






朋友们大家好,今天再开一博说一下自己在学习爬虫练习时遇到的问题及解决办法
1、首先得承认,任何方式的偷盗行为都不在法律的保护范围之内,要是偷自己的东西呢,就另当别论了,douban 还是相当仁义的,只挡一道墙,你只要能越过我的墙,进入的是你家的院子,你随便拿吧。
2、翻过douban的墙,很多网站都反爬的很好的,比如汽车之家,你界面上看到的内容,大部分都是加密的,汽车之前最常用的好像是css 对照加的,你拿汽车之家的数据,拿回来的内容大部份都 :: befor,:: content 我只类比一下,那有没有办法爬汽车之家呢,办法很显然,你只要拿到他的对称加密的方法,原生的对照回来就好了,当然汽车之家也不傻,他基本上每隔一段时间就变一下
3、讲一下爬虫最基本的翻人家墙的方法,IP代理池,用户代理池,什么IP代理池(那不是要自己写一个很长很长的list?那我去哪里搞IP呢,办法是有的“西刺代理”免费版,but 我不建议大家这样玩,建议使用收费的,调用他们的接口就好了,原因很简单,你写完你的IP代理池的时候,前边的已经有N多的不能用了,而且你写程序的时候还要循环这个代理池呢!那么用户代理池呢,原理与IP代理池一样,你要模拟不同用户在登陆你要爬的网站)
4、翻人家墙的方式还有什么呢?答案N多,我也在学习中!~好了,开始最基本的三板斧,settings设置
4-1、robots,false, 如果遵循robots协议,人家就会跟你说,我这个网站上那些是不能爬的,所以你要false
4-2、cookie,true,这个不讲了大家应该都知道
4-3、 user_agnet,当然前边提到了你如果用户代理池,可以忽略这部分,还有一种就是setting里边不设置,可以在爬虫中设置
4-4、 pipelines,打开它,要问为什么不?原理很简单,你使用scrapy框架,你就要单纯的认为在pipelines处理你的数据,就是比你自己写的方法处理快,不信!,不信你试试看吧,试完了通知我,我也学习一下
5、items要不要定义呢,取决于你自己的爱好吧,当然如果4-4你要使用了,你就需要定义你的items了
6、开始我们的爬虫吧,以上是我的建议,各人有各人的办法,俗话说:“小鸡不尿尿,各有各的道”
7、分析一下我们要干的事情,登录douban
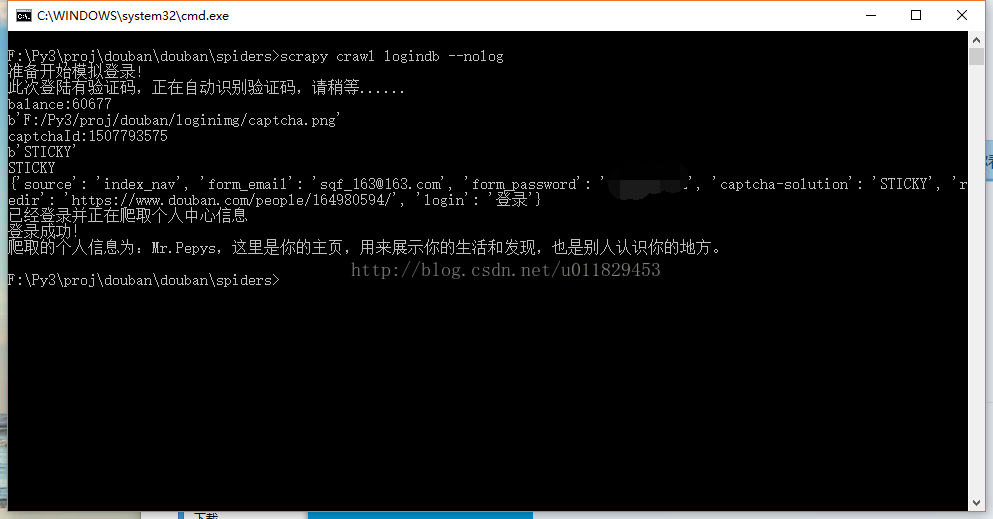
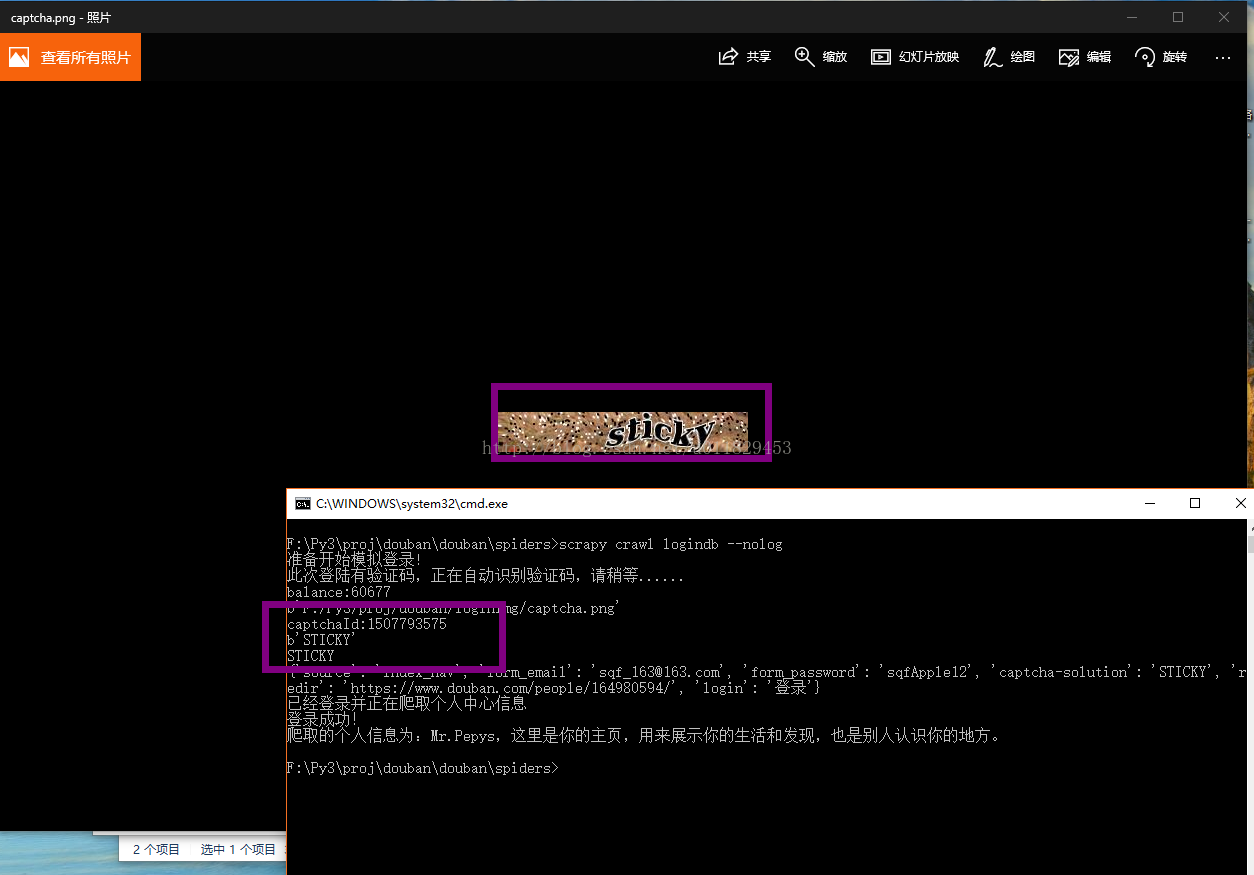
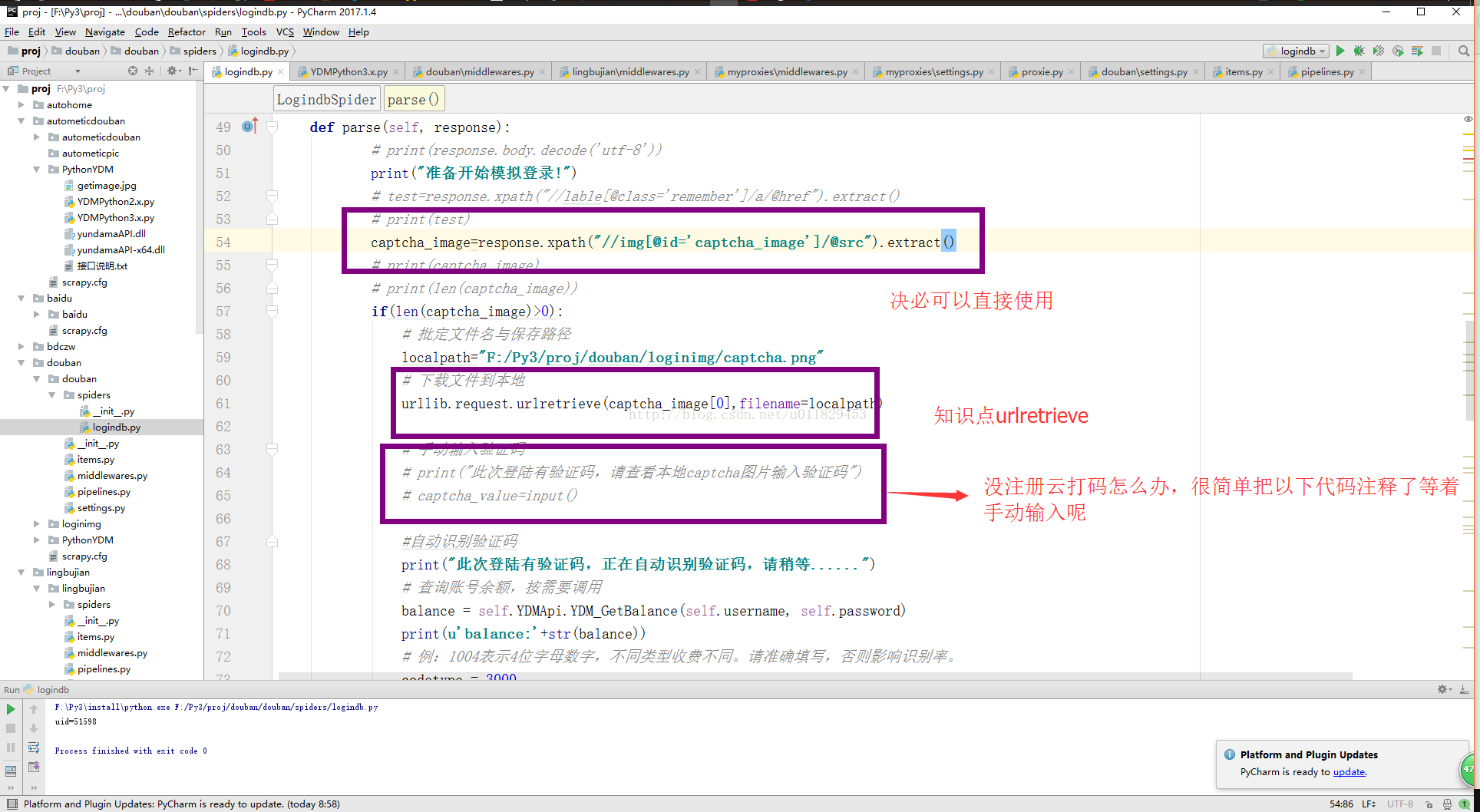
7-1、拿着你的各个账号多登录几次,What happened?,对相信你的感觉,fu?k,captchar!!! 验证码出现了,不用慌,douban兄弟很仗义没使用特复杂的,只使用了一个不定长的英文当验证码
7-2、使用的知识点,urllib.reques或着 requests 都可以
7-3、xpath 表达式
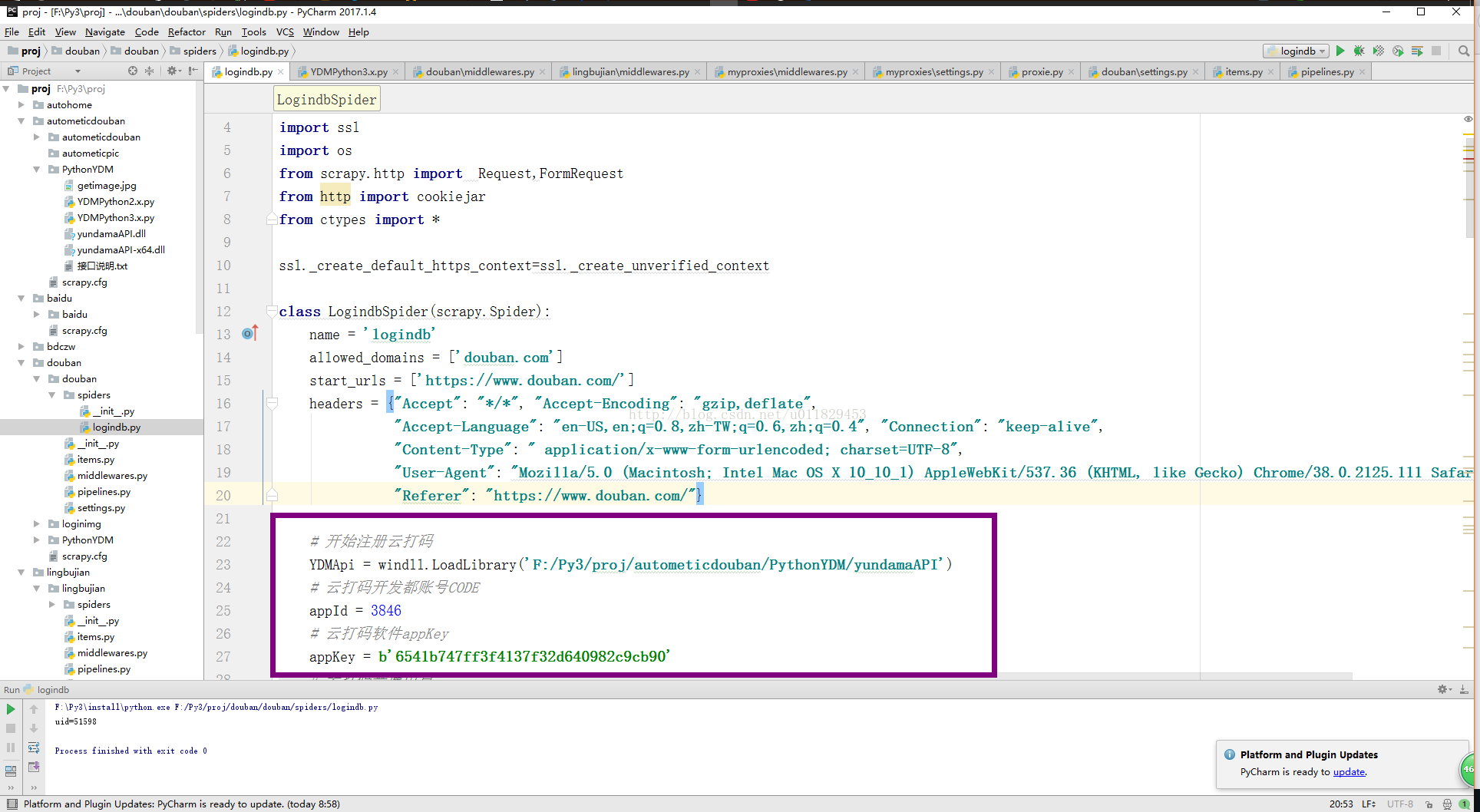
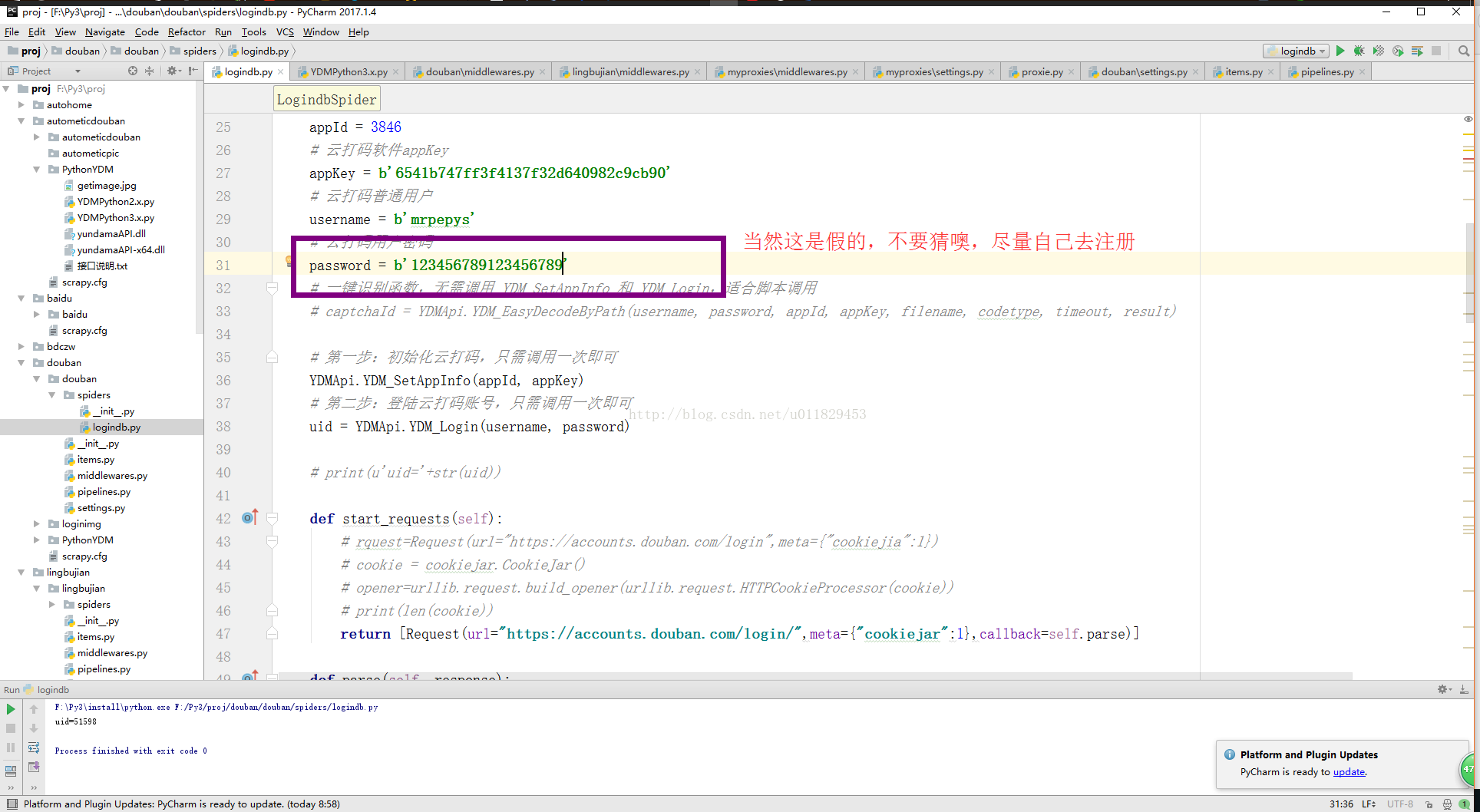
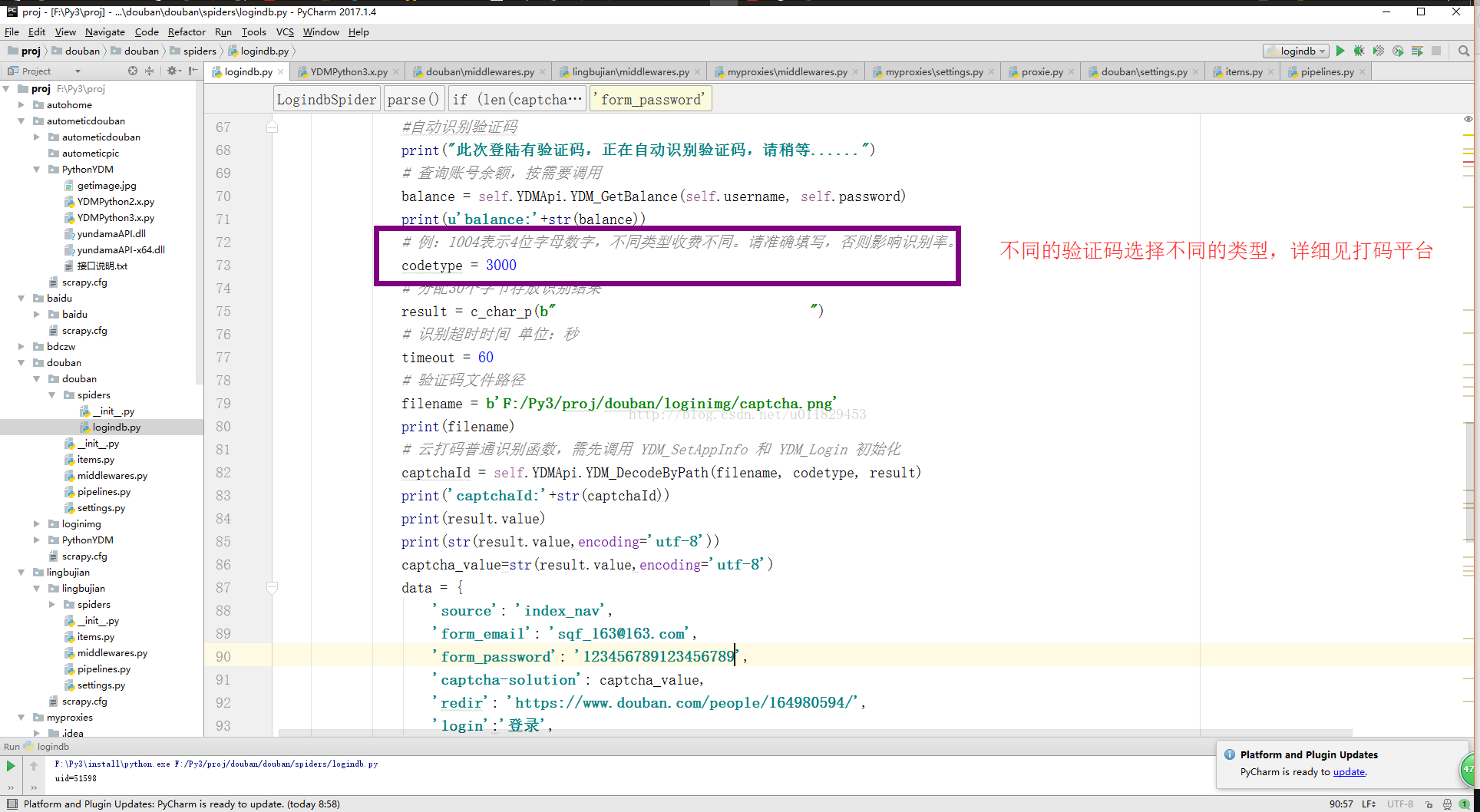
7-4、识别验证码(我推荐云打码)你即可以当开发者,同时有可以当使用者,关键是还有一个好处,你使用开发者创建一个应该程序拿着你的appkey还能给你返利,可算看到回头钱了
7-5、 下载并识别
urllib.request.urlretrieve(captcha_image[0],filename=localpath) 对下载你的captchar,调用你本地的云打码识别captchar
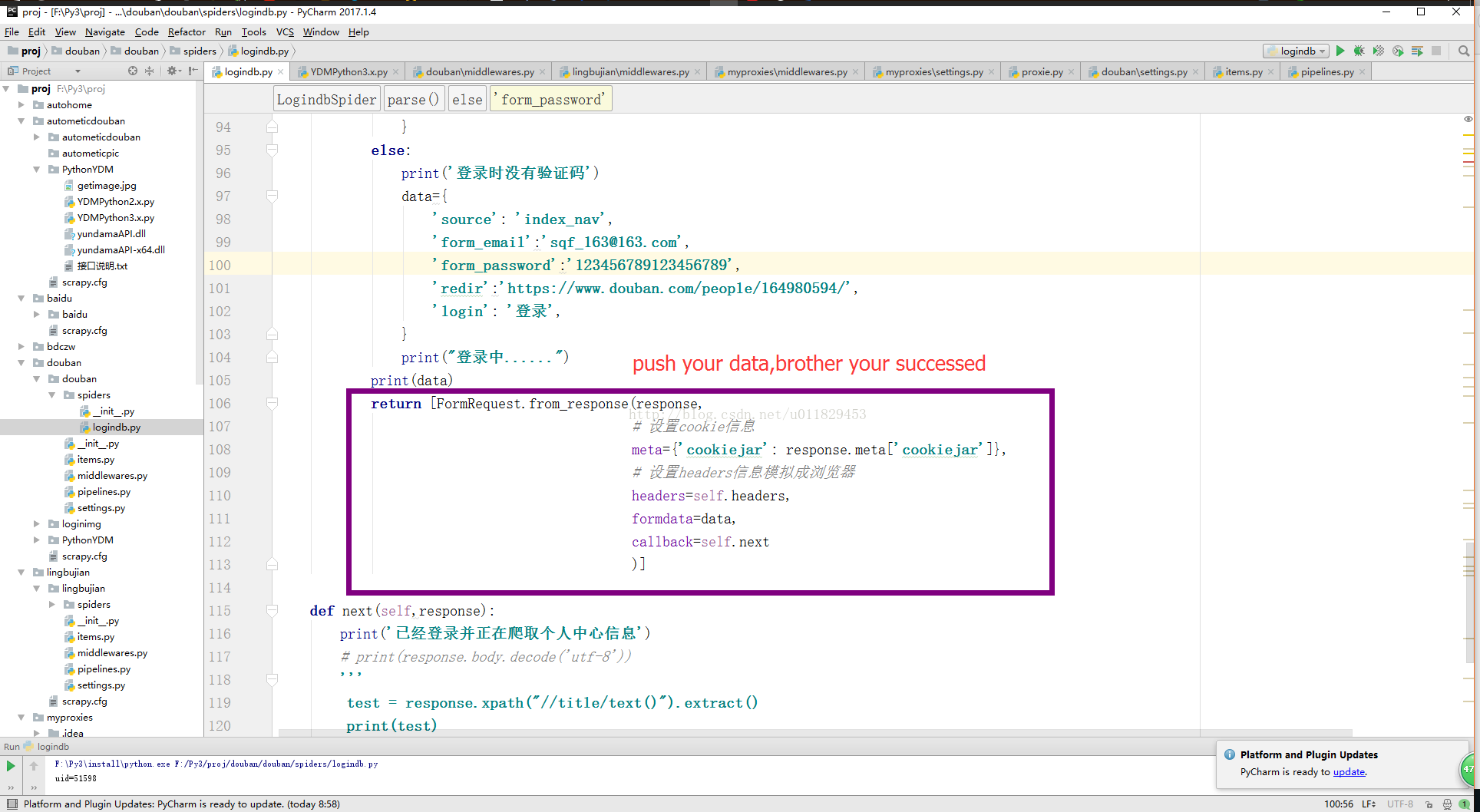
7-6、 pushi your data
data={ 'source': 'index_nav', 'form_email':'sqf_163@163.com', 'form_password':'124567894545', 'redir':'https://www.douban.com/people/164980594/', 'login': '登录', }
return [FormRequest.from_response(response,# 设置cookie信息 meta={'cookiejar': response.meta['cookiejar']}, # 设置headers信息模拟成浏览器 headers=self.headers, formdata=data, callback=self.next )]
7-7、对哥们你成功了,剩下的^_^,哈哈,哥们你自己干吧,到这里模拟登陆就完成了,下边是图,请客官往下看,你现在就可以说我可以随便登陆我们公司自己开发的网站了“你懂得”
7-8、云打码的平台:http://www.yundama.com/
7-9、我的网盘提供一个python3调用你本地“云打码平台”提供的64位的dll文件,32位的我没有试验,我的机器是64位的,各位可以自己试验证一下
7-10、图来了

8、等我学习完了机器学校在来写一篇,我还是不想使用云打码的,^_^,^_^















 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









