







排序
插入排序
平均情况:O(N2)
最坏情况:O(N2)
选择排序法
冒泡排序法
希尔排序
希尔排序也叫缩减增量排序。希尔排序使用一个序列h1,h2,h3, …, hn,叫做增量序列。当增量序列为1,2,5时,示意图如下:
以n=10的一个数组49, 38, 65, 97, 26, 13, 27, 49, 55, 4为例
第一次 gap = 10 / 2 = 5

第二次 gap = 5 / 2 = 2
排序后

第四次 gap = 1 / 2 = 0 排序完成得到数组:
4 13 26 27 38 49 49 55 65 97
不同的增量序列有不同的算法时间复杂度,其中使用行如:1,3,7,。。。,2k-1的增量序列叫Hibbard序列,该增量序列下的最坏运行情况为O(N3/2)
堆排序
平均情况:O(NLogN)
最坏情况:O(NLogN)
归并排序
平均情况:O(NLogN)
最坏情况:O(NLogN)
合并排序是把需要排序的数组分为两部分,然后分别将两部分排序,然后再另外一张表中插入这两张已经排序好的表,依次类推。

归并排序需要另外一张表。对内存需要比较大
快速排序
平均情况:O(NLogN)
最坏情况:O(N2)
快速排序首先选择一个枢纽元,然后将大于枢纽元的放置一边,小于的放在另一边,依次类推。该方法不需要另外的内存。
桶排序和基数排序
桶排序
平均情况:O(N)
最坏情况:O(N)
通排序仅适用在排序元素是小于某个数的正整数时。
基本思想:是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
简单来说,就是把数据分组,放在一个个的桶中,然后对每个桶里面的在进行排序。
基数排序基于桶排序
见p213
不相交集类
数据结构
这是处理等价问题的一种算法,这里的等价指的是集合,a与b等价,是指a∈S,b∈S。通过不相交集类的两个基本操作find就可找出a和b的集合标志是否一致,若一致则说明它们是一个集合的。当然,对于集合的表示,用的是森林的数据结构。集合的标志就是根节点,若根节点一样,就说明集合一样。而除了唯一的根节点之外,剩下的节点里面存放都是父节点的标志。因此,我们只需要一个数据就能表示一个不相交集的结构了。不相交集类的另一个操作就是union。意图是把两个不属于同一集合的元素,进行合并,使其等价
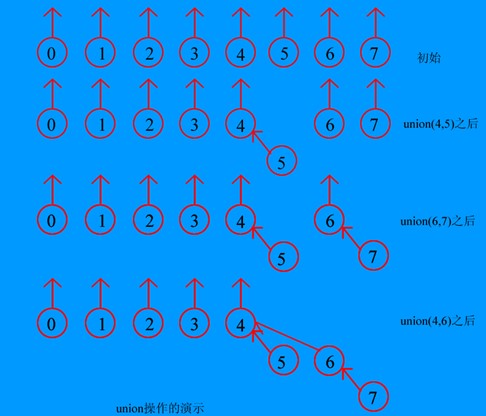
灵巧求并算法
在union(int root1,int root2)操作中,
按大小求并
集合中节点数个数的大小来判断谁合并谁;若root1的个数大于root2的个数,则root1为根,root2为节点;
按高度求并
集合中树的高度的大小来判断谁合并谁;若root1的高度大于root2的高度,则root1为根,root2为节点;
注:大小并不等价于高度,越大的树不一定高度越高。
路径压缩
每次,在find(int x)找到根节点之后,就将这个x添加到这个根节点的下面。那么,下次寻找x的根的时候,其实,只要进行一次搜索即可,也就意味这递归的次数将大大减少。
具体例子见p234 图8-15















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









