




 在高并发环境下,登录接口出现大量死锁问题,导致错误率升高。通过日志发现更新用户登录时间和插入用户日志时存在锁等待。初步认为是幻读引起,调整事务隔离级别为SERIALIZABLE无效。进一步排查发现,持久态对象导致级联更新,引发死锁。即使去除对象依赖和外键,问题仍未解决。最终,发现外键约束在插入userLog时锁定user数据,导致更新操作死锁。移除外键后,成功解决死锁问题。
在高并发环境下,登录接口出现大量死锁问题,导致错误率升高。通过日志发现更新用户登录时间和插入用户日志时存在锁等待。初步认为是幻读引起,调整事务隔离级别为SERIALIZABLE无效。进一步排查发现,持久态对象导致级联更新,引发死锁。即使去除对象依赖和外键,问题仍未解决。最终,发现外键约束在插入userLog时锁定user数据,导致更新操作死锁。移除外键后,成功解决死锁问题。
今天压测用户中心的登录接口。发现这个接口在并发下几乎不可用,错误率70%。
查看后台日志全是:
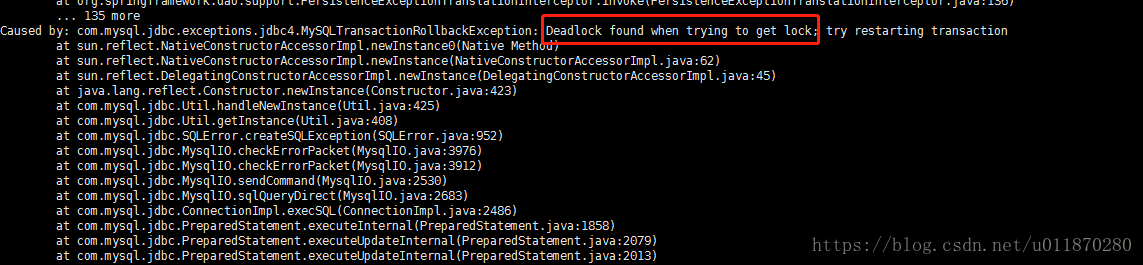
登录接口出现死锁了。
看了下代码,登录中做了更新用户登录时间,插入用户log。查询数据库,发行用户更新和插入log都会lock wait

判断可能是在压测同一个用户登录时,某个请求中的事务读取到了另一个请求里事务未提交的数据。从而需要等待之前的事务提交。(幻读)
然后将事务隔离机制改成SERIALIZABLE。
@Transactional(isolation= Isolation.SERIALIZABLE)。然而并不能解决问题。
后来发现问题出现在记录用户日志上
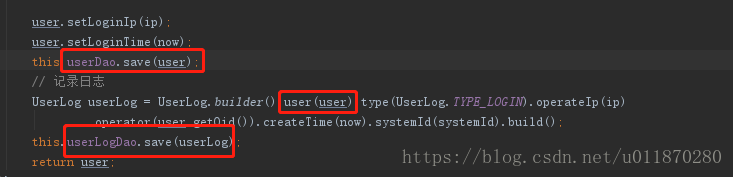
save(user)后,user对象是持久态,然后把持久态的user塞到userlog对象里
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











