









目录
1. 背景和问题
2. VSFA算法的解决措施
3. 实验与效果
4. 源码分析
5. 实测效果与可改善点
6. 参考
一. 背景和问题
目前很多视频是用户通过移动设备拍摄生成的UGC视频, 低质的视频会影响用户的体验,为此自动识别和剔除低质视频就很有必要.但这是一项具有挑战的任务,因为影响画质的因素有很多。
主要有以下几方面:
-
客观算法评估与人类视觉主观感知的差异;
-
视频的复杂性与多样性(包含不同的场景,纹理,运动,光照以及风格等因素);
-
不同设备显示的差异性(同一个视频,在大分辨率的设备上显示可能会有边缘噪点 整体模糊);
-
视频压制(为了节省传输和存储成本以及提升秒开减少卡顿, 在移动端上传前以及后端码率控制进行压制)造成的块效应和伪影等画质降低问题.
如下所示不同场景 纹理 转场 风格的视频



二. VSFA算法的解决措施
作者分析了对人类视觉系统影响比较大的两个特性: 内容依赖性与时间记忆性.
2.1 内容依赖:

上面每对图像都是在相同的拍摄条件下(例如焦距、物体距离)拍摄的。对于第一行的聚焦图像对,10 个受试者中有 9 个更喜欢左边的那个;
对于第二行的失焦图像对,10 个受试者中有 8 个更喜欢左边的那个。
唯一的区别是图像内容,我们可以推断出图像内容影响人类对图像质量的评估。
2.2 时间记忆效应
人类对当前帧的判断依赖于当前帧和来自前一帧的信息, 我们会记住过去质量差的帧(即使后续帧质量上已经恢复到可接受水平,但前面的低质帧也会对该帧的质量感知有影响),这被称为时间滞后效应。因此简单的平均池化策略可能会高估视频得分。
2.3 解决措施
对于内容依赖,使用预训练的图像分类模型中的图像特征提取网络(eg:Resnet50 Vgg16等),将整个帧输入网络,对输出语义特征图应用全局平均池化以及全局标准差池化。
对于时间记忆效应,特别是时间滞后性,在时间建模上考虑两个方面: 特征聚合和质量池化,
特征聚合上,之前的大多数方法是通过在时间轴上对帧级特征进行平均,聚合为视频级特征,该作者采用了GRU门控循环单元网络来建模长期依赖关系;
质量池化上 之前很多方法采用简单的平均池化策略,该方案考虑了时间滞后效应,引入了一个时间池化的新模型,嵌入到神经网络,通过反向传播进行训练。
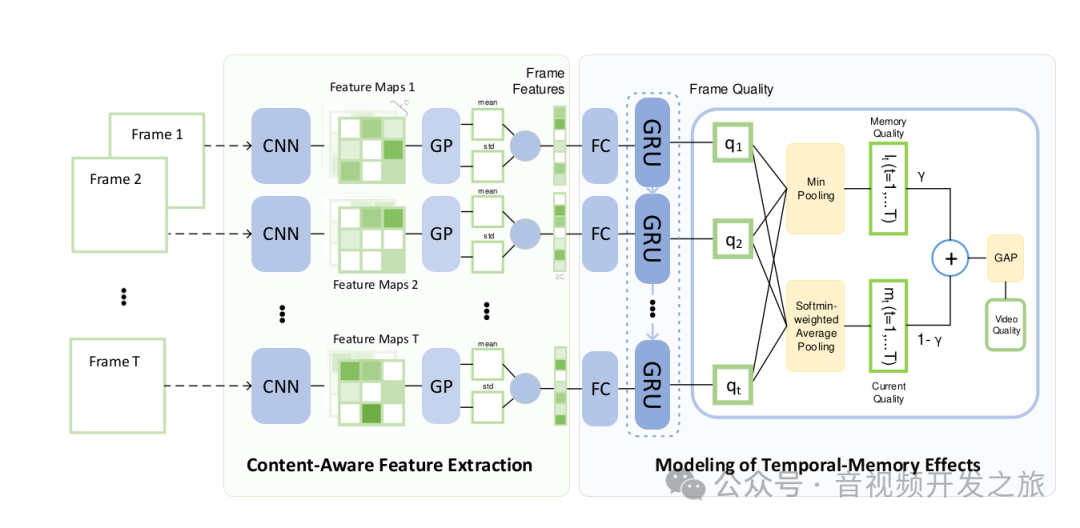
![]()
It 为视频T帧(t=1,2,...,T),输入到CNN,输出语义特征图Mt,
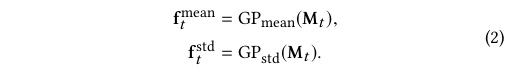
Mt包含C个特征图,我们对Mt的每个特征图进行空间全局池化GP_mean(会丢失大量信息),同时也进行空间全局标准差池化GP_std(保留图像中重要特征的同时减少数据的空间维度)操作来保留Mt中变化的信息.
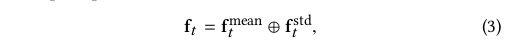
将ftmean和ftstd连接起来作为内容感知特征
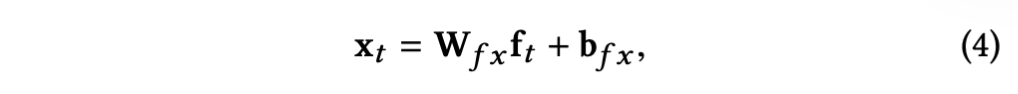
提取的内容感知特征维度很高, 会使得后面的GRU门控循环单元的训练困难,为此使用全连接层进行降维,其中Wfx和bfx为全连接层参数,降维后的xt(1,2...,T)被送到门控循环单元GRU,将GRU中隐藏状态视为整合后的特征,当前隐藏状态ht根据当前的输入xt和前一个隐藏状态ht-1计算而来。
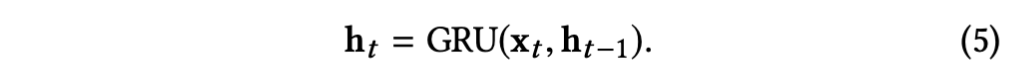
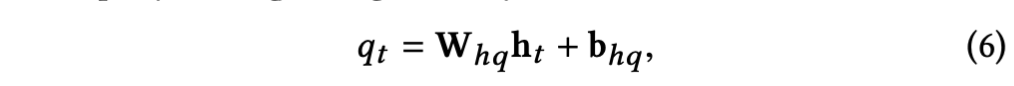
整合后的特征ht经过一个权重参数whq,偏置参数bhq的全连接层后得到当前帧的质量得分qt
在时间记忆效应上(即对质量下降反应强烈但对质量提升反应迟钝),引入质量记忆元素lt(第 t 帧定义一个记忆质量元素 lt, 为前几帧质量分数的最小值)
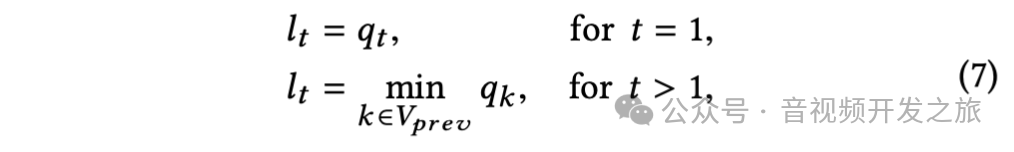
其中 V_prev = {max(1,t-τ),···,t-2,t-1}是所考虑帧的索引集,τ 是与时间持续时间相关的超参数。
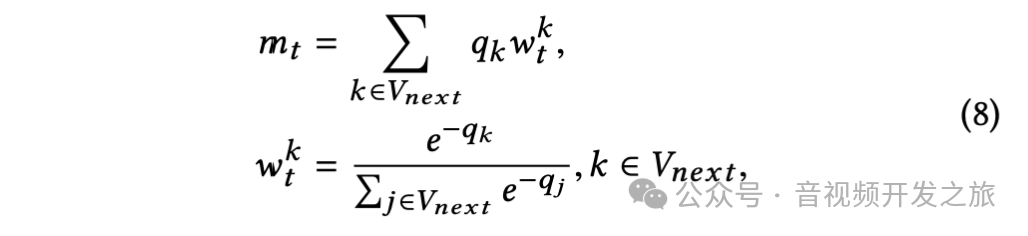
在第 t 帧构建一个当前质量元素 mt,使用后几帧的加权质量分数,其中质量差的帧分配较大的权重,其中 V_next = {t,t+1,···,min(t+τ,T)}是相关帧的索引集
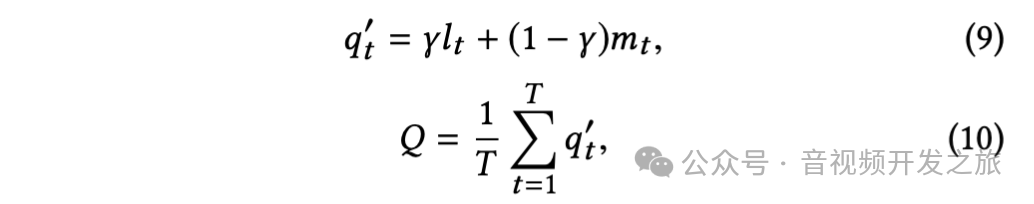
最后通过对记忆元素lt以及当前质量元素mt进行线性组合得到一帧的质量得分,然后进行时间上全局平均池化(GAP)计算得到最终的视频质量得分。
三. 实验与效果
分别在Konvid-1k,CVD2014以及Live-Qualcomm数据集上进行实验
3.1 数据集
Konvid-1k:包括 1200 个分辨率为 960×540 ,视频时长为 8 秒,帧率为 24/25/30fps 的视频。MOS 范围从 1.22 到 4.64。
Live-Qualcomm: 包括 208 个分辨率为 1920×1080 的视频,由 8 种不同设备进行 6 种失真方式拍摄(伪像、颜色、曝光、焦点、清晰度和稳定度),视频时长为 15 秒,帧率为 30fps。MOS 范围从 16.5621 到 73.6428。
CVD2014:包含 234 个分辨率为 640×480 或 1280×720 的视频,由 78 种不同的相机录制。视频时长为 10-25 秒,帧率为 11-31fps, MOS 范围从-6.50 到 93.38
3.2 评估标准:
斯皮尔曼等级相关系数(SROCC)、肯德尔等级相关系数(KROCC)、皮尔逊线性相关系数(PLCC)和均方根误差(RMSE)是质量评估方法的四个性能标准。
SROCC 和 KROCC 表示预测单调性, PLCC 和 RMSE 衡量预测准确性。SROCC/KROCC/PLCC 越大 RMSE越小 ,表示评估算法越好。
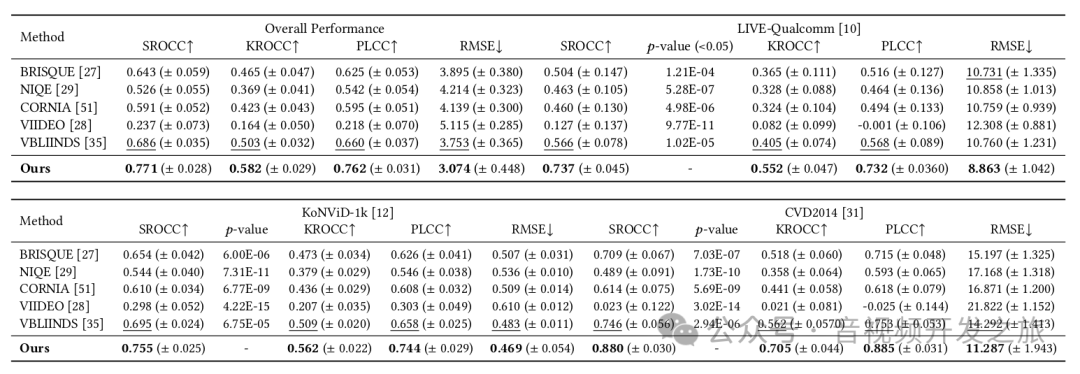
3.3 实验结果
3.4 消融实验
移除内容感知模块会导致相关性系数等显著下降, 在 KoNViD-1k、CVD2014 和 LIVE-Qualcomm 上分别发现 SROCC 下降了 14.57%、30.00%、26.87%.这说明内容感知特征对于画质评分影响最大.
移除时间记忆模块中的长期依赖模块即GRU,会导致SROCC下降2.12%,移除时间池化(即下面代码中的TP函数)会导致SROCC下降2.68%.
四. 源码解析
4.1 推理
import torchfrom torchvision import transformsimport skvideo.iofrom PIL import Imageimport numpy as npfrom VSFA import VSFAfrom CNNfeatures import get_features#调用skvideo对视频进行解析以及提取帧video_data = skvideo.io.vread(video_path)video_length = video_data.shape[0]video_channel = video_data.shape[3]video_height = video_data.shape[1]video_width = video_data.shape[2]transformed_video = torch.zeros([video_length, video_channel, video_height, video_width])#图像数据转换:数据类型转为FloatTensor,使用ImageNet数据集的均值和标准差进行归一化,帮助模型更快收敛,提高模型的泛化能力transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])for frame_idx in range(video_length):frame = video_data[frame_idx]frame = Image.fromarray(frame)frame = transform(frame)transformed_video[frame_idx] = frame# 特征提取features = get_features(transformed_video, frame_batch_size=frame_batch_size, device=device)#增加一维 batch sizefeatures = torch.unsqueeze(features, 0)#使用VSFA模型进行推理model = VSFA()model.load_state_dict(torch.load(model_path))model.to(device)#设置模型评估模式:禁用dropout和bn,固化权重参数,减少内存占用model.eval()#禁用梯度计算with torch.no_grad():input_length = features.shape[1] * torch.ones(1, 1)outputs = model(features, input_length)y_pred = outputs[0][0].to('cpu').numpy()print("Predicted quality: {}".format(y_pred))
4.2 特征提取
import torchfrom torchvision import transforms, modelsimport torch.nn as nnclass ResNet50(torch.nn.Module):"""修改ResNet50用于特征提取:去掉原始ResetNet50的最后两层(用于分类的全联接层)"""def __init__(self):super(ResNet50, self).__init__()self.features = nn.Sequential(*list(models.resnet50(pretrained=True).children())[:-2])for p in self.features.parameters():p.requires_grad = Falsedef forward(self, x):# 逐层进行特征提取,在第8层 对输入x进行全局平均池化和全局标准差池化for ii, model in enumerate(self.features):x = model(x)if ii == 7:features_mean = nn.functional.adaptive_avg_pool2d(x, 1)features_std = global_std_pool2d(x)return features_mean, features_stddef global_std_pool2d(x):"""全局标准差池化,其中x.view(x.size()[0], x.size()[1], -1, 1),重塑张量x的形状,x.size[0]和x.size[1],分别表示特征图的batchsize和channel,在第3维-1表示自适应填充,把wh中特征值展平。 torch.std(x,dim=2,keepdim=True),其中dim是指沿着第2维(即wh特征值)进行std标准差处理;keepdim=True是指保留大小为1的维度,便于后续的计算。 """return torch.std(x.view(x.size()[0], x.size()[1], -1, 1),dim=2, keepdim=True)def get_features(video_data, frame_batch_size=64, device='cuda'):"""使用修改的ResNet50进行特征提取"""extractor = ResNet50().to(device)video_length = video_data.shape[0]frame_start = 0frame_end = frame_start + frame_batch_sizeoutput1 = torch.Tensor().to(device)output2 = torch.Tensor().to(device)extractor.eval()with torch.no_grad():#分批次进行特征提取,把均值和标准差分别进行concate,这里和网络结构图有些不同,是把所有的batch的均值和标准差分别先catwhile frame_end < video_length:batch = video_data[frame_start:frame_end].to(device)features_mean, features_std = extractor(batch)output1 = torch.cat((output1, features_mean), 0)output2 = torch.cat((output2, features_std), 0)frame_end += frame_batch_sizeframe_start += frame_batch_sizelast_batch = video_data[frame_start:video_length].to(device)features_mean, features_std = extractor(last_batch)output1 = torch.cat((output1, features_mean), 0)output2 = torch.cat((output2, features_std), 0)#最后把均值和方差进行cat,去除张量大小为1的维度,返回特征output = torch.cat((output1, output2), 1).squeeze()return output
4.3 网络模型实现
import torchfrom torch.optim import Adam, lr_schedulerimport torch.nn as nnimport torch.nn.functional as F“”“定义一个ANN降维的网络”“”class ANN(nn.Module):def __init__(self, input_size=4096, reduced_size=128, n_ANNlayers=1, dropout_p=0.5):super(ANN, self).__init__()self.n_ANNlayers = n_ANNlayersself.fc0 = nn.Linear(input_size, reduced_size) #self.dropout = nn.Dropout(p=dropout_p) #self.fc = nn.Linear(reduced_size, reduced_size) #def forward(self, input):input = self.fc0(input) # linearfor i in range(self.n_ANNlayers-1): # nonlinearinput = self.fc(self.dropout(F.relu(input)))return input“”“定义一个时间池化的函数,l:前面帧画质得分的最小池化;m:计算当前帧的分数,考虑后几帧的加权质量分数,质量差的帧分配较大的权重”“”def TP(q, tau=12, beta=0.5):"""subjectively-inspired temporal pooling"""q = torch.unsqueeze(torch.t(q), 0)qm = -float('inf')*torch.ones((1, 1, tau-1)).to(q.device)qp = 10000.0 * torch.ones((1, 1, tau - 1)).to(q.device) #l = -F.max_pool1d(torch.cat((qm, -q), 2), tau, stride=1)m = F.avg_pool1d(torch.cat((q * torch.exp(-q), qp * torch.exp(-qp)), 2), tau, stride=1)n = F.avg_pool1d(torch.cat((torch.exp(-q), torch.exp(-qp)), 2), tau, stride=1)m = m / nreturn beta * m + (1 - beta) * l“”“定义VSFA网络”“”class VSFA(nn.Module):def __init__(self, input_size=4096, reduced_size=128, hidden_size=32):super(VSFA, self).__init__()self.hidden_size = hidden_size#实例化降维网络self.ann = ANN(input_size, reduced_size, 1)#实例化GRU网络self.rnn = nn.GRU(reduced_size, hidden_size, batch_first=True)#实例化全连接层self.q = nn.Linear(hidden_size, 1)def forward(self, input, input_length):#对输入的图像特征进行降维,减少GRU的训练成本input = self.ann(input) # dimension reduction#经过GRU进行特征聚合outputs, _ = self.rnn(input, self._get_initial_state(input.size(0), input.device))#经过全连接层,获取帧画质得分q = self.q(outputs) # frame qualityscore = torch.zeros_like(input_length, device=q.device)#进行时间池化操作: for i in range(input_length.shape[0]):#获取每一帧的画质得分qi = q[i, :np.int(input_length[i].numpy())]#进行时间池化:考虑了时间滞后效应qi = TP(qi)#对当前batch取均值score[i] = torch.mean(qi) # video overall qualityreturn scoredef _get_initial_state(self, batch_size, device):h0 = torch.zeros(1, batch_size, self.hidden_size, device=device)return h0
4.4 训练、验证与测试 代码
from argparse import ArgumentParserimport osimport h5pyimport torchfrom torch.optim import Adam, lr_schedulerimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.data import Datasetimport numpy as npimport randomfrom scipy import statsfrom tensorboardX import SummaryWriterimport datetimeclass VQADataset(Dataset):def __init__(self, features_dir='CNN_features_KoNViD-1k/', index=None, max_len=240, feat_dim=4096, scale=1):super(VQADataset, self).__init__()self.features = np.zeros((len(index), max_len, feat_dim))self.length = np.zeros((len(index), 1))self.mos = np.zeros((len(index), 1))for i in range(len(index)):features = np.load(features_dir + str(index[i]) + '_resnet-50_res5c.npy')self.length[i] = features.shape[0]self.features[i, :features.shape[0], :] = featuresself.mos[i] = np.load(features_dir + str(index[i]) + '_score.npy') #self.scale = scale #self.label = self.mos / self.scale # label normalizationdef __len__(self):return len(self.mos)def __getitem__(self, idx):sample = self.features[idx], self.length[idx], self.label[idx]return sampletest_ratio = val_ratio =0.2#设置学习衰减的间隔和比例decay_interval = int(epochs/10)decay_ratio = 0.8#设置随机种子,确保结果的可复现性。#禁用CuDNN的基准测试和设置为确定性,以避免使用随机算法。torch.manual_seed(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsenp.random.seed(seed)random.seed(seed)torch.utils.backcompat.broadcast_warning.enabled = True#设置用于训练的数据集特性信息if database == 'KoNViD-1k':features_dir = 'CNN_features_KoNViD-1k/' # features dirdatainfo = 'data/KoNViD-1kinfo.mat' # database info: video_names, scores; video format, width, height, index, ref_ids, max_len, etc.if database == 'CVD2014':features_dir = 'CNN_features_CVD2014/'datainfo = 'data/CVD2014info.mat'if database == 'LIVE-Qualcomm':features_dir = 'CNN_features_LIVE-Qualcomm/'datainfo = 'data/LIVE-Qualcomminfo.mat'device = torch.device("cuda" if not disable_gpu and torch.cuda.is_available() else "cpu")#加载特征数据信息Info = h5py.File(datainfo, 'r') # index, ref_idsindex = Info['index']index = index[:, exp_id % index.shape[1]] # np.random.permutation(N)ref_ids = Info['ref_ids'][0, :] #max_len = int(Info['max_len'][0])#确定训练集 测试集 indextrainindex = index[0:int(np.ceil((1 - test_ratio - val_ratio) * len(index)))]testindex = index[int(np.ceil((1 - test_ratio) * len(index))):len(index)]train_index, val_index, test_index = [], [], []for i in range(len(ref_ids)):train_index.append(i) if (ref_ids[i] in trainindex) else \test_index.append(i) if (ref_ids[i] in testindex) else \val_index.append(i)scale = Info['scores'][0, :].max() # label normalization factortrain_dataset = VQADataset(features_dir, train_index, max_len, scale=scale)train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)val_dataset = VQADataset(features_dir, val_index, max_len, scale=scale)val_loader = torch.utils.data.DataLoader(dataset=val_dataset)if test_ratio > 0:test_dataset = VQADataset(features_dir, test_index, max_len, scale=scale)test_loader = torch.utils.data.DataLoader(dataset=test_dataset)model = VSFA().to(device) #if not os.path.exists('models'):os.makedirs('models')trained_model_file = 'models/{}-{}-EXP{}'.format(model, database, exp_id)if not os.path.exists('results'):os.makedirs('results')save_result_file = 'results/{}-{}-EXP{}'.format(model, database, exp_id)#TensorBoard 可视化if not disable_visualization: # Tensorboard Visualizationwriter = SummaryWriter(log_dir='{}/EXP{}-{}-{}-{}-{}-{}-{}'.format(log_dir, exp_id, database, model,lr, batch_size, epochs,datetime.datetime.now().strftime("%I:%M%p on %B %d, %Y")))#设置loss和优化器criterion = nn.L1Loss() # L1 lossoptimizer = Adam(model.parameters(), lr=lr, weight_decay=weight_decay)scheduler = lr_scheduler.StepLR(optimizer, step_size=decay_interval, gamma=decay_ratio)best_val_criterion = -1 # SROCC minfor epoch in range(epochs):# Trainmodel.train()L = 0for i, (features, length, label) in enumerate(train_loader):features = features.to(device).float()label = label.to(device).float()optimizer.zero_grad() #outputs = model(features, length.float())loss = criterion(outputs, label)loss.backward()optimizer.step()L = L + loss.item()train_loss = L / (i + 1)model.eval()# 验证y_pred = np.zeros(len(val_index))y_val = np.zeros(len(val_index))L = 0with torch.no_grad():for i, (features, length, label) in enumerate(val_loader):y_val[i] = scale * label.item() #features = features.to(device).float()label = label.to(device).float()outputs = model(features, length.float())y_pred[i] = scale * outputs.item()loss = criterion(outputs, label)L = L + loss.item()val_loss = L / (i + 1)val_PLCC = stats.pearsonr(y_pred, y_val)[0]val_SROCC = stats.spearmanr(y_pred, y_val)[0]val_RMSE = np.sqrt(((y_pred-y_val) ** 2).mean())val_KROCC = stats.stats.kendalltau(y_pred, y_val)[0]# 测试if test_ratio > 0 and not notest_during_training:y_pred = np.zeros(len(test_index))y_test = np.zeros(len(test_index))L = 0with torch.no_grad():for i, (features, length, label) in enumerate(test_loader):y_test[i] = scale * label.item() #features = features.to(device).float()label = label.to(device).float()outputs = model(features, length.float())y_pred[i] = scale * outputs.item()loss = criterion(outputs, label)L = L + loss.item()test_loss = L / (i + 1)PLCC = stats.pearsonr(y_pred, y_test)[0]SROCC = stats.spearmanr(y_pred, y_test)[0]RMSE = np.sqrt(((y_pred-y_test) ** 2).mean())KROCC = stats.stats.kendalltau(y_pred, y_test)[0]if not disable_visualization: # record training curveswriter.add_scalar("loss/train", train_loss, epoch) #writer.add_scalar("loss/val", val_loss, epoch) #writer.add_scalar("SROCC/val", val_SROCC, epoch) #writer.add_scalar("KROCC/val", val_KROCC, epoch) #writer.add_scalar("PLCC/val", val_PLCC, epoch) #writer.add_scalar("RMSE/val", val_RMSE, epoch) #if test_ratio > 0 and not notest_during_training:writer.add_scalar("loss/test", test_loss, epoch) #writer.add_scalar("SROCC/test", SROCC, epoch) #writer.add_scalar("KROCC/test", KROCC, epoch) #writer.add_scalar("PLCC/test", PLCC, epoch) #writer.add_scalar("RMSE/test", RMSE, epoch) ## Update the model with the best val_SROCCif val_SROCC > best_val_criterion:print("EXP ID={}: Update best model using best_val_criterion in epoch {}".format(exp_id, epoch))print("Val results: val loss={:.4f}, SROCC={:.4f}, KROCC={:.4f}, PLCC={:.4f}, RMSE={:.4f}".format(val_loss, val_SROCC, val_KROCC, val_PLCC, val_RMSE))if test_ratio > 0 and not notest_during_training:print("Test results: test loss={:.4f}, SROCC={:.4f}, KROCC={:.4f}, PLCC={:.4f}, RMSE={:.4f}".format(test_loss, SROCC, KROCC, PLCC, RMSE))np.save(save_result_file, (y_pred, y_test, test_loss, SROCC, KROCC, PLCC, RMSE, test_index))torch.save(model.state_dict(), trained_model_file)best_val_criterion = val_SROCC # update best val SROCC# Testif test_ratio > 0:model.load_state_dict(torch.load(trained_model_file)) #model.eval()with torch.no_grad():y_pred = np.zeros(len(test_index))y_test = np.zeros(len(test_index))L = 0for i, (features, length, label) in enumerate(test_loader):y_test[i] = scale * label.item() #features = features.to(device).float()label = label.to(device).float()outputs = model(features, length.float())y_pred[i] = scale * outputs.item()loss = criterion(outputs, label)L = L + loss.item()test_loss = L / (i + 1)PLCC = stats.pearsonr(y_pred, y_test)[0]SROCC = stats.spearmanr(y_pred, y_test)[0]RMSE = np.sqrt(((y_pred-y_test) ** 2).mean())KROCC = stats.stats.kendalltau(y_pred, y_test)[0]print("Test results: test loss={:.4f}, SROCC={:.4f}, KROCC={:.4f}, PLCC={:.4f}, RMSE={:.4f}".format(test_loss, SROCC, KROCC, PLCC, RMSE))np.save(save_result_file, (y_pred, y_test, test_loss, SROCC, KROCC, PLCC, RMSE, test_index))
五. 实测效果与可改善点
5.1 实测效果:
文章开头的几个视频(帧截图形式展示)对应的得分分别为: 3.7, 2.0,2.6 (满分为5分)
相比之前的算法,精准率和PLCC等相关行系数还可有, 但还是不够,后续我们继续介绍其他算法,欢迎一起探讨交流.
5.2 该算法可以改进的点:
1. 思考门控训练网络改为Transformer 通过自注意力机制捕捉系列中的长距离依赖
import torchimport torch.nn as nnimport numpy as npclass VSFA(nn.Module):def __init__(self, input_size=4096, reduced_size=128, hidden_size=32, num_heads=4, num_layers=1):super(VSFA, self).__init__()self.hidden_size = hidden_size# 实例化降维网络self.ann = ANN(input_size, reduced_size, 1)# 实例化Transformer结构#首先通过nn.TransformerEncoderLayer创建单个Transformer编码器层encoder_layers = nn.TransformerEncoderLayer(d_model=reduced_size, nhead=num_heads, dim_feedforward=hidden_size)#然后通过nn.TransformerEncoder来堆叠多个这样的层self.transformer = nn.TransformerEncoder(encoder_layers, num_layers=num_layers)# 实例化全连接层self.q = nn.Linear(reduced_size, 1) # Output size from Transformer matches the reduced sizedef forward(self, input, input_length):# 对输入的图像特征进行降维input = self.ann(input) # dimension reduction# 经过Transformer进行特征聚合#注意这里相比GRU,去掉了_get_initial_state,因为Transfomer不需要像GRU那样需要隐藏状态outputs = self.transformer(input)# 经过全连接层,获取帧画质得分q = self.q(outputs) # frame qualityscore = torch.zeros_like(input_length, device=q.device)# 进行时间池化操作for i in range(input_length.shape[0]):# 获取每一帧的画质得分qi = q[i, :int(input_length[i].numpy())]# 进行时间池化:考虑了时间滞后效应qi = TP(qi)# 对当前batch取均值score[i] = torch.mean(qi) # video overall qualityreturn score
5.3. 加入LSVQ数据集进行训练优化权重
https://paperswithcode.com/dataset/live-fb-lsvq
视频质量评价数据集有38,811个视频样本,是目前最大的开源质量评价数据集。因此,我们在LSVQ数据集上对模型进行预训练
六. 参考
1. VSFA论文 :https://arxiv.org/pdf/1908.00375
2. PatchVQA论文(贡献了LSVQ数据集): https://par.nsf.gov/servlets/purl/10251054
3. VSFA代码 :https://github.com/lidq92/VSFA
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









