







ReceiverTracker管理所有receiver,其中Recevier是一个抽象类
发消息有两种 :
一种是local 自己给自己发 ;
第二种是remote 远程给自己发
ReceiverTracker.scala中receive 方法有以下几个case 类
(StartAllReceiver RestartReceiver CleanupOldBlocks UpdateReceiverRateLimit ReportError)
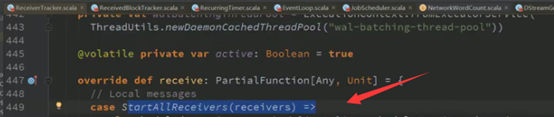
接收到消息后回馈给发送者receiveAndReply

停止发送消息

启动RPC消息通信实体endpoint
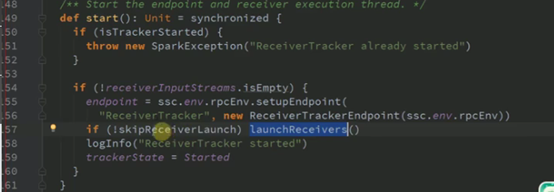
Nis.id是指消息不管从kafka还是socket还是hdfs等哪里来源的都会有个自己的id
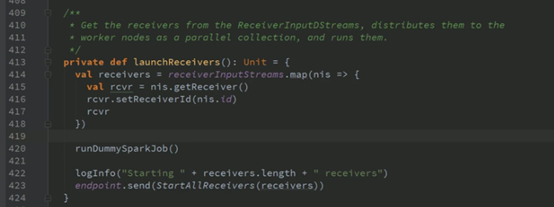

确保所有的slave都已经注册,避免所有receiver都放在一个node中,已经获得资源,在这均衡一下


schedulingPolicy类具体发送到什么地方进行计算,其中scheduleReceivers方法中有两个参数excutors跟receivers,计算哪些receiver在哪个excutor上执行
SocketInputDStream.scala
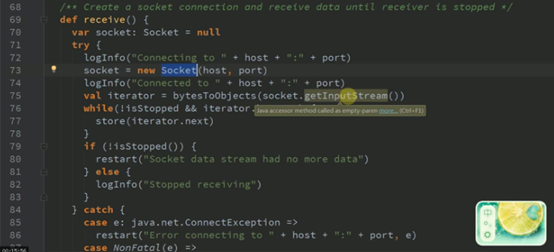
ReceiverSupervisor.scala
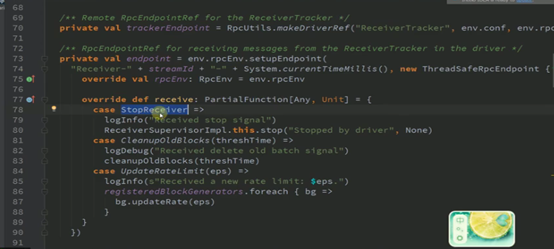
Case StartAllReceivers中是个循环过程
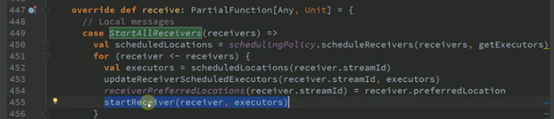
为了启动一个receiver搞了一个RDD,在下面运行了一个spark job,
用job有什么好处呢?
第一个是确保receiver一定被启动起来,job启动失败就给重来的,future.onComplete中有case Success和case Failure,不会因为框架的问题而启动失败;
第二个是task很有可能两个出现在一个机器上但是receiver不大可能,这样做吞吐量更强。
job在excutor中执行时候首先启动一个ReceiverSupervisorImpl(启动时候可以知道host集群excutorid)然后调用它的父类ReceiverSupervisor中的start方法,


ReceiverSupervisorImpl.scala中的
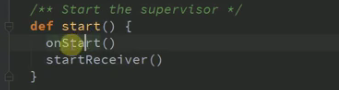
调用onStart及其startReceiver两个方法

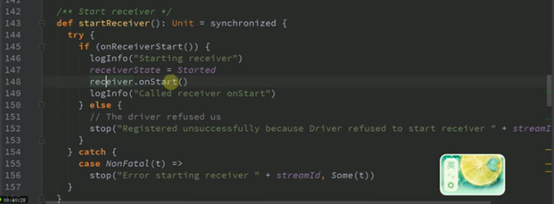
Receivertracker.scala中的
ReceiverSupervisorImpl.scala中的

这两个对应的 此处并不是指Receivertracker这个类
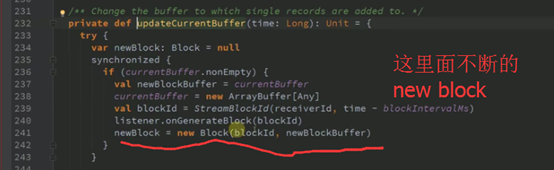















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









