







 本文详细介绍了Kafka消费者在偏移量提交时的策略,包括自动提交和手动提交(同步、异步及混合提交)及其优缺点。讨论了提交偏移量小于或大于客户端处理的偏移量时的影响,以及如何处理再均衡时的偏移量提交,以防止数据丢失和重复处理。还提到了监听再均衡的ConsumerRebalanceListener接口的应用。
本文详细介绍了Kafka消费者在偏移量提交时的策略,包括自动提交和手动提交(同步、异步及混合提交)及其优缺点。讨论了提交偏移量小于或大于客户端处理的偏移量时的影响,以及如何处理再均衡时的偏移量提交,以防止数据丢失和重复处理。还提到了监听再均衡的ConsumerRebalanceListener接口的应用。
Kafka - 偏移量提交
一、偏移量提交
消费者提交偏移量的主要是消费者往一个名为_consumer_offset的特殊主题发送消息,消息中包含每个分区的偏移量。
如果消费者一直运行,偏移量的提交并不会产生任何影响。但是如果有消费者发生崩溃,或者有新的消费者加入消费者群组的时候,会触发 Kafka 的再均衡。这使得 Kafka 完成再均衡之后,每个消费者可能被会分到新分区中。为了能够继续之前的工作,消费者就需要读取每一个分区的最后一次提交的偏移量,然后从偏移量指定的地方继续处理。
但是这样可能会出现如下的问题。
1.1 提交偏移量小于客户端处理的偏移量
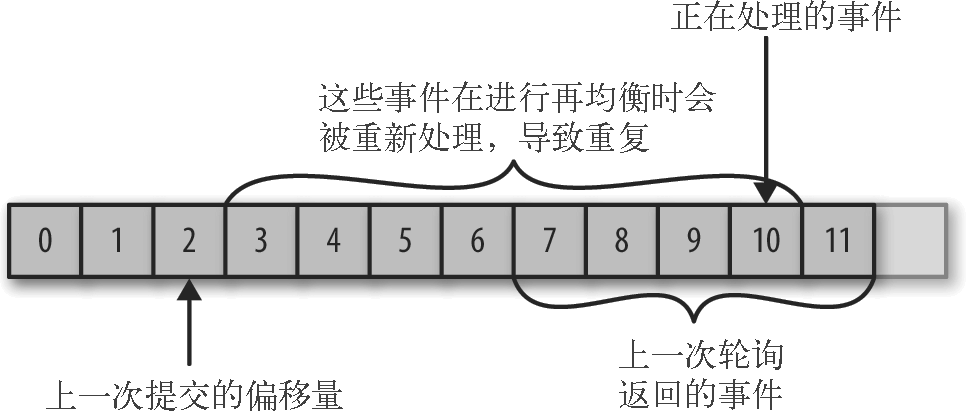
如果提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
1.2 提交偏移量大于客户端处理的偏移量
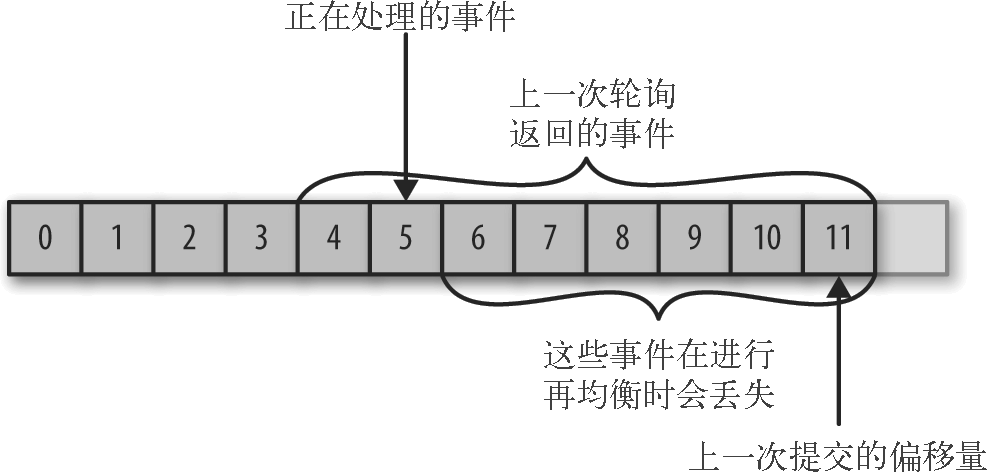
如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
因此,如果处理偏移量,会对客户端处理数据产生影响。KafkaConsumer API 提供了很多种方式来提交偏移量。
二、自动提交
自动提交是 Kafka 处理偏移量最简单的方式。
当 enable.auto.commit 属性被设为 true,那么每过 5s,消费者会自动把从 poll()方法接收到的最大偏移量提交上去。这是因为提交时间间隔由 auto.commit.interval.ms 控制,默认值是 5s。与消费者里的其他东西一样,自动提交也是在轮询里进行的。消费者每次在进行轮询时会检查是否该提交偏移量了,如果是,那么就会提交从上一次轮询返回的偏移量。
但是使用这种方式,容易出现提交的偏移量小于客户端处理的最后一个消息的偏移量这种情况的问题。假设我们仍然使用默认的 5s 提交时间间隔,在最近一次提交之后的 3s 发生了再均衡,再均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。这个时候偏移量已经落后了 3s(因为没有达到5s的时限,并没有提交偏移量),所以在这 3s 的数据将会被重复处理。
虽然可以通过修改提交时间间隔来更频繁地提交偏移量,减小可能出现重复消息的时间窗的时间跨度,不过这种情况是无法完全避免的。
在使用自动提交时,每次调用轮询方法都会把上一次调用返回的偏移量提交上去,它并不知道具体哪些消息已经被处理了,所以在再次调用之前最好确保所有当前调用返回的消息都已经处理完毕(在调用 close() 方法之前也会进行自动提交)。一般情况下不会有什么问题,不过在处理异常或提前退出轮询时要格外小心。
三、手动提交
大部分开发者通过控制偏移量提交时间来消除丢失消息的可能性,并在发生再均衡时减少重复消息的数量。消费者 API 提供了另一种提交偏移量的方式,开发者可以在必要的时候提交当前偏移量,而不是基于时间间隔。
这是我们需要把把 auto.commit.offset 设为 false,让应用程序决定何时提交偏移量。
3.1 同步提交
使用 commitSync() 提交偏移量最简单也最可靠。这个 API 会提交由 poll() 方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。
代码示例如下:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
{
System.out.printf("topic = %s, partition = %s, offset =
%d, customer = %s, country = %s\n",
record.topic(), record.partition(),
record.offset(), record.key(), record.value());
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2567
2567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









