







1、数据同步方式
全量同步与增量同步
全量同步是指全部将数据同步到es,通常是刚建立es,第一次同步时使用。增量同步是指将后续的更新、插入记录同步到es。
2、常用的一些ES同步方法
1)、elasticsearch-jdbc: 严格意义上它已经不是第三方插件。已经成为独立的第三方工具。不支持5.5.1。。。
2)、elasticsearch-river-mysql插件: https://github.com/scharron/elasticsearch-river-mysql
3)、go-mysql-elasticsearch(国内作者siddontang): https://github.com/siddontang/go-mysql-elasticsearch
4)、python-mysql-replication: github地址 https://github.com/noplay/python-mysql-replication
5)、MySQL Binlog: 通过 MySQL binlog 将 MySQL 的数据同步给 ES, 只能使用 row 模式的 binlog。
6)、Logstash-input-jdbc: github地址 https://github.com/logstash-plugins/logstash-input-jdbc
3、Logstash-input-jdbc安装
由于我用的ES版本是5.5.1,elasticsearch-jdbc不支持,只支持2.3.4,这就尴尬了。
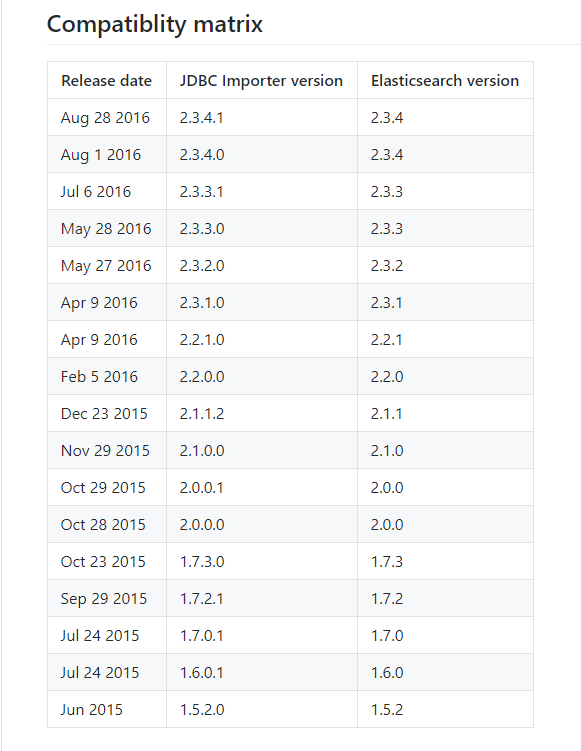
所用这里用Logstash-input-jdbc来同步数据,logstash-input-jdbc插件是logstash 的一个个插件,使用ruby语言开发。所以要先安装ruby,也是为了好使用ruby中的gem安装插件,下载地址:https://rubyinstaller.org/downloads/
下载下来之后,进行安装

安装好之后试下是否安装成功,打开CMD输入:

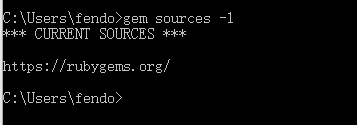
OK,然后修改gem的源,使用以下命令查看gem源
gem sources -l
删除默认的源
gem sources --remove https://rubygems.org/
添加新的源
gem sources -a http://gems.ruby-china.org/
gem sources -l
更改成功,还的修改Gemfile的数据源地址。步骤如下:
gem install bundler
bundle config mirror.https://rubygems.org https://gems.ruby-china.org
然后就是安装logstash-input-jdbc,在logstash-5.5.1/bin目录下
执行安装命令
.\logstash-plugin.bat install logstash-input-jdbc静等一会儿,成功之后提示如下

4、Logstash-input-jdbc使用
官方文档地址
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html
首先在bin目录下新建一个mysql目录,里面包含jdbc.conf,jdbc.sql文件,加入mysql的驱动

A)全量同步
jdbc.conf配置如下
input {
stdin {
}
jdbc {
# mysql 数据库链接,test为数据库名
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/test"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
# 驱动
jdbc_driver_library => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\mysql-connector-java-5.1.9.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
# 执行的sql 文件路径+名称
statement_filepath => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\jdbc.sql"
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "jdbc"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["localhost:9200"]
# 索引名称
index => "article"
# 自增ID 需要关联的数据库中有有一个id字段,对应索引的id号
document_id => "%{id}"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
各数据库对应的链接如下:
MySQL数据库
Driver ="path/to/jdbc-drivers/mysql-connector-java-5.1.35-bin.jar" //驱动程序
Class ="com.mysql.jdbc.Driver";
URL ="jdbc:mysql://localhost:3306/db_name"; //连接的URL,db_name为数据库名
SQL server数据库
Driver ="path/to/jdbc-drivers/sqljdbc4.jar"
Class ="com.microsoft.jdbc.sqlserver.SQLServerDriver";
URL ="jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=db_name"; //db_name为数据库名
Oracle数据库
Driver ="path/to/jdbc-drivers/ojdbc6-12.1.0.2.jar"
Class ="oracle.jdbc.driver.OracleDriver";
URL ="jdbc:oracle:thin:@loaclhost:1521:orcl"; //orcl为数据库的SID
DB2数据库
//连接具有DB2客户端的Provider实例
Driver ="path/to/jdbc-drivers/jt400.jar"
Class ="com.ibm.db2.jdbc.app.DB2.Driver";
URL ="jdbc:db2://localhost:5000/db_name"; //db_name为数据可名
PostgreSQL数据库
Driver ="path/to/jdbc-drivers/postgresql-9.4.1201.jdbc4.jar"
Class ="org.postgresql.Driver"; //连接数据库的方法
URL ="jdbc:postgresql://localhost/db_name"; //db_name为数据可名
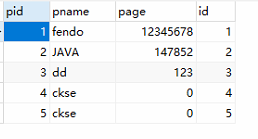
jdbc.sql配置如下:
select * from person就一条查询语句对应的表数据如下:
先启动ES,然后通过sense创建article索引
UT http://localhost:9200/article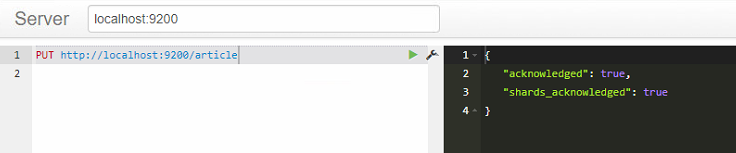
然后通过以下命令启动logstash
.\logstash.bat -f .\mysql\jdbc.conf
过一会他就会自动的往ES里添加数据,输出的日志如下:

执行了SQL查询。查看下article索引会发现多出来了很多文档
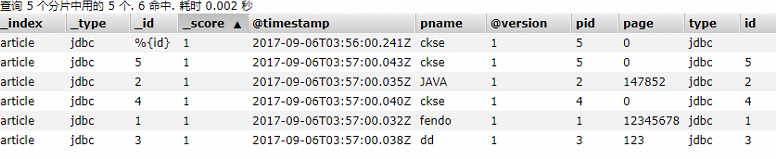
我们在数据库增加一条数据,看他是否自动同步到ES中
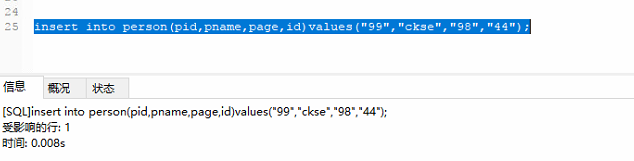
静等一会,发现logstash的日志

查询了一篇,ES中的数据会多出刚刚插入的那条
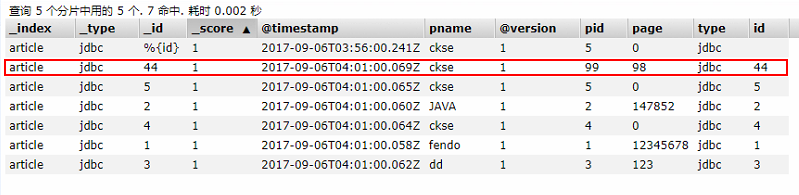
B)增量同步
下面使用增量来新增数据,需要在jdbc.conf配置文件中做如下修改:
input {
stdin {
}
jdbc {
# mysql 数据库链接,test为数据库名
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/test"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
# 驱动
jdbc_driver_library => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\mysql-connector-java-5.1.9.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
#处理中文乱码问题
codec => plain { charset => "UTF-8"}
#使用其它字段追踪,而不是用时间
use_column_value => true
#追踪的字段
tracking_column => id
record_last_run => true
#上一个sql_last_value值的存放文件路径, 必须要在文件中指定字段的初始值
last_run_metadata_path => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\station_parameter.txt"
#开启分页查询
jdbc_paging_enabled => true
jdbc_page_size => 300
# 执行的sql 文件路径+名称
statement_filepath => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\jdbc.sql"
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "jdbc"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
# ES的IP地址及端口
hosts => ["localhost:9200"]
# 索引名称
index => "article"
# 自增ID
document_id => "%{id}"
}
stdout {
# JSON格式输出
codec => json_lines
}
}
参数介绍:
//是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
//是否需要记录某个column 的值,如果 record_last_run 为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
//如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的.比如:ID.
tracking_column => MY_ID
//指定文件,来记录上次执行到的 tracking_column 字段的值
//比如上次数据库有 10000 条记录,查询完后该文件中就会有数字 10000 这样的记录,下次执行 SQL 查询可以从 10001 条处开始.
//我们只需要在 SQL 语句中 WHERE MY_ID > :last_sql_value 即可. 其中 :last_sql_value 取得就是该文件中的值(10000).
last_run_metadata_path => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\station_parameter.txt"
//是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
//是否将 column 名称转小写
lowercase_column_names => false
//存放需要执行的 SQL 语句的文件位置
statement_filepath => "G:\Developer\Elasticsearch5.5.1\ES5\logstash-5.5.1\bin\mysql\jdbc.sql"这里使用webmagic爬虫来爬取数据,导入到数据库中,先运行爬虫,爬取一些数据

这里爬取到了277条,然后启动logstash,通过logstash导入到ES中去

打开mysql目录下的station_parameter.txt文件

这个文件里记录上次执行到的 tracking_column 字段的值,比如上次数据库有 10000 条记录,查询完后该文件中就会有数字 10000 这样的记录,下次执行 SQL 查询可以从 10001 条处开始,我们只需要在 SQL 语句中 WHERE MY_ID > :last_sql_value 即可. 其中 :last_sql_value 取得就是该文件中的值。
然后开启爬虫,爬取数据,往数据库里插,logstash会自动的识别到更新,然后导入到ES中!!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









