







起因
因为最开始听一个老师讲的时候把这个问题将偏了,或者说没有说明根本原因,所以现在这个问题把我搞蒙了。
原因
最根本的原因有2个
原因1
在线性回归中用到的最多的是MSE(最小二乘损失函数),这个比较好理解,就是预测值和目标值的欧式距离。
而交叉熵是一个信息论的概念,交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。
所以交叉熵本质上是概率问题,表征真实概率分布与预测概率分布差异,和几何上的欧氏距离无关,在线性回归中才有欧氏距离的说法,在分类问题中label的值大小在欧氏空间中是没有意义的。所以分类问题不能用mse作为损失函数。
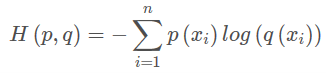
交叉熵损失函数原理
原因2
分类问题是逻辑回归,必须有激活函数这个非线性单元在,比如sigmoid(也可以是其他非线性激活函数),而如果还用mse做损失函数的话:
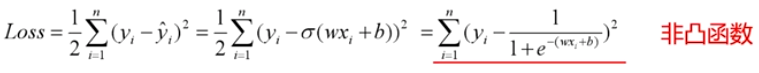
mse已经是非凸函数了,有多个极值点,所以不适用做损失函数了。
另一个常说的原因
mse作为损失函数,求导的时候都会有对激活函数的求导连乘运算,对于sigmoid、tanh,有很大区域导数为0的。
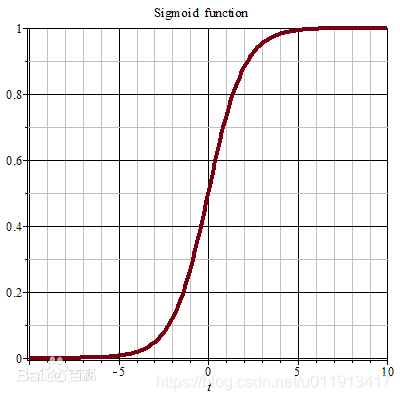
该激活函数的输入很可能直接就在平坦区域,那么导数就几乎是0,梯度就几乎不会被反向传递,梯度直接消失了。所以mse做损失函数的时候最后一层不能用sigmoid做激活函数,其他层可以用sigmoid做激活函数。
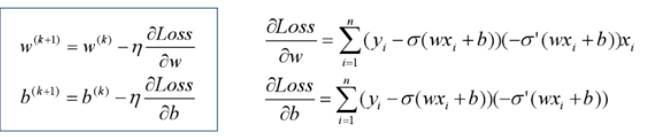
当然,用其他损失函数只能保证在第一步不会直接死掉,反向传播如果激活函数和归一化做得不好,同样会梯度消失。所以从梯度这个原因说mse不好不是很正确。
用交叉熵损失函数后还会有梯度消失的问题吗?
梯度消失问题存在2个地方:
1.损失函数对权值w求导,这是误差反向传播的第一步,mse的损失函数会在损失函数求导这一个层面上就导致梯度消失;所以使用交叉熵损失函数。
2.误差反向传播时,链式求导也会使得梯度消失。使用交叉熵损失函数也不能避免反向传播带来的梯度消失,此时规避梯度消失的方法:
- ReLU等激活函数;
- 输入归一化、每层归一化;
- 网络结构上调整,比如LSTM、GRU等。
深度神经网络,不管用什么损失函数,隐含层的激活函数如果用sigmoid,肯定会梯度消失,训练无效。如果是浅层神经网络,影响可能不是很大,和神经网络的输入有关,如果输入经过了归一化,结果靠谱,如果没有归一化,梯度也直接消失,训练肯定失败。
损失函数和激活函数决定的是模型会不会收敛,也影响训练速度;优化器决定的是模型能不能跳出局部极小值、跳出鞍点、能不能快速下降这些问题的。














 4654
4654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









