







随着大数据技术的发展,数据分析已成为许多行业日常工作中的重要环节。学习Python已经成为上班族的一项必备技能。而Pandas作为Python众多库中最强大的数据分析工具之一,每一位分析师都应该熟练掌握它的主要功能。
现在,我们就来了解6个非常实用的Pandas函数,迅速上手Pandas数据分析。
为了方便演示,假设我们有如下的员工KPI考核表:
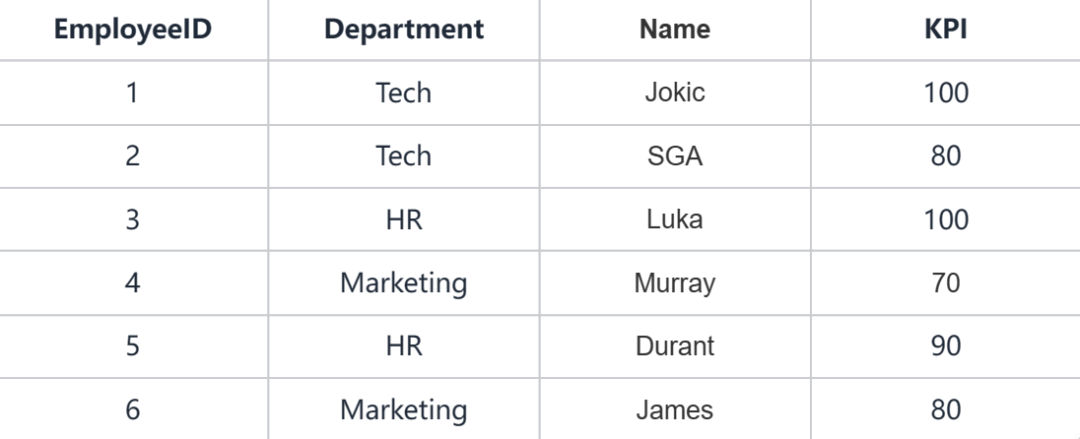
一、创建DataFrame()对象
import pandas as pd
# 使用字典创建DataFrame
df = pd.DataFrame({
"EmployeeID": [1, 2, 3, 4, 5, 6],
"Department": ["Tech", "Tech", "HR", "Marketing", "HR", "Marketing"],
"Name": ['Jokic', 'SGA', 'Luka', 'Murray', 'Durant', 'James'],
"KPI": [100, 80, 100, 70, 90, 80]
})
print(df)代码运行结果如下:
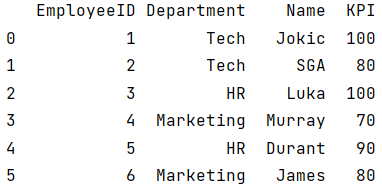
这段代码构建了一个DataFrame对象,也就是我们上面展示的表格,这方便我们后续的操作。
二、筛选与切片
如果我们想筛选员工姓名这一列,可以这样:
# 筛选出员工姓名列
names = df['Name']
print(names)
代码运行结果如下:

如果我们想截取1号员工Jokic的所有信息,可以这样:
info = df.loc[df['EmployeeID']==1, :]
print(info)

三、描述性统计
pandas的describe()函数可以迅速的对数据表进行描述性统计:
# 计算数值列的统计信息
stats = df.describe()
print(stats)代码运行结果如下:
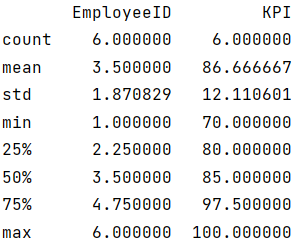
需要注意的是,describe()函数会对所有数值型变量进行统计,但实际上ID这一列的统计结果没有意义。
四、数据过滤
# 过滤出KPI高于平均水平的员工信息
high_income = df[df['KPI'] > df['KPI'].mean()]
print(high_income)过滤结果如下:

五、数据分组
pandas还可以按照指定列进行分组统计:
# 按部门分组并计算每个部门的平均KPI
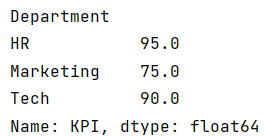
grouped_df = df.groupby('Department')['KPI'].mean()
print(grouped_df)第2行代码是将数据按照“Department”进行分组,并分别计算每一组的KPI平均数:
六、apply()函数
pandas还可以使用apply函数将自定义函数应用于数据表中的某一列:
# 定义一个函数接收KPI,并对其分类
def kpi_category(KPI):
if KPI >= 90:
return "High"
else:
return "Low"
# 对Sales列应用自定义函数,生成新的销售额类别列
df['KPI_Category'] = df['KPI'].apply(lambda x: kpi_category(x))
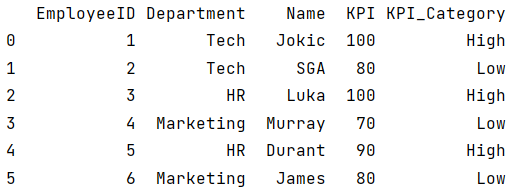
print(df)在这段代码中,我们首先定义一个打分函数:kpi_category(),这个函数可以根据参数KPI的数值来给出得分"High"或者"Low"。
接下来我们利用apply()将kpi_category()应用于数据集的KPI这一列,将所有员工按照其各自KPI数值进行打分。代码运行结果如下:
这些基础但功能强大的Pandas函数是数据分析的入门神器,简单的语法与灵活的操作让你即使是零基础也能快速上手。掌握了这些函数后,你将可以更深入地探索Pandas更复杂的功能,处理各种数据分析任务。















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









