







hadoop有三种模式:
1,独立模式
2,伪分布式
3,集群
其中:独立模式(Local (Standalone) Mode)是指所有的hadoop的节点都运行在同一个JVM中,这个唯一的作用就是debug。伪分布式(Pseudo-Distributed Mode)是指所有的节点运行在同一台机器上的不同JVM中,一般用作学习使用。集群(Fully-Distributed Mode),就是不同的节点运行在不同的服务器上。
按照上一步build完之后,进入hadoop-dist/target/hadoop-2.7.1。
独立模式非常简单:
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*伪分布式配置
etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/hadoop/hadoop-dist/target/hadoop-2.7.1/data</value>
</property>
</configuration>etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>设置ssh免密码登陆
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys执行
格式化文件系统
$ bin/hdfs namenode -format结果如下:
16/04/29 13:28:59 INFO namenode.FSImage: Allocated new BlockPoolId: BP-318440292-127.0.1.1-1461907739427
16/04/29 13:28:59 INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.
16/04/29 13:28:59 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
16/04/29 13:28:59 INFO util.ExitUtil: Exiting with status 0
16/04/29 13:28:59 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop/127.0.1.1
************************************************************/启动NameNode和DataNode
$ sbin/start-dfs.sh结果
hadoop@hadoop:~/hadoop/hadoop/hadoop-dist/target/hadoop-2.7.1$ jps
10513 NameNode
10683 DataNode
11003 Jps
10888 SecondaryNameNodehadoop的日志都记录在HADOOP_HOME/logs

打开浏览器
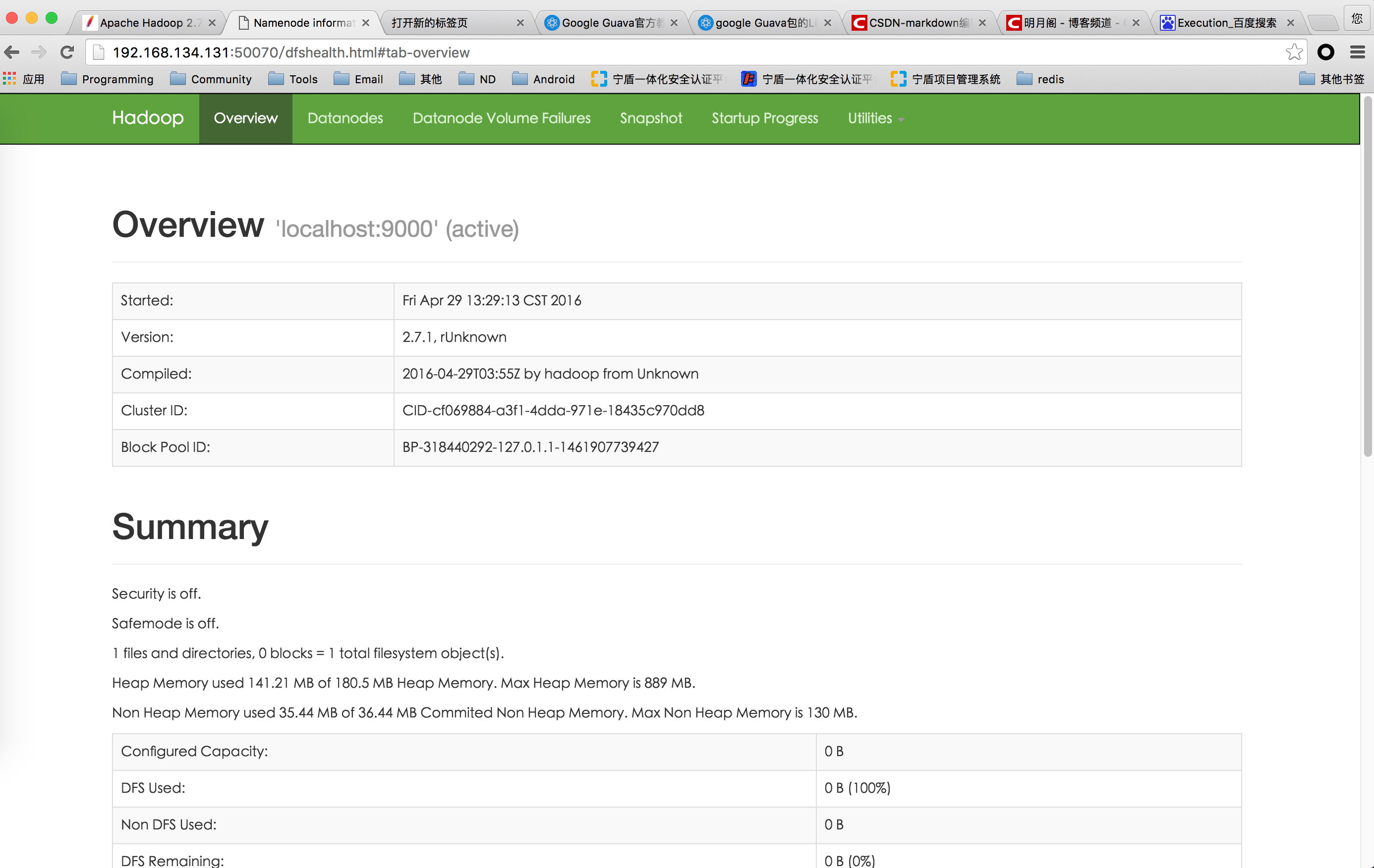
为执行任务创建目录
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>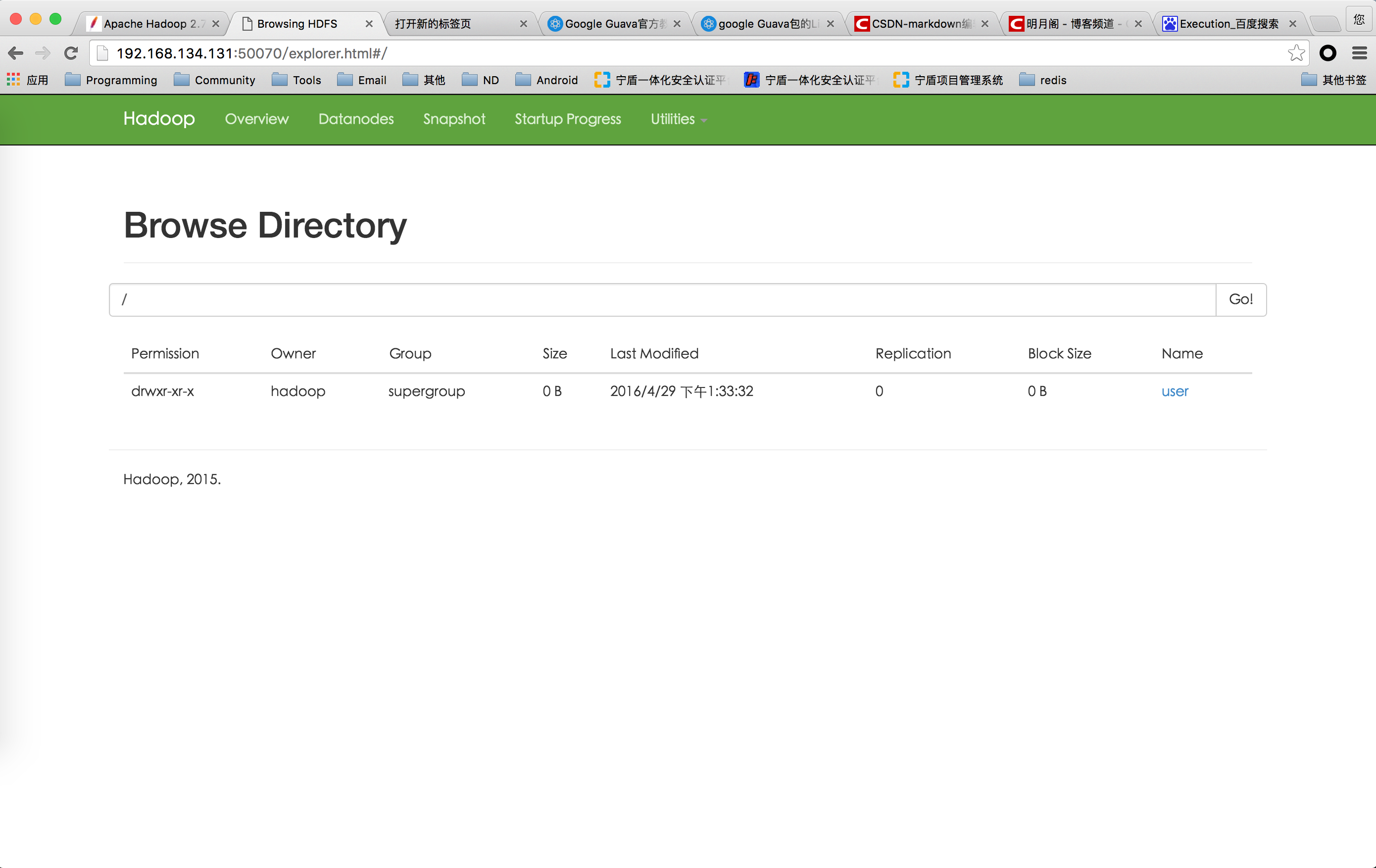
把本地文件上传到dfs
$ bin/hdfs dfs -put etc/hadoop input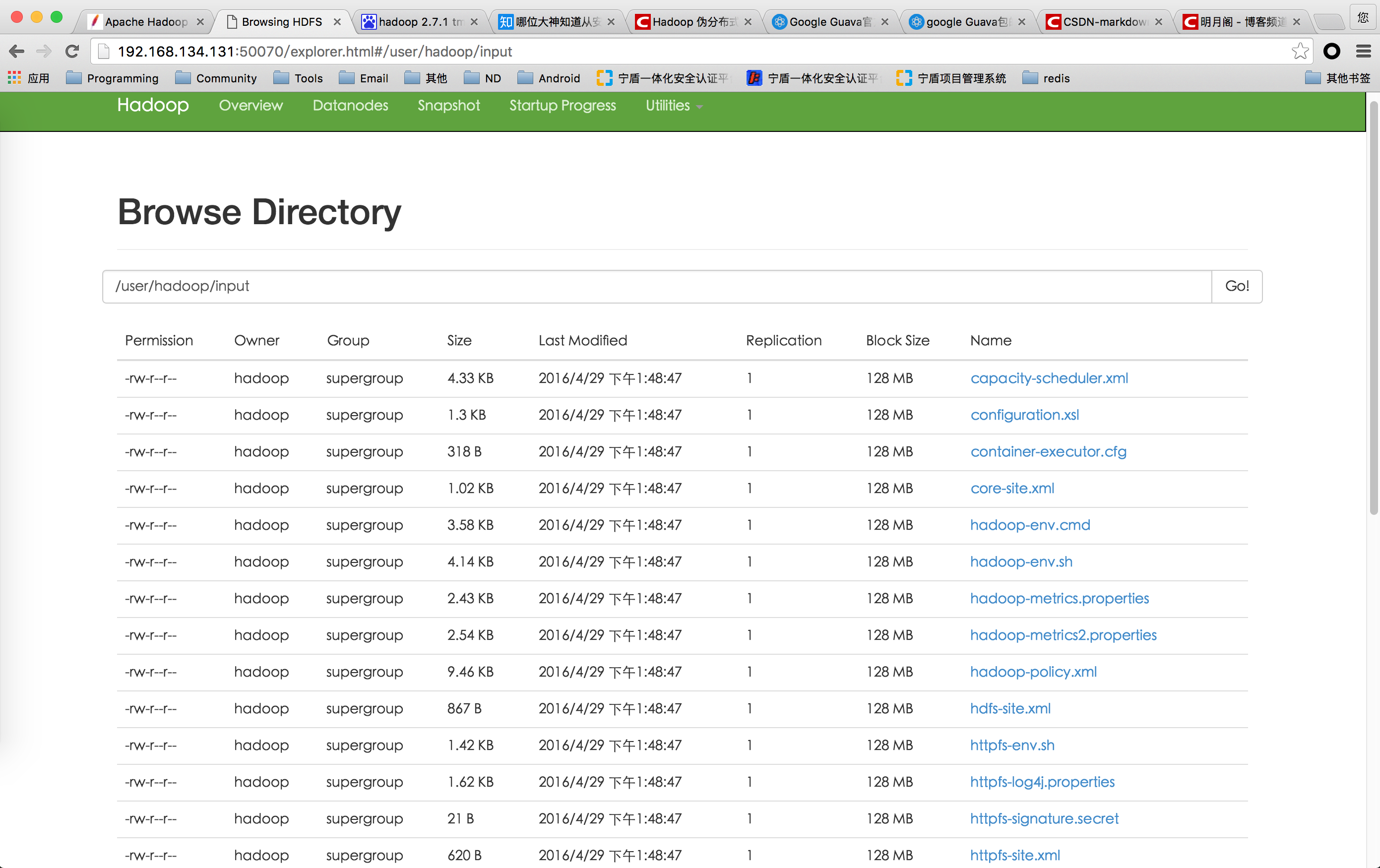
执行example
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+'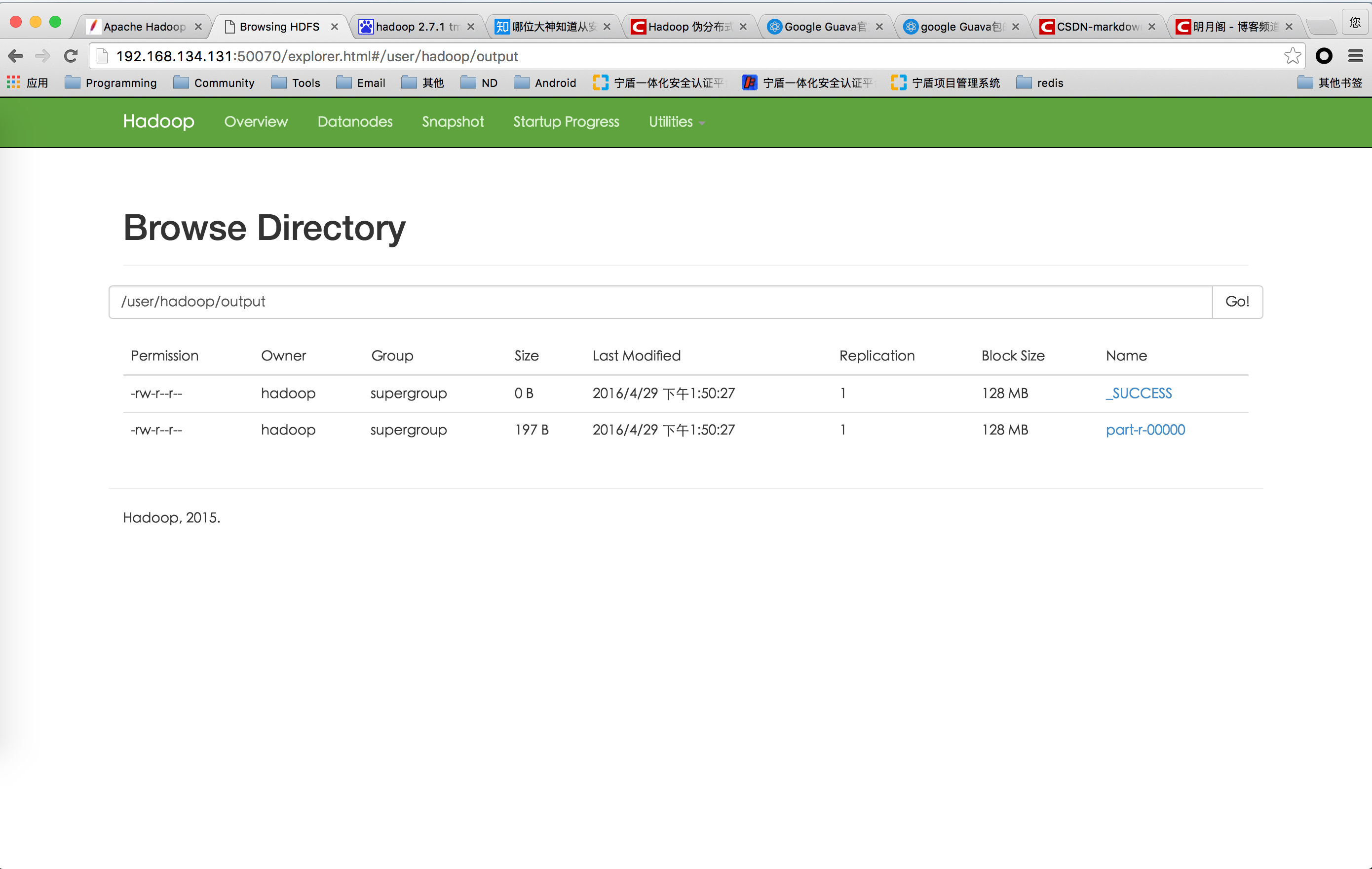
检查结果
把输出文件下载到本地文件系统中,然后查看
$ bin/hdfs dfs -get output output
$ cat output/*或者,在hdfs中直接查看
$ bin/hdfs dfs -cat output/*关闭hdfs
$ sbin/stop-dfs.sh














 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









