







Python爬虫之高清壁纸下载
今天发现了一个非常不错的壁纸网站https://unsplash.com/,高清非常适合做壁纸,我已经受够自己电脑桌面的那么几张壁纸了,于是准备把它们都给爬下来。
Step 1:分析页面
首先打开网站https://unsplash.com/,高清又漂亮的壁纸就呈现在眼前了,页面没有“下一页”,向下滑动页面发现新的图片不断被加载出来,这个过程显然是动态完成的。
于是,打开Chrom浏览器,F12进入开发者工具,抓取页面请求。机智的我发现它们是这样请求图片数据的。
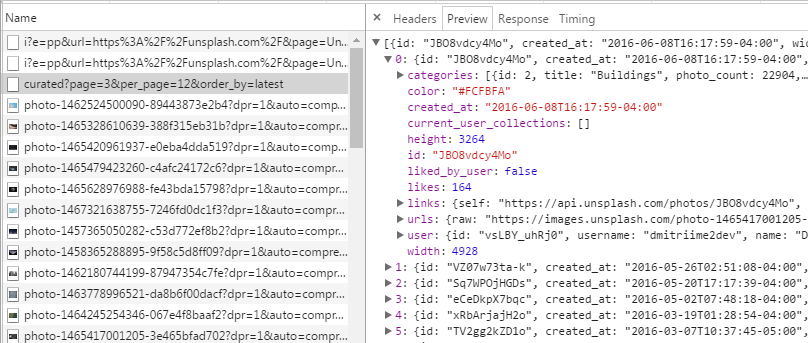
同时,还可以发现url提交的参数中包含了当前页page,每一页显示的图片数per_page以及图片显示顺序order_by,因此想抓取下一页只要在page的值上做改变就可以了。OK,分析完毕可以开抓了。
Step 2:页面抓取
采用多线程爬虫,页面抓取线程负责对页面进行抓取,解析页面返回的Json数据,将每一页的图片url存储在队列中,图片下载线程负责从队列中取出待下载图片的url进行下载,以下是代码部分
定义一些必要的变量
pictures = Queue()#待下载图片url队列
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests':'1',
'authorization':'Client-ID d69927c7ea5c770fa2ce9a2f1e3589bd896454f7068f689d8e41a25b54fa6042',
'x-unsplash-client':'web'}
session = requests.session()
session.headers.update(headers)#更新Http请求头页面抓取线程:
class wallPaperScracher(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.url = ''
self.cur_page = 1
self.pics_pattern = re.compile(r'"download":"(.*?)"',re.S)
def getPicture(self):
while self.cur_page <= 15:
self.url = 'https://unsplash.com/napi/photos/curated?page=' + str(self.cur_page) +'&per_page=12&order_by=latest'
res = session.get(self.url)
json = res.content
pics = re.findall(self.pics_pattern, json)
for url in pics:
print('第%d页,正在存储图片%s' % (self.cur_page,url))
pictures.put(url)
self.cur_page += 1
pictures.put(None)#标志结束
def run(self):
self.getPicture()图片下载线程:
class picDownloader(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.pattern = re.compile(r'photos/(.*?)/')
def downloadPic(self):
while True:
pic_url = pictures.get()
if not pic_url:#取到None则停止下载
break
pic_name = re.search(self.pattern, pic_url).group(1)
f = open('E:\\HDPhoto\\' + pic_name + '.jpg', 'wb')
res = session.get(pic_url)
print('正在下载图片 : %s' % pic_url)
f.write(res.content)
def run(self):
self.downloadPic()主函数:启动三个下载线程
scracher = wallPaperScracher()
scracher.start()
for i in range(3):
downloader = picDownloader()
downloader.start()好了,代码搞定。坐等图片…,有新壁纸喽!
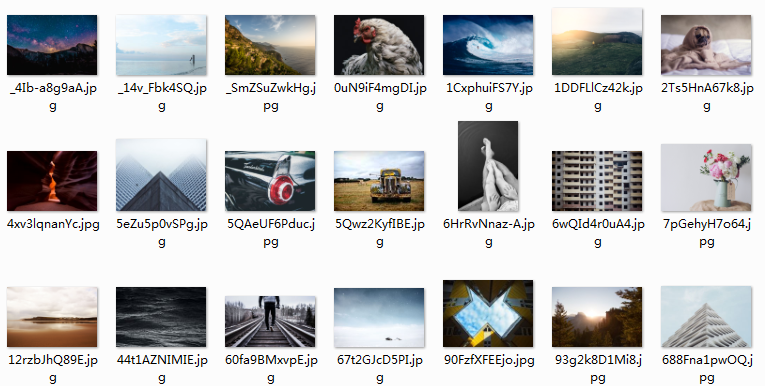















 2936
2936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









