Calico基本概念
- Calico是针对容器,虚拟机和基于主机的本机工作负载的开源网络和网络安全解决方案。
- Calico支持广泛的平台,包括Kubernetes,OpenShift,Docker EE,OpenStack和裸机服务。
- Calico将灵活的网络功能与无处不在的安全性实施相结合,以提供具有本地Linux内核性能和真正的云原生可扩展性的解决方案。
- Calico为开发人员和集群运营商提供了一致的经验和功能集,无论是在公共云中还是本地运行,在单个节点上还是在数千个节点集群中运行。
Calico架构
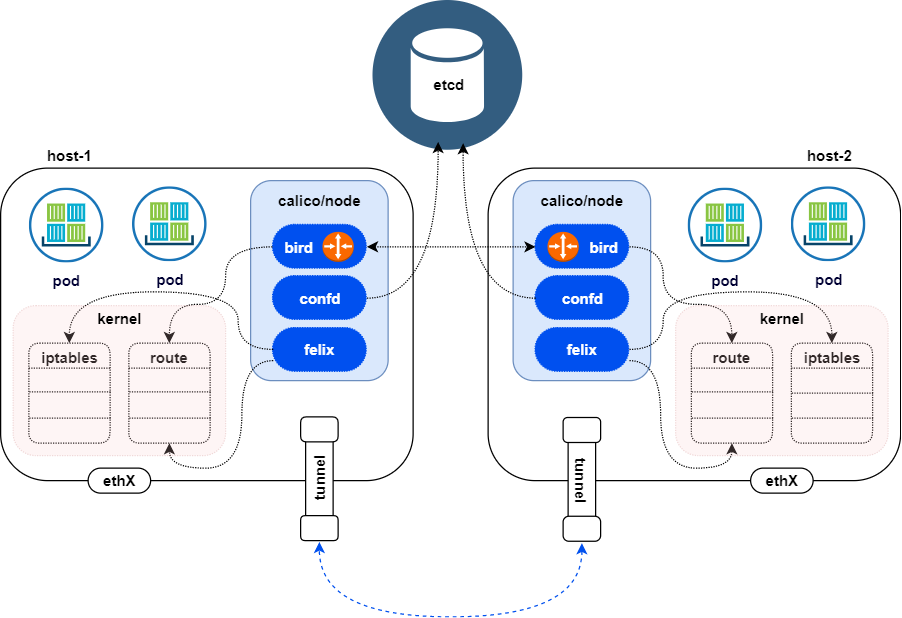
calico-cni
Calico网络模型主要工作组件:
- Felix:运行在每一台 Host 的 agent 进程,主要负责编写路由和ACLs(访问控制列表)。以便为该主机上的
endpoints 资源正常运行提供所需的网络连接。 - etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
- bird(BGP Client):
Calico 为每一台 Host 部署一个 BGP Client,当 Felix 将路由写入 kernel FIB中时 BGP Client 将通过 BGP 协议广播告诉剩余 calico 节点,从而实现网络互通。 - confd:通过监听etcd以了解BGP配置和全局默认值的更改(例如:AS number、日志级别、IPAM信息)。Confd根据ETCD中数据的更新,动态生成BIRD配置文件。当配置文件更改时,confd触发BIRD重新加载新文件。
Calico两种网络模式
  Calico本身支持多种网络模式,从overlay和underlay上区分。Calico overlay 模式,一般也称Calico IPIP或VXLAN模式,不同Node间Pod使用IPIP或VXLAN隧道进行通信。Calico underlay 模式,一般也称calico BGP模式,不同Node Pod使用直接路由进行通信。在overlay和underlay都有nodetonode mesh(全网互联)和Route Reflector(路由反射器)。如果有安全组策略需要开放IPIP协议;要求Node允许BGP协议,如果有安全组策略需要开放TCP 179端口;官方推荐使用在Node小于100的集群,我们在使用的过程中已经通过IPIP模式支撑了100-200规模的集群稳定运行。
路由更新速率问题
  为什么要考虑路由更新速率?在Calico默认的使用模式中,Calico每个Node一个分配一个Block,每个Block默认为64个IP,当单个Node启动的Pod超过64时,才会分配下一个Block。Calico BGP client默认只向外通告聚合后的Block的路由,默认配置,只有在Node上下线、Node上Pod数量超过Block size的倍数才会出现路由的更新,路由的条目数量是Node级别的。
  而实际业务在使用的过程中,会针对一个服务或者一个deployment分配一个IP Pool,这种使用模式会导致Calico的IP Pool没有办法按照Node聚合,出现一些零散的无法聚合的IP地址,最差的情况,会导致每个Pod产生一条路由,会导致路由的条目变为Pod级别。
  在默认情况下,交换机设备为了防止路由震荡,会对BGP路由进行收敛保护。但是Kubernetes集群中,Pod生命周期短,变化频繁,需要关闭网络设备的路由变更保护机制才能满足Kubernetes的要求;对于不同的网络设备,路由收敛速度也是不同的,在大规模Pod扩容和迁移的场景,或者进行双数据中心切换,除了考虑Pod的调度时间、启动时间,还需要对网络设备的路由收敛速度进行性能评估和压测。
路由黑洞问题
  使用Calico Downward Default模型组网时,Node使用EBGP模式与Node建立邻居关系。当Pod使用的IP地址为内部统一规划的地址,出现Pod IP地址紧张的时候,会出现Pod之间不能正常访问的情况。(注:只会在EBGP模式下才会出现)
  Calico分配IP地址的原则为,将整个IPPool分为多个地址块,每个Node获得一个Block,当有Pod调度到某个Node上时,Node优先使用Block内的地址。如果每个新增的Node分不到一个完整的地址块(也就是说Node无法获得整个网段64个IP),Calico IP地址管理功能会去使用其他Node的Block的IP,此时,就会出现Pod无法访问的现象。
如下图所示,Pod 10.168.73.82无法访问Pod 10.168.73.83。
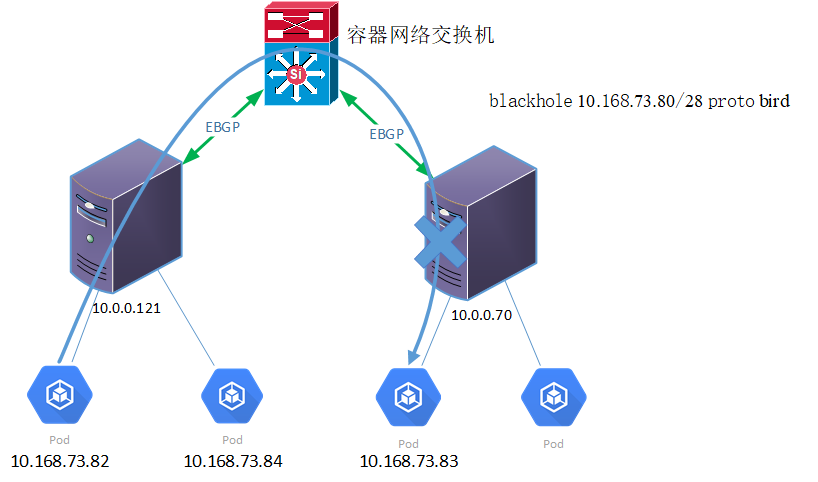
calico-cni-4
  查看Node 10.0.0.70的路由表,其中“blackhole 10.168.73.80/28 proto bird”为黑洞路由。如果没有其他优先级更高的路由,主机会将所有目的地址为10.168.73.80/28的网络数据丢弃掉。所以在Node 10.0.0.70上ping Pod 10.168.73.84会报“参数不合法”的错误。此时,在Downward Default模式下,Calico配置的这一条黑洞路由使得Node 10.0.0.70不能够响应其他Node上PodIP在10.168.73.80/28网段发起的网络请求。
  要解决路由黑洞问题问题,首先,除了对整个Calico 的IP Pool总量进行监控外,还需要对可用的IP Block进行监控,确保不会出现IP Block不够分的情况,或者或者IP地址Block借用的情况;也可以通过在规划时计算IP地址总量,以及在kubelet配置参数中指定maxPods来规避这个问题;(注:一般我们会配置子网为/16也就是说能容纳65536个POD。如果一台主机一个block块(64个IP)那么也要1024个主机。为什么是1024,因为65536/64=1024,用总的IP数除以一个block块的IP数可以计算出总共有多少个block,上面也提到过当一个新的主机无法获得一个完整的block的时候才会出现路由黑洞。所以只要主机不超过1024台或者block块不超过1024个就不会出现。)
IPIP网络:
流量:tunl0设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
效率:流量需要tunl0设备封装,效率略低。
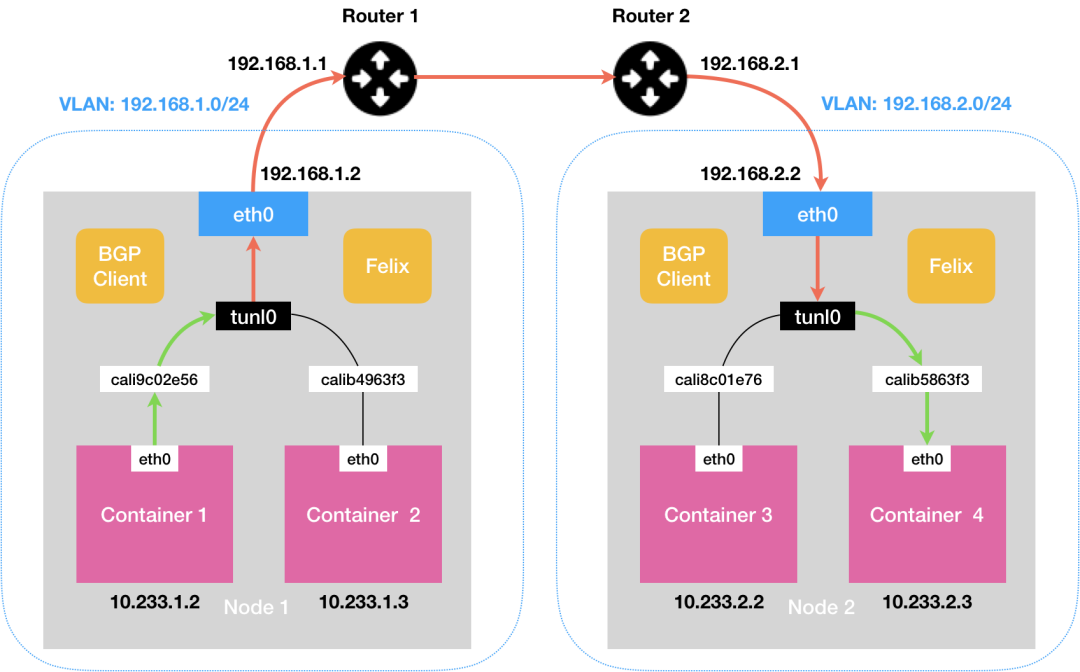
calico-cni-2
BGP网络:
流量:使用主机路由表信息导向流量
适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
效率:原生hostGW,效率高。
calico-cni-3
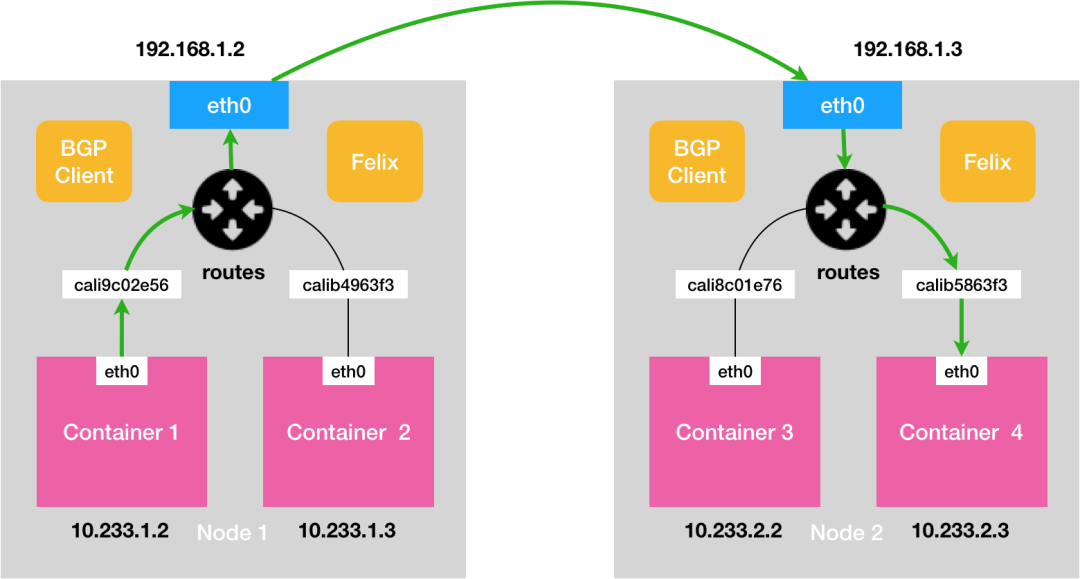
Calico 数据流向
由于个人环境中使用的是 IPIP 模式,因此接下来这里分析一下这种模式。首先是准备两个准备两个Pod分别在不同的主机上。
1
2
3
4
| [root@k8s-m1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 4 4h53m 10.244.215.68 k8s-n1 <none> <none>
nginx-7fb7fd49b4-94694 1/1 Running 0 46h 10.244.111.195 k8s-n2 <none> <none>
CRMSH |
这里在 nginx-7fb7fd49b4-94694 这个Pod中ping busybox 这个Pod
1
2
3
4
5
6
7
8
9
10
11
12
| [root@k8s-m1 ~]# kubectl exec -it nginx-7fb7fd49b4-94694 -- /bin/sh
/ # ping 10.244.215.68
PING 10.244.215.68 (10.244.215.68): 56 data bytes
64 bytes from 10.244.215.68: seq=0 ttl=62 time=0.562 ms
64 bytes from 10.244.215.68: seq=1 ttl=62 time=0.535 ms
64 bytes from 10.244.215.68: seq=2 ttl=62 time=0.408 ms
64 bytes from 10.244.215.68: seq=3 ttl=62 time=0.357 ms
^C
--- 10.244.215.68 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.357/0.465/0.562 ms
ROUTEROS |
进入pod nginx-7fb7fd49b4-94694 中查看这个pod中的路由信息
1
2
3
4
5
6
| [root@k8s-m1 ~]# kubectl exec -it nginx-7fb7fd49b4-94694 -- /bin/sh
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
ACCESSLOG |
根据路由信息 ping 10.244.215.68 会匹配到第一条。
第一条路由的意思是:去往任何网段的数据包都发往网关169.254.1.1,然后从eth0网卡发送出去。
nginx-7fb7fd49b4-94694 所在的 k8s-n2 宿主机上路由信息如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| [root@k8s-n2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.28.1 0.0.0.0 UG 0 0 0 eth0
10.244.42.128 192.168.28.10 255.255.255.192 UG 0 0 0 tunl0
10.244.111.192 0.0.0.0 255.255.255.192 U 0 0 0 *
10.244.111.193 0.0.0.0 255.255.255.255 UH 0 0 0 cali9f065bd7f12
10.244.111.194 0.0.0.0 255.255.255.255 UH 0 0 0 cali09e37c2b7c3
10.244.111.195 0.0.0.0 255.255.255.255 UH 0 0 0 calic9aa42a3793
10.244.111.197 0.0.0.0 255.255.255.255 UH 0 0 0 calia71b83e0080
10.244.111.198 0.0.0.0 255.255.255.255 UH 0 0 0 cali78caf7934ca
10.244.215.64 192.168.28.13 255.255.255.192 UG 0 0 0 tunl0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
192.168.28.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
ACCESSLOG |
可以看到一条Destination为 10.244.215.64 的路由。
意思是:当ping包来到 k8s-n2 节点上,会匹配到路由tunl0。该路由的意思是:去往10.244.215.64/26的网段的数据包都发往网关 192.168.28.13。因为 nginx-7fb7fd49b4-94694 的pod在192.168.28.14上,busybox的pod在192.168.28.13上。所以数据包就通过设备tunl0发往到 k8s-n1 节点上。
busybox所在的 k8s-n1 宿主机上路由信息如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| [root@k8s-n1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.28.1 0.0.0.0 UG 0 0 0 eth0
10.244.42.128 192.168.28.10 255.255.255.192 UG 0 0 0 tunl0
10.244.111.192 192.168.28.14 255.255.255.192 UG 0 0 0 tunl0
10.244.215.64 0.0.0.0 255.255.255.192 U 0 0 0 *
10.244.215.68 0.0.0.0 255.255.255.255 UH 0 0 0 cali12d4a061371
10.244.215.70 0.0.0.0 255.255.255.255 UH 0 0 0 cali9b7bd2198e3
10.244.215.71 0.0.0.0 255.255.255.255 UH 0 0 0 calif301e12f535
10.244.215.72 0.0.0.0 255.255.255.255 UH 0 0 0 cali8af25a4f5bc
10.244.215.73 0.0.0.0 255.255.255.255 UH 0 0 0 cali05ecd722319
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
192.168.28.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
ACCESSLOG |
当 k8s-n1 节点网卡收到数据包之后,发现发往的目的ip为 10.244.215.68 ,于是匹配到Destination为 10.244.215.68 的路由。
该路由的意思是:10.244.215.68 是本机直连设备,去往设备的数据包发往 cali12d4a061371
为什么这么奇怪会有一个名为 cali12d4a061371的设备呢?
简单来说,Calico 在主机上创建了一堆的 veth pair ,其中一端在主机上,另一端在容器的网络命名空间里,然后在容器和主机中分别设置几条路由,来完成网络的互联。
接着验证一下。我们进入 busybox 的pod,查看到 4 号设备后面的编号是:66
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| [root@k8s-m1 ~]# kubectl exec -it busybox -- /bin/sh
sh-4.2# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if66: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether 42:26:b4:65:87:9f brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.244.215.68/32 brd 10.244.215.68 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::4026:b4ff:fe65:879f/64 scope link
valid_lft forever preferred_lft forever
PF |
然后我们登录到 busybox 这个pod所在的宿主机查看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| [root@k8s-n1 ~]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:1c:42:f3:3c:42 brd ff:ff:ff:ff:ff:ff
inet 192.168.28.13/24 brd 192.168.28.255 scope global eth0
valid_lft forever preferred_lft forever
...
66: cali12d4a061371@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 3
68: cali9b7bd2198e3@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0
PF |
发现pod busybox 中的另一端设备编号和k8s-n1宿主机上看到的 cali12d4a061371 编号 66 是一样的
所以,k8s-n1上的路由,发送 cali12d4a061371 网卡设备的数据其实就是发送到了 busybox 的这个pod中去了。到这里ping包就到了目的地。最粗暴的办法是使用 ip link del cali12d4a061371@if4 删除网卡看是否还能ping通就知道了。
  我们看到不管是容器也好还是主机也好都有一些奇怪的地方,从容器路由表可以知道 169.254.1.1 是容器的默认网关,MAC地址也是一个无效的MAC地址ee:ee:ee:ee:ee:ee 为什么会这这样呢,其实这些都是calico写死了的。Calico利用了网卡的proxy_arp功能,具体的,是将/proc/sys/net/ipv4/conf/calic9aa42a3793/proxy_arp置为1。当设置这个标志之后,就开启了proxy_arp功能。主机就会看起来像一个网关,会响应所有的ARP请求,并将自己的MAC地址告诉客户端。
  也就是说,当容器发送ARP请求时,calic9aa42a3793网卡会告诉容器,我拥有169.254.1.1这个IP,我的MAC地址是XXX,这样当容器去访问外部服务时其实是访问的是calic9aa42a3793。然后在由calic9aa42a3793代替容器去访问外部服务然后把结果返回给容器这样就看起来网络就通了。
  通过tcpdump抓包可以看到首先容器会发送一个arp广播问169.254.1.1的MAC地址是多少,告诉10.244.215.81 这IP。其实这个IP就是当前Pod自己的IP,也就是告诉自己。然后cali03d85d58f77这个ARP请求,并回复告诉容器我拥有这个IP的MAC,他的MAC地址是ee:ee:ee:ee:ee:ee。如果你想验证你可以使用ip link set dev cali03d85d58f77 address ee:ee:ee:ee:11:11修改cali03d85d58f77网卡的MAC地址,然后你在抓包看看效果。
1
2
3
4
5
6
7
| tcpdump -i cali03d85d58f77 -e -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on cali03d85d58f77, link-type EN10MB (Ethernet), capture size 262144 bytes
14:36:35.204394 72:f0:91:25:10:ce > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 169.254.1.1 tell 10.244.215.81, length 28
14:36:35.204428 ee:ee:ee:ee:ee:ee > 72:f0:91:25:10:ce, ethertype ARP (0x0806), length 42: Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee, length 28
14:36:35.204433 72:f0:91:25:10:ce > ee:ee:ee:ee:ee:ee, ethertype IPv4 (0x0800), length 98: 10.244.215.81 > 10.244.111.204: ICMP echo request, id 11520, seq 0, length 64
14:36:35.205018 ee:ee:ee:ee:ee:ee > 72:f0:91:25:10:ce, ethertype IPv4 (0x0800), length 98: 10.244.111.204 > 10.244.215.81: ICMP echo reply, id 11520, seq 0, length 64
APACHE |
修改MAC地址后
1
2
3
| / # ip neigh
169.254.1.1 dev eth0 lladdr ee:ee:ee:ee:11:11 ref 1 used 0/0/0 probes 1 REACHABLE
192.168.28.13 dev eth0 lladdr ee:ee:ee:ee:ee:ee used 0/0/0 probes 0 STALE
ACCESSLOG |
部署安装
1)确保Calico可以在主机上进行管理cali和tunl接口,如果主机上存在NetworkManage,请配置NetworkManager。
NetworkManager会为默认网络名称空间中的接口操纵路由表,在该默认名称空间中,固定了Calico veth对以连接到容器,这可能会干扰Calico代理正确路由的能力。
在以下位置创建以下配置文件,以防止NetworkManager干扰接口:
1
2
3
| vim /etc/NetworkManager/conf.d/calico.conf
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*
GRADLE |
选择数据存储方式
  Calico同时支持Kubernetes API数据存储(kdd)和etcd数据存储。建议在本地部署中使用Kubernetes API数据存储,它仅支持Kubernetes工作负载。etcd是混合部署的最佳数据存储。(注意:使用Kubernetes API数据存储安装Calico时calico超过50个节点)需要做如下设置。
  在calico.yaml文件中将名为calico-typha的deployments的replicas修改为当前节点的10/1。假如有200个节点就设置20个replicas。
1
2
3
4
5
6
7
8
| apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: calico-typha
...
spec:
...
replicas: <number of replicas>
DTS |
2)然后更改 CALICO_IPV4POOL_IPIP 为 Never 使用 BGP 模式,另外增加 IP_AUTODETECTION_METHOD 为 interface 使用匹配模式,默认是first-found模式,在复杂网络环境下还是有出错的可能,还有CALICO_IPV4POOL_CIDR 设置为kubeadm初始化时设置的podSubnet参数。
1
| curl https://docs.projectcalico.org/manifests/calico-typha.yaml -o calico.yaml
AWK |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # no effect. This should fall within `--cluster-cidr`.
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
# IP automatic detection
- name: IP_AUTODETECTION_METHOD
value: "interface=en.*"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Never"
PGSQL |
3)应用calico文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| [root@devops010015001003 ~]# kubectl apply -f calico.yaml
configmap/calico-config created
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org created
clusterrole.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrolebinding.rbac.authorization.k8s.io/calico-kube-controllers created
clusterrole.rbac.authorization.k8s.io/calico-node created
clusterrolebinding.rbac.authorization.k8s.io/calico-node created
service/calico-typha created
deployment.apps/calico-typha created
poddisruptionbudget.policy/calico-typha created
daemonset.apps/calico-node created
serviceaccount/calico-node created
deployment.apps/calico-kube-controllers created
serviceaccount/calico-kube-controllers created
BASH |
1
2
3
4
5
6
7
8
9
10
| [root@devops010015001003 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-789f6df884-fxgcl 1/1 Running 0 4m55s
calico-node-28hx7 1/1 Running 0 4m55s
calico-node-fqk8n 1/1 Running 0 4m55s
calico-node-plb4z 1/1 Running 0 4m55s
calico-node-ppgpb 1/1 Running 0 4m55s
calico-node-x9gfj 1/1 Running 0 4m55s
calico-typha-7698958d65-6j5jr 1/1 Running 0 4m55s
calico-typha-7698958d65-b4tn6 1/1 Running 0 4m55s
CRMSH |
安装calicoctl
下载calicoctl客户端
1
2
3
4
| [root@devops010015001003 ~]# curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.14.0/calicoctl
[root@devops010015001003 ~]# chmod 755 calicoctl
[root@devops010015001003 ~]# chown root.root calicoctl
[root@devops010015001003 ~]# mv calicoctl /usr/bin/
AUTOIT |
验证是否可用
1
2
3
4
5
6
7
| [root@devops010015001003 ~]# calicoctl get nodes
NAME
devops010015001003
devops010015001004
devops010015001005
devops010015001006
devops010015001007
DNS |
BGP两种模式
-
全互联模式(node-to-node mesh)
  全互联模式,每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N^2,如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式。
-
路由反射模式Router Reflection(RR)
  RR模式中会指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。在calico中可以通过Global Peer实现RR模式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [root@devops010015001003 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+-------------------+-------+----------+-------------+
| 10.15.1.4 | node-to-node mesh | up | 09:38:47 | Established |
| 10.15.1.5 | node-to-node mesh | up | 09:38:47 | Established |
| 10.15.1.6 | node-to-node mesh | up | 09:38:47 | Established |
| 10.15.1.7 | node-to-node mesh | up | 09:38:48 | Established |
+--------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
GHERKIN |
使用calicoctl命令查看calico当前使用模式为node-to-node mesh全互联模式(full mesh)会造成路由条目过大,无法在大规模集群中部署。使用BGP RR(中心化)的方式交换路由,能够有效降低节点间的连接数。
配置BGP RR模型(使用node充当路由反射器)
我们将建立两个路由反射器,这意味着即使我们取消一个路由反射器节点进行维护,也可以避免单点故障。
选择两个节点,并对每个节点执行以下操作:
1
| calicoctl get node <node name> -o yaml --export > node.yaml
ROUTEROS |
编辑YAML以添加:
1
2
3
4
5
6
| metadata:
labels:
calico-route-reflector: ""
spec:
bgp:
routeReflectorClusterID: 224.0.0.1
DTS |
重新应用YAML
1
| calicoctl apply -f node.yaml
XQUERY |
配置 BGPPeer
将所有非反射器节点配置为与所有路由反射器对等
1
2
3
4
5
6
7
8
9
| calicoctl apply -f - <<EOF
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: peer-to-rrs
spec:
nodeSelector: "!has(calico-route-reflector)"
peerSelector: has(calico-route-reflector)
EOF
NESTEDTEXT |
将所有路由反射器配置为彼此对等
1
2
3
4
5
6
7
8
9
| calicoctl apply -f - <<EOF
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: rrs-to-rrs
spec:
nodeSelector: has(calico-route-reflector)
peerSelector: has(calico-route-reflector)
EOF
NESTEDTEXT |
1
2
3
4
| [root@devops010015001003 overlord]# calicoctl get bgppeer
NAME PEERIP NODE ASN
peer-to-rrs !has(calico-route-reflector) 0
rrs-to-rrs has(calico-route-reflector) 0
CRMSH |
禁用默认的node-to-node mesh模式
1
2
3
4
5
6
7
8
9
| calicoctl create -f - <<EOF
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
nodeToNodeMeshEnabled: false
asNumber: 64512
EOF
YAML |
1
2
3
| [root@devops010015001003 overlord]# calicoctl get bgpconfig -o wide
NAME LOGSEVERITY MESHENABLED ASNUMBER
default false 64512
COFFEESCRIPT |
此时在反射器节点上使用 calicoctl node status 应该能看到类似如下输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [root@devops010015001003 overlord]# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+---------------+-------+----------+-------------+
| 10.15.1.4 | node specific | up | 01:12:40 | Established |
| 10.15.1.5 | node specific | up | 01:12:46 | Established |
| 10.15.1.6 | node specific | up | 01:12:46 | Established |
| 10.15.1.7 | node specific | up | 01:12:46 | Established |
+--------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
GHERKIN |
在非反射器节点上,您应该只看到两个对等体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| [root@devops010015001005 overlord]# calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+---------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+---------------+-------+----------+-------------+
| 10.15.1.3 | node specific | up | 01:12:46 | Established |
| 10.15.1.4 | node specific | up | 01:12:46 | Established |
+--------------+---------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
ASCIIDOC |
Calico BGP跨网段(大型网络)

calico-cni-6
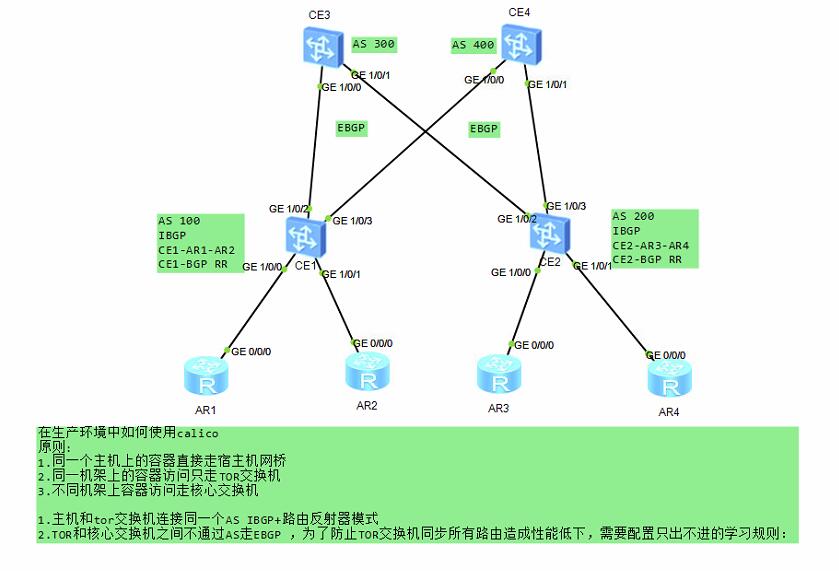
calico-cni-5
当节点位于不同的网络段时,我们需要在交换机或路由器上开启BGP协议,并配置BGPPeer将peerIP设置为路由器或交换机IP,我们需要做如下操作。
为机架1上的节点设置AS号
1
| calicoctl patch node my-node -p '{"spec": {"bgp": {"asNumber": "64514"}}}'
CRMSH |
为机架1上的节点打标签
1
| kubectl label node my-node rack=rack-1
CRMSH |
设置机架1上的node节点与tor交换机做IBGP
1
2
3
4
5
6
7
8
| apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: rack1-tor
spec:
peerIP: 192.20.30.40
asNumber: 64514
nodeSelector: rack == 'rack-1'
NESTEDTEXT |
关闭BGP的node-to-node模式(对全局生效)
1
2
3
4
5
6
7
8
9
| calicoctl create -f - <<EOF
apiVersion: projectcalico.org/v3
kind: BGPConfiguration
metadata:
name: default
spec:
nodeToNodeMeshEnabled: false
asNumber: 64512
EOF
YAML |
Calico Overlay网络
在Calico Overlay网络中有两种模式可选(仅支持IPV4地址)
- IP-in-IP (使用BGP实现)
- Vxlan (不使用BGP实现)
两种模式均支持如下参数
- Always: 永远进行 IPIP 封装(默认)
- CrossSubnet: 只在跨网段时才进行 IPIP 封装,适合有 Kubernetes 节点在其他网段的情况,属于中肯友好方案
- Never: 从不进行 IPIP 封装,适合确认所有 Kubernetes 节点都在同一个网段下的情况(配置此参数就开启了BGP模式)
在默认情况下,默认的 ipPool 启用了 IPIP 封装(至少通过官方安装文档安装的 Calico 是这样),并且封装模式为 Always;这也就意味着任何时候都会在原报文上封装新 IP 地址,在这种情况下将外部流量路由到 RR 节点,RR 节点再转发进行 IPIP 封装时,可能出现网络无法联通的情况(没仔细追查,网络渣,猜测是 Pod 那边得到的源 IP 不对导致的);此时我们应当调整 IPIP 封装策略为 CrossSubnet
导出 ipPool 配置
1
| calicoctl get ippool default-ipv4-ippool -o yaml > ippool.yaml
ACTIONSCRIPT |
修改 ipipMode 值为 CrossSubnet
1
2
3
4
5
6
7
8
9
10
11
12
13
| apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
creationTimestamp: 2019-06-17T13:55:44Z
name: default-ipv4-ippool
resourceVersion: "61858741"
uid: 99a82055-9107-11e9-815b-b82a72dffa9f
spec:
blockSize: 26
cidr: 10.244.0.0/16
ipipMode: CrossSubnet
natOutgoing: true
nodeSelector: all()
YAML |
重新使用 calicoctl apply -f ippool.yaml 应用既可























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









