







1 梯队下降法:
1.1 梯队
比如一个一个函数 f ( x , y ) f(x, y) f(x,y),那么 f f f 的梯度就是
( ∂ f ∂ x , ∂ f ∂ y ) (\frac{\partial f}{\partial x},\ \frac{\partial f}{\partial y}) (∂x∂f, ∂y∂f)
可以称为 g r a d f ( x , y ) grad f(x, y) gradf(x,y) 或者 ∇ f ( x , y ) \nabla f(x, y) ∇f(x,y)。具体某一点 ( x 0 , y 0 ) (x_0,\ y_0) (x0, y0) 的梯度就是 ∇ f ( x 0 , y 0 ) \nabla f(x_0,\ y_0) ∇f(x0, y0)。
1.2 学习率
- 来沿着梯度的反方向,我们能够更快地找到函数的最小值点
- 我们需要每次往下走的那一步的长度,这个长度称为学习率,用 ? 表示
- 学习率太小会导致下降非常缓慢
- 学习率太大又会导致跳动非常明显
1.3 线性回归的参数的误差更新公式
线性回归的公式:
y
^
i
=
w
x
i
+
b
\hat{y}_i = w x_i + b
y^i=wxi+b
y
^
i
\hat{y}_i
y^i 是我们预测的结果,希望通过
y
^
i
\hat{y}_i
y^i 来拟合目标
y
i
y_i
yi,通俗来讲就是找到这个函数拟合
y
i
y_i
yi 使得误差最小,即最小化损失函数定义为
J
=
1
n
∑
i
=
1
n
(
y
^
i
−
y
i
)
2
J=\frac{1}{n} \sum_{i=1}^n(\hat{y}_i - y_i)^2
J=n1i=1∑n(y^i−yi)2
J
J
J对
w
,
b
w,b
w,b求偏导, 微分得到
w
i
+
1
{w}_{i+1}
wi+1 和
w
i
{w}_i
wi的关系,
b
i
+
1
{b}_{i+1}
bi+1 和
b
i
{b}_i
bi的关系如下
w
:
=
w
−
η
∂
f
(
w
,
b
)
∂
w
b
:
=
b
−
η
∂
f
(
w
,
b
)
∂
b
w := w - \eta \frac{\partial f(w,\ b)}{\partial w} \\ b := b - \eta \frac{\partial f(w,\ b)}{\partial b}
w:=w−η∂w∂f(w, b)b:=b−η∂b∂f(w, b)
通过不断地迭代更新,最终我们能够找到一组最优的 w 和 b,这就是梯度下降法的原理。
w 和 b 的梯度分别是
∂ J ∂ w = 2 n ∑ i = 1 n x i ( w x i + b − y i ) ∂ J ∂ b = 2 n ∑ i = 1 n ( w x i + b − y i ) \frac{\partial J}{\partial w} = \frac{2}{n} \sum_{i=1}^n x_i(w x_i + b - y_i) \\ \frac{\partial J}{\partial b} = \frac{2}{n} \sum_{i=1}^n (w x_i + b - y_i) ∂w∂J=n2i=1∑nxi(wxi+b−yi)∂b∂J=n2i=1∑n(wxi+b−yi)
2 代码实现
导入包
import torch
import numpy as np
from torch.autograd import Variable
import matplotlib.pyplot as plt
%matplotlib inline
# 定义随机因子
torch.manual_seed(2019)
<torch._C.Generator at 0x2133ffd6050>
2.1 创建张量tensor(测试样本数据)
tensor的使用接口和 numpy 非常相似
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# 转换成 Tensor
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
2.2 创建变量Variable
Variable 是对 tensor 的封装,操作和 tensor 是一样的,但是每个 Variabel都有三个属性,Variable 中的.data,梯度.grad以及这个 Variable 是通过什么方式得到的.grad_fn。
# 定义参数 w 和 b
w = Variable(torch.randn(1), requires_grad=True) # 随机初始化
b = Variable(torch.zeros(1), requires_grad=True) # 使用 0 进行初始化
x_train = Variable(x_train)
y_train = Variable(y_train)
2.3 构建模型
def linear_model(x):
return x * w + b
y_ = linear_model(x_train)
# 计算误差
def get_loss(y_, y):
return torch.mean((y_ - y_train) ** 2)
2.4 训练模型
初始的参数的模型
plt.plot(x_train.data.numpy(), y_train.data.numpy(), 'bo', label='real')
plt.plot(x_train.data.numpy(), y_.data.numpy(), 'ro', label='estimated')
plt.legend()

loss = get_loss(y_, y_train)
# 打印一下看看 loss 的大小
print(loss)
tensor(10.2335, grad_fn=<MeanBackward1>)
2.4.1 误差函数求偏导
PyTorch 的自动求导,我们不需要手动去算梯度
# 自动求导
loss.backward()
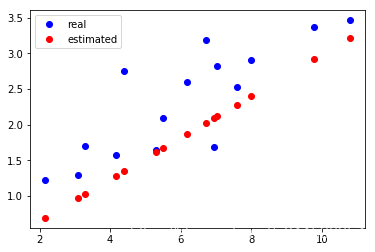
2.4.2 第一次更新参数
print(w.grad)
print(b.grad)
# 更新一次参数
w.data = w.data - 1e-2 * w.grad.data
b.data = b.data - 1e-2 * b.grad.data
y_ = linear_model(x_train)
plt.plot(x_train.data.numpy(), y_train.data.numpy(), 'bo', label='real')
plt.plot(x_train.data.numpy(), y_.data.numpy(), 'ro', label='estimated')
plt.legend()
tensor([-41.1289])
tensor([-6.0890])
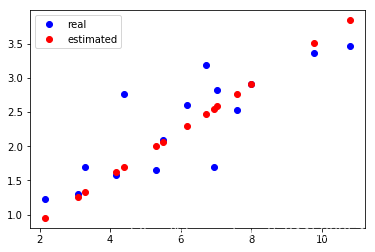
2.4.3 进行30次更新
for e in range(101): # 进行 30 次更新
y_ = linear_model(x_train)
loss = get_loss(y_, y_train)
w.grad.zero_() # 记得归零梯度
b.grad.zero_() # 记得归零梯度
# 自动求导,计算梯队
loss.backward()
# 使用梯队更新参数
w.data = w.data - 1e-2 * w.grad.data # 更新 w
b.data = b.data - 1e-2 * b.grad.data # 更新 b
if e%50==0:
print('epoch: {}, loss: {}'.format(e, loss.item()))
epoch: 0, loss: 0.4142104387283325
epoch: 50, loss: 0.2154277265071869
epoch: 100, loss: 0.20488114655017853
y_ = linear_model(x_train)
plt.plot(x_train.data.numpy(), y_train.data.numpy(), 'bo', label='real')
plt.plot(x_train.data.numpy(), y_.data.numpy(), 'ro', label='estimated')
plt.legend()














 2129
2129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









