()` 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 `copyOf()` 是系统自动在内部新建一个数组,并返回该数组。
## 四 `ensureCapacity`方法
ArrayList 源码中有一个 `ensureCapacity` 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
```java
/**
如有必要,增加此 ArrayList 实例的容量,以确保它至少可以容纳由minimum capacity参数指定的元素数。
*
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
```
**最好在 add 大量元素之前用 `ensureCapacity` 方法,以减少增量重新分配的次数**
我们通过下面的代码实际测试以下这个方法的效果:
```java
public class EnsureCapacityTest {
public static void main(String[] args) {
ArrayList<Object> list = new ArrayList<Object>();
final int N = 10000000;
long startTime = System.currentTimeMillis();
for (int i = 0; i < N; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
list = new ArrayList<Object>();
long startTime1 = System.currentTimeMillis();
list.ensureCapacity(N);
for (int i = 0; i < N; i++) {
list.add(i);
}
long endTime1 = System.currentTimeMillis();
System.out.println("使用ensureCapacity方法后:"+(endTime1 - startTime1));
}
}
```
运行结果:
```
使用ensureCapacity方法前:4637
使用ensureCapacity方法后:241
```
通过运行结果,我们可以很明显的看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量重新分配的次数
<!-- MarkdownTOC -->
- [HashMap 简介](#hashmap-简介)
- [底层数据结构分析](#底层数据结构分析)
- [JDK1.8之前](#jdk18之前)
- [JDK1.8之后](#jdk18之后)
- [HashMap源码分析](#hashmap源码分析)
- [构造方法](#构造方法)
- [put方法](#put方法)
- [get方法](#get方法)
- [resize方法](#resize方法)
- [HashMap常用方法测试](#hashmap常用方法测试)
<!-- /MarkdownTOC -->
> 感谢 [changfubai](https://github.com/changfubai) 对本文的改进做出的贡献!
## HashMap 简介
HashMap 主要用来存放键值对,它基于哈希表的Map接口实现</font>,是常用的Java集合之一。
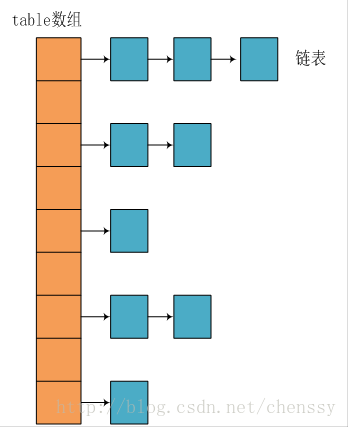
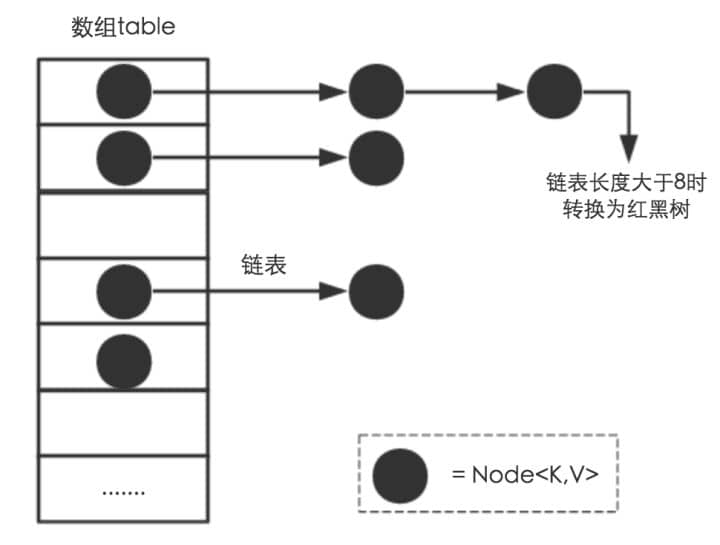
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考 `treeifyBin`方法。
## 底层数据结构分析
### JDK1.8之前
JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
**JDK 1.8 HashMap 的 hash 方法源码:**
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
```java
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
```
对比一下 JDK1.7的 HashMap 的 hash 方法源码.
```java
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
```
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
### JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
**类的属性:**
```java
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
// 加载因子
final float loadFactor;
}
```
- **loadFactor加载因子**
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
**loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值**。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
- **threshold**
**threshold = capacity * loadFactor**,**当Size>=threshold**的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 **衡量数组是否需要扩增的一个标准**。
**Node节点类源码:**
```java
// 继承自 Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较
final K key;//键
V value;//值
// 指向下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// 重写hashCode()方法
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重写 equals() 方法
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
```
**树节点类源码:**
```java
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父
TreeNode<K,V> left; // 左
TreeNode<K,V> right; // 右
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 判断颜色
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// 返回根节点
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
```
## HashMap源码分析
### 构造方法
HashMap 中有四个构造方法,它们分别如下:
```java
// 默认构造函数。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//下面会分析到这个方法
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
```
**putMapEntries方法:**
```java
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
```
### put方法
HashMap只提供了put用于添加元素,putVal方法只是给put方法调用的一个方法,并没有提供给用户使用。
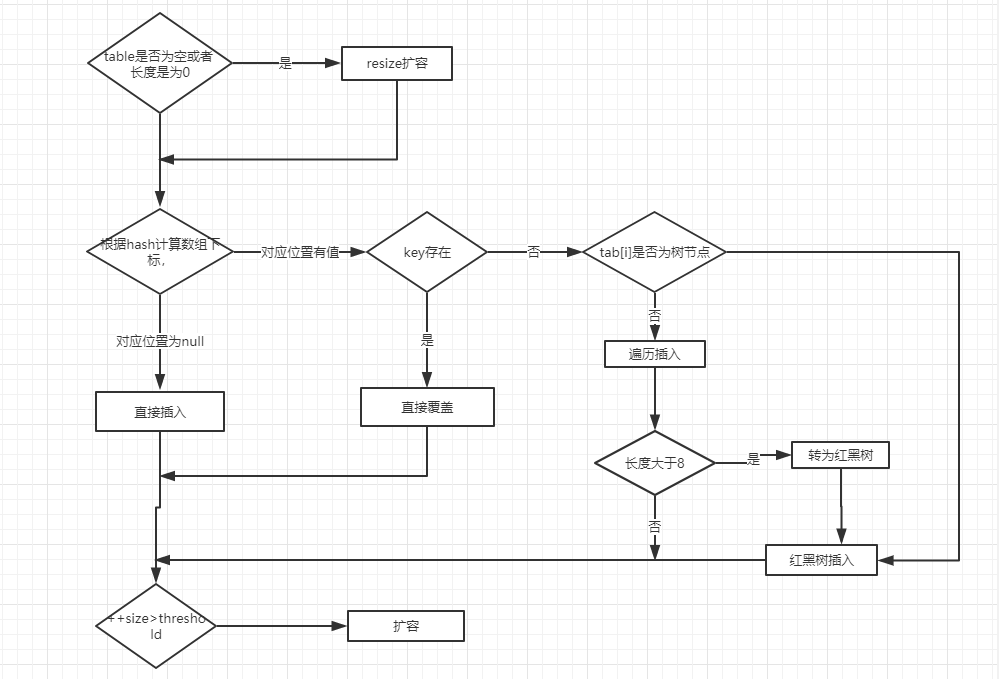
**对putVal方法添加元素的分析如下:**
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用`e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
```java
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
Node<K,V> e; K k;
// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
// hash值不相等,即key不相等;为红黑树结点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值,转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
```
**我们再来对比一下 JDK1.7 put方法的代码**
**对于put方法的分析如下:**
- ①如果定位到的数组位置没有元素 就直接插入。
- ②如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的key比较,如果key相同就直接覆盖,不同就采用头插法插入元素。
```java
public V put(K key, V value)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) { // 先遍历
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // 再插入
return null;
}
```
### get方法
```java
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 数组元素相等
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个节点
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
```
### resize方法
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
```java
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
```
## HashMap常用方法测试
```java
package map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<String, String>();
// 键不能重复,值可以重复
map.put("san", "张三");
map.put("si", "李四");
map.put("wu", "王五");
map.put("wang", "老王");
map.put("wang", "老王2");// 老王被覆盖
map.put("lao", "老王");
System.out.println("-------直接输出hashmap:-------");
System.out.println(map);
/**
* 遍历HashMap
*/
// 1.获取Map中的所有键
System.out.println("-------foreach获取Map中所有的键:------");
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.print(key+" ");
}
System.out.println();//换行
// 2.获取Map中所有值
System.out.println("-------foreach获取Map中所有的值:------");
Collection<String> values = map.values();
for (String value : values) {
System.out.print(value+" ");
}
System.out.println();//换行
// 3.得到key的值的同时得到key所对应的值
System.out.println("-------得到key的值的同时得到key所对应的值:-------");
Set<String> keys2 = map.keySet();
for (String key : keys2) {
System.out.print(key + ":" + map.get(key)+" ");
}
/**
* 另外一种不常用的遍历方式
*/
// 当我调用put(key,value)方法的时候,首先会把key和value封装到
// Entry这个静态内部类对象中,把Entry对象再添加到数组中,所以我们想获取
// map中的所有键值对,我们只要获取数组中的所有Entry对象,接下来
// 调用Entry对象中的getKey()和getValue()方法就能获取键值对了
Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();
for (java.util.Map.Entry<String, String> entry : entrys) {
System.out.println(entry.getKey() + "--" + entry.getValue());
}
/**
* HashMap其他常用方法
*/
System.out.println("after map.size():"+map.size());
System.out.println("after map.isEmpty():"+map.isEmpty());
System.out.println(map.remove("san"));
System.out.println("after map.remove():"+map);
System.out.println("after map.get(si):"+map.get("si"));
System.out.println("after map.containsKey(si):"+map.containsKey("si"));
System.out.println("after containsValue(李四):"+map.containsValue("李四"));
System.out.println(map.replace("si", "李四2"));
System.out.println("after map.replace(si, 李四2):"+map);
}
}
```
<!-- MarkdownTOC -->
- [简介](#简介)
- [内部结构分析](#内部结构分析)
- [LinkedList源码分析](#linkedlist源码分析)
- [构造方法](#构造方法)
- [添加(add)方法](#add方法)
- [根据位置取数据的方法](#根据位置取数据的方法)
- [根据对象得到索引的方法](#根据对象得到索引的方法)
- [检查链表是否包含某对象的方法:](#检查链表是否包含某对象的方法:)
- [删除(remove/pop)方法](#删除方法)
- [LinkedList类常用方法测试:](#linkedlist类常用方法测试)
<!-- /MarkdownTOC -->
## <font face="楷体" id="1">简介</font>
<font color="red">LinkedList</font>是一个实现了<font color="red">List接口</font>和<font color="red">Deque接口</font>的<font color="red">双端链表</font>。
LinkedList底层的链表结构使它<font color="red">支持高效的插入和删除操作</font>,另外它实现了Deque接口,使得LinkedList类也具有队列的特性;
LinkedList<font color="red">不是线程安全的</font>,如果想使LinkedList变成线程安全的,可以调用静态类<font color="red">Collections类</font>中的<font color="red">synchronizedList</font>方法:
```java
List list=Collections.synchronizedList(new LinkedList(...));
```
## <font face="楷体" id="2">内部结构分析</font>
**如下图所示:**

看完了图之后,我们再看LinkedList类中的一个<font color="red">**内部私有类Node**</font>就很好理解了:
```java
private static class Node<E> {
E item;//节点值
Node<E> next;//后继节点
Node<E> prev;//前驱节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
```
这个类就代表双端链表的节点Node。这个类有三个属性,分别是前驱节点,本节点的值,后继结点。
## <font face="楷体" id="3">LinkedList源码分析</font>
### <font face="楷体" id="3.1">构造方法</font>
**空构造方法:**
```java
public LinkedList() {
}
```
**用已有的集合创建链表的构造方法:**
```java
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
```
### <font face="楷体" id="3.2">add方法</font>
**add(E e)** 方法:将元素添加到链表尾部
```java
public boolean add(E e) {
linkLast(e);//这里就只调用了这一个方法
return true;
}
```
```java
/**
* 链接使e作为最后一个元素。
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;//新建节点
if (l == null)
first = newNode;
else
l.next = newNode;//指向后继元素也就是指向下一个元素
size++;
modCount++;
}
```
**add(int index,E e)**:在指定位置添加元素
```java
public void add(int index, E element) {
checkPositionIndex(index); //检查索引是否处于[0-size]之间
if (index == size)//添加在链表尾部
linkLast(element);
else//添加在链表中间
linkBefore(element, node(index));
}
```
<font color="red">linkBefore方法</font>需要给定两个参数,一个<font color="red">插入节点的值</font>,一个<font color="red">指定的node</font>,所以我们又调用了<font color="red">Node(index)去找到index对应的node</font>
**addAll(Collection c ):将集合插入到链表尾部**
```java
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
```
**addAll(int index, Collection c):** 将集合从指定位置开始插入
```java
public boolean addAll(int index, Collection<? extends E> c) {
//1:检查index范围是否在size之内
checkPositionIndex(index);
//2:toArray()方法把集合的数据存到对象数组中
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
//3:得到插入位置的前驱节点和后继节点
Node<E> pred, succ;
//如果插入位置为尾部,前驱节点为last,后继节点为null
if (index == size) {
succ = null;
pred = last;
}
//否则,调用node()方法得到后继节点,再得到前驱节点
else {
succ = node(index);
pred = succ.prev;
}
// 4:遍历数据将数据插入
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//创建新节点
Node<E> newNode = new Node<>(pred, e, null);
//如果插入位置在链表头部
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
//如果插入位置在尾部,重置last节点
if (succ == null) {
last = pred;
}
//否则,将插入的链表与先前链表连接起来
else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
```
上面可以看出addAll方法通常包括下面四个步骤:
1. 检查index范围是否在size之内
2. toArray()方法把集合的数据存到对象数组中
3. 得到插入位置的前驱和后继节点
4. 遍历数据,将数据插入到指定位置
**addFirst(E e):** 将元素添加到链表头部
```java
public void addFirst(E e) {
linkFirst(e);
}
```
```java
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);//新建节点,以头节点为后继节点
first = newNode;
//如果链表为空,last节点也指向该节点
if (f == null)
last = newNode;
//否则,将头节点的前驱指针指向新节点,也就是指向前一个元素
else
f.prev = newNode;
size++;
modCount++;
}
```
**addLast(E e):** 将元素添加到链表尾部,与 **add(E e)** 方法一样
```java
public void addLast(E e) {
linkLast(e);
}
```
### <font face="楷体" id="3.3">根据位置取数据的方法</font>
**get(int index):** 根据指定索引返回数据
```java
public E get(int index) {
//检查index范围是否在size之内
checkElementIndex(index);
//调用Node(index)去找到index对应的node然后返回它的值
return node(index).item;
}
```
**获取头节点(index=0)数据方法:**
```java
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E element() {
return getFirst();
}
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
```
**区别:**
getFirst(),element(),peek(),peekFirst()
这四个获取头结点方法的区别在于对链表为空时的处理,是抛出异常还是返回null,其中**getFirst()** 和**element()** 方法将会在链表为空时,抛出异常
element()方法的内部就是使用getFirst()实现的。它们会在链表为空时,抛出NoSuchElementException
**获取尾节点(index=-1)数据方法:**
```java
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
```
**两者区别:**
**getLast()** 方法在链表为空时,会抛出**NoSuchElementException**,而**peekLast()** 则不会,只是会返回 **null**。
### <font face="楷体" id="3.4">根据对象得到索引的方法</font>
**int indexOf(Object o):** 从头遍历找
```java
public int indexOf(Object o) {
int index = 0;
if (o == null) {
//从头遍历
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
//从头遍历
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
```
**int lastIndexOf(Object o):** 从尾遍历找
```java
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
//从尾遍历
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
//从尾遍历
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
```
### <font face="楷体" id="3.5">检查链表是否包含某对象的方法:</font>
**contains(Object o):** 检查对象o是否存在于链表中
```java
public boolean contains(Object o) {
return indexOf(o) != -1;
}
```
### <font face="楷体" id="3.6">删除方法</font>
**remove()** ,**removeFirst(),pop():** 删除头节点
```
public E pop() {
return removeFirst();
}
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
```
**removeLast(),pollLast():** 删除尾节点
```java
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
```
**区别:** removeLast()在链表为空时将抛出NoSuchElementException,而pollLast()方法返回null。
**remove(Object o):** 删除指定元素
```java
public boolean remove(Object o) {
//如果删除对象为null
if (o == null) {
//从头开始遍历
for (Node<E> x = first; x != null; x = x.next) {
//找到元素
if (x.item == null) {
//从链表中移除找到的元素
unlink(x);
return true;
}
}
} else {
//从头开始遍历
for (Node<E> x = first; x != null; x = x.next) {
//找到元素
if (o.equals(x.item)) {
//从链表中移除找到的元素
unlink(x);
return true;
}
}
}
return false;
}
```
当删除指定对象时,只需调用remove(Object o)即可,不过该方法一次只会删除一个匹配的对象,如果删除了匹配对象,返回true,否则false。
unlink(Node<E> x) 方法:
```java
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;//得到后继节点
final Node<E> prev = x.prev;//得到前驱节点
//删除前驱指针
if (prev == null) {
first = next;//如果删除的节点是头节点,令头节点指向该节点的后继节点
} else {
prev.next = next;//将前驱节点的后继节点指向后继节点
x.prev = null;
}
//删除后继指针
if (next == null) {
last = prev;//如果删除的节点是尾节点,令尾节点指向该节点的前驱节点
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
```
**remove(int index)**:删除指定位置的元素
```java
public E remove(int index) {
//检查index范围
checkElementIndex(index);
//将节点删除
return unlink(node(index));
}
```
## <font face="楷体" id="4">LinkedList类常用方法测试</font>
```java
package list;
import java.util.Iterator;
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] srgs) {
//创建存放int类型的linkedList
LinkedList<Integer> linkedList = new LinkedList<>();
/************************** linkedList的基本操作 ************************/
linkedList.addFirst(0); // 添加元素到列表开头
linkedList.add(1); // 在列表结尾添加元素
linkedList.add(2, 2); // 在指定位置添加元素
linkedList.addLast(3); // 添加元素到列表结尾
System.out.println("LinkedList(直接输出的): " + linkedList);
System.out.println("getFirst()获得第一个元素: " + linkedList.getFirst()); // 返回此列表的第一个元素
System.out.println("getLast()获得第最后一个元素: " + linkedList.getLast()); // 返回此列表的最后一个元素
System.out.println("removeFirst()删除第一个元素并返回: " + linkedList.removeFirst()); // 移除并返回此列表的第一个元素
System.out.println("removeLast()删除最后一个元素并返回: " + linkedList.removeLast()); // 移除并返回此列表的最后一个元素
System.out.println("After remove:" + linkedList);
System.out.println("contains()方法判断列表是否包含1这个元素:" + linkedList.contains(1)); // 判断此列表包含指定元素,如果是,则返回true
System.out.println("该linkedList的大小 : " + linkedList.size()); // 返回此列表的元素个数
/************************** 位置访问操作 ************************/
System.out.println("-----------------------------------------");
linkedList.set(1, 3); // 将此列表中指定位置的元素替换为指定的元素
System.out.println("After set(1, 3):" + linkedList);
System.out.println("get(1)获得指定位置(这里为1)的元素: " + linkedList.get(1)); // 返回此列表中指定位置处的元素
/************************** Search操作 ************************/
System.out.println("-----------------------------------------");
linkedList.add(3);
System.out.println("indexOf(3): " + linkedList.indexOf(3)); // 返回此列表中首次出现的指定元素的索引
System.out.println("lastIndexOf(3): " + linkedList.lastIndexOf(3));// 返回此列表中最后出现的指定元素的索引
/************************** Queue操作 ************************/
System.out.println("-----------------------------------------");
System.out.println("peek(): " + linkedList.peek()); // 获取但不移除此列表的头
System.out.println("element(): " + linkedList.element()); // 获取但不移除此列表的头
linkedList.poll(); // 获取并移除此列表的头
System.out.println("After poll():" + linkedList);
linkedList.remove();
System.out.println("After remove():" + linkedList); // 获取并移除此列表的头
linkedList.offer(4);
System.out.println("After offer(4):" + linkedList); // 将指定元素添加到此列表的末尾
/************************** Deque操作 ************************/
System.out.println("-----------------------------------------");
linkedList.offerFirst(2); // 在此列表的开头插入指定的元素
System.out.println("After offerFirst(2):" + linkedList);
linkedList.offerLast(5); // 在此列表末尾插入指定的元素
System.out.println("After offerLast(5):" + linkedList);
System.out.println("peekFirst(): " + linkedList.peekFirst()); // 获取但不移除此列表的第一个元素
System.out.println("peekLast(): " + linkedList.peekLast()); // 获取但不移除此列表的第一个元素
linkedList.pollFirst(); // 获取并移除此列表的第一个元素
System.out.println("After pollFirst():" + linkedList);
linkedList.pollLast(); // 获取并移除此列表的最后一个元素
System.out.println("After pollLast():" + linkedList);
linkedList.push(2); // 将元素推入此列表所表示的堆栈(插入到列表的头)
System.out.println("After push(2):" + linkedList);
linkedList.pop(); // 从此列表所表示的堆栈处弹出一个元素(获取并移除列表第一个元素)
System.out.println("After pop():" + linkedList);
linkedList.add(3);
linkedList.removeFirstOccurrence(3); // 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表)
System.out.println("After removeFirstOccurrence(3):" + linkedList);
linkedList.removeLastOccurrence(3); // 从此列表中移除最后一次出现的指定元素(从尾部到头部遍历列表)
System.out.println("After removeFirstOccurrence(3):" + linkedList);
/************************** 遍历操作 ************************/
System.out.println("-----------------------------------------");
linkedList.clear();
for (int i = 0; i < 100000; i++) {
linkedList.add(i);
}
// 迭代器遍历
long start = System.currentTimeMillis();
Iterator<Integer> iterator = linkedList.iterator();
while (iterator.hasNext()) {
iterator.next();
}
long end = System.currentTimeMillis();
System.out.println("Iterator:" + (end - start) + " ms");
// 顺序遍历(随机遍历)
start = System.currentTimeMillis();
for (int i = 0; i < linkedList.size(); i++) {
linkedList.get(i);
}
end = System.currentTimeMillis();
System.out.println("for:" + (end - start) + " ms");
// 另一种for循环遍历
start = System.currentTimeMillis();
for (Integer i : linkedList)
;
end = System.currentTimeMillis();
System.out.println("for2:" + (end - start) + " ms");
// 通过pollFirst()或pollLast()来遍历LinkedList
LinkedList<Integer> temp1 = new LinkedList<>();
temp1.addAll(linkedList);
start = System.currentTimeMillis();
while (temp1.size() != 0) {
temp1.pollFirst();
}
end = System.currentTimeMillis();
System.out.println("pollFirst()或pollLast():" + (end - start) + " ms");
// 通过removeFirst()或removeLast()来遍历LinkedList
LinkedList<Integer> temp2 = new LinkedList<>();
temp2.addAll(linkedList);
start = System.currentTimeMillis();
while (temp2.size() != 0) {
temp2.removeFirst();
}
end = System.currentTimeMillis();
System.out.println("removeFirst()或removeLast():" + (end - start) + " ms");
}
}
```
> 原文地址: https://juejin.im/post/5c94a123f265da610916081f。
## JVM 配置常用参数
1. 堆参数;
2. 回收器参数;
3. 项目中常用配置;
4. 常用组合;
### 堆参数

### 回收器参数

如上表所示,目前**主要有串行、并行和并发三种**,对于大内存的应用而言,串行的性能太低,因此使用到的主要是并行和并发两种。并行和并发 GC 的策略通过 `UseParallelGC `和` UseConcMarkSweepGC` 来指定,还有一些细节的配置参数用来配置策略的执行方式。例如:`XX:ParallelGCThreads`, `XX:CMSInitiatingOccupancyFraction` 等。 通常:Young 区对象回收只可选择并行(耗时间),Old 区选择并发(耗 CPU)。
### 项目中常用配置
> 备注:在Java8中永久代的参数`-XX:PermSize` 和`-XX:MaxPermSize`已经失效。

### 常用组合

## 常用 GC 调优策略
1. GC 调优原则;
2. GC 调优目的;
3. GC 调优策略;
### GC 调优原则
在调优之前,我们需要记住下面的原则:
> 多数的 Java 应用不需要在服务器上进行 GC 优化; 多数导致 GC 问题的 Java 应用,都不是因为我们参数设置错误,而是代码问题; 在应用上线之前,先考虑将机器的 JVM 参数设置到最优(最适合); 减少创建对象的数量; 减少使用全局变量和大对象; GC 优化是到最后不得已才采用的手段; 在实际使用中,分析 GC 情况优化代码比优化 GC 参数要多得多。
### GC 调优目的
将转移到老年代的对象数量降低到最小; 减少 GC 的执行时间。
### GC 调优策略
**策略 1:**将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
**策略 2:**大对象进入老年代,虽然大部分情况下,将对象分配在新生代是合理的。但是对于大对象这种做法却值得商榷,大对象如果首次在新生代分配可能会出现空间不足导致很多年龄不够的小对象被分配的老年代,破坏新生代的对象结构,可能会出现频繁的 full gc。因此,对于大对象,可以设置直接进入老年代(当然短命的大对象对于垃圾回收来说简直就是噩梦)。`-XX:PretenureSizeThreshold` 可以设置直接进入老年代的对象大小。
**策略 3:**合理设置进入老年代对象的年龄,`-XX:MaxTenuringThreshold` 设置对象进入老年代的年龄大小,减少老年代的内存占用,降低 full gc 发生的频率。
**策略 4:**设置稳定的堆大小,堆大小设置有两个参数:`-Xms` 初始化堆大小,`-Xmx` 最大堆大小。
**策略5:**注意: 如果满足下面的指标,**则一般不需要进行 GC 优化:**
> MinorGC 执行时间不到50ms; Minor GC 执行不频繁,约10秒一次; Full GC 执行时间不到1s; Full GC 执行频率不算频繁,不低于10分钟1次。
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
<!-- TOC -->
- [Java 内存区域详解](#java-内存区域详解)
- [写在前面 (常见面试题)](#写在前面-常见面试题)
- [基本问题](#基本问题)
- [拓展问题](#拓展问题)
- [一 概述](#一-概述)
- [二 运行时数据区域](#二-运行时数据区域)
- [2.1 程序计数器](#21-程序计数器)
- [2.2 Java 虚拟机栈](#22-java-虚拟机栈)
- [2.3 本地方法栈](#23-本地方法栈)
- [2.4 堆](#24-堆)
- [2.5 方法区](#25-方法区)
- [2.5.1 方法区和永久代的关系](#251-方法区和永久代的关系)
- [2.5.2 常用参数](#252-常用参数)
- [2.5.3 为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?](#253-为什么要将永久代-permgen-替换为元空间-metaspace-呢)
- [2.6 运行时常量池](#26-运行时常量池)
- [2.7 直接内存](#27-直接内存)
- [三 HotSpot 虚拟机对象探秘](#三-hotspot-虚拟机对象探秘)
- [3.1 对象的创建](#31-对象的创建)
- [Step1:类加载检查](#step1类加载检查)
- [Step2:分配内存](#step2分配内存)
- [Step3:初始化零值](#step3初始化零值)
- [Step4:设置对象头](#step4设置对象头)
- [Step5:执行 init 方法](#step5执行-init-方法)
- [3.2 对象的内存布局](#32-对象的内存布局)
- [3.3 对象的访问定位](#33-对象的访问定位)
- [四 重点补充内容](#四--重点补充内容)
- [4.1 String 类和常量池](#41-string-类和常量池)
- [4.2 String s1 = new String("abc");这句话创建了几个字符串对象?](#42-string-s1--new-stringabc这句话创建了几个字符串对象)
- [4.3 8 种基本类型的包装类和常量池](#43-8-种基本类型的包装类和常量池)
- [参考](#参考)
- [公众号](#公众号)
<!-- /TOC -->
# Java 内存区域详解
如果没有特殊说明,都是针对的是 HotSpot 虚拟机。
## 写在前面 (常见面试题)
### 基本问题
- **介绍下 Java 内存区域(运行时数据区)**
- **Java 对象的创建过程(五步,建议能默写出来并且要知道每一步虚拟机做了什么)**
- **对象的访问定位的两种方式(句柄和直接指针两种方式)**
### 拓展问题
- **String 类和常量池**
- **8 种基本类型的包装类和常量池**
## 一 概述
对于 Java 程序员来说,在虚拟机自动内存管理机制下,不再需要像 C/C++程序开发程序员这样为每一个 new 操作去写对应的 delete/free 操作,不容易出现内存泄漏和内存溢出问题。正是因为 Java 程序员把内存控制权利交给 Java 虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎样使用内存的,那么排查错误将会是一个非常艰巨的任务。
## 二 运行时数据区域
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。JDK. 1.8 和之前的版本略有不同,下面会介绍到。
**JDK 1.8 之前:**
<div align="center">
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3/JVM运行时数据区域.png" width="600px"/>
</div>
**JDK 1.8 :**
<div align="center">
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3Java运行时数据区域JDK1.8.png" width="600px"/>
</div>
**线程私有的:**
- 程序计数器
- 虚拟机栈
- 本地方法栈
**线程共享的:**
- 堆
- 方法区
- 直接内存 (非运行时数据区的一部分)
### 2.1 程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。**字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。**
另外,**为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。**
**从上面的介绍中我们知道程序计数器主要有两个作用:**
1. 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
2. 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
**注意:程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。**
### 2.2 Java 虚拟机栈
**与程序计数器一样,Java 虚拟机栈也是线程私有的,它的生命周期和线程相同,描述的是 Java 方法执行的内存模型,每次方法调用的数据都是通过栈传递的。**
**Java 内存可以粗糙的区分为堆内存(Heap)和栈内存 (Stack),其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。** (实际上,Java 虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。)
**局部变量表主要存放了编译器可知的各种数据类型**(boolean、byte、char、short、int、float、long、double)、**对象引用**(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
**Java 虚拟机栈会出现两种错误:StackOverFlowError 和 OutOfMemoryError。**
- **StackOverFlowError:** 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。
- **OutOfMemoryError:** 若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出 OutOfMemoryError 错误。
Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
**扩展:那么方法/函数如何调用?**
Java 栈可用类比数据结构中栈,Java 栈中保存的主要内容是栈帧,每一次函数调用都会有一个对应的栈帧被压入 Java 栈,每一个函数调用结束后,都会有一个栈帧被弹出。
Java 方法有两种返回方式:
1. return 语句。
2. 抛出异常。
不管哪种返回方式都会导致栈帧被弹出。
### 2.3 本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是: **虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种错误。
### 2.4 堆
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。**此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。**
Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(Garbage Collected Heap)**.从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。**进一步划分的目的是更好地回收内存,或者更快地分配内存。**
在 JDK 7 版本及JDK 7 版本之前,堆内存被通常被分为下面三部分:
1. 新生代内存(Young Generation)
2. 老生代(Old Generation)
3. 永生代(Permanent Generation)

JDK 8 版本之后方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。

**上图所示的 Eden 区、两个 Survivor 区都属于新生代(为了区分,这两个 Survivor 区域按照顺序被命名为 from 和 to),中间一层属于老年代。**
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
> 修正([issue552](https://github.com/Snailclimb/JavaGuide/issues/552)):“Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值”。
>
> **动态年龄计算的代码如下**
>
> ```c++
> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
> //survivor_capacity是survivor空间的大小
> size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
> size_t total = 0;
> uint age = 1;
> while (age < table_size) {
> total += sizes[age];//sizes数组是每个年龄段对象大小
> if (total > desired_survivor_size) break;
> age++;
> }
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
> ...
> }
>
> ```
>
>
堆这里最容易出现的就是 OutOfMemoryError 错误,并且出现这种错误之后的表现形式还会有几种,比如:
1. **`OutOfMemoryError: GC Overhead Limit Exceeded`** : 当JVM花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。
2. **`java.lang.OutOfMemoryError: Java heap space`** :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发`java.lang.OutOfMemoryError: Java heap space` 错误。(和本机物理内存无关,和你配置的对内存大小有关!)
3. ......
### 2.5 方法区
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 **Java 虚拟机规范把方法区描述为堆的一个逻辑部分**,但是它却有一个别名叫做 **Non-Heap(非堆)**,目的应该是与 Java 堆区分开来。
方法区也被称为永久代。很多人都会分不清方法区和永久代的关系,为此我也查阅了文献。
#### 2.5.1 方法区和永久代的关系
> 《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。 **方法区和永久代的关系很像 Java 中接口和类的关系,类实现了接口,而永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。** 也就是说,永久代是 HotSpot 的概念,方法区是 Java 虚拟机规范中的定义,是一种规范,而永久代是一种实现,一个是标准一个是实现,其他的虚拟机实现并没有永久代这一说法。
#### 2.5.2 常用参数
JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
```java
-XX:PermSize=N //方法区 (永久代) 初始大小
-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
```
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
下面是一些常用参数:
```java
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小
```
与永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
#### 2.5.3 为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?
1. 整个永久代有一个 JVM 本身设置固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
>当你元空间溢出时会得到如下错误: `java.lang.OutOfMemoryError: MetaSpace`
你可以使用 `-XX:MaxMetaspaceSize` 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。`-XX:MetaspaceSize` 调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
2. 元空间里面存放的是类的元数据,这样加载多少类的元数据就不由 `MaxPermSize` 控制了, 而由系统的实际可用空间来控制,这样能加载的类就更多了。
3. 在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了。
### 2.6 运行时常量池
运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池信息(用于存放编译期生成的各种字面量和符号引用)
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 错误。
**JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**
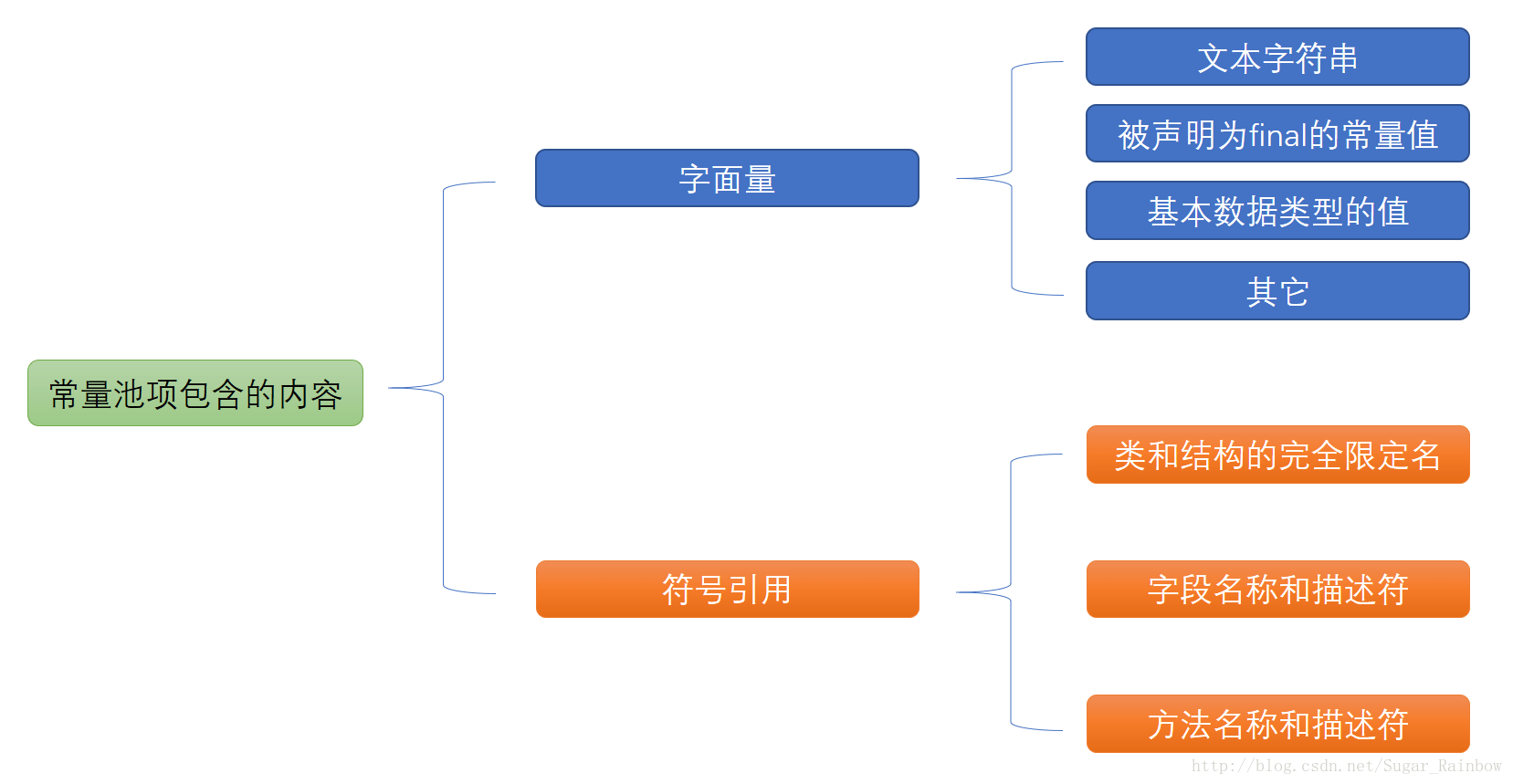
——图片来源:https://blog.csdn.net/wangbiao007/article/details/78545189
### 2.7 直接内存
**直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。**
JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)** 与**缓存区(Buffer)** 的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
本机直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
## 三 HotSpot 虚拟机对象探秘
通过上面的介绍我们大概知道了虚拟机的内存情况,下面我们来详细的了解一下 HotSpot 虚拟机在 Java 堆中对象分配、布局和访问的全过程。
### 3.1 对象的创建
下图便是 Java 对象的创建过程,我建议最好是能默写出来,并且要掌握每一步在做什么。

#### Step1:类加载检查
虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
#### Step2:分配内存
在**类加载检查**通过后,接下来虚拟机将为新生对象**分配内存**。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。**分配方式**有 **“指针碰撞”** 和 **“空闲列表”** 两种,**选择那种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定**。
**内存分配的两种方式:(补充内容,需要掌握)**
选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而 Java 堆内存是否规整,取决于 GC 收集器的算法是"标记-清除",还是"标记-整理"(也称作"标记-压缩"),值得注意的是,复制算法内存也是规整的

**内存分配并发问题(补充内容,需要掌握)**
在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
- **CAS+失败重试:** CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。**虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。**
- **TLAB:** 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
#### Step3:初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
#### Step4:设置对象头
初始化零值完成之后,**虚拟机要对对象进行必要的设置**,例如这个对象是那个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 **这些信息存放在对象头中。** 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
#### Step5:执行 init 方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,`<init>` 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 `<init>` 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
### 3.2 对象的内存布局
在 Hotspot 虚拟机中,对象在内存中的布局可以分为 3 块区域:**对象头**、**实例数据**和**对齐填充**。
**Hotspot 虚拟机的对象头包括两部分信息**,**第一部分用于存储对象自身的自身运行时数据**(哈希码、GC 分代年龄、锁状态标志等等),**另一部分是类型指针**,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是那个类的实例。
**实例数据部分是对象真正存储的有效信息**,也是在程序中所定义的各种类型的字段内容。
**对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。** 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
### 3.3 对象的访问定位
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;

2. **直接指针:** 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。

**这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。**
## 四 重点补充内容
### 4.1 String 类和常量池
**String 对象的两种创建方式:**
```java
String str1 = "abcd";//先检查字符串常量池中有没有"abcd",如果字符串常量池中没有,则创建一个,然后 str1 指向字符串常量池中的对象,如果有,则直接将 str1 指向"abcd"";
String str2 = new String("abcd");//堆中创建一个新的对象
String str3 = new String("abcd");//堆中创建一个新的对象
System.out.println(str1==str2);//false
System.out.println(str2==str3);//false
```
这两种不同的创建方法是有差别的。
- 第一种方式是在常量池中拿对象;
- 第二种方式是直接在堆内存空间创建一个新的对象。
记住一点:**只要使用 new 方法,便需要创建新的对象。**
再给大家一个图应该更容易理解,图片来源:<https://www.journaldev.com/797/what-is-java-string-pool>:
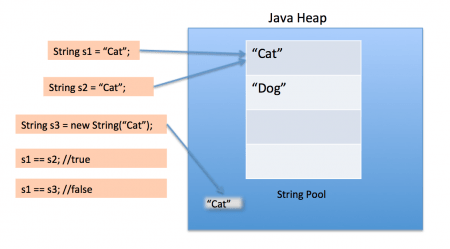
**String 类型的常量池比较特殊。它的主要使用方法有两种:**
- 直接使用双引号声明出来的 String 对象会直接存储在常量池中。
- 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方法。String.intern() 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,JDK1.7之前(不包含1.7)的处理方式是在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用,JDK1.7以及之后的处理方式是在常量池中记录此字符串的引用,并返回该引用。
```java
String s1 = new String("计算机");
String s2 = s1.intern();
String s3 = "计算机";
System.out.println(s2);//计算机
System.out.println(s1 == s2);//false,因为一个是堆内存中的 String 对象一个是常量池中的 String 对象,
System.out.println(s3 == s2);//true,因为两个都是常量池中的 String 对象
```
**字符串拼接:**
```java
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";//常量池中的对象
String str4 = str1 + str2; //在堆上创建的新的对象
String str5 = "string";//常量池中的对象
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false
```

尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
**将创建 1 或 2 个字符串。如果池中已存在字符串常量“abc”,则只会在堆空间创建一个字符串常量“abc”。如果池中没有字符串常量“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。**
**验证:**
```java
String s1 = new String("abc");// 堆内存的地址值
String s2 = "abc";
System.out.println(s1 == s2);// 输出 false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。
System.out.println(s1.equals(s2));// 输出 true
```
**结果:**
```
false
true
```
### 4.3 8 种基本类型的包装类和常量池
- **Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;这 5 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象。** 为啥把缓存设置为[-128,127]区间?([参见issue/461](https://github.com/Snailclimb/JavaGuide/issues/461))性能和资源之间的权衡。
- **两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。**
```java
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// 输出 true
Integer i11 = 333;
Integer i22 = 333;
System.out.println(i11 == i22);// 输出 false
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// 输出 false
```
**Integer 缓存源代码:**
```java
/**
*此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
```
**应用场景:**
1. Integer i1=40;Java 在编译的时候会直接将代码封装成 Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
2. Integer i1 = new Integer(40);这种情况下会创建新的对象。
```java
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);//输出 false
```
**Integer 比较更丰富的一个例子:**
```java
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
System.out.println("i1=i2 " + (i1 == i2));
System.out.println("i1=i2+i3 " + (i1 == i2 + i3));
System.out.println("i1=i4 " + (i1 == i4));
System.out.println("i4=i5 " + (i4 == i5));
System.out.println("i4=i5+i6 " + (i4 == i5 + i6));
System.out.println("40=i5+i6 " + (40 == i5 + i6));
```
结果:
```
i1=i2 true
i1=i2+i3 true
i1=i4 false
i4=i5 false
i4=i5+i6 true
40=i5+i6 true
```
解释:
语句 i4 == i5 + i6,因为+这个操作符不适用于 Integer 对象,首先 i5 和 i6 进行自动拆箱操作,进行数值相加,即 i4 == 40。然后 Integer 对象无法与数值进行直接比较,所以 i4 自动拆箱转为 int 值 40,最终这条语句转为 40 == 40 进行数值比较。
## 参考
- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
- 《实战 java 虚拟机》
- <https://docs.oracle.com/javase/specs/index.html>
- <http://www.pointsoftware.ch/en/under-the-hood-runtime-data-areas-javas-memory-model/>
- <https://dzone.com/articles/jvm-permgen-%E2%80%93-where-art-thou>
- <https://stackoverflow.com/questions/9095748/method-area-and-permgen>
- 深入解析String#intern<https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html>
## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。

点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
<!-- TOC -->
- [JDK 监控和故障处理工具总结](#jdk-监控和故障处理工具总结)
- [JDK 命令行工具](#jdk-命令行工具)
- [`jps`:查看所有 Java 进程](#jps查看所有-java-进程)
- [`jstat`: 监视虚拟机各种运行状态信息](#jstat-监视虚拟机各种运行状态信息)
- [` jinfo`: 实时地查看和调整虚拟机各项参数](#-jinfo-实时地查看和调整虚拟机各项参数)
- [`jmap`:生成堆转储快照](#jmap生成堆转储快照)
- [**`jhat`**: 分析 heapdump 文件](#jhat-分析-heapdump-文件)
- [**`jstack`** :生成虚拟机当前时刻的线程快照](#jstack-生成虚拟机当前时刻的线程快照)
- [JDK 可视化分析工具](#jdk-可视化分析工具)
- [JConsole:Java 监视与管理控制台](#jconsolejava-监视与管理控制台)
- [连接 Jconsole](#连接-jconsole)
- [查看 Java 程序概况](#查看-java-程序概况)
- [内存监控](#内存监控)
- [线程监控](#线程监控)
- [Visual VM:多合一故障处理工具](#visual-vm多合一故障处理工具)
<!-- /TOC -->
# JDK 监控和故障处理工具总结
## JDK 命令行工具
这些命令在 JDK 安装目录下的 bin 目录下:
- **`jps`** (JVM Process Status): 类似 UNIX 的 `ps` 命令。用户查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息;
- **`jstat`**( JVM Statistics Monitoring Tool): 用于收集 HotSpot 虚拟机各方面的运行数据;
- **`jinfo`** (Configuration Info for Java) : Configuration Info forJava,显示虚拟机配置信息;
- **`jmap`** (Memory Map for Java) :生成堆转储快照;
- **`jhat`** (JVM Heap Dump Browser ) : 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果;
- **`jstack`** (Stack Trace for Java):生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。
### `jps`:查看所有 Java 进程
`jps`(JVM Process Status) 命令类似 UNIX 的 `ps` 命令。
`jps`:显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)。`jps -q` :只输出进程的本地虚拟机唯一 ID。
```powershell
C:\Users\SnailClimb>jps
7360 NettyClient2
17396
7972 Launcher
16504 Jps
17340 NettyServer
```
`jps -l`:输出主类的全名,如果进程执行的是 Jar 包,输出 Jar 路径。
```powershell
C:\Users\SnailClimb>jps -l
7360 firstNettyDemo.NettyClient2
17396
7972 org.jetbrains.jps.cmdline.Launcher
16492 sun.tools.jps.Jps
17340 firstNettyDemo.NettyServer
```
`jps -v`:输出虚拟机进程启动时 JVM 参数。
`jps -m`:输出传递给 Java 进程 main() 函数的参数。
### `jstat`: 监视虚拟机各种运行状态信息
jstat(JVM Statistics Monitoring Tool) 使用于监视虚拟机各种运行状态信息的命令行工具。 它可以显示本地或者远程(需要远程主机提供 RMI 支持)虚拟机进程中的类信息、内存、垃圾收集、JIT 编译等运行数据,在没有 GUI,只提供了纯文本控制台环境的服务器上,它将是运行期间定位虚拟机性能问题的首选工具。
**`jstat` 命令使用格式:**
```powershell
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
```
比如 `jstat -gc -h3 31736 1000 10`表示分析进程 id 为 31736 的 gc 情况,每隔 1000ms 打印一次记录,打印 10 次停止,每 3 行后打印指标头部。
**常见的 option 如下:**
- `jstat -class vmid` :显示 ClassLoader 的相关信息;
- `jstat -compiler vmid` :显示 JIT 编译的相关信息;
- `jstat -gc vmid` :显示与 GC 相关的堆信息;
- `jstat -gccapacity vmid` :显示各个代的容量及使用情况;
- `jstat -gcnew vmid` :显示新生代信息;
- `jstat -gcnewcapcacity vmid` :显示新生代大小与使用情况;
- `jstat -gcold vmid` :显示老年代和永久代的信息;
- `jstat -gcoldcapacity vmid` :显示老年代的大小;
- `jstat -gcpermcapacity vmid` :显示永久代大小;
- `jstat -gcutil vmid` :显示垃圾收集信息;
另外,加上 `-t`参数可以在输出信息上加一个 Timestamp 列,显示程序的运行时间。
### ` jinfo`: 实时地查看和调整虚拟机各项参数
`jinfo vmid` :输出当前 jvm 进程的全部参数和系统属性 (第一部分是系统的属性,第二部分是 JVM 的参数)。
`jinfo -flag name vmid` :输出对应名称的参数的具体值。比如输出 MaxHeapSize、查看当前 jvm 进程是否开启打印 GC 日志 ( `-XX:PrintGCDetails` :详细 GC 日志模式,这两个都是默认关闭的)。
```powershell
C:\Users\SnailClimb>jinfo -flag MaxHeapSize 17340
-XX:MaxHeapSize=2124414976
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:-PrintGC
```
使用 jinfo 可以在不重启虚拟机的情况下,可以动态的修改 jvm 的参数。尤其在线上的环境特别有用,请看下面的例子:
`jinfo -flag [+|-]name vmid` 开启或者关闭对应名称的参数。
```powershell
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:-PrintGC
C:\Users\SnailClimb>jinfo -flag +PrintGC 17340
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:+PrintGC
```
### `jmap`:生成堆转储快照
`jmap`(Memory Map for Java)命令用于生成堆转储快照。 如果不使用 `jmap` 命令,要想获取 Java 堆转储,可以使用 `“-XX:+HeapDumpOnOutOfMemoryError”` 参数,可以让虚拟机在 OOM 异常出现之后自动生成 dump 文件,Linux 命令下可以通过 `kill -3` 发送进程退出信号也能拿到 dump 文件。
`jmap` 的作用并不仅仅是为了获取 dump 文件,它还可以查询 finalizer 执行队列、Java 堆和永久代的详细信息,如空间使用率、当前使用的是哪种收集器等。和`jinfo`一样,`jmap`有不少功能在 Windows 平台下也是受限制的。
示例:将指定应用程序的堆快照输出到桌面。后面,可以通过 jhat、Visual VM 等工具分析该堆文件。
```powershell
C:\Users\SnailClimb>jmap -dump:format=b,file=C:\Users\SnailClimb\Desktop\heap.hprof 17340
Dumping heap to C:\Users\SnailClimb\Desktop\heap.hprof ...
Heap dump file created
```
### **`jhat`**: 分析 heapdump 文件
**`jhat`** 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果。
```powershell
C:\Users\SnailClimb>jhat C:\Users\SnailClimb\Desktop\heap.hprof
Reading from C:\Users\SnailClimb\Desktop\heap.hprof...
Dump file created Sat May 04 12:30:31 CST 2019
Snapshot read, resolving...
Resolving 131419 objects...
Chasing references, expect 26 dots..........................
Eliminating duplicate references..........................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
```
访问 <http://localhost:7000/>
### **`jstack`** :生成虚拟机当前时刻的线程快照
`jstack`(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合.
生成线程快照的目的主要是定位线程长时间出现停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的原因。线程出现停顿的时候通过`jstack`来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者在等待些什么资源。
**下面是一个线程死锁的代码。我们下面会通过 `jstack` 命令进行死锁检查,输出死锁信息,找到发生死锁的线程。**
```java
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "线程 2").start();
}
}
```
Output
```
Thread[线程 1,5,main]get resource1
Thread[线程 2,5,main]get resource2
Thread[线程 1,5,main]waiting get resource2
Thread[线程 2,5,main]waiting get resource1
```
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过` Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
**通过 `jstack` 命令分析:**
```powershell
C:\Users\SnailClimb>jps
13792 KotlinCompileDaemon
7360 NettyClient2
17396
7972 Launcher
8932 Launcher
9256 DeadLockDemo
10764 Jps
17340 NettyServer
C:\Users\SnailClimb>jstack 9256
```
输出的部分内容如下:
```powershell
Found one Java-level deadlock:
=============================
"线程 2":
waiting to lock monitor 0x000000000333e668 (object 0x00000000d5efe1c0, a java.lang.Object),
which is held by "线程 1"
"线程 1":
waiting to lock monitor 0x000000000333be88 (object 0x00000000d5efe1d0, a java.lang.Object),
which is held by "线程 2"
Java stack information for the threads listed above:
===================================================
"线程 2":
at DeadLockDemo.lambda$main$1(DeadLockDemo.java:31)
- waiting to lock <0x00000000d5efe1c0> (a java.lang.Object)
- locked <0x00000000d5efe1d0> (a java.lang.Object)
at DeadLockDemo$$Lambda$2/1078694789.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
"线程 1":
at DeadLockDemo.lambda$main$0(DeadLockDemo.java:16)
- waiting to lock <0x00000000d5efe1d0> (a java.lang.Object)
- locked <0x00000000d5efe1c0> (a java.lang.Object)
at DeadLockDemo$$Lambda$1/1324119927.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.
```
可以看到 `jstack` 命令已经帮我们找到发生死锁的线程的具体信息。
## JDK 可视化分析工具
### JConsole:Java 监视与管理控制台
JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监视本地及远程服务器的 java 进程的内存使用情况。你可以在控制台输出`console`命令启动或者在 JDK 目录下的 bin 目录找到`jconsole.exe`然后双击启动。
#### 连接 Jconsole

如果需要使用 JConsole 连接远程进程,可以在远程 Java 程序启动时加上下面这些参数:
```properties
-Djava.rmi.server.hostname=外网访问 ip 地址
-Dcom.sun.management.jmxremote.port=60001 //监控的端口号
-Dcom.sun.management.jmxremote.authenticate=false //关闭认证
-Dcom.sun.management.jmxremote.ssl=false
```
在使用 JConsole 连接时,远程进程地址如下:
```
外网访问 ip 地址:60001
```
#### 查看 Java 程序概况

#### 内存监控
JConsole 可以显示当前内存的详细信息。不仅包括堆内存/非堆内存的整体信息,还可以细化到 eden 区、survivor 区等的使用情况,如下图所示。
点击右边的“执行 GC(G)”按钮可以强制应用程序执行一个 Full GC。
> - **新生代 GC(Minor GC)**:指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
> - **老年代 GC(Major GC/Full GC)**:指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。

#### 线程监控
类似我们前面讲的 `jstack` 命令,不过这个是可视化的。
最下面有一个"检测死锁 (D)"按钮,点击这个按钮可以自动为你找到发生死锁的线程以及它们的详细信息 。

### Visual VM:多合一故障处理工具
VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java 应用程序的详细信息。在 VisualVM 的图形用户界面中,您可以方便、快捷地查看多个 Java 应用程序的相关信息。Visual VM 官网:<https://visualvm.github.io/> 。Visual VM 中文文档:<https://visualvm.github.io/documentation.html>。
下面这段话摘自《深入理解 Java 虚拟机》。
> VisualVM(All-in-One Java Troubleshooting Tool)是到目前为止随 JDK 发布的功能最强大的运行监视和故障处理程序,官方在 VisualVM 的软件说明中写上了“All-in-One”的描述字样,预示着他除了运行监视、故障处理外,还提供了很多其他方面的功能,如性能分析(Profiling)。VisualVM 的性能分析功能甚至比起 JProfiler、YourKit 等专业且收费的 Profiling 工具都不会逊色多少,而且 VisualVM 还有一个很大的优点:不需要被监视的程序基于特殊 Agent 运行,因此他对应用程序的实际性能的影响很小,使得他可以直接应用在生产环境中。这个优点是 JProfiler、YourKit 等工具无法与之媲美的。
VisualVM 基于 NetBeans 平台开发,因此他一开始就具备了插件扩展功能的特性,通过插件扩展支持,VisualVM 可以做到:
- **显示虚拟机进程以及进程的配置、环境信息(jps、jinfo)。**
- **监视应用程序的 CPU、GC、堆、方法区以及线程的信息(jstat、jstack)。**
- **dump 以及分析堆转储快照(jmap、jhat)。**
- **方法级的程序运行性能分析,找到被调用最多、运行时间最长的方法。**
- **离线程序快照:收集程序的运行时配置、线程 dump、内存 dump 等信息建立一个快照,可以将快照发送开发者处进行 Bug 反馈。**
- **其他 plugins 的无限的可能性......**
这里就不具体介绍 VisualVM 的使用,如果想了解的话可以看:
- <https://visualvm.github.io/documentation.html>
- <https://www.ibm.com/developerworks/cn/java/j-lo-visualvm/index.html>
## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。

无论什么级别的Java从业者,JVM都是进阶时必须迈过的坎。不管是工作还是面试中,JVM都是必考题。如果不懂JVM的话,薪酬会非常吃亏(近70%的面试者挂在JVM上了)。
掌握了JVM机制,就等于学会了深层次解决问题的方法。对于Java开发者而言,只有熟悉底层虚拟机的运行机制,才能通过JVM日志深入到字节码的层次去分析排查问题,发现隐性的系统缺陷,进而提升系统性能。
一些技术人员开发工具用得很熟练,触及JVM问题时却是模棱两可,甚至连内存模型和内存区域,HotSpot和JVM规范,都混淆不清。工作很长时间,在生产时还在用缺省参数来直接启动,以致系统运行时出现性能、稳定性等问题时束手无措,不知该如何追踪排查。久而久之,这对自己的职业成长是极为不利的。
掌握JVM,是深入Java技术栈的必经之路。
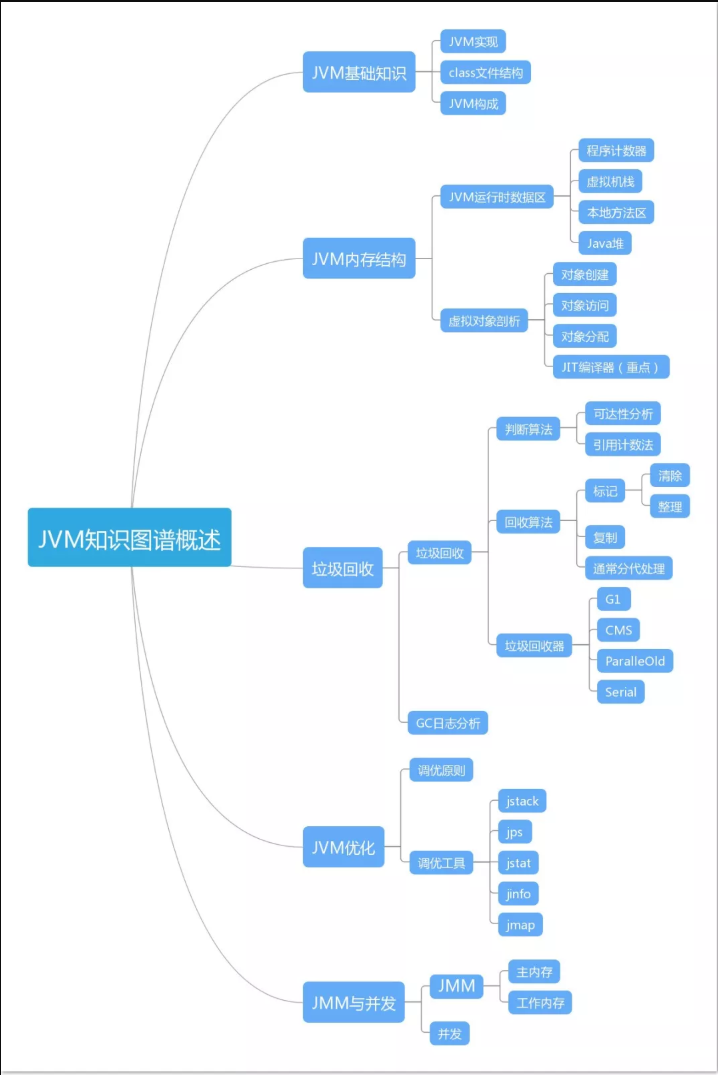
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
<!-- TOC -->
- [JVM 垃圾回收](#jvm-垃圾回收)
- [写在前面](#写在前面)
- [本节常见面试题](#本节常见面试题)
- [本文导火索](#本文导火索)
- [1 揭开 JVM 内存分配与回收的神秘面纱](#1--揭开-jvm-内存分配与回收的神秘面纱)
- [1.1 对象优先在 eden 区分配](#11-对象优先在-eden-区分配)
- [1.2 大对象直接进入老年代](#12-大对象直接进入老年代)
- [1.3 长期存活的对象将进入老年代](#13-长期存活的对象将进入老年代)
- [1.4 动态对象年龄判定](#14-动态对象年龄判定)
- [2 对象已经死亡?](#2-对象已经死亡)
- [2.1 引用计数法](#21-引用计数法)
- [2.2 可达性分析算法](#22-可达性分析算法)
- [2.3 再谈引用](#23-再谈引用)
- [2.4 不可达的对象并非“非死不可”](#24-不可达的对象并非非死不可)
- [2.5 如何判断一个常量是废弃常量](#25-如何判断一个常量是废弃常量)
- [2.6 如何判断一个类是无用的类](#26-如何判断一个类是无用的类)
- [3 垃圾收集算法](#3-垃圾收集算法)
- [3.1 标记-清除算法](#31-标记-清除算法)
- [3.2 复制算法](#32-复制算法)
- [3.3 标记-整理算法](#33-标记-整理算法)
- [3.4 分代收集算法](#34-分代收集算法)
- [4 垃圾收集器](#4-垃圾收集器)
- [4.1 Serial 收集器](#41-serial-收集器)
- [4.2 ParNew 收集器](#42-parnew-收集器)
- [4.3 Parallel Scavenge 收集器](#43-parallel-scavenge-收集器)
- [4.4.Serial Old 收集器](#44serial-old-收集器)
- [4.5 Parallel Old 收集器](#45-parallel-old-收集器)
- [4.6 CMS 收集器](#46-cms-收集器)
- [4.7 G1 收集器](#47-g1-收集器)
- [参考](#参考)
<!-- /TOC -->
# JVM 垃圾回收
## 写在前面
### 本节常见面试题
问题答案在文中都有提到
- 如何判断对象是否死亡(两种方法)。
- 简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区别、使用软引用能带来的好处)。
- 如何判断一个常量是废弃常量
- 如何判断一个类是无用的类
- 垃圾收集有哪些算法,各自的特点?
- HotSpot 为什么要分为新生代和老年代?
- 常见的垃圾回收器有哪些?
- 介绍一下 CMS,G1 收集器。
- Minor Gc 和 Full GC 有什么不同呢?
### 本文导火索
当需要排查各种内存溢出问题、当垃圾收集成为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
## 1 揭开 JVM 内存分配与回收的神秘面纱
Java 的自动内存管理主要是针对对象内存的回收和对象内存的分配。同时,Java 自动内存管理最核心的功能是 **堆** 内存中对象的分配与回收。
Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(Garbage Collected Heap)**.从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。**进一步划分的目的是更好地回收内存,或者更快地分配内存。**
**堆空间的基本结构:**
<div align="center">
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3堆结构.png" width="400px"/>
</div>
上图所示的 eden 区、s0("From") 区、s1("To") 区都属于新生代,tentired 区属于老年代。大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s1("To"),并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。经过这次GC后,Eden区和"From"区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的"To"就是上次GC前的“From”,新的"From"就是上次GC前的"To"。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,"To"区被填满之后,会将所有对象移动到老年代中。

### 1.1 对象优先在 eden 区分配
目前主流的垃圾收集器都会采用分代回收算法,因此需要将堆内存分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
大多数情况下,对象在新生代中 eden 区分配。当 eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.下面我们来进行实际测试以下。
在测试之前我们先来看看 **Minor GC 和 Full GC 有什么不同呢?**
- **新生代 GC(Minor GC)**:指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
- **老年代 GC(Major GC/Full GC)**:指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
**测试:**
```java
public class GCTest {
public static void main(String[] args) {
byte[] allocation1, allocation2;
allocation1 = new byte[30900*1024];
//allocation2 = new byte[900*1024];
}
}
```
通过以下方式运行:

添加的参数:`-XX:+PrintGCDetails`
运行结果 (红色字体描述有误,应该是对应于 JDK1.7 的永久代):
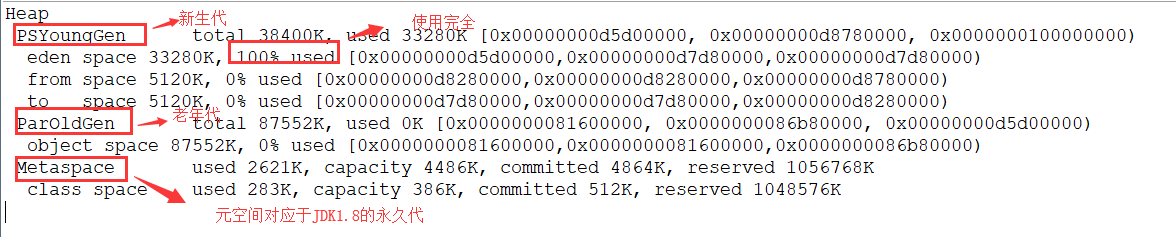
从上图我们可以看出 eden 区内存几乎已经被分配完全(即使程序什么也不做,新生代也会使用 2000 多 k 内存)。假如我们再为 allocation2 分配内存会出现什么情况呢?
```java
allocation2 = new byte[900*1024];
```
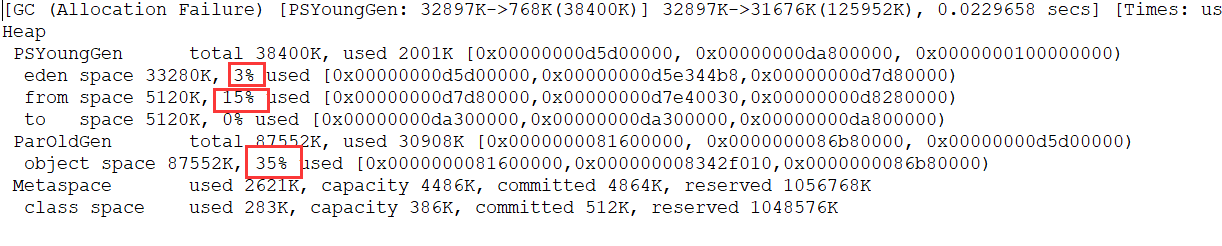
**简单解释一下为什么会出现这种情况:** 因为给 allocation2 分配内存的时候 eden 区内存几乎已经被分配完了,我们刚刚讲了当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC.GC 期间虚拟机又发现 allocation1 无法存入 Survivor 空间,所以只好通过 **分配担保机制** 把新生代的对象提前转移到老年代中去,老年代上的空间足够存放 allocation1,所以不会出现 Full GC。执行 Minor GC 后,后面分配的对象如果能够存在 eden 区的话,还是会在 eden 区分配内存。可以执行如下代码验证:
```java
public class GCTest {
public static void main(String[] args) {
byte[] allocation1, allocation2,allocation3,allocation4,allocation5;
allocation1 = new byte[32000*1024];
allocation2 = new byte[1000*1024];
allocation3 = new byte[1000*1024];
allocation4 = new byte[1000*1024];
allocation5 = new byte[1000*1024];
}
}
```
### 1.2 大对象直接进入老年代
大对象就是需要大量连续内存空间的对象(比如:字符串、数组)。
**为什么要这样呢?**
为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。
### 1.3 长期存活的对象将进入老年代
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。为了做到这一点,虚拟机给每个对象一个对象年龄(Age)计数器。
如果对象在 Eden 出生并经过第一次 Minor GC 后仍然能够存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间中,并将对象年龄设为 1.对象在 Survivor 中每熬过一次 MinorGC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
### 1.4 动态对象年龄判定
为了更好的适应不同程序的内存情况,虚拟机不是永远要求对象年龄必须达到了某个值才能进入老年代,如果 Survivor 空间中相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无需达到要求的年龄。
## 2 对象已经死亡?
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断那些对象已经死亡(即不能再被任何途径使用的对象)。
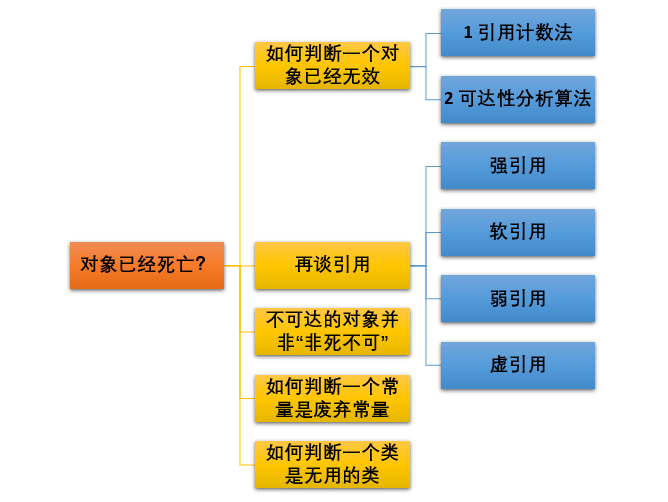
### 2.1 引用计数法
给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计数器就减 1;任何时候计数器为 0 的对象就是不可能再被使用的。
**这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。** 所谓对象之间的相互引用问题,如下面代码所示:除了对象 objA 和 objB 相互引用着对方之外,这两个对象之间再无任何引用。但是他们因为互相引用对方,导致它们的引用计数器都不为 0,于是引用计数算法无法通知 GC 回收器回收他们。
```java
public class ReferenceCountingGc {
Object instance = null;
public static void main(String[] args) {
ReferenceCountingGc objA = new ReferenceCountingGc();
ReferenceCountingGc objB = new ReferenceCountingGc();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
}
}
```
### 2.2 可达性分析算法
这个算法的基本思想就是通过一系列的称为 **“GC Roots”** 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。
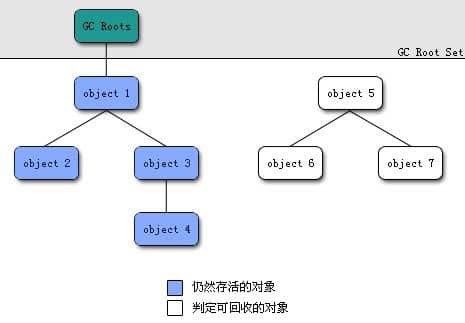
### 2.3 再谈引用
无论是通过引用计数法判断对象引用数量,还是通过可达性分析法判断对象的引用链是否可达,判定对象的存活都与“引用”有关。
JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
**1.强引用(StrongReference)**
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
**2.软引用(SoftReference)**
如果一个对象只具有软引用,那就类似于**可有可无的生活用品**。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。
**3.弱引用(WeakReference)**
如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
**4.虚引用(PhantomReference)**
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
**虚引用主要用来跟踪对象被垃圾回收的活动**。
**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为**软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生**。
### 2.4 不可达的对象并非“非死不可”
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
### 2.5 如何判断一个常量是废弃常量
运行时常量池主要回收的是废弃的常量。那么,我们如何判断一个常量是废弃常量呢?
假如在常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池。
注意:我们在 [可能是把 Java 内存区域讲的最清楚的一篇文章 ](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484303&idx=1&sn=af0fd436cef755463f59ee4dd0720cbd&chksm=fd9855eecaefdcf8d94ac581cfda4e16c8a730bda60c3b50bc55c124b92f23b6217f7f8e58d5&token=506869459&lang=zh_CN#rd) 也讲了 JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。
### 2.6 如何判断一个类是无用的类
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 **“无用的类”** :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
## 3 垃圾收集算法

### 3.1 标记-清除算法
该算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
1. **效率问题**
2. **空间问题(标记清除后会产生大量不连续的碎片)**
<img src="http://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-8-27/63707281.jpg" alt="公众号" width="500px">
### 3.2 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
<img src="http://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-8-27/90984624.jpg" alt="公众号" width="500px">
### 3.3 标记-整理算法
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
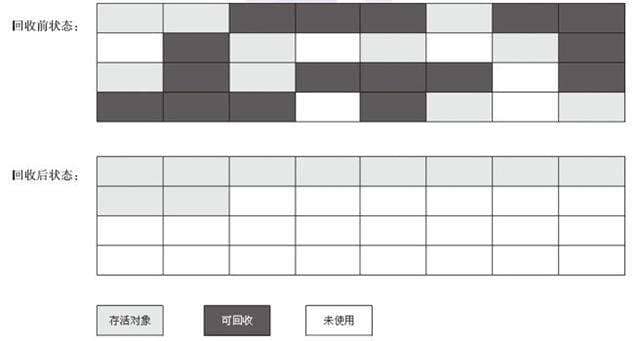
### 3.4 分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
**延伸面试问题:** HotSpot 为什么要分为新生代和老年代?
根据上面的对分代收集算法的介绍回答。
## 4 垃圾收集器

**如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。**
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
### 4.1 Serial 收集器
Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
**新生代采用复制算法,老年代采用标记-整理算法。**
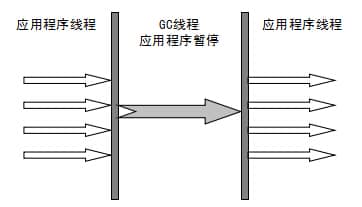
虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它**简单而高效(与其他收集器的单线程相比)**。Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择。
### 4.2 ParNew 收集器
**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
**新生代采用复制算法,老年代采用标记-整理算法。**

它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
**并行和并发概念补充:**
- **并行(Parallel)** :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- **并发(Concurrent)**:指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
### 4.3 Parallel Scavenge 收集器
Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和ParNew都一样。 **那么它有什么特别之处呢?**
```
-XX:+UseParallelGC
使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC
使用 Parallel 收集器+ 老年代并行
```
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
**新生代采用复制算法,老年代采用标记-整理算法。**

### 4.4.Serial Old 收集器
**Serial 收集器的老年代版本**,它同样是一个单线程收集器。它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
### 4.5 Parallel Old 收集器
**Parallel Scavenge 收集器的老年代版本**。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
### 4.6 CMS 收集器
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。**
**CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
从名字中的**Mark Sweep**这两个词可以看出,CMS 收集器是一种 **“标记-清除”算法**实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
- **初始标记:** 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
- **并发标记:** 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
- **重新标记:** 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
- **并发清除:** 开启用户线程,同时 GC 线程开始对为标记的区域做清扫。
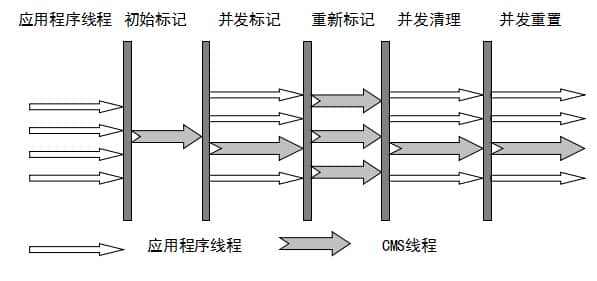
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:**并发收集、低停顿**。但是它有下面三个明显的缺点:
- **对 CPU 资源敏感;**
- **无法处理浮动垃圾;**
- **它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。**
### 4.7 G1 收集器
**G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.**
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备一下特点:
- **并行与并发**:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
- **分代收集**:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
- **空间整合**:与 CMS 的“标记--清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
G1 收集器的运作大致分为以下几个步骤:
- **初始标记**
- **并发标记**
- **最终标记**
- **筛选回收**
**G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)**。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 GF 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
## 参考
- 《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第二版》
- https://my.oschina.net/hosee/blog/644618
- <https://docs.oracle.com/javase/specs/jvms/se8/html/index.html>
## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。

> 本文由 JavaGuide 翻译自 https://www.baeldung.com/jvm-parameters,并对文章进行了大量的完善补充。翻译不易,如需转载请注明出处为: 作者: 。
## 1.概述
在本篇文章中,你将掌握最常用的 JVM 参数配置。如果对于下面提到了一些概念比如堆、
## 2.堆内存相关
>Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。**此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。**
>
### 2.1.显式指定堆内存`–Xms`和`-Xmx`
与性能有关的最常见实践之一是根据应用程序要求初始化堆内存。如果我们需要指定最小和最大堆大小(推荐显示指定大小),以下参数可以帮助你实现:
```
-Xms<heap size>[unit]
-Xmx<heap size>[unit]
```
- **heap size** 表示要初始化内存的具体大小。
- **unit** 表示要初始化内存的单位。单位为***“ g”*** (GB) 、***“ m”***(MB)、***“ k”***(KB)。
举个栗子🌰,如果我们要为JVM分配最小2 GB和最大5 GB的堆内存大小,我们的参数应该这样来写:
```
-Xms2G -Xmx5G
```
### 2.2.显式新生代内存(Young Ceneration)
根据[Oracle官方文档](https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html),在堆总可用内存配置完成之后,第二大影响因素是为 `Young Generation` 在堆内存所占的比例。默认情况下,YG 的最小大小为 1310 *MB*,最大大小为*无限制*。
一共有两种指定 新生代内存(Young Ceneration)大小的方法:
**1.通过`-XX:NewSize`和`-XX:MaxNewSize`指定**
```
-XX:NewSize=<young size>[unit]
-XX:MaxNewSize=<young size>[unit]
```
举个栗子🌰,如果我们要为 新生代分配 最小256m 的内存,最大 1024m的内存我们的参数应该这样来写:
```
-XX:NewSize=256m
-XX:MaxNewSize=1024m
```
**2.通过`-Xmn<young size>[unit] `指定**
举个栗子🌰,如果我们要为 新生代分配256m的内存(NewSize与MaxNewSize设为一致),我们的参数应该这样来写:
```
-Xmn256m
```
GC 调优策略中很重要的一条经验总结是这样说的:
> 将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
另外,你还可以通过**`-XX:NewRatio=<int>`**来设置新生代和老年代内存的比值。
比如下面的参数就是设置新生代(包括Eden和两个Survivor区)与老年代的比值为1。也就是说:新生代与老年代所占比值为1:1,新生代占整个堆栈的 1/2。
```
-XX:NewRatio=1
```
### 2.3.显示指定永久代/元空间的大小
**从Java 8开始,如果我们没有指定 Metaspace 的大小,随着更多类的创建,虚拟机会耗尽所有可用的系统内存(永久代并不会出现这种情况)。**
JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
```java
-XX:PermSize=N //方法区 (永久代) 初始大小
-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
```
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
**JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。**
下面是一些常用参数:
```java
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
```
## 3.垃圾收集相关
### 3.1.垃圾回收器
为了提高应用程序的稳定性,选择正确的[垃圾收集](http://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html)算法至关重要。
JVM具有四种类型的*GC*实现:
- 串行垃圾收集器
- 并行垃圾收集器
- CMS垃圾收集器
- G1垃圾收集器
可以使用以下参数声明这些实现:
```
-XX:+UseSerialGC
-XX:+UseParallelGC
-XX:+USeParNewGC
-XX:+UseG1GC
```
有关*垃圾回收*实施的更多详细信息,请参见[此处](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/jvm/JVM%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6.md)。
### 3.2.GC记录
为了严格监控应用程序的运行状况,我们应该始终检查JVM的*垃圾回收*性能。最简单的方法是以人类可读的格式记录*GC*活动。
使用以下参数,我们可以记录*GC*活动:
```
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=< number of log files >
-XX:GCLogFileSize=< file size >[ unit ]
-Xloggc:/path/to/gc.log
```
## 推荐阅读
- [CMS GC 默认新生代是多大?](https://www.jianshu.com/p/832fc4d4cb53)
- [CMS GC启动参数优化配置](https://www.cnblogs.com/hongdada/p/10277782.html)
- [从实际案例聊聊Java应用的GC优化-美团技术团队](https://tech.meituan.com/2017/12/29/jvm-optimize.html)
- [JVM性能调优详解](https://www.choupangxia.com/2019/11/11/interview-jvm-gc-08/) (2019-11-11)
- [JVM参数使用手册](https://segmentfault.com/a/1190000010603813)
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
<!-- TOC -->
- [回顾一下类加载过程](#回顾一下类加载过程)
- [类加载器总结](#类加载器总结)
- [双亲委派模型](#双亲委派模型)
- [双亲委派模型介绍](#双亲委派模型介绍)
- [双亲委派模型实现源码分析](#双亲委派模型实现源码分析)
- [双亲委派模型的好处](#双亲委派模型的好处)
- [如果我们不想要双亲委派模型怎么办?](#如果我们不想要双亲委派模型怎么办)
- [自定义类加载器](#自定义类加载器)
- [推荐](#推荐)
<!-- /TOC -->
> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
## 回顾一下类加载过程
类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
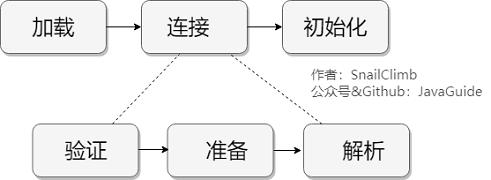
一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。
所有的类都由类加载器加载,加载的作用就是将 .class文件加载到内存。
## 类加载器总结
JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`:
1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/lib`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载目录 `%JRE_HOME%/lib/ext` 目录下的jar包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的jar包。
3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
## 双亲委派模型
### 双亲委派模型介绍
每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 **双亲委派模型** 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。加载的时候,首先会把该请求委派该父类加载器的 `loadClass()` 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 `BootstrapClassLoader` 中。当父类加载器无法处理时,才由自己来处理。当父类加载器为null时,会使用启动类加载器 `BootstrapClassLoader` 作为父类加载器。

每个类加载都有一个父类加载器,我们通过下面的程序来验证。
```java
public class ClassLoaderDemo {
public static void main(String[] args) {
System.out.println("ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader());
System.out.println("The Parent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent());
System.out.println("The GrandParent of ClassLodarDemo's ClassLoader is " + ClassLoaderDemo.class.getClassLoader().getParent().getParent());
}
}
```
Output
```
ClassLodarDemo's ClassLoader is sun.misc.Launcher$AppClassLoader@18b4aac2
The Parent of ClassLodarDemo's ClassLoader is sun.misc.Launcher$ExtClassLoader@1b6d3586
The GrandParent of ClassLodarDemo's ClassLoader is null
```
`AppClassLoader`的父类加载器为`ExtClassLoader`
`ExtClassLoader`的父类加载器为null,**null并不代表`ExtClassLoader`没有父类加载器,而是 `BootstrapClassLoader`** 。
其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mother ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方API文档对这部分的描述如下:
>The Java platform uses a delegation model for loading classes. **The basic idea is that every class loader has a "parent" class loader.** When loading a class, a class loader first "delegates" the search for the class to its parent class loader before attempting to find the class itself.
### 双亲委派模型实现源码分析
双亲委派模型的实现代码非常简单,逻辑非常清晰,都集中在 `java.lang.ClassLoader` 的 `loadClass()` 中,相关代码如下所示。
```java
private final ClassLoader parent;
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查请求的类是否已经被加载过
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {//父加载器不为空,调用父加载器loadClass()方法处理
c = parent.loadClass(name, false);
} else {//父加载器为空,使用启动类加载器 BootstrapClassLoader 加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
//抛出异常说明父类加载器无法完成加载请求
}
if (c == null) {
long t1 = System.nanoTime();
//自己尝试加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
```
### 双亲委派模型的好处
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
### 如果我们不想用双亲委派模型怎么办?
为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重写 `loadClass()` 即可。
## 自定义类加载器
除了 `BootstrapClassLoader` 其他类加载器均由 Java 实现且全部继承自`java.lang.ClassLoader`。如果我们要自定义自己的类加载器,很明显需要继承 `ClassLoader`。
## 推荐阅读
- <https://blog.csdn.net/xyang81/article/details/7292380>
- <https://juejin.im/post/5c04892351882516e70dcc9b>
- <http://gityuan.com/2016/01/24/java-classloader/>
### 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。

点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
<!-- TOC -->
- [类加载过程](#类加载过程)
- [加载](#加载)
- [验证](#验证)
- [准备](#准备)
- [解析](#解析)
- [初始化](#初始化)
<!-- /TOC -->
> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
# 类加载过程
Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。

## 加载
类加载过程的第一步,主要完成下面3件事情:
1. 通过全类名获取定义此类的二进制字节流
2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
3. 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
虚拟机规范多上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
**一个非数组类的加载阶段(加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式(重写一个类加载器的 `loadClass()` 方法)。数组类型不通过类加载器创建,它由 Java 虚拟机直接创建。**
类加载器、双亲委派模型也是非常重要的知识点,这部分内容会在后面的文章中单独介绍到。
加载阶段和连接阶段的部分内容是交叉进行的,加载阶段尚未结束,连接阶段可能就已经开始了。
## 验证

## 准备
**准备阶段是正式为类变量分配内存并设置类变量初始值的阶段**,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
1. 这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
2. 这里所设置的初始值"通常情况"下是数据类型默认的零值(如0、0L、null、false等),比如我们定义了`public static int value=111` ,那么 value 变量在准备阶段的初始值就是 0 而不是111(初始化阶段才会赋值)。特殊情况:比如给 value 变量加上了 fianl 关键字`public static final int value=111` ,那么准备阶段 value 的值就被赋值为 111。
**基本数据类型的零值:**
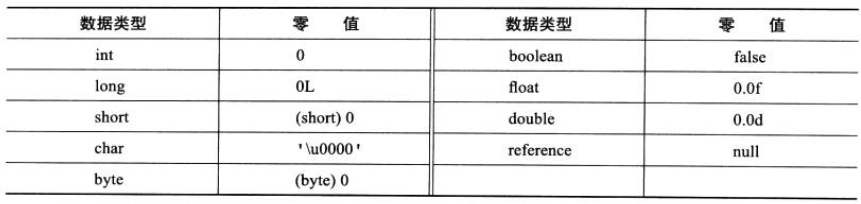
## 解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
符号引用就是一组符号来描述目标,可以是任何字面量。**直接引用**就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。在程序实际运行时,只有符号引用是不够的,举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方发表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
综上,解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,也就是得到类或者字段、方法在内存中的指针或者偏移量。
## 初始化
初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 `<clinit> ()`方法的过程。
对于`<clinit>()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `<clinit>()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
对于初始化阶段,虚拟机严格规范了有且只有5种情况下,必须对类进行初始化:
1. 当遇到 new 、 getstatic、putstatic或invokestatic 这4条直接码指令时,比如 new 一个类,读取一个静态字段(未被 final 修饰)、或调用一个类的静态方法时。
2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时 ,如果类没初始化,需要触发其初始化。
3. 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
4. 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 main 方法的那个类),虚拟机会先初始化这个类。
5. 当使用 JDK1.7 的动态动态语言时,如果一个 MethodHandle 实例的最后解析结构为 REF_getStatic、REF_putStatic、REF_invokeStatic、的方法句柄,并且这个句柄没有初始化,则需要先触发器初始化。
**参考**
- 《深入理解Java虚拟机》
- 《实战Java虚拟机》
- <https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-5.html>
## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。

点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
<!-- TOC -->
- [类文件结构](#类文件结构)
- [一 概述](#一-概述)
- [二 Class 文件结构总结](#二-class-文件结构总结)
- [2.1 魔数](#21-魔数)
- [2.2 Class 文件版本](#22-class-文件版本)
- [2.3 常量池](#23-常量池)
- [2.4 访问标志](#24-访问标志)
- [2.5 当前类索引,父类索引与接口索引集合](#25-当前类索引父类索引与接口索引集合)
- [2.6 字段表集合](#26-字段表集合)
- [2.7 方法表集合](#27-方法表集合)
- [2.8 属性表集合](#28-属性表集合)
- [参考](#参考)
<!-- /TOC -->
# 类文件结构
## 一 概述
在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行在 Java 虚拟机之上。下图展示了不同的语言被不同的编译器编译成`.class`文件最终运行在 Java 虚拟机之上。`.class`文件的二进制格式可以使用 [WinHex](https://www.x-ways.net/winhex/) 查看。
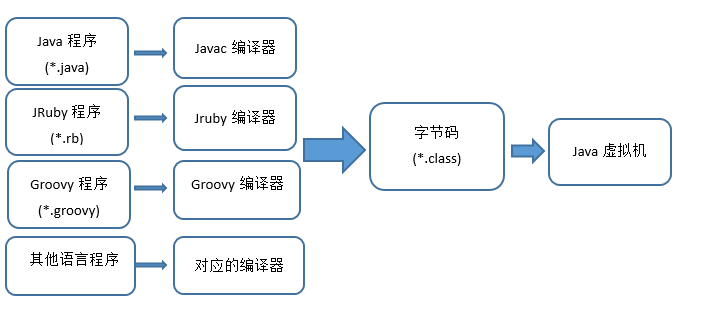
**可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。**
## 二 Class 文件结构总结
根据 Java 虚拟机规范,类文件由单个 ClassFile 结构组成:
```java
ClassFile {
u4 magic; //Class 文件的标志
u2 minor_version;//Class 的小版本号
u2 major_version;//Class 的大版本号
u2 constant_pool_count;//常量池的数量
cp_info constant_pool[constant_pool_count-1];//常量池
u2 access_flags;//Class 的访问标记
u2 this_class;//当前类
u2 super_class;//父类
u2 interfaces_count;//接口
u2 interfaces[interfaces_count];//一个类可以实现多个接口
u2 fields_count;//Class 文件的字段属性
field_info fields[fields_count];//一个类会可以有个字段
u2 methods_count;//Class 文件的方法数量
method_info methods[methods_count];//一个类可以有个多个方法
u2 attributes_count;//此类的属性表中的属性数
attribute_info attributes[attributes_count];//属性表集合
}
```
下面详细介绍一下 Class 文件结构涉及到的一些组件。
**Class文件字节码结构组织示意图** (之前在网上保存的,非常不错,原出处不明):

### 2.1 魔数
```java
u4 magic; //Class 文件的标志
```
每个 Class 文件的头四个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。
程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
### 2.2 Class 文件版本
```java
u2 minor_version;//Class 的小版本号
u2 major_version;//Class 的大版本号
```
紧接着魔数的四个字节存储的是 Class 文件的版本号:第五和第六是**次版本号**,第七和第八是**主版本号**。
高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
### 2.3 常量池
```java
u2 constant_pool_count;//常量池的数量
cp_info constant_pool[constant_pool_count-1];//常量池
```
紧接着主次版本号之后的是常量池,常量池的数量是 constant_pool_count-1(**常量池计数器是从1开始计数的,将第0项常量空出来是有特殊考虑的,索引值为0代表“不引用任何一个常量池项”**)。
常量池主要存放两大常量:字面量和符号引用。字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。而符号引用则属于编译原理方面的概念。包括下面三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
常量池中每一项常量都是一个表,这14种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
| 类型 | 标志(tag) | 描述 |
| :------------------------------: | :---------: | :--------------------: |
| CONSTANT_utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | 整形字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
| CONSTANT_MothodType_info | 16 | 标志方法类型 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
### 2.4 访问标志
在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 public 或者 abstract 类型,如果是类的话是否声明为 final 等等。
类访问和属性修饰符:
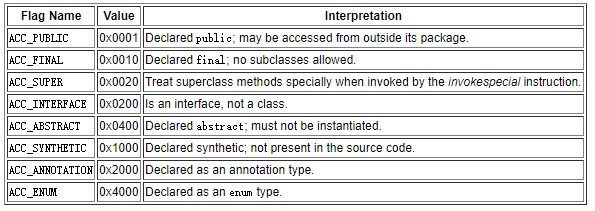
我们定义了一个 Employee 类
```java
package top.snailclimb.bean;
public class Employee {
...
}
```
通过`javap -v class类名` 指令来看一下类的访问标志。
### 2.5 当前类索引,父类索引与接口索引集合
```java
u2 this_class;//当前类
u2 super_class;//父类
u2 interfaces_count;//接口
u2 interfaces[interfaces_count];//一个雷可以实现多个接口
```
**类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。**
**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按`implents`(如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
### 2.6 字段表集合
```java
u2 fields_count;//Class 文件的字段的个数
field_info fields[fields_count];//一个类会可以有个字段
```
字段表(field info)用于描述接口或类中声明的变量。字段包括类级变量以及实例变量,但不包括在方法内部声明的局部变量。
**field info(字段表) 的结构:**

- **access_flags:** 字段的作用域(`public` ,`private`,`protected`修饰符),是实例变量还是类变量(`static`修饰符),可否被序列化(transient 修饰符),可变性(final),可见性(volatile 修饰符,是否强制从主内存读写)。
- **name_index:** 对常量池的引用,表示的字段的名称;
- **descriptor_index:** 对常量池的引用,表示字段和方法的描述符;
- **attributes_count:** 一个字段还会拥有一些额外的属性,attributes_count 存放属性的个数;
- **attributes[attributes_count]:** 存放具体属性具体内容。
上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型这些都是无法固定的,只能引用常量池中常量来描述。
**字段的 access_flags 的取值:**

### 2.7 方法表集合
```java
u2 methods_count;//Class 文件的方法的数量
method_info methods[methods_count];//一个类可以有个多个方法
```
methods_count 表示方法的数量,而 method_info 表示的方法表。
Class 文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式。方法表的结构如同字段表一样,依次包括了访问标志、名称索引、描述符索引、属性表集合几项。
**method_info(方法表的) 结构:**

**方法表的 access_flag 取值:**

注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
### 2.8 属性表集合
```java
u2 attributes_count;//此类的属性表中的属性数
attribute_info attributes[attributes_count];//属性表集合
```
在 Class 文件,字段表,方法表中都可以携带自己的属性表集合,以用于描述某些场景专有的信息。与 Class 文件中其它的数据项目要求的顺序、长度和内容不同,属性表集合的限制稍微宽松一些,不再要求各个属性表具有严格的顺序,并且只要不与已有的属性名重复,任何人实现的编译器都可以向属性表中写 入自己定义的属性信息,Java 虚拟机运行时会忽略掉它不认识的属性。
## 参考
- <https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html>
- <https://coolshell.cn/articles/9229.html>
- <https://blog.csdn.net/luanlouis/article/details/39960815>
- 《实战 Java 虚拟机》
## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。




























 3914
3914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











