







最近在笔记更新上有所懈怠,不过最终总算是没有烂尾,今天贴上前天写的一个中缀转后缀表达式的应用,顺带复习了栈和字符串的相关知识。
《计算机组成与结构》中的写到,堆栈作为一种特殊的存储结构,有着先进后出,后进先出的特点,而程序中的栈也是同样的特点,相信大多数已经学习过数据结构的人都已经非常了解栈了,我在前面顺序表的逆置中也使用了栈,前几个天写了一个中缀转后缀表达式的小程序,在此写下一些笔记心得。
首先,中缀表达式就是我们的平时常用的运算表达方法,如”3+9-2+(3*6)/2”,可见每个运算符处于两个操作数中间,而如果将以上式子转换为后缀表达式,则为”3 9 + 2 -3 6 * 2 / +”,这个过程是一个经典的栈应用,原理如下
首先转换规则为遇见数字就输出,遇见第一个符号先入栈,遇到第二个符号时,与栈顶的符号比较优先级,如果优先级相同或者新符号优先级小于栈顶符号优先级,则栈顶符号出栈输出,当前符号入栈,若优先级大于栈顶符号,则当前符号入栈。如果遇见’(‘,那么在读取时遇见’)’以后,输出’(’以后的所有入栈符号,同时将括号丢弃。当读取的式子读取完毕后,栈中仍然有符号,则一次输出至已经生成的后缀表达式末尾。
过程图解:
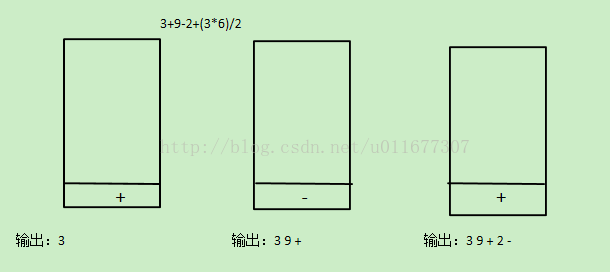
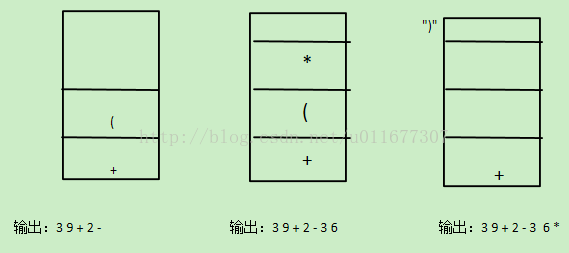
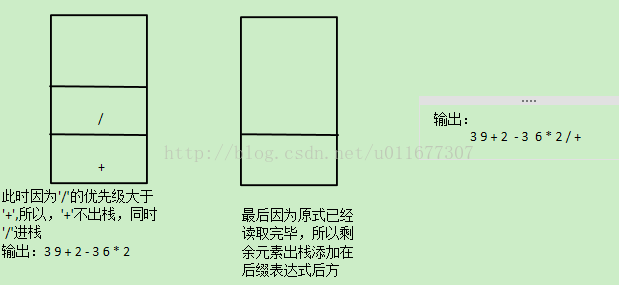
源代码:
acctstack.h
#ifndef ACCTSTACK_H_
#define ACCTSTACK_H_
template <class Elem>
class Stack
{
public:
virtual void clear() = 0;
virtual bool push(const Elem &item) = 0;
virtual Elem pop() = 0;
virtual Elem topValue() const = 0 ;
virtual int length() const = 0;
};
#endifstack._array.h
#include"acctstack.h"
#include<iostream>
template <class Elem>
class AStack : public Stack<Elem>
{
private:
int top;
int size;
Elem *listArray;
public:
AStack(int sz)
{
size = sz;
top = 0;
listArray = new Elem[sz];
}
~AStack()
{
delete [] listArray;
}
void clear()
{
top = 0;
}
bool push(const Elem& item);
Elem pop();
Elem topValue() const;
int length() const
{
return top;
}
};
template <class Elem>
bool AStack<Elem> :: push(const Elem& item)
{
if( top == size ){
return false;
}else{
listArray[top++] = item;
return true;
}
}
template <class Elem>
Elem AStack<Elem> :: pop()
{
if( top == 0 ){
return NULL;
}else{
return listArray[--top] ;
}
}
template <class Elem>
Elem AStack<Elem> :: topValue() const
{
if( top == 0 ){
return NULL;
}else{
return listArray[top - 1] ;
}
}在写栈的声明函数的时候,终于一改往常的坏习惯,避免写了太多的内联函数,以规范代码。
middle-_to_back.cpp
#include<iostream>
#include"stack_array.h"
using namespace std;
int priority(char c);
int main()
{
cout << "Pleaer enter the funcation you want to change"
<< endl;
char c[20];
char c2[20];
cin >> c ;
AStack<char> Fun(100);
int i = 0,j = 0;
while( c[i] != '\0')
{
if( c[i] >= '0' && c[i] <= '9')
{
c2[j++] = c[i];
}
else if( c[i] == '(')
{
Fun.push(c[i]);
}
else if( c[i] == ')')
{
while(Fun.topValue() != '(' )
{
c2[j++] = ' '; //加入空格符方便输入两位数与美观性
c2[j++]=Fun.pop();
}
Fun.pop();
}
else if( c[i] == '+'|| c[i] == '-' ||
c[i] == '*'|| c[i] == '/')
{
c2[j++] = ' ';
while(priority(c[i]) <= priority(Fun.topValue()))
{
c2[j++]=Fun.pop();
c2[j++] = ' ';
}
Fun.push(c[i]);
}
i++;
}
while( Fun.length() != 0 )
{
c2[j++] = ' ';
c2[j++] = Fun.pop();
}
c2[j] = '\0' ;
cout << "Function after change is "<<endl;
cout << c2;
};
int priority(char c) //符号优先级判断函数
{
int priority = -1 ;
switch(c)
{
case '(' :
case ')' : break;
case '+' : priority = 1; break;
case '-' : priority = 1; break;
case '*' : priority = 2; break;
case '/' : priority = 2; break;
}
return priority ;
};测试
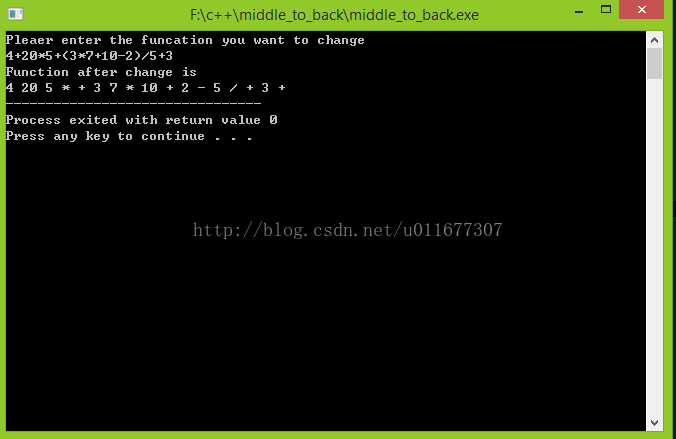
测试结果成功,其中对两位数的判断也达到了设计要求(实际上多位数亦可识别,但没有加入识别小数的功能)。这次实现过程中,仍然有些问题比如栈函数pop的原型本为pop(Elem & it),但在实现过程中却无法取出出战的元素,从而修改了pop函数以适应该程序,这个问题需是要继续改进,处理字符串时使用的字符指针也出现了问题,改用了字符数组,因而这一片内容是需要再复习的。今天就写到这吧,OpenGL还有的看呢~















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









