







flink内存管理
JVM 存在的几个问题:
- Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
- Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
- OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
flink内存管理针对实时场景做了哪些优化
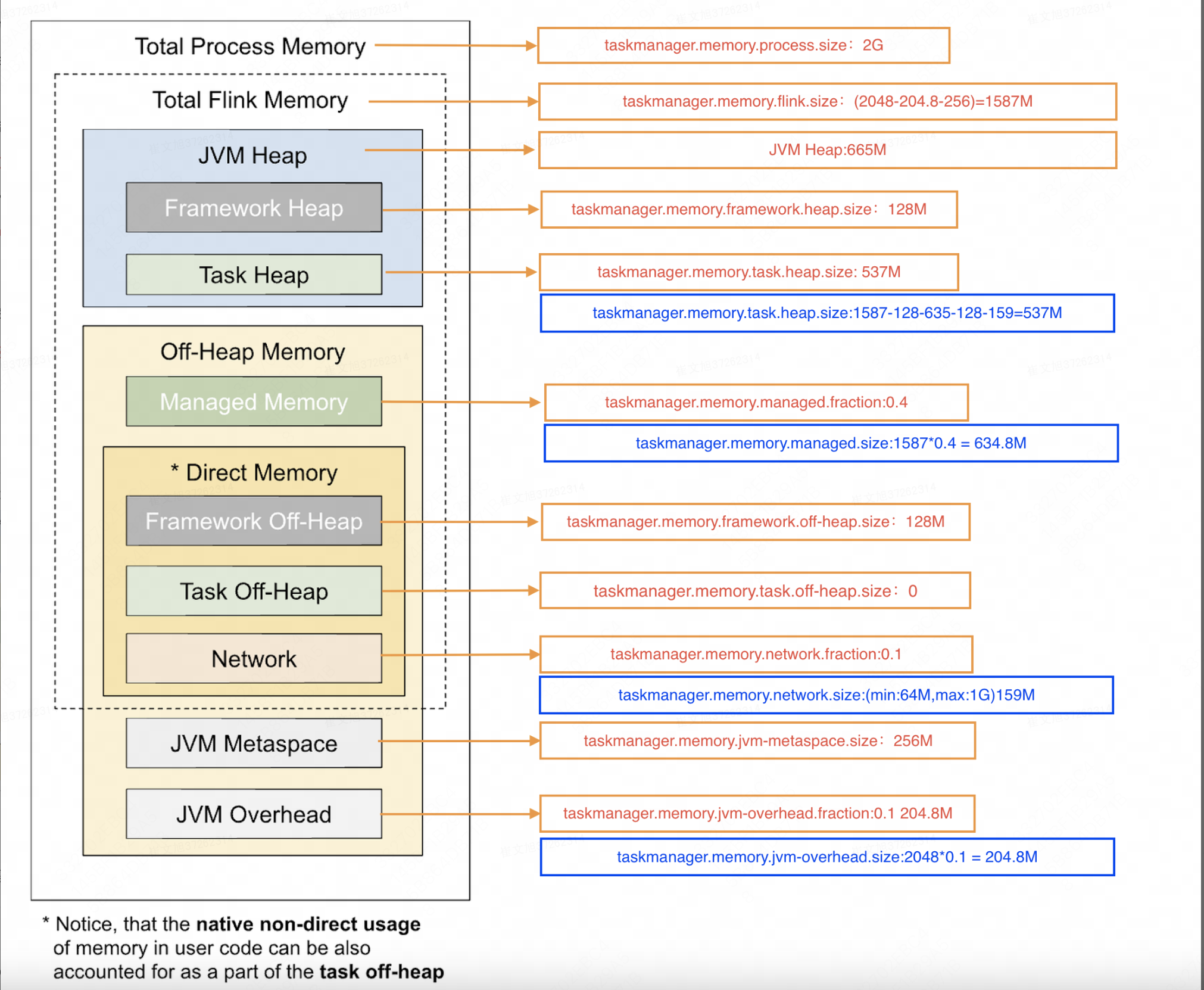
积极的堆外内存管理,因为流处理注重低延迟,为每一条要处理的数据在堆内存上创建对象会触发频繁的gc,导致处理停滞
- flink在堆外开辟network buffer(专门存放缓冲数据)
- 开辟managed memory,用于排序,缓存中间值
怎么定位背压
flink拓扑图,Flink的下游算子无法及时处理上游的消息时会出现反压的提示。反压提示一般有OK,LOW,HIGH三种状态。某个算子的BackPressure指标如果是HIGH,说明后面的算子存在性能问题。在任务性能调优时,对于串在一起的算子(Flink会对并发度一样,在同一个slotgroup下,且允许和其他链在一起的算子进行串联)可以disableChaining,然后分析各个算子的性能。
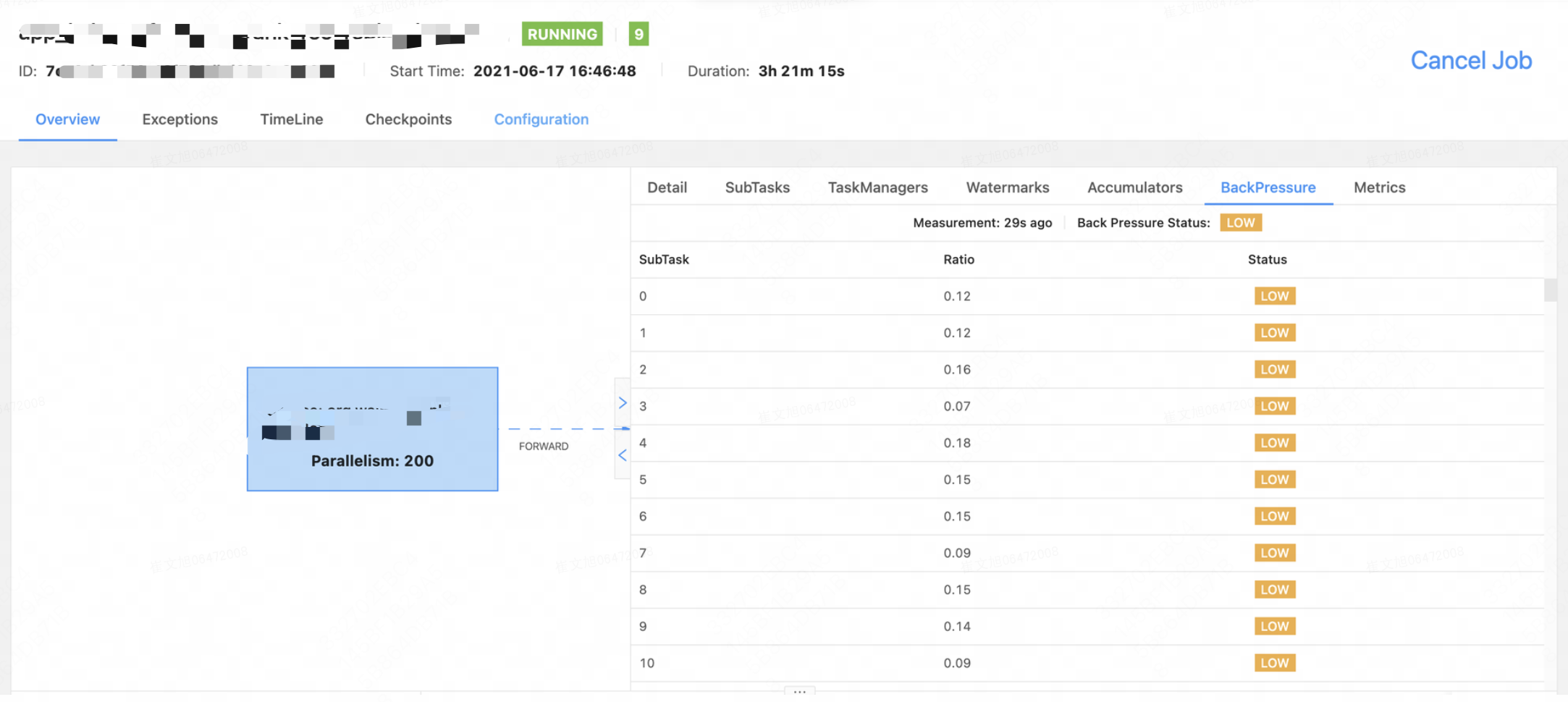
ratio计算原理
怎么处理背压
-
增加并行度
增加下游任务的并行度可以帮助提高处理速度,从而减轻背压。这可以通过配置更多的 Task Slots 或调整并行度参数来实现。 -
调整缓冲区大小
Flink 允许调整网络缓冲区的大小。通过增加缓冲区大小,可以为下游任务提供更多的缓冲空间来处理突发的数据。然而,这只是临时缓解背压的方法,并不能从根本上解决问题。 -
优化代码
检查下游任务的代码,看是否有优化空间。有时候,算子的代码可能存在性能瓶颈,如不必要的数据转换、低效的算法或过多的状态访问。优化这些代码可以提高处理速度。
写redis,mget和mset,要 -
使用异步 I/O
对于涉及外部系统调用的操作,使用异步 I/O 可以避免阻塞任务的执行线程。Flink 提供了异步 I/O API,允许你以异步方式执行数据库查询、HTTP 请求等操作。 -
调整 Checkpoint 配置
首先说明checkpoint和反压的关系,checkpoint分为对齐和非对齐,对齐的checkpoint会阻断快流的消费,非对齐的checkpoint是把快流数据缓存下来,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











