







原文链接:http://www.cnblogs.com/virusolf/p/4892334.html
我们都知道X86系统进程中堆栈都向下增长的,那为什么是向下增长呢?
“这个问题与虚拟地址空间的分配规则有关,每一个可执行C程序,从低地址到高地址依次是:text,data,bss,堆,栈,环境参数变量;其中堆和栈之间有很大的地址空间空闲着,在需要分配空间的时候,堆向上涨,栈往下涨。”
这样设计可以使得堆和栈能够充分利用空闲的地址空间。如果栈向上涨的话,我们就必须得指定栈和堆的一个严格分界线,但这个分界线怎么确定呢?平均分?但是有的程序使用的堆空间比较多,而有的程序使用的栈空间比较多。所以就可能出现这种情况:一个程序因为栈溢出而崩溃的时候,其实它还有大量闲置的堆空间呢,但是我们却无法使用这些闲置的堆空间。所以呢,最好的办法就是让堆和栈一个向上涨,一个向下涨,这样它们就可以最大程度地共用这块剩余的地址空间,达到利用率的最大化!!
呵呵,其实当你明白这个原理的时候,你也会不由地惊叹当时设计计算机的那些科学家惊人的聪明和智慧!
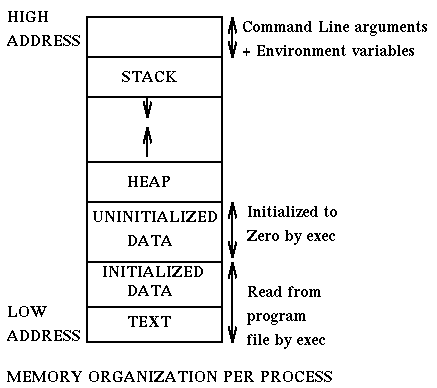
在没有MMU的时代,为了最大的利用内存空间,堆和栈被设计为从两端相向生长。那么哪一个向上,哪一个向下呢?
人们对数据访问是习惯于向上的,比如你在堆中new一个数组,是习惯于把低元素放到低地址,把高位放到高地址,所以堆向上生长比较符合习惯。而栈则对方向不敏感,一般对栈的操作只有PUSH和pop,无所谓向上向下,所以就把堆放在了低端,把栈放在了高端。MMU出来后就无所谓了,只不过也没必要改了。
有一篇更详细的讨论:判断栈和堆的生长方向 - youxin - 博客园

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









