







 本文深入探讨了信息熵的概念,解释了其作为衡量不确定性的重要指标,并详细介绍了信息熵在决策树和主动学习等机器学习领域的应用。通过具体实例,展示了不同事件发生概率下信息熵的变化,帮助读者理解其计算原理。
本文深入探讨了信息熵的概念,解释了其作为衡量不确定性的重要指标,并详细介绍了信息熵在决策树和主动学习等机器学习领域的应用。通过具体实例,展示了不同事件发生概率下信息熵的变化,帮助读者理解其计算原理。
熵
来自维基百科的定义:
在信息论中,熵(英语:entropy)是接收的每条消息中包含的信息的平均量,又被称为信息熵、信源熵、平均自信息量。这里,“消息”代表来自分布或数据流中的事件、样本或特征。
熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。
普遍人物熵是代表了混乱程度,熵越大,则越混乱。
信息熵
信息熵(Information Entropy)是度量样本集合纯度最常用的一种指标。假定当前样本集合 D D D中第 k k k类样本所占的比例为 p k ( k = 1 , 2 , . . . , ∣ Y ∣ ) p_k(k = 1,2,...,|Y|) pk(k=1,2,...,∣Y∣),则 D D D的信息熵定义为
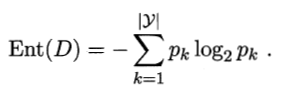
E n t ( D ) Ent(D) Ent(D)的值越小,则 D D D的纯度越高。
举例说明:
以下事件发生概率和为 1 1 1:
- 两个事件,事件 A A A发生概率为 1 1 1,事件 B B B发生概率为 0 0 0,经计算信息熵为0。
- 两个事件,事件 A A A发生概率为 1 / 3 1/3 1/3,事件 B B B发生概率为 2 / 3 2/3 2/3,经计算信息熵为0.918。
- 两个事件,每个事件发生的概率为 1 / 2 1/2 1/2,经计算信息熵为1。
- 三个事件,每个事件发生的概率为 1 / 3 1/3 1/3,经计算信息熵为1.585。
- 四个事件,每个事件发生的概率为 1 / 4 1/4 1/4,经计算信息熵为2。
可见事件发生的种种情况中,越稳定,则信息熵越小。
部分应用
1. 决策树
决策树中ID3算法利用信息增益进行计算,C4.5算法利用增益率进行计算,均用到了信息熵。

2. 主动学习 Active Learning
-
在Uncertainty Sampling策略中计算不确定度可以利用信息熵,根据预测类别的混乱程度判断不确定度。
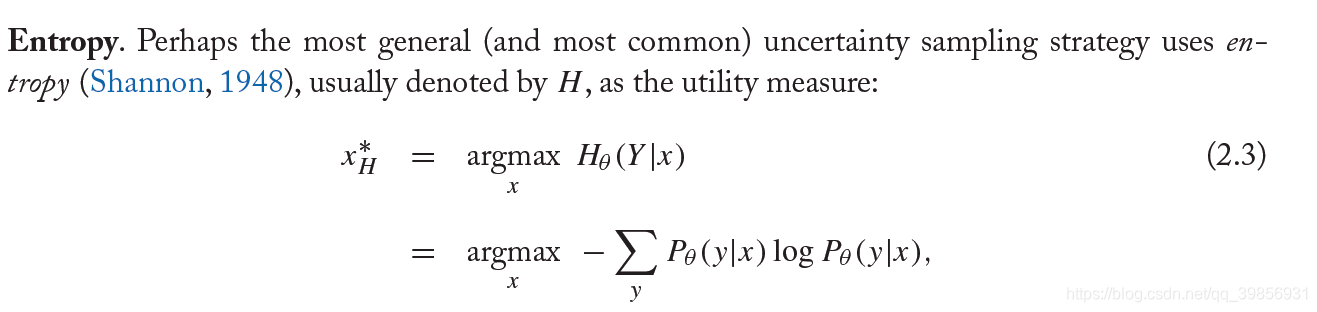
-
在Query by Committee策略中选择query instance时也利用到了信息熵,根据投票结果的混乱程度。

参考
部分参考:
《机器学习》, 周志华, 2012
Active Learning, B Settles, 2012.


















 669
669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









