









大家好,我是程序员X小鹿,前互联网大厂程序员,自由职业2年+,也一名 AIGC 爱好者,持续分享更多前沿的「AI 工具」和「AI副业玩法」,欢迎一起交流~
前段时间分享了一款 AI 绘画工具,深受大家喜爱。甚至几年都没联系的前同事,都发消息问我,这个 AI 工具是啥?

像上面这组图,就是用这个 AI 绘画工具画的。
比如一些职场吐槽、职场反内卷的插画,还是非常容易引起打工人的共鸣的。
用来做自媒体账号、发朋友圈、做文章插图,都可以!比如X小鹿就经常用它来生成文章插图。
之前问的人太多,回复不过来了,就放公众号了,需要的话发送【插图】自取吧~
但是这个 AI 工具有一定免费额度,免费体验次数用完了,就需要付费了。
有网友就问,有免费的吗?
当然有呀!
免费的就用奇域AI呗。每天签到可领 100 积分,每天可画 100 张。大部分用户绝对够画了。
但是要画出一样的效果,需要自己调提示词。出图后,还需要自己把文字 P 上去。
除了奇域AI,如果会 Stable Diffusion,本地部署出图,也是免费的。而且我见有网友在 LibLib 上发了相关 Lora,可以跑跑试试看。
但依然需要后期自己把文字 P 上去。
因为很多 AI 绘画工具,是不支持图片上出文字的,比如像下面这个:
提示词:一只柯基狗的侧面,头顶上方写着“你瞅啥”。
发现它完全不理解。
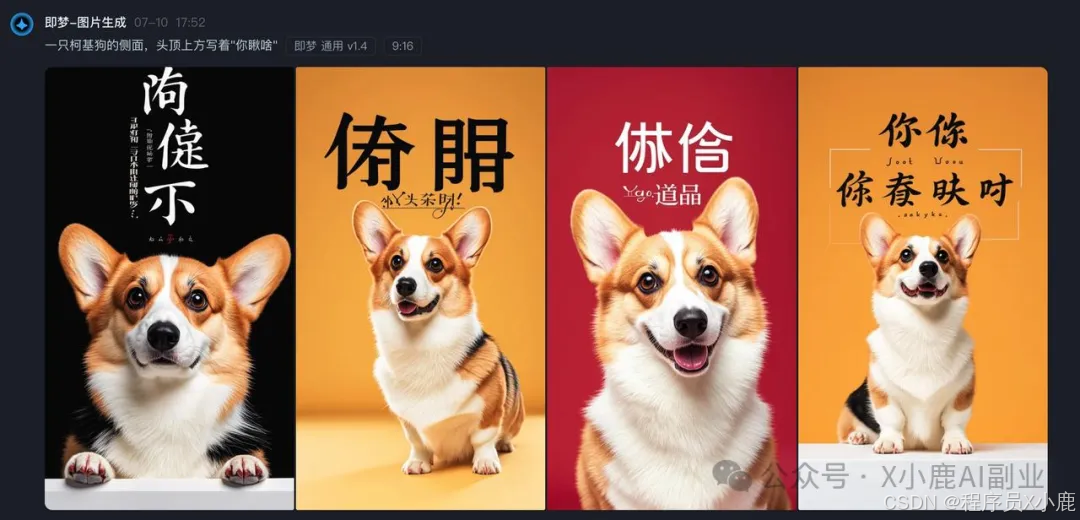
虽然已经有一些工具目前是支持文本输出的,但对于汉字的输出,可控性并不是很高。
前几天在 WAIC 2024 的大会上,快手公布了「可灵 AI」的 Web 端平台以及最新功能。
快手可灵的 AI 视频,备受大家喜爱,不仅国内出圈了,还火到了国外,估计快手自己也是没有料到。
但,大家是不是太宠幸「可灵」AI 视频了,而忘了还有「可图」 AI 绘画。
快手可图大模型(Kolors),是快手大模型团队研发的图像生成大模型,也是行业顶尖的图像生成大模型。
在 WAIC 大会上,快手团队称:
可图大模型(Kolors)是最懂中文的文生图模型!综合指标超过 SDXL / SD3 等开源模型和 Midjourney 等闭源模型。
目前可图(Kolors)完全开源,而且 ComfyUI 插件也出了。
开源地址:
https://github.com/Kwai-Kolors/Kolors
但如果不懂技术也没有关系,可以直接在「可灵AI」官网体验。

快手的可图(Kolors),能够很好地理解中文语义,并且可以直接生成汉字!
比如像刚刚出图失败的文字「你瞅啥」,这里用可图再试一下:
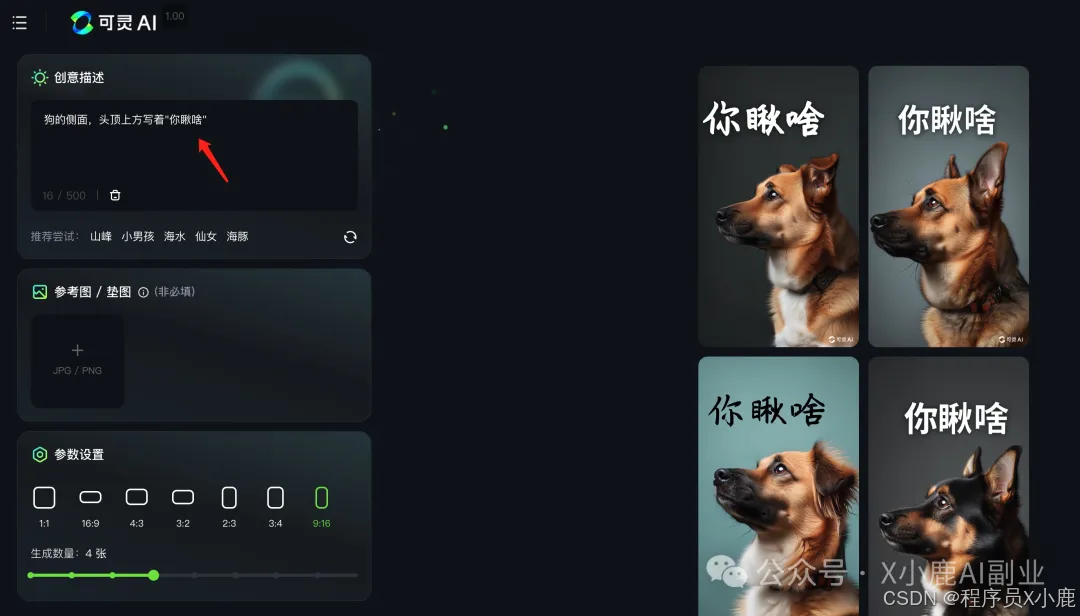
发现汉字出得还不赖!

又试了几个 Case,还不错:


不过有时候也会出汉字失败,尤其是文字比较长的时候。像下面这张。
想让一只小猫咪说「你瞅啥」,另一只说「瞅你咋滴」。但这貌似对可图来说,有些困难。
呃,你俩这是说了个啥…

但不管怎么说,已经比之前的文生图大模型有了很大进步。
快手的可图,不仅会写汉字,而且
1、支持多种风格的绘画。
2、也支持垫图。
3、最多可一次出 9 张图。
4、速度还贼快,差不多 10 多秒就能出图。
而且现在是完全免费!
后续是否收费或是否也会采用积分制,就看官方了,但至少目前可「免费无限出图」!
感兴趣的快去玩一下吧~
结束语
之前在知乎上看到一个提问,说可灵大模型是否已经超越美国了。
我觉得不敢说是否已经超过了,但肯定已经跻身世界前列了!而且在其他 AI 领域的差距也在慢慢缩小。
相信国产大模型一定会更加出色。一起期待一下~
觉得文章有帮助,请帮忙点赞收藏关注一下呦~
我是程序员X小鹿,前互联网大厂程序员,自由职业2年+,也是一名 AIGC 爱好者,欢迎一起交流~
AI及副业资料,关注下方公众号,回复【资料】领取。



















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











