




K-Means 简介
聚类算法有很多种(几十种),K-Means是聚类算法中的最常用的一种,算法最大的特点是简单,好理解,运算速度快,但是一定要在聚类前需要手工指定要分成几类。
具体实现步骤如下:
给定n个训练样本{x1,x2,x3,…,xn}
kmeans算法过程描述如下所示:
1.创建k个点作为起始质心点,c1,c2,…,ck
2.重复以下过程直到收敛
遍历所有样本xi,根据距离确定每一个样本的类别。
确定类别后,计算每一个样本到各自质心的距离,然后求和。和用来和前一次计算出来的距离和比较,已确定是否收敛。
对每一个类,计算所有样本的均值并将其作为新的质心(对于点而言,就是所有x坐标的平均值作为质心的x坐标,所有y坐标的平均值作为y坐标的均值)
根据以上步骤,实现的具体效果如下:
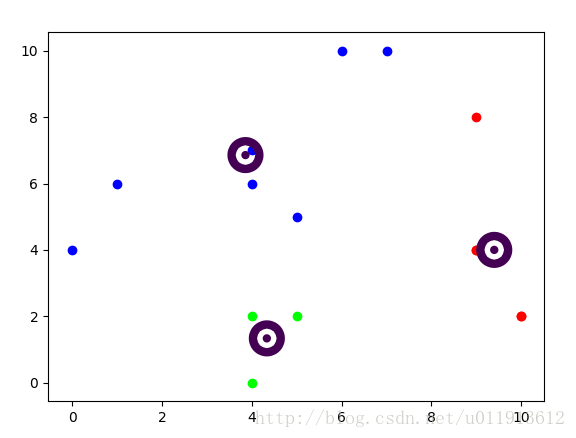
完整代码如下:
from matplotlib import pyplot
import numpy as np
#随机生成K个质心
def randomCenter(pointers,k):
indexs = np.random.random_integers(0,len(pointers)-1,k)
centers = []
for index in indexs:
centers.append(pointers[index])
return< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6659
6659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









