










基数排序
多排序码排序的概念
如果每个元素的排序码都是由多个数据项组成的组项,则依据它进行排序时就需要利用多排序码排序。实现多排序码排序有两种常用的方法,最高位优先(Most Significant Digit (MSD) First)和最低位优先(Least Signnificant Digit(LSD) first)。利用多排序码排序实现对单个排序码排序的算法就称为基数排序。
MSD基数排序
思想
在基数排序中,将单排序码
Ki
看作是一个子排序码组:
(K1i,K2i,...,Kdi)
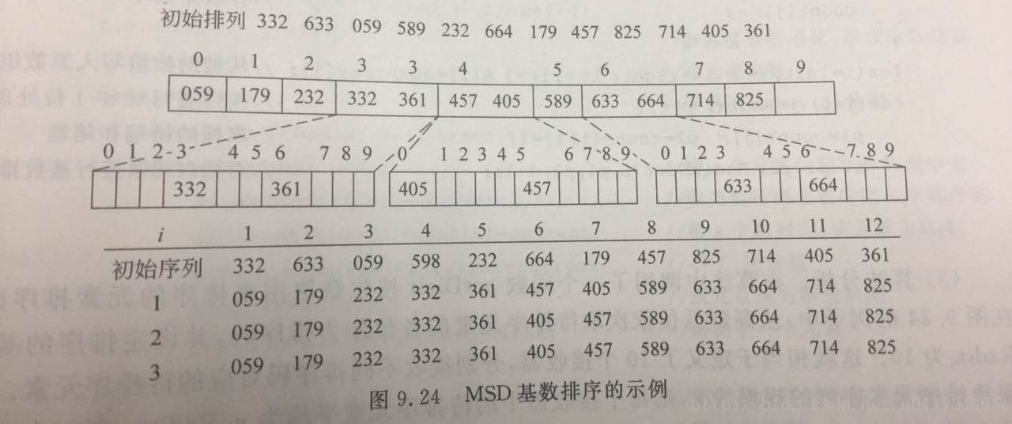
。例如,有一组元素,它们的排序码取值范围是0~999,如{332,633,059,598,232,664,179,457,825,714,405,361},可以把这些排序码看作是
(K1,K2,K3)
的组合,按
K1,K2,K3
的顺序对所有的元素做3次排序,如下图所示。
在排序过程中,首先是根据
K1
进行排序,按各个数据在百位上的取值,分配到各个子序列(称为桶)中,然后再按桶的编号对每个桶递归地进行基数排序。
步骤
- 算法要求事先设置Radix个桶,Radix叫做基数,即排序码的每一位可能取值的数目。为了知道每个桶中会有多少个元素,在算法中还设置了一个辅助数组
count[Radix]
,用
count[k]
记忆在处理第
i
位时第
i 位取值为 k 的元素有多少个。k 与基数 Radix 有关。如果 k 属于十进制整数,Radix 等于10。例如,在上图中当 i=1 时, count 各数组元素记忆了不同取值的元素个数, count[0]=1 表示值为0的元素有1个, count[3]=2 表示值为3的元素有2个。 - 在算法中还使用了一个辅助数组 auxArray[] 存放按桶分配的结果,根据 count[] 预先算定各桶元素的使用位置。在每一趟向各桶分配结束时,元素都被复制回原表中。
算法实现
#pragma once
#include<iostream>
#define RADIX 10
class MSDRaixSort
{
public:
MSDRaixSort(int length);
void create();
void sort();
void print();
~MSDRaixSort();
private:
int *elem;
int len;
void radixSort(int left, int right, int d);
int getDigit(int num, int d);
};
MSDRaixSort::MSDRaixSort(int length)
{
len = length;
elem = new int[len];
}
inline void MSDRaixSort::create()
{
std::cout << "please input the list" << std::endl;
for (int i = 0; i < len; i++)
{
int temp;
std::cin >> temp;
elem[i] = temp;
}
std::cout << "finish!" << std::endl;
}
inline void MSDRaixSort::sort()
{
radixSort(0, len - 1, 3);
}
inline void MSDRaixSort::print()
{
for (int i = 0; i < len; i++)
{
std::cout << elem[i] << " ";
}
std::cout << std::endl;
}
MSDRaixSort::~MSDRaixSort()
{
delete[] elem;
}
inline void MSDRaixSort::radixSort(int left, int right, int d) //MSD基数排序算法,从高位到低位对序列进行分配,实现排序
{ //其中d时位数,n时待排序元素的个数。left和right时待排序
int i, j, count[RADIX + 1], p1, p2; //元素子序列的始端和尾端,最低位d=1,最高位是d
int *auxArray = new int[right - left + 1];
if (d <= 0)
{
return;
}
for (j = 0; j < RADIX; j++)
{
count[j] = 0;
}
for (i = left; i <= right; i++) //统计各桶元素的个数
{
count[getDigit(elem[i], d)]++;
}
count[RADIX] = right - left + 1;
for (j = 1; j < RADIX; j++) //安排各桶元素位置
{
count[j] = count[j] + count[j - 1];
}
for (i = left; i <= right; ++i) {
j = getDigit(elem[i], d);
auxArray[count[j] - 1] = elem[i];
--count[j];
}
for (i = left, j = 0; i <= right; j++, i++) //从辅助数组auxArray写入原数组。
{
elem[i] = auxArray[j];
}
for (j = 0; j < RADIX; j++) //将各桶内的元素迭代进行MSD基数排序,直到桶内只有一个元素为止。
{
p1 = count[j];
p2 = count[j + 1] - 1;
if (p1 < p2)
{
radixSort(p1, p2, d - 1);
}
}
}
inline int MSDRaixSort::getDigit(int num, int d)
{
int count = 0;
while (num > 0) {
count++;
if (count == d)
{
return num % 10;
}
num = num / 10;
}
return 0;
}
//MSD基数排序main文件
using namespace std;
#include"MSDRadixSorting.h"
int main() {
MSDRaixSort m(15);
m.create();
m.sort();
m.print();
system("pause");
}算法分析
时间复杂度
在算法中调用一个getDigit按位获取用来排序的元素排序码。在上述例子中,从高位到低位一次取待排序元素的各位作为排序码,并设定排序的基数RADIX为10。这就相当于定义了10个接收器,分别接受不同排序码对应的待排序元素。如果待排序元素序列的规模为n,则每个接收器中的待排元素平局为 n/RADIX 。所以在基数排序算法中选择较大的基数有利于得到个数较多而规模较小的子序列划分,从而提高效率。但实际上,各个接收器中接收到的元素数目不可能是平局分配的,会有较大的差异,有可能出现很多空接收器。空接收器的大量存在会影响基数排序的效率。
空间复杂度
在算法中用到了两个数组,一个是
count
用于处理第
i
位的值得元素有多少个,用
算法的稳定性
MSD基数排序算法是稳定的。
LSD基数排序
思想
LSD基数排序抽取排序码的顺序和MSD基数排序正好相反。使用这种方法,把单排序码
ki
看成是一个
d
元组:利用“分配”和“收集”两种运算对单排序码进行排序。
如果对于所有元素的排序码
K0,K1,...,Kn−1
,依次对各位的分量
Kji
,让
j=d,d−1,...,1
,分别用这种“分配”和“收集”的运算逐趟进行排序,在最后一趟“分配”和“收集”完成后,所有元素就按其排序码的值从小到大排好序了。
各个桶都采用链式队列结构,分配到同一桶的排序码用链接指针链接起来。每一个桶设置两个队列指针:一个指向队头(第一个进入此队列的排序码),记为
intf[RADIX]
;一个指向队尾(最后一个进入此队列的排序码),记为
inte[RADIX]
。
待排序的
n
个元素组织成循环链表,
算法的实现
//LSD基数排序算法头文件
#pragma once
#include<iostream>
#define Radix 10
struct ElementType
{
int data;
int link;
};
class LSDRadixSort
{
public:
LSDRadixSort(int length);
void create();
void print();
void sort(int d); //排序核心部分
~LSDRadixSort();
private:
int len;
ElementType *elem;
int getDigit(int num, int d);
};
LSDRadixSort::LSDRadixSort(int length)
{
len = length;
elem = new ElementType[len + 1]; //由于elem[0]存储了排序的结果,所以分配空间的时候需要多一个
}
inline void LSDRadixSort::create()
{
std::cout << "please input the list: " << std::endl;
for (int i = 1; i <= len; i++)
{
std::cin >> elem[i].data;
}
std::cout << "finish!" << std::endl;
}
inline void LSDRadixSort::print() //结果都存储在elem[0]中,按顺序输出就行
{
int temp = 0;
while (elem[temp].link != 0)
{
temp = elem[temp].link;
std::cout << elem[temp].data << " ";
}
std::cout << std::endl;
}
inline void LSDRadixSort::sort(int d) //d表示位数,比如100,则d=3
{
int rear[Radix], front[Radix];
int i, j, k, last, current;
for (i = 0; i < len; i++) //elem[0]用于存储排序的结果
{
elem[i].link = i + 1;
}
elem[len].link = 0; //循环链表
for (i = 1; i <= d; i++) //从低位向高位排序
{
current = elem[0].link; //获得链表中第一个元素
for (j = 0; j < Radix; j++) //初始化front数组
{
front[j] = 0;
}
while (current)
{
k = getDigit(elem[current].data, i); //获取第i位
if (front[k] == 0) //如果该位没有元素,则放在front位置中。
{
front[k] = current;
}
else //否则,放在链表的尾部
{
elem[rear[k]].link = current;
}
rear[k] = current; //每次放入后改变链表的尾部位置
current = elem[current].link; //移向下一个目标
}
j = 0;
while (front[j] == 0) //找到第一个值不为0的front
{
++j;
}
elem[0].link = front[j]; //用elem[0]记录排序后的结果
last = rear[j]; //将链表的尾部串向下一个链表的头部,形成完整的链。
for (k = j + 1; k < Radix; ++k)
{
if (front[k] != 0)
{
elem[last].link = front[k];
last = rear[k];
}
}
elem[last].link = 0; //循环链表
}
}
LSDRadixSort::~LSDRadixSort()
{
delete[] elem;
}
inline int LSDRadixSort::getDigit(int num, int d) //取num的第d位余数
{
int count = 1;
while (num != 0)
{
if (count == d)
{
return num % 10;
}
num = num / 10;
count++;
}
return 0;
}
//LSD基数排序算法main文件
using namespace std;
#include "LSDRadixSort.h"
int main() {
LSDRadixSort m(10);
m.create();
m.sort(2);
m.print();
system("pause");
}结果
算法分析
时间复杂度
在此算法中,对于有n个元素的链表,每趟进行“分配”的while循环需要执行n次,把n个元素分配到Radix个队列中去。进行“收集”的for循环需要执行Radix次,从各个队列中把元素收集起来按顺序链接。若每个排序码有d位,需要重复执行d趟“分配”与“收集”,所以总的时间复杂度为 O(d(n+Radix)) 。若基数Radix,对于元素较多而排序码位数较少的情况,使用链式基数排序较好。
空间复杂度
在此算法中,使用了两个数组,一个是 front[Radix] ,另一个是 rear[Radix] ,故空间复杂度为 O(2∗Radix) 。
算法的稳定性
LSD基数排序是稳定的。
注:本文参考书籍《数据结构精讲与习题详解—考研辅导与答疑解惑》,殷人昆编著,清华大学出版社。















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









