






最近开始阅读 周志华教授《机器学习》,有一些经验跟心得拿来分享,并且在这边做些笔记,以来做知识总结和回顾
-------------------------------------------------------------------------------------------------------------------------------------------------------------
在入这个坑之前,先来了解下,什么是机器学习?
先来看这两张图


凭借我们的经验,左图眼睛、鼻子、嘴巴更显端正,更符合我们日常的审美,所以我们能很快得出一个结论,左图更加的漂亮。那么问题来了,机器并不是人,该如何辨别“谁更加漂亮”呢。
而机器学习正是基于类似的目的而诞生,它致力于研究如何通过计算的手段,利用经验来使得机器能跟人一样的来辨别分类。而“经验”就是如我们上面所说的,“眼睛更大更漂亮”,“鹅蛋脸更漂亮”等等这些我们的认知。
在计算机领域中,经验存储在数据中,因此通过学习数据,我们能得到这些“经验”,而通过“经验”来构成模型,在通过模型来辨别其他Machine不认识的妹子谁更漂亮,这就是机器学习。
------------------------------------------------------------------------------------------------------------------------------------------------------------
做为机器学习的第一站,先从决策树,最简单的开始

上图就是最简单的一种决策树,通过判断多种外观特征,来判断一个女孩是否“漂亮”(当然,这只是一个比较粗浅的判别方法~ - _-#)。不知各位看官有没有注意到,我把“脸型“这个属性放在第一位哈,为什么呢,“脸型”属性跟其他“胸”、“眉毛”属性有什么区别吗?(好可惜~)
这里就要引出来决策树里面一个非常重要的概念,叫做“信息增益”。
什么是信息增益呢?官方的解释是“度量样本集合纯度最常用的一种指标”有公式
信息增益:

D指当前的样本集,a指离散属性,其中Ent(D)被称作信息熵,公式为:

其中pk是指第K类样本所占的比例。 最后算出的Gain值越小,则代表纯度越高。
这样看似乎太过于绕人了,不过数学公式仍然是要介绍。现在我们用这两个公式来解决之前关于为什么要选“脸型”做为第一个分支属性的原因。
下面是数据集1.0,规模不大,不过做为测试勉强够用了
| 编号1 | 胸 | 脸型 | 眉毛 | 漂亮 |
| 1 | A | 圆 | 柳叶 | 否 |
| 2 | B | 圆 | 剑眉 | 否 |
| 3 | B | 鹅蛋 | 剑眉 | 是 |
| 4 | C | 圆 | 柳叶 | 是 |
| 5 | A | 国字 | 一字 | 否 |
| 6 | A | 圆 | 一字 | 否 |
| 7 | C | 鹅蛋 | 剑眉 | 是 |
| 8 | B | 圆 | 柳叶 | 否 |
| 9 | C | 国字 | 一字 | 否 |
我们运用信息熵公式可得出

然后,我们要计算出当前的属性{“胸”,“脸型”,“眉毛”}中每个属性的信息增益,来确定需要选择哪个属性做为第一分支属性。
我们以“胸”来举例,可以更为直观的明白这里面的门道。
那观察数据集D,我们很容易发现,属性“胸”有三个属性值,分别是{A,B,C},我们把它们记住三个子集,D1,D2,D3数据集的详细内容如下
D1(胸=A)= {1,5,6}
D2(胸=B)= {2,3,8}
D3(胸=C)= {4,7,9}
由此,我们可以轻易的计算出每个子集(分支节点)的信息熵:
Ent(D1) = 0
Ent(D2) = 0.918
Ent(D3) = 0.918
算出分支属性之后,我们还差最后一步就可算出“胸”的信息增益

信息增益越大,那么使用属性a来对样本集D划分所获得的“纯度提升越大”。简单点说就是,Gain值越大,则就选用此来划分。
Gain(D,脸型) = 0.517
Gain(D,五官) = 0.306
最后结果很明显,我们得到最大的信息增益来自于脸型,因此,这就是为什么我们要选择“脸型”做为第一分支属性的原因。
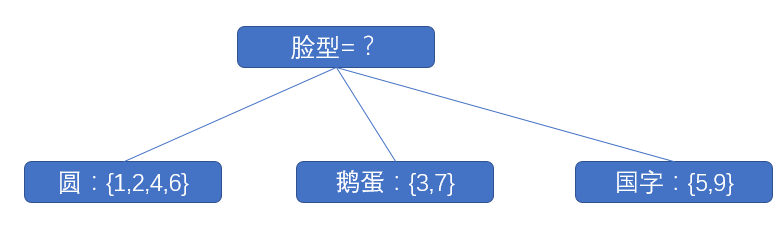
我们可以根据 “脸型”的三个属性值,将脸型分为三个数据集,分别是D圆,D鹅蛋,D国字。在新的数据集上,我们则只需要考虑计算两个属性的信息增益,分别是“胸”,
“眉毛”(因为脸型已经作为了分支节点),步骤仍然是跟上文一样的步骤,并最终得到决策树。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









