







介绍一下 pyspark 的 DataFrame 基础操作。
一、DataFrame创建
创建 pyspark 的 DataFrame 的方式有很多种,这边列举一些:
- 通过 Row list 创建DataFrame
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
df
# 输出
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]- 通过指定 schema 创建 DataFrame
df = spark.createDataFrame([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
], schema='a long, b double, c string, d date, e timestamp')
df
# 输出
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]- 通过 pandas DataFrame 创建 pyspark DataFrame
pandas_df = pd.DataFrame({
'a': [1, 2, 3],
'b': [2., 3., 4.],
'c': ['string1', 'string2', 'string3'],
'd': [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)],
'e': [datetime(2000, 1, 1, 12, 0), datetime(2000, 1, 2, 12, 0), datetime(2000, 1, 3, 12, 0)]
})
df = spark.createDataFrame(pandas_df)
df
# 输出
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]- 从包含有元组列表的 rdd 创建 pyspark DataFrame
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
df
# 输出
DataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]二、查看DataFrame数据
- 查看1或n行数据
df.show(1)
# 输出
+---+---+-------+----------+-------------------+
| a| b| c| d| e|
+---+---+-------+----------+-------------------+
| 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|
+---+---+-------+----------+-------------------+
only showing top 1 row- 查看列名
df.columns
# 输出
['a', 'b', 'c', 'd', 'e']- 查看表结构
df.printSchema()
# 输出
root
|-- a: long (nullable = true)
|-- b: double (nullable = true)
|-- c: string (nullable = true)
|-- d: date (nullable = true)
|-- e: timestamp (nullable = true)- pyspark DataFrame 转换成 pandas DataFrame
df.toPandas()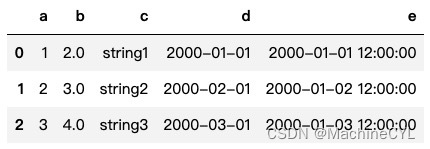
三、DataFrame保存与读取
pyspark DataFrame 支持保存成多种格式:csv、json、parquet、orc 等。具体如下:
- DataFrame 保存
df.write.csv('foo.csv', mode="overwrite", header=True, sep=",")
df.write.json('foo.json', mode="overwrite")
df.write.parquet('foo.parquet', mode="overwrite")
df.write.orc('foo.orc', mode="overwrite")
- DataFrame 读取
spark.read.csv('foo.csv', header=True)
spark.read.json('foo.json')
spark.read.parquet('foo.parquet')
spark.read.orc('foo.orc')
















 1886
1886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









