






 本文讨论了在不同场景下如何选择数据库索引结构,如B树、哈希索引、跳表、SSTable、LSM树、后缀树、倒排索引和R树,强调了根据数据存储位置、数据格式、搜索需求和操作类型来优化性能的关键性。
本文讨论了在不同场景下如何选择数据库索引结构,如B树、哈希索引、跳表、SSTable、LSM树、后缀树、倒排索引和R树,强调了根据数据存储位置、数据格式、搜索需求和操作类型来优化性能的关键性。
无论数据存储于磁盘还是内存,我们都需要有一种高效的数据结构来访问和获取数据。
那么我们应该选用哪一种索引结构呢?我们需要考虑如下几个因素:
-
数据存储于内存还是磁盘?
-
数据格式和结构是怎样的?是字符串,数字,还是地理坐标?
-
搜索时是否需要精确匹配?是否需要容忍一定的输入错误?
-
系统是读操作多还是写操作多?
我们来看看 8 种常用的数据库索引结构。
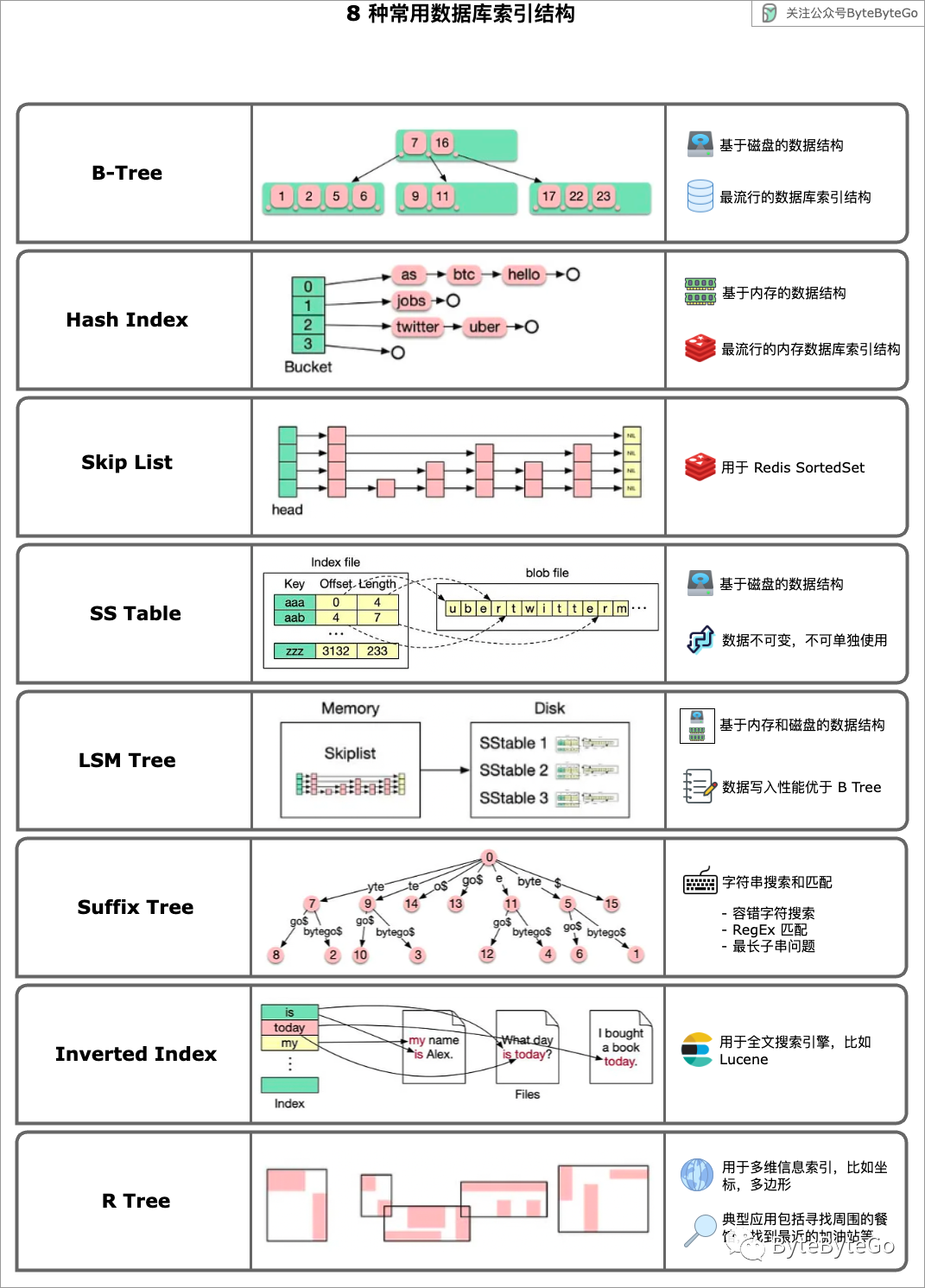
-
B 树
B 树/B+ 树作为最流行的数据库索引数据结构,是基于磁盘的解决方案,其读/写性能稳定。不同于传统的二叉树,B 树的单个节点中可以存储大量的键值,这样树的高度较低,可以加快搜索和插入元素的速度,减少磁盘的 I/O 操作。B 树的时间复杂度为 O(logN)。
-
Hash Index(哈希索引)
Map 数据结构的常用实现。哈希值映射到存储桶,该存储桶存储数据的偏移值。这样我们可以根据键值很快地查找数据。
-
Skiplist(跳表)
一种常见的内存索引类型,在 Redis SortedSet 中使用。跳表解决了链表搜索效率低下的问题。每个节点都包含几个前向指针,因此我们不被遍历过程中的步长所限制,可以跳过一些节点来加快搜索速度。
-
SSTable(Sorted String Table)
SSTable 是 Apache Cassandra 和其他 NoSQL 数据库使用的一种持久性文件格式。它可以对 memtable 里的内存数据进行排序以便快速访问,并将其存储在磁盘上的持久有序、不可变的一组文件中。不可变意味着 SSTables 永远不会被修改。它们稍后会合并到新的 SSTables 中,或者随着数据的更新而被删除。SSTable 与 LSM Tree 一起使用。与 B 树相比,这种结构对于写入量大、快速增长的超大数据集效率更高。
-
LSM 树(Log-Structured Merge Tree)
LSM Tree 在 SSTable 的基础上提供一整套存储解决方案。它由两层结构组成:memtable (内存)和 SSTable(磁盘)。新数据先写入 memtable 中,如果 memtable 过大,那就会 flush 到磁盘的 SSTable 上。各个 SSTable 上会有重复的键值,在一段时间后会进行合并压缩。我们可以看到,每个写入请求实际上都只在内存中进行,所以 LSM Tree 的写入吞吐量明显高于 B Tree。
-
Suffix Tree(后缀树)
后缀树通常用于存储字符串列表。它也被称为 Trie 的压缩版本。后缀树常用于字符串的搜索和匹配,比如容忍一定输入错误的字符搜索,正则表达式匹配,最长子串问题等。
-
Inverted Index(倒排索引)
用于高效的文档索引,比如 Lucene。在倒排索引中,索引按单词进行组织,每个单词都指向包含该单词的文档列表。
-
R 树
用于多维信息的搜索,包含地理坐标、矩形、多边形等。我们可以借助这种索引来搜索附近的餐馆,找到最近的加油站,检索附近所有路段等。


















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









