







1、执行计划的解释
1.1 EXPLAIN命令
在关系型数据库中,一般使用EXPLAIN命令来显示SQL命令的执行计划,只是不同的数据库中,该命令的具体格式有一些差别。
PostgreSQL中EXPLAIN命令的语法格式如下:
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
该命令的可选项“options”如下:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
BUFFERS [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }
ANALYZE选项通过实际执行SQL来获得SQL命令的实际执行计划。ANALYZE选项查看到的执行计划因为真正被执行过,所以可以看到执行计划每一步耗费了多长时间,以及它实际返回的行数。
加上ANALYZE选项后是真正执行实际的SQL命令,如果SQL语句是一个插入、删除、更新或CREATE TABLE AS语句(这些语句会修改数据库),为了不影响实际数据,可以把EXPLAIN ANALYZE放到一个事务中,执行完后即回滚事务,命令如下:
BEGIN
EXPLAIN ANALYZE...;
ROLLBACK;VERBOSE选项显示计划的附加信息,如计划树中每个节点输出的各个列,如果触发器被触发,还会输出触发器的名称。该选项的值默认为“FALSE”。
COSTS选项显示每个计划节点的启动成本和总成本,以及估计行数和每行宽度。该选项的值默认为“TRUE”。
BUFFERS选项显示缓冲区使用的信息。该参数只能与ANALYZE参数一起使用。显示的缓冲区信息包括共享块读和写的块数、本地块读和写的块数,以及临时块读和写的块数。共享块、本地块和临时块分别包含表和索引、临时表和临时索引,以及在排序和物化计划中使用的磁盘块。上层节点显示出来的块数包括所有其子节点使用的块数。该选项的值默认为“FALSE”。
FORMAT选项指定输出格式,输出格式可以是TEXT、XML、JSON或者YAML。非文本输出包含与文本输出格式相同的信息,但其他程序更易于解析。该参数默认为“TEXT”。
1.2 EXPLAIN输出结果解释
maxwelldb=# explain select * from playground;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on playground (cost=0.00..12.80 rows=280 width=262)
(1 row)
maxwelldb=# 上面的运行结果中“Seq Scan on playground”表示顺序扫描表“playground”,顺序扫描也就是全表扫描,即从头到尾地扫描表。后面的内容“(cost=0.00..12.80 rows=280width=262)”可以分为以下3个部分。·cost=0.00..12.80:“cost=”后面有两个数字,中间由“..”分隔,第一个数字“0.00”表示启动的成本,也就是说,返回第一行需要多少cost值;第二个数字表示返回所有数据的成本,关于成本“cost”后面会解释。
·rows=280:表示会返回280行。·
width=262:表示每行平均宽度为262字节。
成本“cost”用于描述SQL命令的执行代价,默认情况下,不同操作的cost值如下:
·顺序扫描一个数据块,cost值定为“1”。
·随机扫描一个数据块,cost值定为“4”。·
处理一个数据行的CPU代价,cost值定为“0.01”。·
处理一个索引行的CPU代价,cost值定为“0.005”。·
每个操作符的CPU代价为“0.0025”。
根据上面的操作类型,PostgreSQL可以智能地计算出一个SQL命令的执行代价,虽然计算结果不是很精确,但大多数情况下够用了。
1.3 EXPLAIN使用示例
默认情况下输出的执行计划是文本格式,但也可以输出JSON格式。
maxwelldb=# explain(format json) select * from playground;
QUERY PLAN
--------------------------------------
[ +
{ +
"Plan": { +
"Node Type": "Seq Scan", +
"Parallel Aware": false, +
"Relation Name": "playground",+
"Alias": "playground", +
"Startup Cost": 0.00, +
"Total Cost": 12.80, +
"Plan Rows": 280, +
"Plan Width": 262 +
} +
} +
]
(1 row)
maxwelldb=# 也可以输出XML格式,示例如下:
maxwelldb=# explain (format xml) select * from playground;
QUERY PLAN
----------------------------------------------------------
<explain xmlns="http://www.postgresql.org/2009/explain">+
<Query> +
<Plan> +
<Node-Type>Seq Scan</Node-Type> +
<Parallel-Aware>false</Parallel-Aware> +
<Relation-Name>playground</Relation-Name> +
<Alias>playground</Alias> +
<Startup-Cost>0.00</Startup-Cost> +
<Total-Cost>12.80</Total-Cost> +
<Plan-Rows>280</Plan-Rows> +
<Plan-Width>262</Plan-Width> +
</Plan> +
</Query> +
</explain>
(1 row)
maxwelldb=# 还可以输出YAML格式
maxwelldb=# explain (format YAML) select * from playground;
QUERY PLAN
---------------------------------
- Plan: +
Node Type: "Seq Scan" +
Parallel Aware: false +
Relation Name: "playground"+
Alias: "playground" +
Startup Cost: 0.00 +
Total Cost: 12.80 +
Plan Rows: 280 +
Plan Width: 262
(1 row)
maxwelldb=# 添加“analyze”参数,通过实际执行来获得更精确的执行计划,命令如下:
maxwelldb=# explain analyze select * from playground;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Seq Scan on playground (cost=0.00..12.80 rows=280 width=262) (actual time=0.009..0.009 rows=1 loops=1)
Planning Time: 0.036 ms
Execution Time: 0.021 ms
(3 rows)
maxwelldb=# 从上面的运行结果中可以看出,加了“analyze”参数后,可以看到实际的启动时间(第一行返回的时间)、执行时间、实际的扫描行数(actual time=0.009..0.009 rows=1 loops=1),其中启动时间为0.009毫秒,返回所有行的时间为0,009毫秒,返回的行数是1。
analyze选项还有另一种语法,即放在小括号内,得到的结果与上面的结果完全一致,示例如下:
maxwelldb=# explain (analyze true) select * from playground;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Seq Scan on playground (cost=0.00..12.80 rows=280 width=262) (actual time=0.010..0.011 rows=1 loops=1)
Planning Time: 0.061 ms
Execution Time: 0.025 ms
(3 rows)
maxwelldb=# 如果只查看执行的路径情况而不看cost值,则可以加“(costs false)”选项,命令如下:
maxwelldb=# explain (costs false) select * from playground;
QUERY PLAN
------------------------
Seq Scan on playground
(1 row)
maxwelldb=# 联合使用analyze选项和buffers选项,通过实际执行来查看实际的代价和缓冲区命中的情况,命令如下:
maxwelldb=# explain (analyze true,buffers true) select * from playground;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Seq Scan on playground (cost=0.00..12.80 rows=280 width=262) (actual time=0.008..0.010 rows=1 loops=1)
Buffers: shared hit=1
Planning Time: 0.037 ms
Execution Time: 0.021 ms
(4 rows)
maxwelldb=# 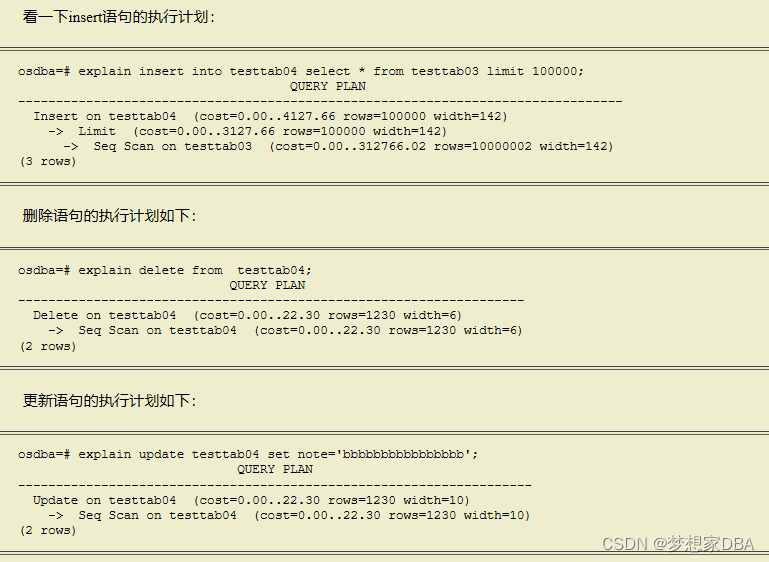
1.4 全表扫描
全表扫描在PostgreSQL中也称顺序扫描(Seq Scan),全表扫描就是把表中的所有数据块从头到尾读一遍,然后从中找到符合条件的数据块。
全表扫描在EXPLAIN命令的输出结果中用“Seq Scan”表示,示例如下:
maxwelldb=# EXPLAIN select * from playground;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on playground (cost=0.00..12.80 rows=280 width=262)
(1 row)
maxwelldb=# 1.5 索引扫描
索引通常是为了加快查询数据的速度而增加的。索引扫描,就是在索引中找出需要的数据行的物理位置,然后再到表的数据块中把相应的数据读出来的过程。
索引扫描在EXPLAIN命令的输出结果中用“Index Scan”表示,示例如下:

1.6 位图扫描
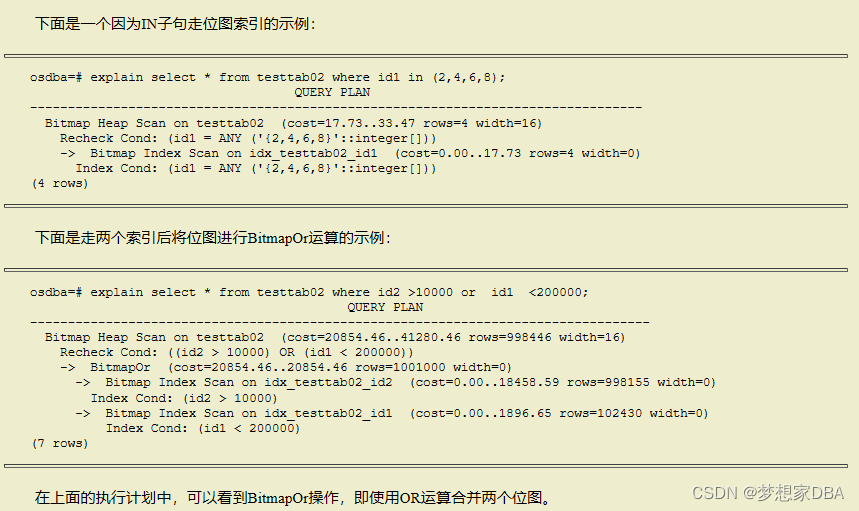
位图扫描也是走索引的一种方式。方法是扫描索引,把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图到表的数据文件中把相应的数据读出来。如果走了两个索引,可以把两个索引形成的位图通过AND或OR计算合并成一个,再到表的数据文件中把数据读出来。
当执行计划的结果行数很多时会走这种扫描,如非等值查询、IN子句或有多个条件都可以走不同的索引时。
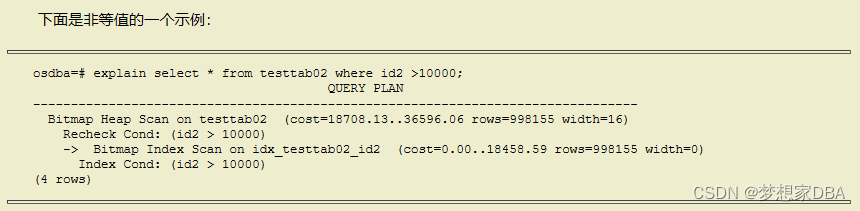
在位图扫描中可以看到,“Bitmap Index Scan”先在索引中找到符合条件的行,然后在内存中创建位图,再到表中扫描,也就是我们看到的“Bitmap Heap Scan”。大家还会看到“Recheck Cond:(id2>10000)”,这是因为多版本的原因,从索引中找出的行从表中读出后还需要再检查一下条件。
1.7 条件过滤
条件过滤,一般就是在WHERE子句上加过滤条件,当扫描数据行时会找出满足过滤条件的行。条件过滤在执行计划中显示为“Filter”。
如果条件的列上有索引,可能会走索引而不走过滤。
1.8 嵌套循环连接
嵌套循环连接(NestLoop Join)是在两个表做连接时最朴素的一种连接方式。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1万不适合),要把返回子集较小的表作为外表,而且在内表的连接字段上要有索引,否则速度会很慢。
执行的过程如下:确定一个驱动表(Outer Table),另一个表为Inner Table,驱动表中的每一行与Inner Table表中的相应记录Join类似一个嵌套的循环。适用于驱动表的记录集比较小(<10000)而且Inner Table表有有效的访问方法(Index)。需要注意的是,Join的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间才是最快的。
1.9 散列连接
优化器使用两个表中较小的表,利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表可以完全放于内存中的情况,这样总成本就是访问两个表的成本之和。但是如果表很大,不能完全放入内存,优化器会将它分割成若干不同的分区,把不能放入内存的部分写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O的性能。

1.10 合并连接
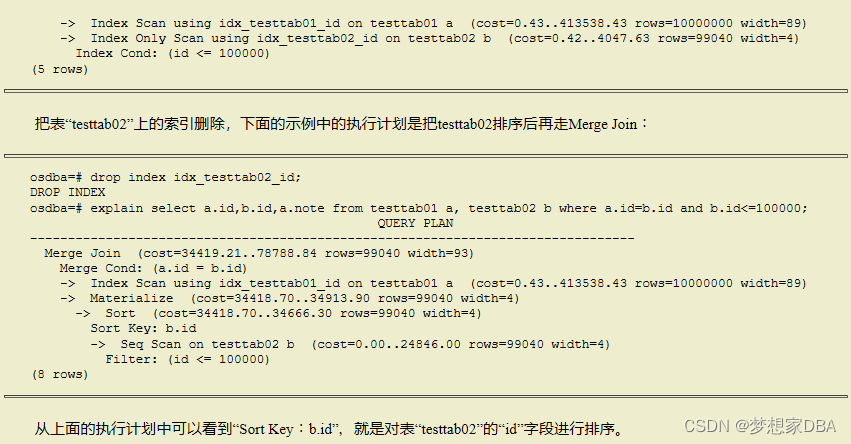
通常情况下,散列连接的效果比合并连接要好,然而如果源数据上有索引,或者结果已经被排过序,此时执行排序合并连接不需要再进行排序,合并连接的性能会优于散列连接。
下面的示例中,表“testtab01”的“id”字段上有索引,表“testtab02”的“id”字段上也有索引,这时从索引扫描的数据已经排好序了,就可以直接进行合并连接(Merge Join):

2.与执行计划相关的配置项
2.1 ENABLE_*参数
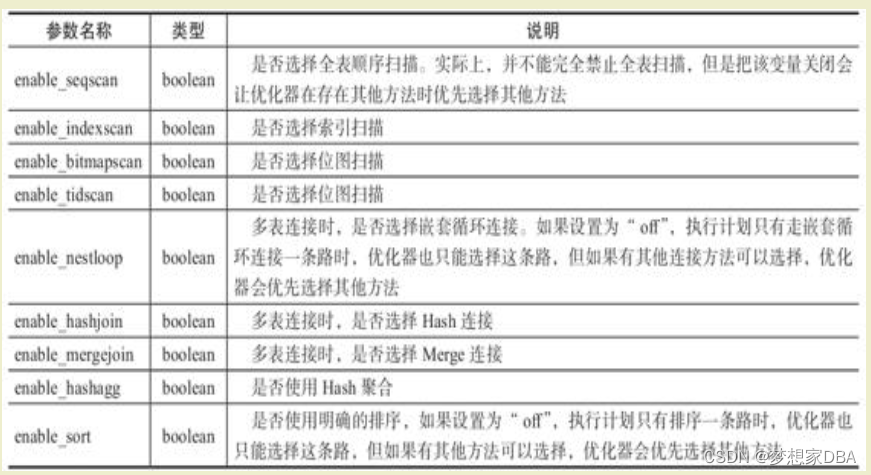
在PostgreSQL中有一些以“ENABLE_”开头的参数,这些参数提供了影响查询优化器选择不同执行计划的方法。有时,如果优化器为特定查询选择的执行计划并不是最优的,可以设置这些参数强制优化器选择一个更好的执行计划来临时解决这个问题。一般不会在PostgreSQL中配置来改变这些参数值的默认值,因为通常情况下,PostgreSQL不会走错执行计划。PostgreSQL走错执行计划是统计信息收集得不及时导致的,可通过更频繁地运行ANALYZE来解决这个问题,使用“ENABLE_”只是一个临时的解决方法。这些参数的详细说明见表9-1。
2.2 COST基准参数
执行计划在选择最优路径时,不同路径的cost值只有相对意义,同时缩放它们将不会对不同路径的选择产生任何影响。默认情况下,它们以顺序扫描一个数据块的开销作为基准单位,也就是说,将顺序扫描的基准参数“seq_page_cost”默认设为“1.0”,其他开销的基准参数都对照它来设置。从理论上来说也可以使用其他基准方法,如以毫秒计的实际执行时间作基准,但这些基准方法可能会更复杂一些。这些COST基准值参数如表所示。

在上面的配置项中,“seq_page_cost”一般作为基准,不用改变。可能需要改变的是“random_page_cost”,如果在读数据时,数据基本都命中在内存中,这时随机读和顺序读的差异不大,可能需要把“random_page_cost”的值调得小一些。如果想让优化器偏向走索引,而不走全表扫描,可以把“random_page_cost”的值调得低一些。
2.3 基因查询优化的参数
GEQO是一个使用探索式搜索来执行查询规划的算法,它可以缩短负载查询的规划时间。GEQO的检索是随机的,因此它生成的执行计划会有不可确定性。基因查询优化器的相关的配置参数如表9-3所示。

当没有很多表做关连查询时,并不需要关注这些基因查询优化器的参数,因为此时基本不会走基因查询,只有当关连查询表的数目超过“geqo_threshold”配置项时才会走基因查询优化算法。如果不清楚基因查询的原理,不能理解以上参数,保留它们的默认值就可以了。
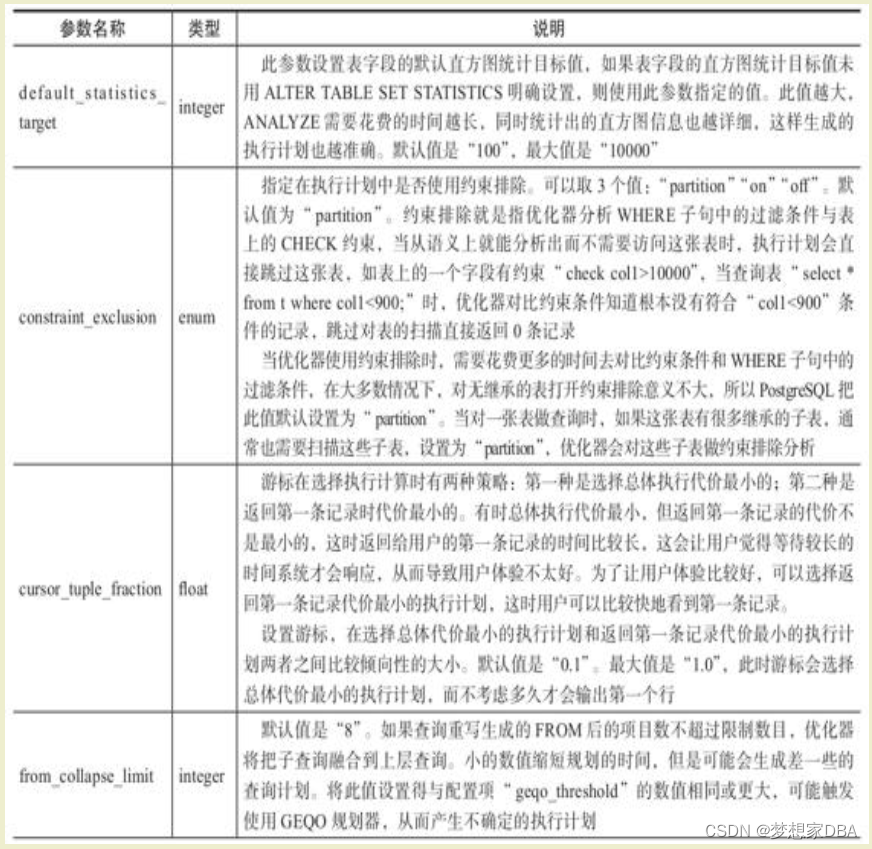
2.4 其他执行计划配置项

3.统计信息的收集
信息主要是AutoVacuum进程收集的,用于查询优化时的代价估算。表和索引的行数、块数等统计信息记录在系统表“pg_class”中,其他的统计信息主要收集在系统表“pg_statistic”中。而Stats Collector子进程是PostgreSQL中专门的性能统计数据收集器进程,其收集的性能数据可以通过“pg_stat_*”视图来查看,这些性能统计数据对数据库活动的监控及分析性能有很大的帮助。
3.1 统计信息收集器的配置项

3.2 SQL执行的统计信息输出
可以使用以下4个boolean类型的参数来控制是否输出SQL执行过程的统计信息到日志中:
·log_statement_stats。
·log_parser_stats。
·log_planner_stats。
·log_executor_stats。
参数“log_statement_stats”控制是否输出所有SQL语句的统计信息,其他的参数控制每个SQL命令是否输出不同执行模块中的统计信息。
3.3 手动收集统计信息
手动收集统计信息的命令是ANALYZE命令,此命令用于收集表的统计信息,然后把结果保存在系统表“pg_statistic”中。优化器可以使用收集到的统计信息来确定最优的执行计划。
在默认的PostgreSQL配置中,AutoVacuum守护进程是打开的,它能自动分析表、收集表的统计信息。当AutoVacuum进程关闭时,需要周期性地,或者在表的大部分内容变更后运行ANALYZE命令。准确的统计信息能帮助优化器生成最优的执行计划,从而改善查询的性能。比较常用的一种策略是每天在数据库比较空闲的时候运行一次VACUUM和ANALYZE命令。
ANALYZE命令的语法格式如下:
ANALYZE [ VERBOSE ] [ table [ ( column [, ...] ) ] ]命令中的选项说明如下。
·VERBOSE:增加此选项将显示处理的进度以及表的一些统计信息。
·table:要分析的表名,如果不指定,则对整个数据库中的所有表进行分析。
·column:要分析的特定字段的名称。默认分析所有字段。
ANALYZE命令只需在表上加一个读锁,因此它可以与表上的其他SQL命令并发执行。ANALYZE命令会收集表的每个字段的直方图和最常用数值的列表。
对于大表,ANALYZE命令只读取表的部分内容做一个随机抽样,不读取表的所有内容,这样就保证了即使是在很大的表上也只需要很少时间就可以完成统计信息的收集。统计信息只是近似的结果,即使表内容实际上没有改变,运行ANALYZE命令后EXPLAIN命令显示的执行计划中的COST值也会有一些变化。为了增加所收集的统计信息的准确度,可以增大随机抽样比例,这可以通过调整参数“default_statistics_target”来实现,该参数可在session级别设置,比如在分析不同的表时设置不同的值。在下面的示例中,假设表“test01”的行数较少,设置“default_statistics_target”为“500”,然后分析test01表,表“test02”行数较多,设置“default_statistics_target”为“10”,再分析test02表,命令如下:

















 2345
2345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









