







GitHub

本文采用Kafka 0.8.2版本
Overview
Producer的作用
生成数据(消息),并将其发送到Kafka集群(brokers)中。
将消息发送给谁
Producer在向Kafka集群发送消息时,需要指定发送到哪一个topic中。除此之外,还可以指定发送到该topic的哪一个partition中。
消息的构成
一条消息的成分,从逻辑上来说,由真正的消息数据(message)和元数据(metadata)构成;从数据结构上来说(以org.apache.kafka.clients.producer. ProducerRecord为例),由以下四个field构成:
public final class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final K key;
private final V value;
}Examples
简单的入门例子
首先考虑最简单的应用,我们在生成messages时,只指定target topic,并且只生成消息的value域。
package cn.gridx.kafka.apis.scala.producer
import java.util.Properties
import kafka.consumer._
import kafka.message.MessageAndMetadata
import org.apache.kafka.clients.producer.{RecordMetadata, ProducerRecord, KafkaProducer, ProducerConfig}
import org.apache.kafka.common.serialization.StringSerializer
/**
* Created by tao on 6/30/15.
*/
object SimpleProducerExample {
// 这个Topic在创建时设置了5个partitions
def Topic = "my-3rd-topic"
def Broker_List = "ecs2:9092,ecs3:9092,ecs4:9092"
def ZK_CONN = "ecs1:2181,ecs2:2181,ecs3:2181"
def Group_ID = "group-SimpleProducerExample"
def main(args: Array[String]): Unit = {
startProducer
Thread.sleep(3000)
println("发送完成")
startConsumer
}
/**
* producer 产生messages
*/
def startProducer() {
val props = new Properties()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, Broker_List)
// 必须要为`key`和`value`设置`serializer`,即使我们不使用key也必须要设置
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
// 由于我们不产生key,只产生String类型的value
// 因此prducer的类型是 KafkaProducer[Nothing, String]
val producer = new KafkaProducer[Nothing, String](props)
for (i <- 0 to 10) {
// 只指定topic
val record: ProducerRecord[Nothing, String] = new ProducerRecord(Topic, s"val-${i}")
producer.send(record)
}
producer.close // 完了必须关闭producer
}
/**
* consumer 消费 messages
*/
def startConsumer(): Unit = {
val props = new Properties()
props.put("zookeeper.connect", ZK_CONN)
props.put("group.id", Group_ID)
props.put("zookeeper.session.timeout.ms", "400")
props.put("zookeeper.sync.time.ms", "200")
props.put("auto.commit.interval.ms", "1000")
val config = new ConsumerConfig(props)
val topicCountMap = Map(Topic -> 1)
val connector: ConsumerConnector = Consumer.create(config)
val topicStreamsMap: collection.Map[String, List[KafkaStream[Array[Byte], Array[Byte]]]]
= connector.createMessageStreams(topicCountMap)
val stream: KafkaStream[Array[Byte], Array[Byte]] = topicStreamsMap.get(Topic).get.head
val it: ConsumerIterator[Array[Byte], Array[Byte]] = stream.iterator()
while (it.hasNext) {
val data: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next
println(s"value -> [${new String(data.message)}] | partition -> [${data.partition}] | " +
s"offset -> [${data.offset}] | topic -> [${data.topic}]")
}
}
}运行结果:
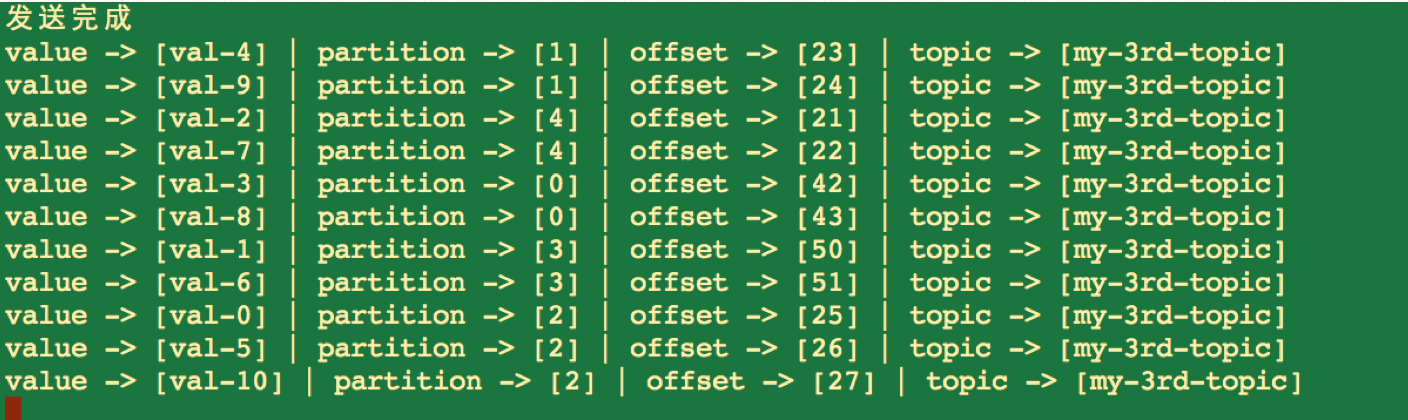
可见,我们没有使用key,消息被随机地分配到了Topic的各个partition中。
控制消息发往哪一个partition
现在,我们要为message加上key,并且控制每一条消息发到哪一个partition。
在Kafka 0.8.0 中,对于一条消息的target partition的设置是通过partitioner.class这个配置来实现的。但是在0.8.2版本中,这个配置项不再起作用了,而是通过在创建ProducerRecord时直接指明:
/**
* Creates a record to be sent to a specified topic and partition
*
* @param topic The topic the record will be appended to
* @param partition The partition to which the record should be sent
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, Integer partition, K key, V value) {
if (topic == null)
throw new IllegalArgumentException("Topic cannot be null");
this.topic = topic;
this.partition = partition;
this.key = key;
this.value = value;
}
下面看一个例子
package cn.gridx.kafka.apis.scala.producer
import java.util.Properties
import kafka.consumer._
import kafka.message.MessageAndMetadata
import org.apache.kafka.clients.producer.{ProducerRecord, KafkaProducer, ProducerConfig}
import org.apache.kafka.common.serialization.StringSerializer
/**
* Producer 可以为每一个record 的partition number
*
* 在0.8.2之前,可以通过 `partitioner.class` 来设置
*
* 在0.8.2,这个配置不起作用了,而是改为在构造`ProducerRecord`
* 时直接填入 partition number
*
* Created by tao on 6/29/15.
*/
object CustomPartitionerExample {
// 这个Topic在创建时设置了5个partitions
def Topic = "my-3rd-topic"
def Broker_List = "ecs2:9092,ecs3:9092,ecs4:9092"
def ZK_CONN = "ecs1:2181,ecs2:2181,ecs3:2181"
def Group_ID = "group-SimpleProducerExample"
def main(args: Array[String]): Unit = {
startProducer
Thread.sleep(3000)
println("发送完成")
startConsumer
}
def startProducer(): Unit = {
val props = new Properties()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, Broker_List)
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
// 在0.8.2中`partitioner.class`不再起作用
//props.put("partitioner.class", "cn.gridx.kafka.apis.scala.producer.CustomPartitionerExample.MyPartitioner")
val producer = new KafkaProducer[String, String](props)
for (i <- 0 to 10) {
// 这里的`i%2`实际上就是为每一个record指定其partition number,必须是一个合法的数字
val record = new ProducerRecord(Topic, i%2, i.toString, "val_"+i.toString)
producer.send(record)
}
producer.close
}
def startConsumer(): Unit = {
val props = new Properties()
props.put("zookeeper.connect", ZK_CONN)
props.put("group.id", Group_ID)
props.put("zookeeper.session.timeout.ms", "400")
props.put("zookeeper.sync.time.ms", "200")
props.put("auto.commit.interval.ms", "1000")
val config = new ConsumerConfig(props)
val topicCountMap = Map(Topic -> 1)
val connector: ConsumerConnector = Consumer.create(config)
val topicStreamsMap: collection.Map[String, List[KafkaStream[Array[Byte], Array[Byte]]]]
= connector.createMessageStreams(topicCountMap)
val stream: KafkaStream[Array[Byte], Array[Byte]] = topicStreamsMap.get(Topic).get.head
val it: ConsumerIterator[Array[Byte], Array[Byte]] = stream.iterator()
while (it.hasNext) {
val data: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next
// 现在要打印出每一条Message的key
println(s"key -> [${new String(data.key)}}] | value -> [${new String(data.message)}] | " +
s"partition -> [${data.partition}] | offset -> [${data.offset}] | topic -> [${data.topic}]")
}
}
}
运行结果为
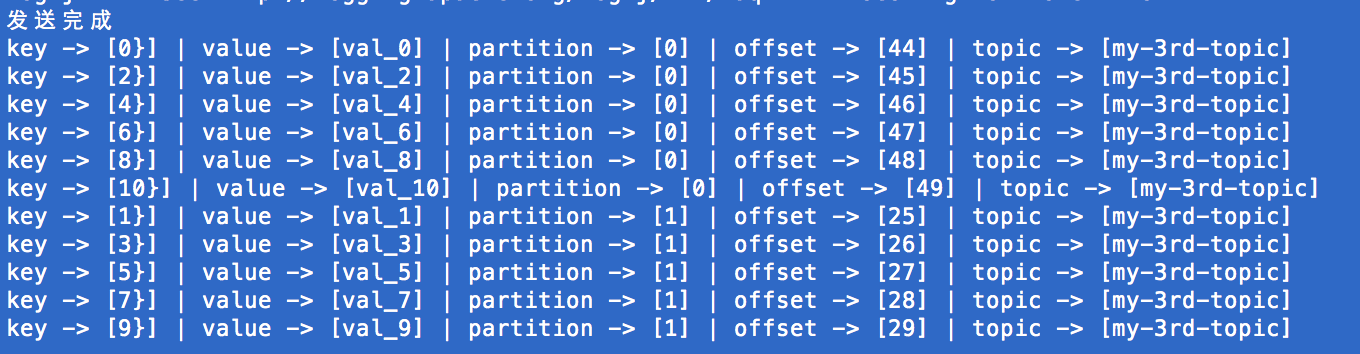
可见,尽管这个Topic共有5个partition,我们成功地限制了将所有的消息都发送到partition number为0和1的两个分区中。
在考虑消息的target partition时,经常需要在知道该topic共有多少个partitions的情况下才能决定该消息的target partition。那么,怎样获取一个target的partitions数量呢?
>
为消息的key和value实现序列化及反序列化机制
上面说了,在producer中,必须为key和value配置相应的serializer及decoder,以便消息进行序列化和反序列化。
在本文上面的例子中,我们以String作为消息的key和value的类型。那么,在这个例子中:
对于Producer :
在创建ProducerRecord时需要指定key和value的类型参数,在创建KafkaProducer也要指定这两个类型参数,同时还要对其配置中的ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG和ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG指定serializer
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
val producer = new KafkaProducer[String, String](props)
for (i <- 0 to 10) {
val record = new ProducerRecord(Topic, i%2, i.toString, "val_"+i.toString)
producer.send(record)
}
对于Consumer:
如果不进行任何配置的话,那么创建的Streamde类型是KafkaStream[Array[Byte], Array[Byte]],流中的每一条记录的类型是MessageAndMetadata[Array[Byte], Array[Byte]],记录中的key和value类型都是byte array,需要对它们进行手动的反序列化:
val topicStreamsMap: collection.Map[String, List[KafkaStream[Array[Byte], Array[Byte]]]]
= connector.createMessageStreams(topicCountMap)
val stream: KafkaStream[Array[Byte], Array[Byte]] = topicStreamsMap.get(Topic).get.head
val it: ConsumerIterator[Array[Byte], Array[Byte]] = stream.iterator()
while (it.hasNext) {
val data: MessageAndMetadata[Array[Byte], Array[Byte]] = it.next
// 现在要打印出每一条Message的key
println(s"key -> [${new String(data.key)}}] | value -> [${new String(data.message)}] | "
}
那么怎样来为其他数据类型定义序列化和反序列化机制,使得不必在produce/consume messages的时候手动地去对消息进行编码和解码?
对于Producer:
- 编写自己的Serializer
- 在创建
KafkaProducer实例之前配置ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,这样创建好的KafkaProducer的类型就直接是我们自己的数据类型- 在创建
ProducerRecord时可以直接写入我们的类型,不必转换为byte array
对于Consumer:
- 编写自己的Decoder
- 在
ConsumerConnector创建message streams时为key和value直接指定Decoder- 返回的
KafkaStream的key和value的类型直接就是我们的目标类型,而不再是byte array
下面我们以整型为例,来说明怎样使用serializer和decoder:
package cn.gridx.kafka.apis.scala.serialization
import java.util.Properties
import kafka.consumer.{KafkaStream, Consumer, ConsumerConfig}
import org.apache.kafka.clients.producer.{ProducerRecord, KafkaProducer, ProducerConfig}
/**
* Created by tao on 7/1/15.
*/
object IntegerKeyValueMessagesExample {
def Topic = "my-3rd-topic"
def Broker_List = "ecs2:9092,ecs3:9092,ecs4:9092"
def ZK_CONN = "ecs1:2181,ecs2:2181,ecs3:2181"
def Group_ID = "group-SimpleProducerExample"
def main(args: Array[String]): Unit = {
startProducer()
Thread.sleep(2000)
startConsumer()
}
def startProducer(): Unit = {
val props = new Properties()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, Broker_List)
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[IntegerSerializer])
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[IntegerSerializer])
val producer = new KafkaProducer[Int, Int](props)
for (i <- 0 to 20 if i%3 == 0)
producer.send(new ProducerRecord(Topic, i, i*100))
producer.close
}
def startConsumer(): Unit = {
val props = new Properties()
props.put("zookeeper.connect", ZK_CONN)
props.put("group.id", Group_ID)
props.put("zookeeper.session.timeout.ms", "400")
props.put("zookeeper.sync.time.ms", "200")
props.put("auto.commit.interval.ms", "1000")
val config = new ConsumerConfig(props)
val topicCountMap = Map(Topic -> 1)
val connector = Consumer.create(config)
val topicStreamsMap: collection.Map[String, List[KafkaStream[Int, Int]]] = connector.createMessageStreams(topicCountMap,
new IntegerDecoder(), new IntegerDecoder())
val stream = topicStreamsMap.get(Topic).get.head
val it = stream.iterator
while (it.hasNext) {
val data = it.next
println(s"key ->[${data.key}] | value -> [${data.message}}]")
}
}
}package cn.gridx.kafka.apis.scala.serialization;
import org.apache.kafka.common.serialization.Serializer;
import java.util.Map;
/**
* Created by tao on 6/30/15.
*/
public class IntegerSerializer implements Serializer<Integer> {
public void configure(Map<String, ?> configs, boolean isKey) {
}
public byte[] serialize(String topic, Integer data) {
return java.nio.ByteBuffer.allocate(4).putInt(data).array();
}
public void close() {
}
}package cn.gridx.kafka.apis.scala.serialization
import kafka.serializer.Decoder
/**
* Created by tao on 7/1/15.
*/
class IntegerDecoder extends Decoder[Int] {
def fromBytes(bytes: Array[Byte]): Int = {
if (None == bytes || bytes.isEmpty || bytes.size != 4)
throw new IllegalArgumentException("The bytes to be decoded is invalid")
else
return java.nio.ByteBuffer.wrap(bytes).getInt
}
}运行结果:
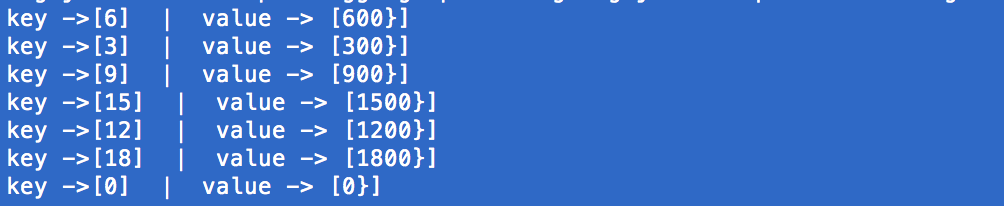
关于IntegerSerializer:由于org.apache.kafka.common.serialization.Serializer是Java写的一个interface,无法在Scala中实现该接口,因此IntegerSerializer是一个Java文件。
由于IntegerSerializer是放在scala目录下,因此用maven编译时默认就不会去编译这个Java文件了:
所以,为了让Maven能去编译位于scala目录下的Java文件,在pom.xml中除了maven-scala-plugin插件外,还需要用到另一个build-helper-maven-plugin插件,如下:
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<!-- <version> 不要在这里指定 version,否则找不到对应的pom文件 </version> -->
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<executions>
<execution>
<phase>generate-sources</phase>
<goals><goal>add-source</goal></goals>
<configuration>
<sources>
<!-- <source>src/main/java</source> -->
<source>src/main/scala</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>














 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









