







fork函数的作用是根据一个现有的进程复制出一个新进程,原来的进程称为父进程,新进程称为子进程;系统中同时运行着很多进程,这些进程都是从最初只有一个进程开始一个一个复制出来的。在shell下输入命令可以运行一个程序,是因为shell进程在读取用户输入的命令后会调用fork复制出一个新的shell进程,然后新的shell进程调用exec执行新的程序。下面回到本编的正文:
fork函数的描述
#include <unistd.h>
pid_t fork(void)#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <stdlib.h>
int main (void)
{
pid_t pid;
char *message;
int n;
pid=fork();
if(pid<0){
perror("fork failed");
exit(1);
}
if(pid==0){
printf("pid=%d\tpid=%d\n",getpid(),getppid());
message="This is the child\n";
n=6;
}
else{
message="This is the parent\n";
n=3;
}
for(;n>0;n--){
printf(message);
sleep(1);
}
return 0;
}程序运行结果如下:
./a.out
This is the parent
pid=2794 pid=2793
This is the child
This is the parent
This is the child
This is the parent
This is the child
This is the child
machine:~/shell$ This is the child
This is the child
ls //自己输入的
a.out exec.c fork.c waitpid.c这个程序的运行过程如下图所示:
程序剖析:
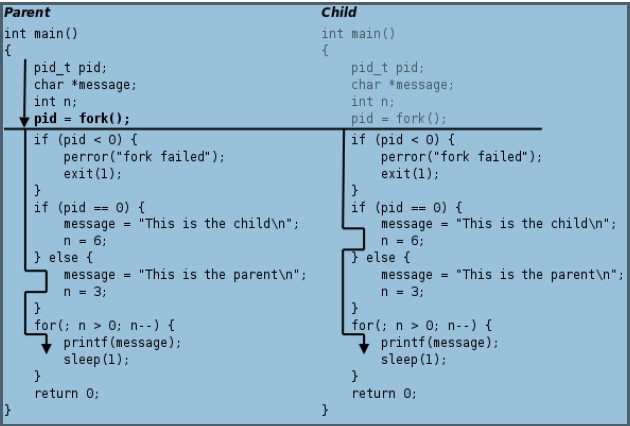
(1)首先对父进程初始化;
(2)系统调用fork函数,创建一个新的进程,内核为新进场复制父进程的PCB信息;
(3)然后进行判断PID的值,当等于0时则为子进程,并打印子进程PID与父进程PID;
(4)循环并判断程序是子进程还是父进程并打印。
注意:a:目前有两个一模一样的进程看起来调用了fork函数进入内核等待从内核返回,此外系统中还有很多别的进程也等待从内核返回,那个进程返回取决于内核的调度算法。
b:当某时刻子进程被调度执行了,则从内核返回就从fork函数返回,保存变量在pid中的返回值为0,执行if(pid==0)分支,如果父进程被调度执行,则内核返回后就从fork函数返回,保存在pid中的返回值是子进程的id,为一个大于0的数,故执行else后面的分支;
c:父进程每打印一条消息就睡眠1秒,这1秒可能去调度别的进程,所以程序结构基本上是父子进程交替打印(如果去掉sleep(1),则会先打印完父进程在大于子进程);
d:当父进程终止时Shell进程认为命令执行结束了,于是打印Shell提示符,而事实上子进程这时还没结束,所以子进程的消息打印到了Shell提示符后面。最后光标停在This is the child的下一行,这时用户仍然可以敲命令,即使命令不是紧跟在提示符后面,Shell也能正确读取。
fork函数的特点概括起来就是“调用一次,返回两次”,在父进程中调用一次,在父进程和子进程中各返回一次。从上图可以看出,一开始是一个控制流程,调用fork之后发生了分叉,变成两个控制流程,这也就是“fork”(分叉)这个名字的由来了。子进程中fork的返回值是0,而父进程中fork的返回值则是子进程的id(从根本上说fork是从内核返回的,内核自有办法让父进程和子进程返回不同的值),这样当fork函数返回后,程序员可以根据返回值的不同让父进程和子进程执行不同的代码。
fork的另一个特性是所有由父进程打开的描述符都被复制到子进程中。















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









