1 关于垃圾 1.1 什么是垃圾? 一个没有引用指向的对象,就是垃圾。简单说来即内存中不会再次被使用的对象被称为垃圾。
例如以下代码在main线程中doSomething方法执行完后,原本创建的GCDemo不再被使用变成垃圾。
public class GCDemo {
private String message = "hello";
public static void doSomething() {
// 虚拟机栈中本地变量所引用的对象
GCDemo gcDemo = new GCDemo();
System.out.println(gcDemo.message);
}
public static void main(String[] args) {
doSomething();
}
}
1.2 如何确定垃圾?
Java中有引用计数法和可达性分析两种方法可以确定垃圾。
1.2.1 引用计数法 (1) 算法原理
引用计数算法很简单,它实际上是通过在对象头中分配一个空间来保存该对象被引用的次数。如果该对象被其它对象引用,则它的引用计数加一,如果删除对该对象的引用,那么它的引用计数就减一,当该对象的引用计数为0时,那么该对象就会被回收。
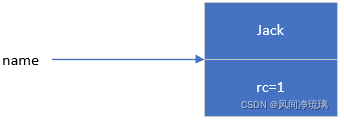
比如:String name = new String("Jack");
如图1 对于Jack这个字符串对象的引用计数值为1。
图1 将name指向Jack字符串对象
而当我们去除Jack字符串对象引用时,如图2 则Jack字符串对象的引用次数减1。
图2 将name置空
(2) 引用变化过程演示
引用计数新增
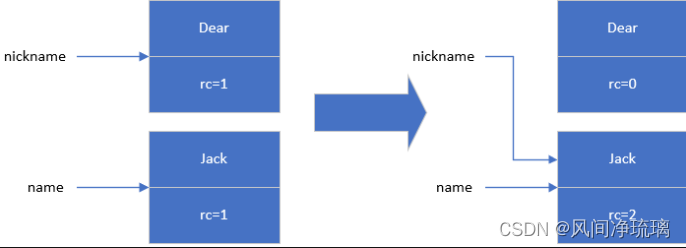
第一个是当对象的引用发生变化时,比如说将对象重新赋值给新的变量等,对象的引用计数如何变化。
假设我们有两个变量nickname和name,它们分别指向不同的对象,当我们将他们指向同一个对象时,图3展示了nickname和name变量指向的两个对象的引用计数的变化。
Person nickname = new Person("Dear");
Person name= new Person("Jack");
nickname = jack;
图3 对象新增引用变化过程
图3 对象新增引用变化过程
注:图中的rc既是引用计数reference counting的缩写。
引用计数删除
第二点需要理解的是,当某个对象的引用计数减为0时,collector需要递归遍历它所指向的所有域,将它所有域所指向的对象的引用计数都减一,然后才能回收当前对象。在递归过程中,引用计数为0的对象也都将被回收。图4展示了该过程。
图4 对象减少引用变化
(3) 循环引用问题
引用计数法实现简单,但有一个比较大的问题,那就是它不能处理环形数据 。 即如果有两个对象相互引用,那么这两个对象就不能被回收,因为它们的引用计数始终为1。这也就是我们常说的“内存泄漏”问题。如图5所示。
图5 循环依赖
1.2.2 可达性分析 (1) 算法原理
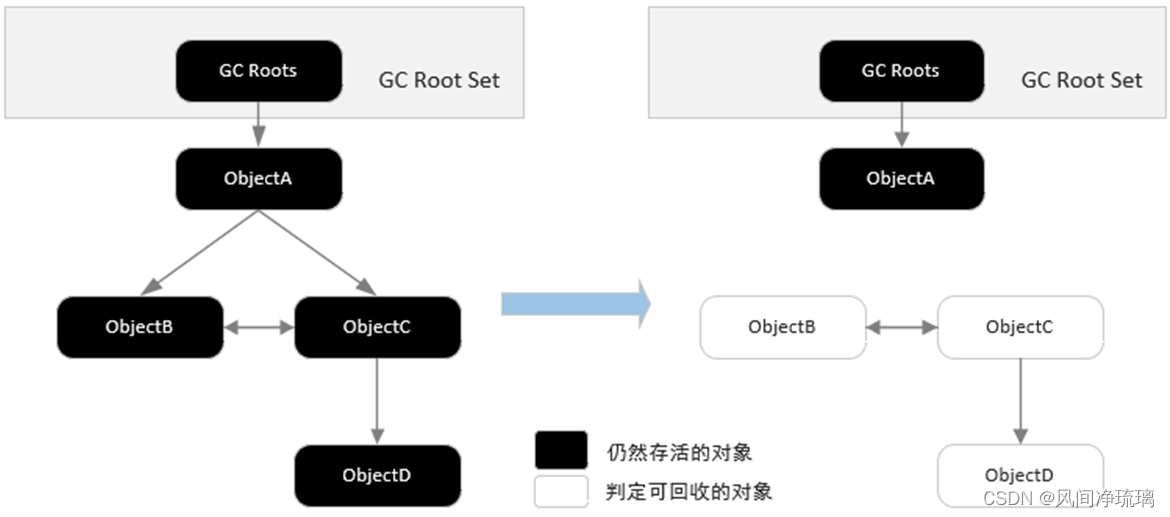
该算法的基本思路就是通过一些被称为引用链(GC Roots)的对象作为起点,从这些节点开始向下搜索,搜索走过的路径被称为(Reference Chain),当一个对象到GC Roots没有任何引用链相连时(即从GC Roots节点到该节点不可达),则证明该对象是不可用的。
图6 可达性分析原理
如图6所示,ObjectA对GC Root是可达的,说明不可被回收,ObjectB、ObjectC和ObjectD对GC Root节点不可达,说明其可以被回收。
GC Root对象
在Java中,可作为GC Root的对象包括以下几种:
虚拟机栈(栈帧中的本地变量表)中引用的对象 方法区中类静态属性引用的对象 方法区中常量引用的对象 本地方法栈中JNI(即一般说的Native方法)引用的对象 可以理解为:
首先第一种虚拟机栈中的引用的对象,我们在程序中正常创建一个对象,对象会在堆上开辟一块空间,同时会将这块空间的地址作为引用保存到虚拟机栈中,如果对象生命周期结束了,那么引用就会从虚拟机栈中出栈,因此如果在虚拟机栈中有引用,就说明这个对象还是有用的,这种情况是最常见的。 第二种是我们在类中定义了全局的静态的对象,也就是使用了static关键字,由于虚拟机栈是线程私有的,所以这种对象的引用会保存在共有的方法区中,显然将方法区中的静态引用作为GC Roots是必须的。 第三种便是常量引用,就是使用了static final关键字,由于这种引用初始化之后不会修改,所以方法区常量池里的引用的对象也应该作为GC Roots。 最后一种是在使用JNI技术时,有时候单纯的Java代码并不能满足我们的需求,我们可能需要在Java中调用C或C++的代码,因此会使用native方法,JVM内存中专门有一块本地方法栈,用来保存这些对象的引用,所以本地方法栈中引用的对象也会被作为GC Roots。 如下示例演示了可作为GC Root的对象:
public class GCDemo {
private byte[] bytes = new byte[1024 * 1024 * 512];
// 类的静态属性引用的对象
private static UserInfo userInfo = new UserInfo();
// 类的常量引用的对象
private final FileData fileData = new FileData();
/**
* 做GC操作流程
*/
public static void doGc() {
// 虚拟机栈中的本地变量所引用的对象
GCDemo gcDemo = new GCDemo();
System.gc();
System.out.println(" , ");
}
public static void main(String[] args) {
doGc();
}
}
(2) finalize()方法最终判定对象是否存活
即使在可达性分析算法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑”阶段,要真正宣告一个对象死亡,至少要经历再次标记过程。如图7所示:
标记的前提是对象在进行可达性分析后发现没有与GC Roots相连接的引用链。
第一次标记并进行一次筛选。
筛选的条件是此对象是否有必要执行finalize()方法。
当对象没有覆盖finalize方法,或者finzlize方法已经被虚拟机调用过,虚拟机将这两种情况都视为“没有必要执行”,对象被回收。
第二次标记
如果这个对象被判定为有必要执行finalize()方法,那么这个对象将会被放置在一个名为:F-Queue的队列之中,并在稍后由一条虚拟机自动建立的、低优先级的Finalizer线程去执行。这里所谓的“执行”是指虚拟机会触发这个方法,但并不承诺会等待它运行结束。这样做的原因是,如果一个对象finalize()方法中执行缓慢,或者发生死循环(更极端的情况),将很可能会导致F-Queue队列中的其他对象永久处于等待状态,甚至导致整个内存回收系统崩溃。
Finalize()方法是对象脱逃死亡命运的最后一次机会,稍后GC将对F-Queue中的对象进行第二次小规模标记,如果对象要在finalize()中成功拯救自己----只要重新与引用链上的任何的一个对象建立关联即可,譬如把自己赋值给某个类变量或对象的成员变量,那在第二次标记时它将移除出“即将回收”的集合。如果对象这时候还没逃脱,那基本上它就真的被回收了。
图7 二次标记过程示例
(3) Java引用
从可达性算法中可以看出,判断对象是否可达时,与“引用”有关。那么什么情况下可以说一个对象被引用,引用到底代表什么?
在JDK1.2之后,Java对引用的概念进行了扩充,可以将引用分为以下四类:
强引用(Strong Reference) 软引用(Soft Reference) 弱引用(Weak Reference) 虚引用(Phantom Reference) 这四种引用从上到下,依次减弱
强引用
强引用就是指在程序代码中普遍存在的,类似Object obj = new Object()这类似的引用,只要强引用在,垃圾搜集器永远不会搜集被引用的对象。也就是说,宁愿出现内存溢出,也不会回收这些对象。
软引用
软引用是用来描述一些有用但并不是必需的对象,在Java中用java.lang.ref.SoftReference类来表示。对于软引用关联着的对象,只有在内存不足的时候JVM才会回收该对象。因此,这一点可以很好地用来解决OOM的问题,并且这个特性很适合用来实现缓存:比如网页缓存、图片缓存等。
import java.lang.ref.SoftReference;
public class Main {
public static void main(String[] args) {
SoftReference<String> sr = new SoftReference<String>(new String("hello"));
System.out.println(sr.get());
}
}
弱引用
弱引用也是用来描述非必需对象的,当JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference类来表示。下面是使用示例:
import java.lang.ref.WeakReference;
public class Main {
public static void main(String[] args) {
WeakReference<String> sr = new WeakReference<String>(new String("hello"));
System.out.println(sr.get());
System.gc(); //通知JVM的gc进行垃圾回收
System.out.println(sr.get());
}
}
虚引用
虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期。在java中用java.lang.ref.PhantomReference类表示。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。
要注意的是,虚引用必须和引用队列关联使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会把这个虚引用加入到与之 关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class Main {
public static void main(String[] args) {
ReferenceQueue<String> queue = new ReferenceQueue<String>();
PhantomReference<String> pr = new PhantomReference<String>(new String("hello"), queue);
System.out.println(pr.get());
}
}
1.2.3 可达性分析使用证明 如何证明jvm使用哪种类型的垃圾回收策略?
从理论入手,如下代码是循环依赖代码,恰如jvm使用的是引用计数法,那么将不会进行垃圾回收。如果使用可达性分析,那么就会存在垃圾回收。
public class RootGcTest {
private Object instance;
/** 2M Data */
private byte[] bytes = new byte[2 * 1024 * 1024];
public static void main(String[] args) {
// 演示循环依赖
RootGcTest rootGcTestA = new RootGcTest();
RootGcTest rootGcTestB = new RootGcTest();
rootGcTestA.instance = rootGcTestB;
rootGcTestB.instance = rootGcTestA;
rootGcTestA = null;
rootGcTestB = null;
System.gc();
}
}
在运行完上面的程序后,从GC日志能看到年轻代在gc回收前大小为5396K,gc后为720k。说明两个对象并没有因为相互持有,造成循环引用,无法释放。间接证明JVM 并未采用reference counting算法管理内存。
图8 jdk8使用可达性分析证明结果
2 垃圾回收算法 2.1 问在前面 2.1.1 为什么要进行垃圾回收?
设想一下没有垃圾回收,在有限的内存条件下,会导致OOM(out of memory)。
2.1.2 垃圾回收器会针对哪些区域呢?
程序计数器、虚拟机栈、本地方法栈等区域随着方法结束或线程结束时,内存自然就跟随着回收了,每个栈帧分配多少内存基本上是在类结构确定下来时就已知的,所以这三个区域内存分配和回收都是确定的。 垃圾收集器所关注的是这部分内存——方法区和堆。 堆外内存,代码释放。
2.1.3 垃圾回收算法有哪些?
如标记-清除、标记-复制、标记-整理等基本算法,以及在此基础上可以增加分代(新生代/老年代),每代采取不同的回收算法,以提高整体的分配和回收效率。
2.1.4 垃圾回收器为什么要分代?
绝大多数对象存活周期很短 (更新频率快,分代只需要关注少量存活的对象,不分代要标记大量消亡的对象) 熬过越多次垃圾收集过程的对象越难消亡(单独处理,更新频率低一些) 跨代引用相对于同代引用仅仅只是极少数 兼顾垃圾收集时间开销和内存空间的有效利用,不同代采取不同的垃圾回收算法。
2.1.5 JVM调优是调优什么?
减少stop the word,STW在垃圾回收的过程中会短暂的停止业务线程。
2.1.6 JVM为什么会有STW?
复制过程中,对象位置发生变化,若应用程序线程同步执行,为保证正常,复杂度需要多高(解析固定数据和变化数据复杂度)。 标记过程中,可能出现误删等情况,造成程序出错。
2.1.7 哪些代会发生STW?
年轻代YoungGC,老年代FullGC都会,相对来说FullGC停顿时间会比较长。
2.2 标记-清除(Mark-Sweep) 2.2.1 回收过程
主要分为两个阶段:
标记:先通过根节点,标记所有从根节点开始可达的对象,未被标记的对象就是未被引用的垃圾对象。 清除:清除所有未被标记的对象
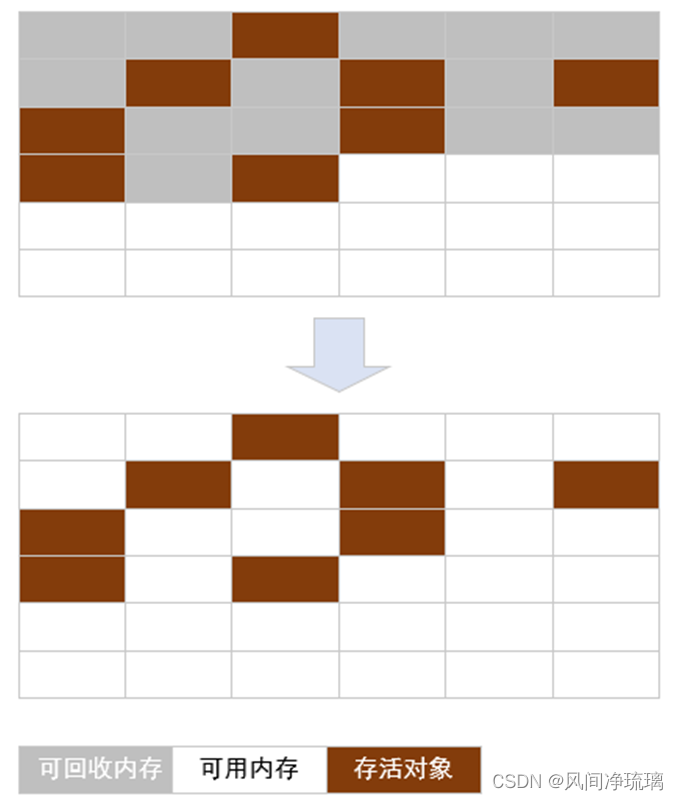
下图演示了标记清除的过程:
图9 标记清除过程
2.2.2 算法优势 2.2.3 算法劣势
会造成不连续的内存空间,空间碎片严重,不利于下次分配。空间不连续,大对象分配,不得不提前GC。 性能不稳定:大量对象回收时,对象比较分散,清楚过程耗时,速度较慢。
2.3 标记-复制(Mark-Copy)2.3.1 回收过程 内存分为大小相同的两块,使用一块复制存活对象到另一块,再清理本块。重复该过程。每次的内存回收都是对内存区间的一半进行回收。
下面演示标记复制算法过程:
图10 标记复制算法过程
2.3.2 算法优势
解决标记清除空间碎片问题,采用移动存活对象的方式,每次清除针对的都是一整块内存,故清除可回收对象的效率也比较高,但因为要移动对象耗时,所以标记复制法效率会低于标记清除法。
2.3.3 算法劣势
会浪费一部分空间:一块空闲的内存区域是利用不到的,资源浪费。 存活对象多会非常耗时:复制移动对象的过程耗时,不仅需要移动对象本身还需修改使用了这些对象的引用地址。这也提示我们标记复制法比较适合存活对象较少的场景。 需要担保机制:因复制区总会有一块空间的浪费,为了减少空间浪费,会把复制区的空间分配控制在很小的区间。但空间太小会产生新问题,就是在存活的对象比较多的时候,这时复制区的空间可能不够容纳这些对象,这时就需要借一些空间来保证容纳这些对象,这种从其他地方借内存的方式我们称它为担保机制。
2.4 标记-整理(Mark-Compact) 2.4.1 回收过程
标记:先把存活的对象和可回收的对象标记出来 整理:会把存活的对象往内存的一端移动,移动完对象后再清除存活对象边界之外的对象
图11 标记整理算法过程
2.4.2 算法优势 解决了标记清除法的空间碎片问题,同时也不至于像标记复制法需要空闲的内存空间,所以它非常适合存活对象多的场景。
2.4.3 算法劣势 三种垃圾回收算法中性能最低的,移动对象的时候不仅需要移动对象,还要额外的维护对象的引用的地址,这个过程可能要对内存经过几次的扫描定位才能完成,做的事情越多那么耗时越多。
2.5 分代收集算法 当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。
2.5.1 分代 一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集,而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以一般“标记-整理”算法进行垃圾收集。(cms垃圾收集器例外,老年代采用标记清除会有碎片)
图12 分代示意图
从上图我们可以看见分代垃圾回收的内存默认划分,年轻代:老年代=1:2,而年轻代中eden:survivor from:survivor to = 8:1:1。
有些人也会疑问为什么要有两个Survivor?
主要是为了解决内存碎片化和效率问题。如果只有一个Survivor时,每触发一次minor gc都会有数据从Eden放到Survivor,一直这样循环下去。注意的是,Survivor区也会进行垃圾回收,这样就会出现内存碎片化问题.
2.5.2 垃圾回收机制 (1)Minor GC触发条件
(2)Full GC触发条件
调用System.gc时,系统建议执行Full GC,但是不必然执行 老年代空间不足 方法区空间不足 通过Minor GC后进入老年代的平均大小大于老年代的可用内存 由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
2.5.3 晋升老年代 图13演示了年轻代晋升老年代的一种情况。
图13 年轻代晋升老年代
2.5.4 对象进入老年代的四种情况
Minor GC时,存活的对象在ToSpace区中存不下,把存活的对象存入老年代。 大对象直接进入老年代,新创建的对象很大,那么即使Eden区有足够的空间来存放,也不会存放在Eden区,而是直接存入老年代。 长期存活的对象将进入老年代此外,如果对象在Eden出生并且经过1次Minor GC后仍然存活,并且能被To区容纳,那么将被移动到To区,并且把对象的年龄设置为1,对象没"熬过"一次Minor GC(没有被回收,也没有因为To区没有空间而被移动到老年代中),年龄就增加一岁,当它的年龄增加到一定程度(默认15岁,配置参数-XX:MaxTenuringThreshold),就会被晋升到老年代中。 动态对象年龄判定还有一种情况,如果在From空间中,相同年龄所有对象的大小总和大于Survivor空间的一半,那么年龄大于等于该年龄的对象就会被移动到老年代,而不用等到15岁(默认)。
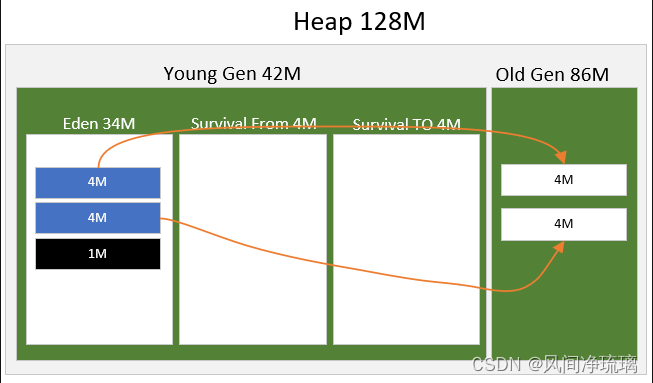
图14 演示Minor GC时,存活对象在toSpace区中存不下,把存活的对象存入老年代的情况。
图14 TO Space区存不下晋升示意图
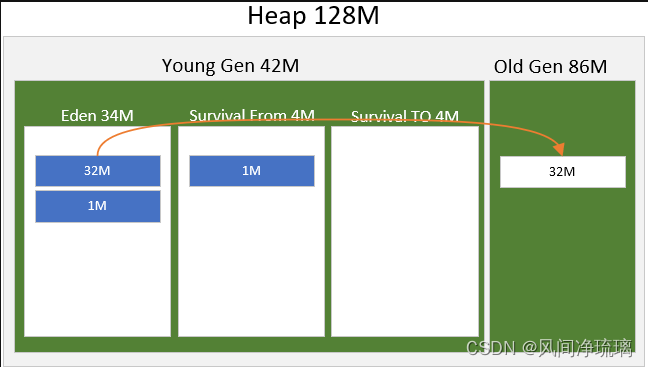
图15 演示大对象晋升老年代的情况,可以看见大对象32M远大于survival from大小,直接晋升到老年代。
图15 大对象晋升示意图
图16 演示动态年龄判断晋升,可以看见survival from区中内存大小已经是3.1M,大于from区一半的值,超5岁的对象都被晋升到老年代。
图16 动态年龄判断示意图
2.6 垃圾回收算法总结
三种垃圾回收算法没有一个算法是完美的,我们只能根据具体的场景去选择合适的垃圾收集算法。
算法名称 特点 适用场景 标记-清除 简单、收集速度快,但会有空间碎片,空间碎片会导致后面的GC频率增加。 只有小部分对象需要进行回收的,适用于老年代的垃圾回收,因为老年代一般存活对象会比回收对象要多。 标记-复制 收集速度快,可以避免空间碎片,但是有空间浪费,存活对象较多的情况下复制对象的过程等会非常耗时,而且需要担保机制。 只有少量对象存活的场景,这也正是新生代对象的特点,所以一般新生代的垃圾回收器基本都会选择标记复制法。 标记整理法 相对于标记复制法不会浪费内存空间,相对标记清除法则可以避免空间碎片,但是速度比其他两个算法慢。 内存吃紧,又要避免空间碎片的场景,老年代想要避免空间碎片问题的话通常会使用标记整理法。
3 JVM内存结构详解 3.1 Java字节码反编译成汇编指令
java反编译成汇编指令,平常我们想研究下class底层的一些逻辑,这时候就需要对class进行反汇编,反汇编后看到的就是一些汇编指令,当然想看懂汇编的逻辑,就得熟悉汇编的 “助记符”。
有代码如下:
public class Mode {
public static final int INIT_NUM = 888;
public static Tree tree = new Tree();
public Mode() {
}
public int doCompute() {
int addend = 2;
int augend = 3;
return (addend + augend) * 8;
}
public static void main(String[] args) {
Mode mode = new Mode();
mode.doCompute();
}
}
将上述代码编译成class文件后,可通过javap –c Mode.class 反解析成汇编指令,可以得到以下的内容:
Compiled from "Mode.java"
public class com.test.my.demo.jvm.Mode {
public static final int INIT_NUM;
public static com.test.my.demo.dto.Tree tree;
public com.test.my.demo.jvm.Mode();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int doCompute();
Code:
0: iconst_2 // int型常量2进栈
1: istore_1 // 栈顶int数值存入第1局部变量
2: iconst_3 // int型常量3进栈
3: istore_2 // 栈顶int述指存入第2局部变量
4: iload_1 // 第1局部变量入栈
5: iload_2 // 第2局部变量入栈
6: iadd // 操作栈中第1局部变量+第2局部变量
7: bipush 8 // 操作栈中常量8进栈
9: imul // 操作栈中常量*之前的加法结果
10: ireturn // 当前方法返回栈中的结果int
public static void main(java.lang.String[]);
Code:
0: new #2 // class com/test/my/demo/jvm/Mode
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method doCompute:()I
12: pop
13: return
static {};
Code:
0: new #5 // class com/test/my/demo/dto/Tree
3: dup
4: invokespecial #6 // Method com/test/my/demo/dto/Tree."<init>":()V
7: putstatic #7 // Field tree:Lcom/test/my/demo/dto/Tree;
10: return
}
3.2 JVM内存结构介绍 Java程序在执行前首先会被编译成字节码文件,然后再由Java虚拟机执行这些字节码文件从而使得Java程序得以执行。事实上,在程序执行过程中,内存的使用和管理一直是值得关注的问题。Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域,这些数据区域都有各自的用途,以及创建和销毁的时间,并且它们可以分为两种类型:线程共享的方法区和堆,线程私有的虚拟机栈、本地方法栈和程序计数器。
在此基础上,我们探讨了在虚拟机中对象的创建和对象的访问定位等问题,并分析了Java虚拟机规范中异常产生的情况。
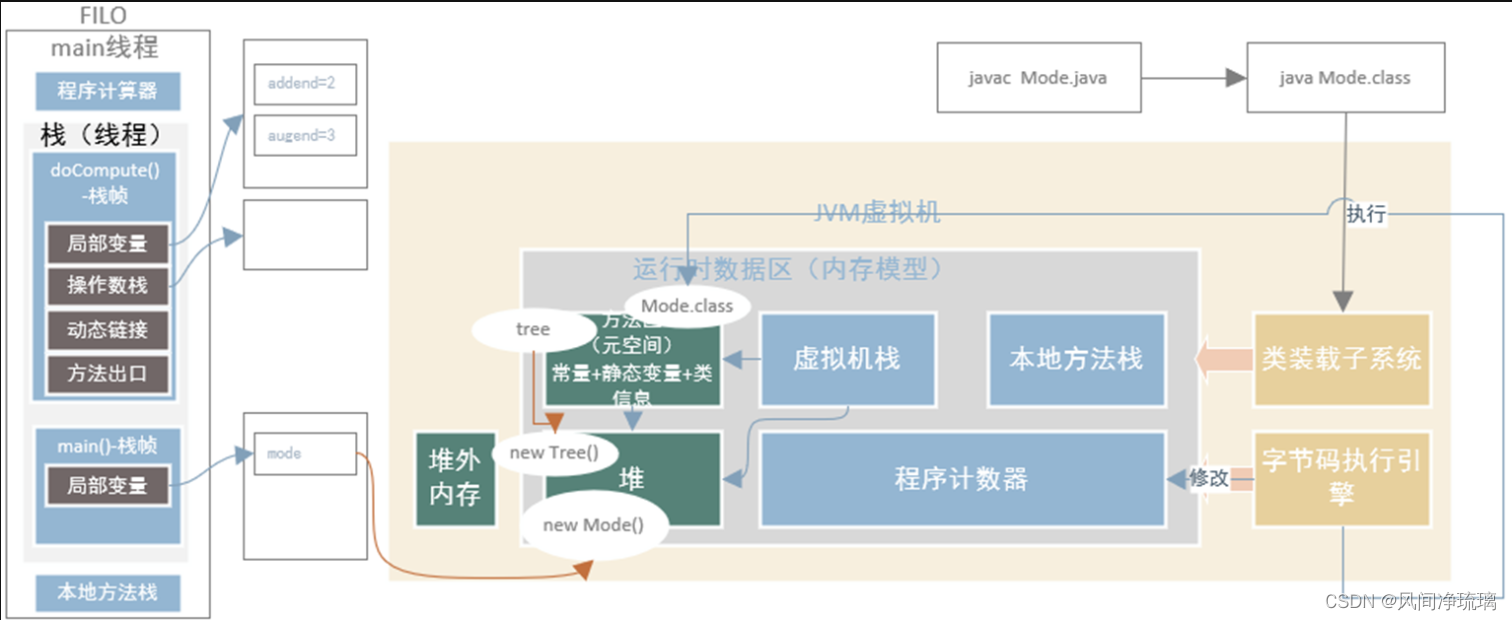
图17 是上述代码运行时内存模型示意图。
图17 代码运行时内存模型示意图
3.2.1 程序计数器
程序计数器是一块很小的内存空间,它是线程私有的,可以认作为当前线程的行号指示器。
(1) 为什么需要程序计数器?
我们知道对于一个处理器(如果是多核cpu那就是一核),在一个确定的时刻都只会执行一条线程中的指令,一条线程中有多个指令,为了线程切换可以恢复到正确执行位置,每个线程都需有独立的一个程序计数器,不同线程之间的程序计数器互不影响,独立存储。
注意:如果线程执行的是个java方法,那么计数器记录虚拟机字节码指令的地址。如果为native【底层方法】,那么计数器为空。这块内存区域是虚拟机规范中唯一没有OutOfMemoryError的区域。
3.2.2 Java栈(虚拟机栈)
同计数器也为线程私有,生命周期与相同,就是我们平时说的栈,栈描述的是Java方法执行的内存模型。
每个方法被执行的时候都会创建一个栈帧用于存储局部变量表,操作栈,动态链接,方法出口等信息。每一个方法被调用的过程就对应一个栈帧在虚拟机栈中从入栈到出栈的过程。
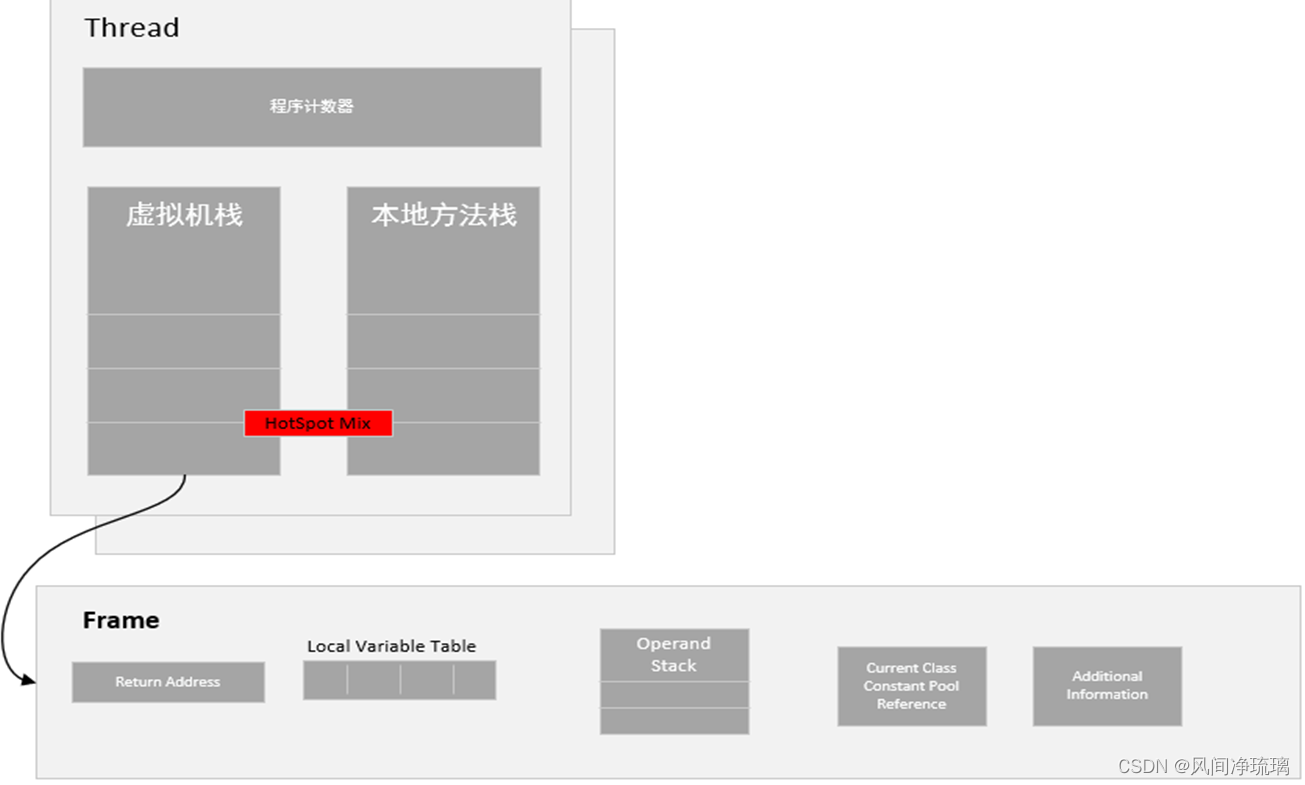
图18 是虚拟机栈示意图:
图18 虚拟机栈示意图
(1) 栈帧(Stack Frame)
栈帧: 是用来存储数据和部分过程结果的数据结构。
栈帧的位置: 内存 -> 运行时数据区 -> 某个线程对应的虚拟机栈 -> here[在这里]
栈帧大小确定时间: 编译期确定,不受运行期数据影响。
(2) 局部变量表(Local Variable Table)
局部变量表:一片连续的内存空间,用来存放方法参数,以及方法内定义的局部变量,存放着编译期间已知的数据类型(八大基本类型和对象引用(reference类型),returnAddress类型。
它的最小的局部变量表空间单位为Slot,虚拟机没有指明Slot的大小,但在jvm中,long和double类型数据明确规定为64位,这两个类型占2个Slot,其它基本类型固定占用1个Slot。reference类型:与基本类型不同的是它不等同本身,即使是String,内部也是char数组组成,它可能是指向一个对象起始位置指针,也可能指向一个代表对象的句柄或其他与该对象有关的位置。returnAddress类型:指向一条字节码指令的地址
需要注意的是,局部变量表所需要的内存空间在编译期完成分配,当进入一个方法时,这个方法在栈中需要分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表大小。
(3) 操作数栈(Operand Stack)
操作数栈也常被称为操作栈,。在Class 文件的Code 属性的 max_stacks 指定了执行过程中最大的栈深度。Java 虚拟机的解释执行引擎称为“基于栈的执行引擎”,这里的栈就是指操作数栈。 操作数栈的每个位置上可以保存一个java虚拟机中定义的任意数据类型的值,包括long和double
以下代码将演示操作数栈作用。
iload_0 // 将局部变量表0号索引的值入操作数栈 iload_1 // 将局部变量表1号索引的值入操作数栈 iadd // 操作数栈去除前两位相加,放入栈顶 istore_2 // 操作数栈顶元素出栈,放入局部变量表2号索引
(4) 动态连接(Dynamic Linking)
每个栈帧都包含一个指向当前方法所在类型的运行时常量池的引用,持有这个引用是为了支持方法调用过程中的动态连接(Dynamic Linking)。 Class 文件中存放了大量的符号引用,字节码中的方法调用指令就是以常量池中指向方法的符号引用作为参数。这些符号引用一部分会在类加载阶段或第一次使用时转化为直接引用,这种转化称为静态解析。另一部分将在每一次运行期间转化为直接引用,这部分称为动态连接。
(5) 附加信息(additional information)
栈帧中还允许携带与java虚拟机实现相关的一些附加信息。例如对程序调试提供支持的信息(常见如Jstack指令)。
(6) 关于异常
Java虚拟机栈可能出现两种类型的异常:
线程请求的栈深度大于虚拟机允许的栈深度,将抛出StackOverflowError。 虚拟机栈空间可以动态扩展,当动态扩展是无法申请到足够的空间时,抛出OutOfMemory异常。
3.2.3 本地方法栈
本地方法栈是与虚拟机栈发挥的作用十分相似,区别是虚拟机栈执行的是Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的native方法服务,可能底层调用的c或者c++,我们打开jdk安装目录可以看到也有很多用c编写的文件,可能就是native方法所调用的c代码。
3.2.4 堆 对于大多数应用来说,堆是java虚拟机管理内存最大的一块内存区域,因为堆存放的对象是线程共享的,所以多线程的时候也需要同步机制。因此需要重点了解下。
java虚拟机规范对这块的描述是:所有对象实例及数组都要在堆上分配内存,但随着JIT编译器的发展和逃逸分析技术的成熟,这个说法也不是那么绝对,但是大多数情况都是这样的。
即时编译器:可以把把Java的字节码,包括需要被解释的指令的程序)转换成可以直接发送给处理器的指令的程序)逃逸分析:通过逃逸分析来决定某些实例或者变量是否要在堆中进行分配,如果开启了逃逸分析,即可将这些变量直接在栈上进行分配,而非堆上进行分配。这些变量的指针可以被全局所引用,或者其其它线程所引用。
注意:
它是所有线程共享的,它的目的是存放对象实例。同时它也是GC所管理的主要区域,因此常被称为GC堆,又由于现在收集器常使用分代算法,Java堆中还可以细分为新生代和老年代,再细致点还有Eden(伊甸园)空间之类的不做深究。 根据虚拟机规范,Java堆可以存在物理上不连续的内存空间,就像磁盘空间只要逻辑是连续的即可。它的内存大小可以设为固定大小,也可以扩展。 当前主流的虚拟机如HotPot都能按扩展实现(通过设置 -Xmx和-Xms),如果堆中没有内存内存完成实例分配,而且堆无法扩展将报OOM错误(OutOfMemoryError)
3.2.5 方法区
方法区同堆一样,是所有线程共享的内存区域,为了区分堆,又被称为非堆。用于存储已被虚拟机加载的类信息、常量、静态变量,如static修饰的变量加载类的时候就被加载到方法区中。
运行时常量池是方法区的一部分,class文件除了有类的字段、接口、方法等描述信息之外,还有常量池用于存放编译期间生成的各种字面量和符号引用。
java虚拟机对方法区比较宽松,除了跟堆一样可以不存在连续的内存空间,定义空间和可扩展空间,还可以选择不实现垃圾收集。
在老版jdk,方法区也被称为永久代。因为没有强制要求方法区必须实现垃圾回收,HotSpot虚拟机以永久代来实现方法区,从而JVM的垃圾收集器可以像管理堆区一样管理这部分区域,从而不需要专门为这部分设计垃圾回收机制。不过自从JDK7之后,Hotspot虚拟机便将运行时常量池从永久代移除了。jdk8真正开始废弃永久代,而使用元空间(Metaspace)。图19 将演示这种演变过程。
图19 方法区演变示意图
(1) 方法区和元空间对比
永久代 元空间 使用空间 单独的堆空间 本地内存(堆外内存) 内存限制 启动时确定最大值 不指定最大值则可动态增长 GC时机 G1: Full GC CMS: Full GC/-XX:+CMSClassUnloadingEnabled 到达MaxMetaspaceSize时触发
注意:
CMS收集器默认不会对永久代进行垃圾回收。要对永久代进行垃圾回收,可用设置标志-XX:+CMSClassUnloadingEnabled。 在早期JVM版本中,要求设置额外的标志-XX:+CMSPermGenSweepingEnabled。 即使没有设置这个标志,一旦永久代耗尽空间也会尝试进行垃圾回收,但是收集不会是并行的,而再一次进行Full GC。
3.2.6 堆外内存 (1) 定义
显然,看名字就知道堆外内存与堆内内存是相对应的:Java 虚拟机管理堆之外的内存,称为非堆内存,即堆外内存。 换句话说:堆外内存就是把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
(2) 堆外内存构成
Java 虚拟机具有一个由所有线程共享的方法区。方法区属于非堆内存。它存储每个类结构,如运行时常数池、字段和方法数据,以及方法和构造方法的代码。它是在 Java 虚拟机启动时创建的。
方法区在逻辑上属于堆,但 Java 虚拟机实现可以选择不对其进行回收或压缩。与堆类似,方法区的内存不需要是连续空间,因此方法区的大小可以固定,也可以扩大和缩小。。
除了方法区外,Java 虚拟机实现可能需要用于内部处理或优化的内存,这种内存也是非堆内存 。例如,JIT 编译器需要内存来存储从 Java 虚拟机代码转换而来的本机代码,从而获得高性能。
(3) 关联异常
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。 如果虚拟机栈可以动态扩展(当前部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),如果扩展时无法申请到足够的内存,就会抛出OutOfMemoryError异常。
(4) 堆外内存的申请和释放
JDK中使用DirectByteBuffer对象来表示堆外内存,每个DirectByteBuffer对象在初始化时,都会创建一个对应的Cleaner对象,这个Cleaner对象会在合适的时候执行unsafe.freeMemory(address),从而回收这块堆外内存。
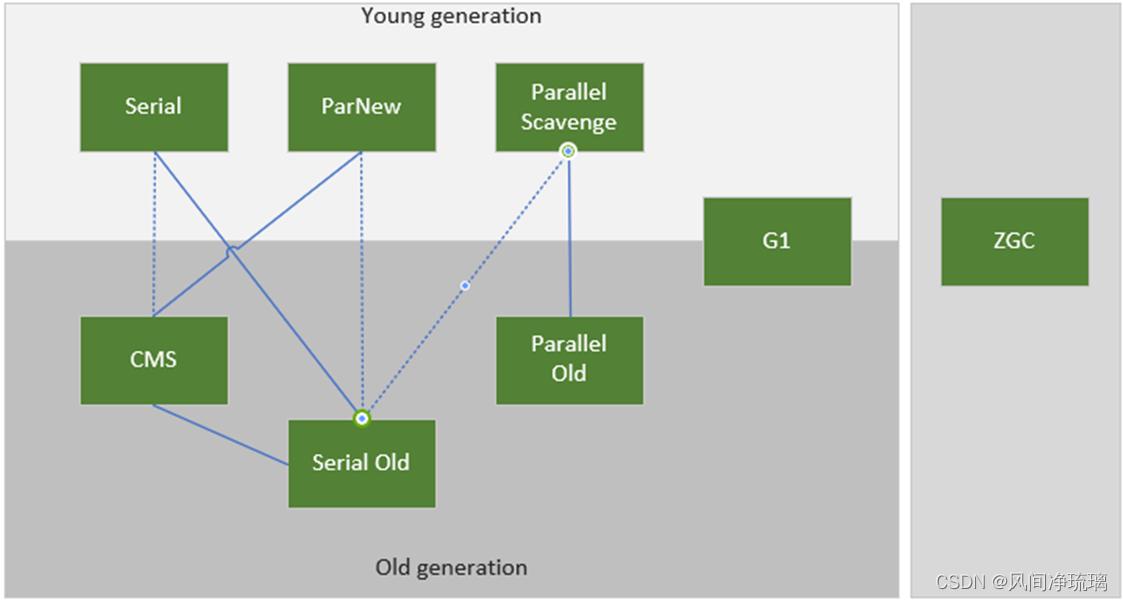
4 常见垃圾回收器介绍 4.1 常见垃圾回收器总览
本文将介绍8种垃圾回收器,有只针对年轻代的Serial、ParNew、Parallel Scavenge,有只针对老年代的CMS、Serial Old、Parallel Old,有即包含年轻代又包含老年代的G1,还有没有分代概念的ZGC垃圾回收器。
同时不同的垃圾回收器还可以针对业务,自行搭配使用。
图20是当下常见的垃圾回收器。
图20 常见垃圾回收器示意图
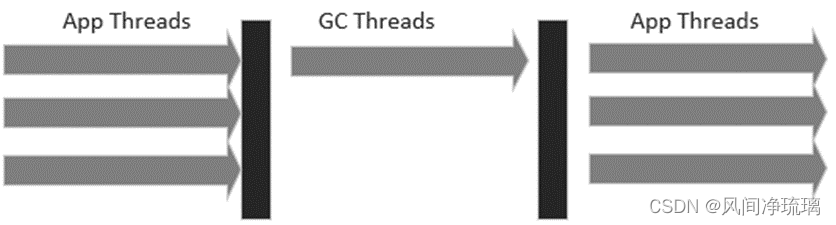
4.2 串行垃圾收集器 常见的串行垃圾回收器,如Serial垃圾收集器和Serial Old垃圾收集器。
从图21我们可以只管看到,串行垃圾回收器穿插在业务线程中执行,GC线程只有一个。
图21 串行垃圾收集器
4.2.1 Serial垃圾收集器
Serial收集器是针对新生代的,采用复制算法,采用串行回收方式,是虚拟机在client级别默认新生代的GC方式,利用STW机制方式执行垃圾回收。
4.2.2 Serial Old 垃圾收集器
Serial Old收集器是针对老年代的,采用标记-整理算法,是Serial收集器的老年代版本,与Serial收集器类相同的是,它也采用串行回收方式和STW机制,是虚拟机在client级别默认老年代GC方式。
除此之外,在Server模式下,与新生代的Parallel Scavenge配合使用,同时作为老年代CMS收集器(CMS稍后介绍)的后备方案。
4.2.3 相关参数
可以通过-XX:+UseSerialGC来强制指定Serial 收集器进行GC。相当于新生代使用Serial,老年代使用Serial Old。一般在Java web程序中也不会使用该串行收集器。 可以通过-XX:PrintGCApplicationStoppedTime 查看STW时间。
4.3 多线程垃圾回收器
常见的多线程垃圾回收器如ParNew垃圾收集器、Parallel Scavenge垃圾收集器和Parallel Old垃圾收集器。
图22 演示的是多线程垃圾回收器的工作原理。
图22 多线程垃圾回收器原理
4.3.1 ParNew垃圾收集器
针对新生代,采用的是复制算法,是serial回收器的多线程版本,是并行回收方式,所以在多核CPU环境下有着比Serial更好的表现,但是在单CPU情况下,并不比serial性能好,同时,与Serial一样,采用STW机制。
注:可用-XX:+UseParNewGC来指定使用Parallel收集器,用-XX:ParallelGCThreads=X来指定线程数,默认使用与CPU核数相同的线程数。
4.3.2 Parallel Scavenge垃圾收集器
并行收集器,采用复制算法,追求高吞吐量,高效利用CPU,亦是STW机制。吞吐量一般为99%, 吞吐量= 用户线程时间/(用户线程时间+GC线程时间)。适合后台应用等对交互相应要求不高的场景。是server级别默认采用的GC方式。
4.3.3 Parallel Old垃圾收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,采用标记-整理算法,亦是STW机制,并行收集器,吞吐量优先。
注:
可用-XX:+UseParallelGC来指定使用Parallel收集器. 可用-XX:+UseParallelOldGC来指定使用Parallel Old收集器。 可用-XX:ParallelGCThreads=X来指定线程数。一般当CPU核数小于8,则设置与核数相同,否则设置为3+5*num/8,是Java 8 默认的GC回收器
4.4 CMS垃圾收集器
CMS(Concurrent Mark Sweep),从英文名称可以看出来,它其实是采用标记-清除算法的,表现为高并发、低停顿,追求最短GC回收停顿时间,在收集过程中既会存在GC线程与工作线程并发工作的时候,也会有存在STW机制的过程,表现为CPU占用比较高,但响应时间快,停顿时间短,是多核cpu 追求高响应时间的选择。CMS在JDK9中标记为废弃,并在JDK14中移除。
4.4.1工作原理 主要工作步骤
初始标记(STW initial mark):标记出GC Roots能直接关联到的对象。所有的工作线程会暂停,不过这个过程很短暂。 并发标记(Concurrent marking):从GC Roots的直接关联对象,开始遍历整个对象图的过程,这个过程耗时较长但是不需要停顿用户线程,与垃圾收集线程一起并发运行。 重新标记(STW remark):在并发标记阶段,事实上会因用户程序继续运作导致标记产生变动,所以需要重新标记。 并发清理(Concurrent sweeping):清理删除掉标记阶段标记的对象 并发重置(Concurrent reset): 这个阶段主要是重置CMS收集器的数据结构,以等待下一次垃圾回收。
图23是CMS垃圾回收器工作过程。
图23 CMS垃圾回收器工作过程
注:可用-XX:+UseConcMarkSweepGC 来指定使用CMS垃圾收集器。
4.4.2 缺点
采用标记-清除算法,所以不可避免会产生内存碎片。而之所以不使用标记-压缩算法来避免产生内存碎片,是因为在标记-压缩中,会整理内存空间单元,但是要注意CMS收集器是有并发过程的,是有工作线程在同时执行的,譬如并发清理阶段,这时是不能整理内存空间单元的。 存在并发过程,所以需要更多的CPU资源。 CMS的另一个缺点是它需要更大的堆空间。这是因为CMS标记阶段应用程序的线程还是在执行的,堆空间会有继续分配的情况,为保证在CMS回收完之前还有空间分配给正在运行的应用程序,必须预留一部分空间,如果预留的内存空间无法满足程序需要,那么会出现一次“Concurrent Mode Failure”失败,这时会临时使用Serial Old收集器。综上所述,其实CMS不会在老年代满的时候才开始收集,而是会尝试更早的开始收集,从而避免上面提到的情况,默认当老年代使用68%的时候,CMS就开始行动,可用– XX:CMSInitiatingOccupancyFraction =n 来设置这个阀值。
4.4.3 参数说明
参数 说明 默认值 建议值 -XX:+UseConcMarkSweepGC 启用CMS后,年轻代默认用ParNewGC -XX:+CMSParallelInitialMarkEnabled 初始化标记阶段是否多线程 false(jdk1.7) true(jdk1.8) true -XX:+CMSConcurrentMTEnabled 并发阶段多线程 true true -XX:ParallelGCThreads=N STW期间,并行GC线程数 -XX:ConcGCThreads=N 并发采集阶段的线程数 (ParallelGC Threads+3)/4 -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=N 采用内存比例的判断方式来开始GC,默认基于统计数据开始GC。当内存大于N%时开始GC False 92 true -XX:CMSFullGCBeforeCompaction=N 每隔N次FullGC做一次压缩,N过大可能减少每次FullGC时间,但增加FullGC频率,N过小可能增加每次FullGC时间 0 -XX:+CMSScavengeBeforeRemark GC前做一次YGC,降低remark时间 False 如果remark耗时长,考虑开启
4.5 G1垃圾收集器
G1(Garbage-First)是JDK9中默认的垃圾收集器,官方给G1设定的目标是在延迟可控的情况下,获得尽可能高的吞吐量。G1的思想是区域分代化,即避免在整个Java堆中进行全区域的垃圾收集,而是尽量优先回收垃圾最大量的区间(G1把内存划分为一个个区间,即Region),所以Garbage-First我们也可以理解为垃圾优先的意思。
4.5.1 为什么kafka这样大并发的中间件要选择G1垃圾回收器? (1) 预想场景1
假设线上有一服务,单机4C8G ,可支撑300~1000qps。
采用分代收集器 ,内存分配情况分别是JVM分配4G, 老年代3G,年轻代1G。
老年代Full GC时间是瓶颈,YGC还不是瓶颈,传统的分代垃圾回收器能支持。
(2) 预想场景2
假设线上有一个kafka集群,单台Kafka8C32G ,JVM分配30G,老年代20G,年轻代10G
这是不仅老年代FGC存在瓶颈,YGC也有瓶颈。
(3) 优化思路
避免全内存扫描,每次只回收一小块内存区域,或者指定回收部分内存区域。 GC的时间打散,原本2S/次,20*100MS/次,停顿感大大降低。
G1垃圾回收器算法原理也秉承了以上的思路。
4.5.2 算法原理
将整个堆内存区域分成大小相同的子区域(Region),JVM启动时会自动设置这些子区域的大小在堆的使用上,G1并不要求对象的存储一定是物理上连续的,只要逻辑上连续即可。 每个分区也不会固定地位某个代服务,可以按需在年轻代和老年代切换 启动时可以通过参数-XX:G1HeapRegionSize=n可指定分区大小(1MB~32MB,且必须是2的幂), 默认将整堆划分为2048个分区,大小范围在1MB~32MB
(1)新生代Region
依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或Survivor空间。
(2)老生代Region
对象从一个区域复制到另外一个区域,完成了清理工作这意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有CMS内存问题的存在了
(3)Humongous Region
在G1中,还有一种特殊的区域,叫Humongous(巨大的)区域如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。这种巨型对象默认直接会被分配在老年代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响,为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象如果H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储,为了能找到连续的H区,有时候不得不启动Full GC。
图24将演示G1垃圾回收器堆内存划分。
图24 堆内存划分
4.5.3 过程
初始标记:STW,标记GC ROOT直接关联到的对象,借用YGC的暂停,因此没有额外的、单独的暂停阶段。 并发标记:扫描整个堆并标记,可能被YGC打断。 最终标记:STW,标记在并发标记阶段发生变化的对象 清理:
图25演示G1垃圾回收过程。
图25 G1垃圾回收过程
4.5.4 优点
并发垃圾收集,相对CMS更快,停顿时间更好预测,无内存碎片,吞吐量更高
4.5.5 缺点
并发收集占用CPU,降低吞吐量 无法处理浮动垃圾,并发处理期间,如果需要将对象放入老生代,但老生代空间不足。G1将失败(allocation failure),此时降级为Serial,进行一次full gc,停顿时间大大提高。(java10后full gc优化成并行方式) G1 本身的数据结构也有很大的内存占用 G1对小堆没有太大优化,甚至不如CMS
4.5.6 参数说明
参数 说明 默认值 建议值 -XX:+UseG1GC 使用G1垃圾回收器 -XX:MaxGCPauseMillis=n 设置G1收集过程目标时间,注意设置Xmn/NewRatio都会覆盖此值 200ms -XX:G1NewSizePercent=n -XX:G1MaxNewSizePercent=n 新生代比例 新生代最大比例 5% 60% -XX:ParallelGCThread=n STW,并行GC线程数 -XX:ConcGCThread=n 并发标记阶段,并行执行的线程数 -XX:InitiatingHeapOccupancyPercent=n 设置触发标记周期的java堆占用率阈值 45% -XX:G1HeapRegionSize=n 设置Region大小,取值范围从1M~32M,且是2的指数 根据Heap大小自动决定,保证2048region 特定情况下考虑增大,以减少大对象 -XX:G1ReserverPercent=n 空闲空间的预留内存百分比,降低目标空间溢出的风险,遇到to-space overflow时可以调整该值 10
4.6 ZGC
英文全称Z Garbage Collector,即低延迟的并发垃圾收集器。
4.6.1 特点
非分代收集 最大支持4TB内存 最大暂停时间不超过10ms 最大吞吐率损耗不高于15% 暂停时间不会随着堆增大而变长 支持NUMA架构(各CPU访问自己临近的内存,避免并发竞争某一块内存)
(1)内存分区
为了细粒度地控制内存的分配,和G1一样,ZGC将内存划分成小的分区,在ZGC中称为页面(page)。ZGC支持3种页面,分别为小页面、中页面和大页面。其中小页面指的是2MB的页面空间,中页面指32MB的页面空间,大页面指受操作系统控制的大页。
图26演示了ZGC内存分区情况。
图26 ZGC内存分区
4.6.2 过程
初始阶段:STW,标记GC ROOT直接关联的对象 并发阶段:并发递归标记 标记结束:STW,处理一些边缘case,如弱引用清理等 重定位:将需要被清理的region中的对象转移到新的region 重新映射:更新跨region的调用
图27将简单演示ZGC的回收过程。
图27 ZGC回收过程
注:通过-XX:UseZGC,开启使用ZGCZGC未采用分代垃圾回收,因此内存参数只需要考虑Xmx。
5 常见JVM参数
可划分为三类,即标准参数(-)、非标准参数(-X)和非Stable参数(-XX)。
5.1 标准参数(-)
所有的JVM实现都必须实现这些参数的功能,而且向后兼容。
命令 java -help可以列出java 应用启动时标准选项(不同的JVM实现是不同的)。
如tpuc-core-server使用的镜像包中的jvm标准参数如下:
root@tpuc-core-server-5678c989b7-v82kw:/# java -help
Usage: java [-options] class [args...]
(to execute a class)
or java [-options] -jar jarfile [args...]
(to execute a jar file)
where options include:
-d32 use a 32-bit data model if available
-d64 use a 64-bit data model if available
-server to select the "server" VM
-zero to select the "zero" VM
-dcevm to select the "dcevm" VM
The default VM is server,
because you are running on a server-class machine.
-cp <class search path of directories and zip/jar files>
-classpath <class search path of directories and zip/jar files>
A : separated list of directories, JAR archives,
and ZIP archives to search for class files.
-D<name>=<value>
set a system property
-verbose:[class|gc|jni]
enable verbose output
-version print product version and exit
-version:<value>
Warning: this feature is deprecated and will be removed
in a future release.
require the specified version to run
-showversion print product version and continue
-jre-restrict-search | -no-jre-restrict-search
Warning: this feature is deprecated and will be removed
in a future release.
include/exclude user private JREs in the version search
-? -help print this help message
-X print help on non-standard options
-ea[:<packagename>...|:<classname>]
-enableassertions[:<packagename>...|:<classname>]
enable assertions with specified granularity
-da[:<packagename>...|:<classname>]
-disableassertions[:<packagename>...|:<classname>]
disable assertions with specified granularity
-esa | -enablesystemassertions
enable system assertions
-dsa | -disablesystemassertions
disable system assertions
-agentlib:<libname>[=<options>]
load native agent library <libname>, e.g. -agentlib:hprof
see also, -agentlib:jdwp=help and -agentlib:hprof=help
-agentpath:<pathname>[=<options>]
load native agent library by full pathname
-javaagent:<jarpath>[=<options>]
load Java programming language agent, see java.lang.instrument
-splash:<imagepath>
show splash screen with specified image
See http://www.oracle.com/technetwork/java/javase/documentation/index.html for more details.
5.2 非标准参数(-X)
默认JVM实现这些参数的功能,但是并不保证所有JVM实现都满足,且不保证向后兼容。
java -X可以列出不标准的参数(这是JVM的扩展特性)。-X相关的选项不是标准的,被改变也不会通知。
如tpuc-core-server使用的镜像包中jvm参数是:
root@tpuc-core-server-5678c989b7-v82kw:/# java -X
-Xmixed mixed mode execution (default)
-Xint interpreted mode execution only
-Xbootclasspath:<directories and zip/jar files separated by :>
set search path for bootstrap classes and resources
-Xbootclasspath/a:<directories and zip/jar files separated by :>
append to end of bootstrap class path
-Xbootclasspath/p:<directories and zip/jar files separated by :>
prepend in front of bootstrap class path
-Xdiag show additional diagnostic messages
-Xnoclassgc disable class garbage collection
-Xincgc enable incremental garbage collection
-Xloggc:<file> log GC status to a file with time stamps
-Xbatch disable background compilation
-Xms<size> set initial Java heap size
-Xmx<size> set maximum Java heap size
-Xss<size> set java thread stack size
-Xprof output cpu profiling data
-Xfuture enable strictest checks, anticipating future default
-Xrs reduce use of OS signals by Java/VM (see documentation)
-Xcheck:jni perform additional checks for JNI functions
-Xshare:off do not attempt to use shared class data
-Xshare:auto use shared class data if possible (default)
-Xshare:on require using shared class data, otherwise fail.
-XshowSettings show all settings and continue
-XshowSettings:all
show all settings and continue
-XshowSettings:vm
show all vm related settings and continue
-XshowSettings:system
(Linux Only) show host system or container
configuration and continue
-XshowSettings:properties
show all property settings and continue
-XshowSettings:locale
show all locale related settings and continue
The -X options are non-standard and subject to change without notice.
5.3 非Stable参数(-XX)
此类参数各个JVM实现会有所不同,这些都是不稳定的并且不推荐在生产环境中使用。将来可能会随时取消,需要慎重使用;而且如果在新版本有什么改动也不会发布通知。
5.4 JVM选项
关于JVM选项的几点:
1)布尔型参数选项:-XX:+ 打开,-XX:- 关闭。(比如-XX:+PrintGCDetails)
2)数字型参数选项:通过-XX:=设定。数字可以是m/M(兆字节),k/K(千字节),g/G(G字节)。比如:32K表示32768字节。
3)字符行参数选项:通过-XX:=设定。通常用来指定一个文件、路径,或者一个命令列表。(比如-XX:HeapDumpPath=./java_pid.hprof)
如果你想查看当前应用使用的JVM参数,你可以使用:
ManagementFactory.getRuntimeMXBean().getInputArguments()
5.5 常用参数讲解
5.5.1 标准参数篇 以下标准参数是比较有用的:
(1)参数明细
-verbose:class
输出JVM载入类的相关信息,当JVM报告说找不到类或者类冲突时可用此进行诊断。
-verbose:gc
输出每次GC的相关情况。
-verbose:jni
输出native方法调用的相关情况,一般用于诊断JNI(Java Native Interface)调用错误信息。
5.5.2 非标准参数篇 以下非标准参数是比较常用的:
(1) 参数明细
-Xms512m
设置JVM初始堆内存为512M。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmx512m
设置JVM最大堆可用内存为512M。
注意:常在生产环境上将-Xms与-Xmx值设为一致,减少运行期间系统在内存申请上的花销。
Xmn200m
设置年轻代大小为200M。此处的大小是(eden+ 2 survivor space);与jmap -heap中显示的New gen是(eden+1 survivor space)不同的。
注意:-Xmn 在G1/ZGC中要去掉新生代相关设置。
年老代大小 =(-Xmx)减(-Xmn) 整个堆大小 = 年轻代大小 + 年老代大小 + 持久代大小 持久代大小:一般固定大小为64M,所以增大年轻代(-Xmn)后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k
设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-Xss 设置过小,可能会栈溢出,设置过大,影响到创建栈的数量,如果是多线程的应用,就会出现内存溢出的错误【默认,或128k~512k】
-Xloggc:file
与-verbose:gc功能类似,只是将每次GC事件的相关情况记录到一个文件中,文件的位置最好在本地,以避免网络的潜在问题。若与verbose命令同时出现在命令行中,则以-Xloggc为准。
-Xprof
跟踪正运行的程序,并将跟踪数据在标准输出输出;适合于开发环境调试。
-Xrunhprof
HPROF是J2SE自带的一个内存使用分析工具profiler agent。他是一个动态链接库文件,监控CPU的使用率,Heap分配情况等。将这些信息输出到文件或到socket。从而找到占用内存较大的对象。这对应经常出现内存泄漏(OOM)的JAVA系统进行调优很有帮助。
-Xdebug
JVM调试参数,用于远程调试。
例如在tomcat中的远程调试设置方法为:
-Xdebug -Xnoagent -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8000
-Xnoagent:禁用默认sun.tools.debug调试器;
-Xbootclasspath
用来指定你需要加载,但不想通过校验的类路径。JVM 会对所有的类在加载前进行校验并为每个类通过一个int数值来应用。这个是保证 JVM稳定的必要过程,但比较耗时,如果你希望跳过这个过程,就把你的类通过这个参数来指定。
-Xnoclassgc
-Xnoclassgc 表示不对方法区进行垃圾回收。请谨慎使用。
5.5.3 非Stable参数篇
用-XX作为前缀的参数列表在JVM中可能是不健壮的,SUN也不推荐使用,后续可能会在没有通知的情况下就直接取消了;但是由于这些参数中的确有很多是对我们很有用的,比如我们经常会见到的-XX:PermSize、-XX:MaxPermSize等等。
(1) 行为参数
-XX:-DisableExplicitGC
禁止调用System.gc(),但JVM的GC仍然有效。
-XX:+MaxFDLimit
最大化文件描述符的数量限制。
-XX:+ScavengeBeforeFullGC
新生代GC优先于Full GC执行。
-XX:+UseGCOverheadLimit
在抛出OOM之前限制JVM耗费在GC上的时间比例。
-XX:-UseConcMarkSweepGC
对老年代采用并发标记交换算法进行GC。
-XX:-UseParallelGC
启用并行GC。
-XX:-UseParallelOldGC
对Full GC启用并行,当-XX:-UseParallelGC启用时该项自动启用。
-XX:-UseSerialGC
启用串行GC。
-XX:+UseThreadPriorities
启用本地线程优先级。
串行(SerialGC)是JVM的默认GC方式,一般适用于小型应用和单处理器,算法比较简单,GC效率也较高,但可能会给应用带来停顿;
并行(ParallelGC)是指GC运行时,对应用程序运行没有影响,GC和app两者的线程在并发执行,这样可以最大限度不影响app的运行;
并发(ConcMarkSweepGC)是指多个线程并发执行GC,一般适用于多处理器系统中,可以提高GC的效率,但算法复杂,系统消耗较大。
(2)性能调优
-XX:LargePageSizeInBytes=4m
设置用于Java堆的大页面尺寸。
-XX:MaxHeapFreeRatio=70
GC后Java堆中空闲量占的最大比例。
-XX:MinHeapFreeRatio=40
GC后Java堆中空闲量占的最小比例。
-XX:MaxNewSize=512m
新生成对象能占用内存的最大值。
-XX:MaxPermSize=64m
老年代对象能占用内存的最大值。
-XX:NewRatio=2
新生代内存容量与老年代内存容量的比例。
-XX:SurvivorRatio
用于设置Eden和其中一个Survivor的比值,默认比例为8(Eden):1(一个survivor)。
例如:-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6。
-XX:NewSize=2.125m
新生代对象生成时占用内存的默认值。
-XX:MaxMetaspaceSize
java8中-XX:MaxMetaspaceSize=10m设置MetaSpace的最大值为10M。默认是Java的Metaspace空间不受限制。
-没有配置-XX:MetaspaceSize,那么触发FGC的阈值是21807104(约20.8m),可以通过jinfo -flag MetaspaceSize pid得到这个值
-如果配置了-XX:MetaspaceSize,那么触发FGC的阈值就是配置的值;
-Metaspace由于使用不断扩容到-XX:MetaspaceSize参数指定的量,就会发生FGC;且之后每次Metaspace扩容都可能会发生FGC(至于什么时候会,比较复杂,跟几个参数有关);
-如果Old区配置CMS垃圾回收,那么扩容引起的FGC也会使用CMS算法进行回收;
-如果MaxMetaspaceSize设置太小,可能会导致频繁FullGC,甚至OOM
-XX:ReservedCodeCacheSize=32m
保留代码占用的内存容量。
-XX:ThreadStackSize=512
设置线程栈大小,若为0则使用系统默认值。
-XX:+UseLargePages
使用大页面内存。
(3)调试参数
-XX:-CITime
打印消耗在JIT(Just-In-Time Compilation,即时编译)编译的时间。
-XX:ErrorFile=./hs_err_pid<pid>.log
保存错误日志或者数据到文件中。
-XX:-ExtendedDTraceProbes
开启solaris特有的dtrace(Dynamic Tracing,也称为动态跟踪)探针。
-XX:HeapDumpPath=./java_pid<pid>.hprof
指定导出堆信息时的路径或文件名。
-XX:-HeapDumpOnOutOfMemoryError
当首次遭遇OOM时导出此时堆中相关信息。
-XX:OnError
例:-XX:OnError="<cmd args>;<cmd args>"
出现致命ERROR之后运行自定义命令。
-XX:OnOutOfMemoryError
例:-XX:OnOutOfMemoryError="<cmd args>;<cmd args>"
当首次遭遇OOM时执行自定义命令。
-XX:-PrintClassHistogram
遇到Ctrl-Break后打印类实例的柱状信息,与jmap -histo功能相同。
-XX:-PrintConcurrentLocks
遇到Ctrl-Break后打印并发锁的相关信息,与jstack -l功能相同。
-XX:-PrintCommandLineFlags
打印在命令行中出现过的标记。
-XX:-PrintCompilation
当一个方法被编译时打印相关信息。
-XX:-PrintGC
每次GC时打印相关信息。
-XX:-PrintGCDetails
每次GC时打印详细信息。
-XX:-PrintGCTimeStamps
打印每次GC的时间戳。
-XX:-TraceClassLoading
跟踪类的加载信息
-XX:-TraceClassLoadingPreorder
跟踪被引用到的所有类的加载信息
-XX:-TraceClassResolution
跟踪常量池。
-XX:-TraceClassUnloading
跟踪类的卸载信息。
-XX:-TraceLoaderConstraints
跟踪类加载器约束的相关信息。
5.6 示例 如下指令,会指定相关的jar运行,OOM会自动生成相应的堆栈,且支持日志的打印。
java -Xmx128m -Xmx128m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/zhangzhongqiu/demo/ -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log -XX:MetaspaceSize=64M -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=3 -XX:GCLogFileSize=2m -jar demo-0.0.1-SNAPSHOT.jar --mock.load.mysql.data.enabled=true>demo.log &
6 常用分析命令及工具
java服务在运行的过程中,我们监控相关的指标,进行故障排除,都需要有相关的命令和工具。下面将讲述相关的命令和工具进行介绍。
6.1 JPS Java虚拟机进程状态工具,支持语法如下:
jps [options] [hostid]
示例:
root@tpuc-core-server-5678c989b7-wkjrc:/# jps -v
993 Jps -Dapplication.home=/usr/lib/jvm/java-8-openjdk-amd64 -Xms8m
6 server.jar -javaagent:/opt/skywalking/agent/skywalking-agent.jar -XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap -XX:InitialRAMPercentage=60.0 -XX:MaxRAMPercentage=60.0 -XX:MinRAMPercentage=60.0 -Dfile.encoding=UTF-8 -Dlogging.config=/home/ubuntu/server/config/log4j2.xml -Dspring.config.location=/home/ubuntu/server/config/,/home/ubuntu/server/secret/
6.2 jmap 命令jmap是一个多功能的命令。它可以生成 java 程序的 dump 文件, 也可以查看堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
jmap [ option ] pid
示例:
jmap -dump:format=b,file=/var/logs/heap.hprof pid
6.3 Jstat Jstat是JDK自带的一个轻量级小工具。全称“Java Virtual Machine statistics monitoring tool”,它位于java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。
jstat [ generalOption | outputOptions vmid [ interval [ s|ms ] [ count ] ] ]
示例:
root@tpuc-core-server-5678c989b7-wkjrc:/# jstat -gcutil 6 10 10
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
47.21 0.00 81.67 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.67 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.67 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.73 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.73 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.73 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.73 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.77 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.77 41.73 94.82 93.40 344 11.501 5 1.246 12.747
47.21 0.00 81.77 41.73 94.82 93.40 344 11.501 5 1.246 12.747
6.4 jstack jstack是java虚拟机自带的一种堆栈跟踪工具,用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息。
jstack [ option ] pid
-m 打印Java和C++栈信息
-l 额外打印关于锁的信息
示例:jstack 9029|grep 244b –A 30
6.5 Jhat jhat也是jdk内置的工具之一。主要是用来分析java堆的命令,可以将堆中的对象以html的形式显示出来,包括对象的数量,大小等等,并支持对象查询语言。
使用jmap等方法生成java的堆文件后,使用其进行分析。
6.6 jinfo 打印配置信息【重点其实是可以动态设置虚拟机参数】
jinfo [ option ] pid
6.7 jconsole jdk自带可视化工具,可以监控CPU、内存、线程等情况。
6.8 Visual VM Visual VM是一款All-in-One的Java分析工具,堆栈信息、线程信息等都可以分析,而且还支持装插件。但jdk1.9之后默认JDK不再支持,可以通过VisualVM: Download 这里下载。
7 Arthas
7.1 安装 7.1.1 快速安装 (1) 使用arthas-boot(推荐)
下载arthas-boot.jar,然后用java -jar的方式启动:
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
打印帮助信息:
java -jar arthas-boot.jar -h
(2) 使用as.sh
Arthas 支持在 Linux/Unix/Mac 等平台上一键安装,请复制以下内容,并粘贴到命令行中,敲 回车 执行即可:
curl -L https://arthas.aliyun.com/install.sh | sh
上述命令会下载启动脚本文件 as.sh 到当前目录,你可以放在任何地方或将其加入到 $PATH 中。 直接在shell下面执行./as.sh,就会进入交互界面。
也可以执行./as.sh -h来获取更多参数信息。
7.1.2 全量安装 最新版本,点击下载:
解压后,在文件夹里有arthas-boot.jar,直接用java -jar的方式启动:
java -jar arthas-boot.jar
打印帮助信息:
java -jar arthas-boot.jar -h
7.1.3 手动安装 (1)通过rpm/deb来安装
在releases页面下载rpm/deb包: https://github.com/alibaba/arthas/releases
安装deb
安装rpm
deb/rpm安装的用法
在安装后,可以直接执行:
7.2 命令列表 7.2.1 基础命令
help——查看命令帮助信息 cat——打印文件内容,和linux里的cat命令类似 echo–打印参数,和linux里的echo命令类似 grep——匹配查找,和linux里的grep命令类似 base64——base64编码转换,和linux里的base64命令类似 tee——复制标准输入到标准输出和指定的文件,和linux里的tee命令类似 pwd——返回当前的工作目录,和linux命令类似 cls——清空当前屏幕区域 session——查看当前会话的信息 reset——重置增强类,将被 Arthas 增强过的类全部还原,Arthas 服务端关闭时会重置所有增强过的类 version——输出当前目标 Java 进程所加载的 Arthas 版本 history——打印命令历史 quit——退出当前 Arthas 客户端,其他 Arthas 客户端不受影响 stop——关闭 Arthas 服务端,所有 Arthas 客户端全部退出 keymap——Arthas快捷键列表及自定义快捷键 7.2.2 jvm相关
dashboard——当前系统的实时数据面板 thread——查看当前 JVM 的线程堆栈信息 jvm——查看当前 JVM 的信息 sysprop——查看和修改JVM的系统属性 sysenv——查看JVM的环境变量 vmoption——查看和修改JVM里诊断相关的option perfcounter——查看当前 JVM 的Perf Counter信息 logger——查看和修改logger getstatic——查看类的静态属性 ognl——执行ognl表达式 mbean——查看 Mbean 的信息 heapdump——dump java heap, 类似jmap命令的heap dump功能 vmtool——从jvm里查询对象,执行forceGc 7.2.3 class/classloader相关
sc——查看JVM已加载的类信息 sm——查看已加载类的方法信息 jad——反编译指定已加载类的源码 mc——内存编译器,内存编译.java文件为.class文件 retransform——加载外部的.class文件,retransform到JVM里 redefine——加载外部的.class文件,redefine到JVM里 dump——dump 已加载类的 byte code 到特定目录 classloader——查看classloader的继承树,urls,类加载信息,使用classloader去getResource 7.2.4 monitor/watch/trace相关
monitor——方法执行监控 watch——方法执行数据观测 trace——方法内部调用路径,并输出方法路径上的每个节点上耗时 stack——输出当前方法被调用的调用路径 tt——方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测 7.2.5 profiler/火焰图
profiler–使用async-profiler对应用采样,生成火焰图 7.2.6 鉴权
7.2.7 options
7.2.8 管道 Arthas支持使用管道对上述命令的结果进行进一步的处理,如sm java.lang.String * | grep 'index'
grep——搜索满足条件的结果 plaintext——将命令的结果去除ANSI颜色 wc——按行统计输出结果 7.2.9 后台异步任务 当线上出现偶发的问题,比如需要watch某个条件,而这个条件一天可能才会出现一次时,异步后台任务就派上用场了,详情请参考这里
使用 > 将结果重写向到日志文件,使用 & 指定命令是后台运行,session断开不影响任务执行(生命周期默认为1天)
jobs——列出所有job kill——强制终止任务 fg——将暂停的任务拉到前台执行 bg——将暂停的任务放到后台执行
7.3 常用指令介绍 7.3.1 dashboard
当运行在Ali-tomcat时,会显示当前tomcat的实时信息,如HTTP请求的qps, rt, 错误数, 线程池信息等等。
(1) 参数说明
参数名称 参数说明 [i:] 刷新实时数据的时间间隔 (ms),默认5000ms [n:] 刷新实时数据的次数
(2) 使用参考
[arthas@7]$ dashboard
ID NAME GROUP PRIORI STATE %CPU DELTA_ TIME INTER DAEMON
-1 C2 CompilerThread0 - -1 - 0.0 0.000 2:33.9 false true
21 DestroyJavaVM main 5 RUNNAB 0.0 0.000 1:24.5 false false
-1 C1 CompilerThread1 - -1 - 0.0 0.000 0:38.7 false true
-1 VM Thread - -1 - 0.0 0.000 0:27.6 false true
7 DataCarrier.DEFAULT main 5 TIMED_ 0.0 0.000 0:16.7 false true
10 event_center_tpuc.t main 5 RUNNAB 0.0 0.000 0:13.5 false false
13 event_center_tpuc.n main 5 RUNNAB 0.0 0.000 0:13.1 false false
10 event_center_tpuc.t main 5 RUNNAB 0.0 0.000 0:12.9 false false
14 event_center_tpuc.l main 5 RUNNAB 0.0 0.000 0:12.8 false false
13 event_center_tpuc.n main 5 RUNNAB 0.0 0.000 0:12.8 false false
Memory used total max usage GC
heap 322M 870M 870M gc.copy.count 427
eden_space 51M 240M 240M gc.copy.time(ms) 14949
survivor_space 10M 30M 30M gc.marksweepcompact 5
tenured_gen 261M 600M 600M .count
nonheap 372M 386M -1 gc.marksweepcompact 1342
code_cache 124M 125M 240M .time(ms)
metaspace 220M 231M -1
Runtime
os.name Linux
os.version 4.14.238-182.422.amzn2.x86_64
java.version 1.8.0_292
(3) 数据说明
ID: Java级别的线程ID,注意这个ID不能跟jstack中的nativeID一一对应。 NAME: 线程名 GROUP: 线程组名 PRIORITY: 线程优先级, 1~10之间的数字,越大表示优先级越高 STATE: 线程的状态 CPU%: 线程的cpu使用率。比如采样间隔1000ms,某个线程的增量cpu时间为100ms,则cpu使用率=100/1000=10% DELTA_TIME: 上次采样之后线程运行增量CPU时间,数据格式为秒 TIME: 线程运行总CPU时间,数据格式为分:秒 INTERRUPTED: 线程当前的中断位状态 DAEMON: 是否是daemon线程 7.3.2 thread
(1) 参数说明
参数名称 参数说明 id 线程id [n:] 指定最忙的前N个线程并打印堆栈 [b] 找出当前阻塞其他线程的线程 [i <value>] 指定cpu使用率统计的采样间隔,单位为毫秒,默认值为200 [--all] 显示所有匹配的线程
cpu使用率是如何统计出来的?
这里的cpu使用率与linux 命令top -H -p <pid> 的线程%CPU类似,一段采样间隔时间内,当前JVM里各个线程的增量cpu时间与采样间隔时间的比例。
工作原理说明:
首先第一次采样,获取所有线程的CPU时间(调用的是java.lang.management.ThreadMXBean#getThreadCpuTime()及sun.management.HotspotThreadMBean.getInternalThreadCpuTimes()接口) 然后睡眠等待一个间隔时间(默认为200ms,可以通过-i指定间隔时间) 再次第二次采样,获取所有线程的CPU时间,对比两次采样数据,计算出每个线程的增量CPU时间 线程CPU使用率 = 线程增量CPU时间 / 采样间隔时间 * 100% 注意:
这个统计也会产生一定的开销(JDK这个接口本身开销比较大),因此会看到as的线程占用一定的百分比,为了降低统计自身的开销带来的影响,可以把采样间隔拉长一些,比如5000毫秒。
7.3.3 jad
jad 命令将 JVM 中实际运行的 class 的 byte code 反编译成 java 代码,便于你理解业务逻辑;
在 Arthas Console 上,反编译出来的源码是带语法高亮的,阅读更方便 当然,反编译出来的 java 代码可能会存在语法错误,但不影响你进行阅读理解 (1) 参数说明
参数说明 参数说明 class-pattern 类名表达式匹配 [c:] 类所属 ClassLoader 的 hashcode [classLoaderClass:] 指定执行表达式的 ClassLoader 的 class name [E] 开启正则表达式匹配,默认为通配符匹配
7.3.4 watch
让你能方便的观察到指定函数的调用情况。能观察到的范围为:返回值、抛出异常、入参,通过编写 OGNL 表达式进行对应变量的查看。
(1) 参数说明
watch 的参数比较多,主要是因为它能在 4 个不同的场景观察对象
参数名称 参数说明 class-pattern 类名表达式匹配 method-pattern 函数名表达式匹配 express 观察表达式,默认值:{params, target, returnObj} condition-express [b] 在函数调用之前观察 [e] 在函数调用之后观察 [s] 在函数返回之后观察 [f] 在函数结束之后(正常返回和异常返回)观察 [E] 开启正则表达式匹配,默认为通配符匹配 [x:] 指定输出结果的属性遍历深度,默认为 1
这里重点要说明的是观察表达式,观察表达式的构成主要由 ognl 表达式组成,所以你可以这样写"{params,returnObj}",只要是一个合法的 ognl 表达式,都能被正常支持。
观察的维度也比较多,主要体现在参数 advice 的数据结构上。Advice 参数最主要是封装了通知节点的所有信息。请参考表达式核心变量中关于该节点的描述。
特别说明:
watch 命令定义了4个观察事件点,即 -b 函数调用前,-e 函数异常后,-s 函数返回后,-f 函数结束后 4个观察事件点 -b、-e、-s 默认关闭,-f 默认打开,当指定观察点被打开后,在相应事件点会对观察表达式进行求值并输出 这里要注意函数入参和函数出参的区别,有可能在中间被修改导致前后不一致,除了 -b 事件点 params 代表函数入参外,其余事件都代表函数出参 当使用 -b 时,由于观察事件点是在函数调用前,此时返回值或异常均不存在 在watch命令的结果里,会打印出location信息。location有三种可能值:AtEnter,AtExit,AtExceptionExit。对应函数入口,函数正常return,函数抛出异常。 7.3.5 Monitor
对匹配 class-pattern/method-pattern/condition-express的类、方法的调用进行监控。
monitor 命令是一个非实时返回命令.
实时返回命令是输入之后立即返回,而非实时返回的命令,则是不断的等待目标 Java 进程返回信息,直到用户输入 Ctrl+C 为止。
服务端是以任务的形式在后台跑任务,植入的代码随着任务的中止而不会被执行,所以任务关闭后,不会对原有性能产生太大影响,而且原则上,任何Arthas命令不会引起原有业务逻辑的改变。
监控的维度说明
监控项 说明 timestamp 时间戳 class Java类 method 方法(构造方法、普通方法) total 调用次数 success 成功次数 fail 失败次数 rt 平均RT fail-rate 失败率
(1) 参数说明
方法拥有一个命名参数 [c:],意思是统计周期(cycle of output),拥有一个整型的参数值
参数名称 参数说明 class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 condition-express 条件表达式 [E] 开启正则表达式匹配,默认为通配符匹配 [c:]统计周期,默认值为120秒 [b] 在方法调用之前 计算condition-express
7.3.6 trace
方法内部调用路径,并输出方法路径上的每个节点上耗时
trace 命令能主动搜索 class-pattern/method-pattern 对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路。
(1) 参数说明
参数名称 参数说明 class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 condition-express 条件表达式 [E] 开启正则表达式匹配,默认为通配符匹配 [n:]命令执行次数 #cost方法执行耗时
这里重点要说明的是观察表达式,观察表达式的构成主要由 ognl 表达式组成,所以你可以这样写"{params,returnObj}",只要是一个合法的 ognl 表达式,都能被正常支持。
观察的维度也比较多,主要体现在参数 advice 的数据结构上。Advice 参数最主要是封装了通知节点的所有信息。
请参考表达式核心变量中关于该节点的描述。
很多时候我们只想看到某个方法的rt大于某个时间之后的trace结果,现在Arthas可以按照方法执行的耗时来进行过滤了,例如trace *StringUtils isBlank '#cost>100'表示当执行时间超过100ms的时候,才会输出trace的结果。
watch/stack/trace这个三个命令都支持#cost
(2) 注意事项
trace 能方便的帮助你定位和发现因 RT 高而导致的性能问题缺陷,但其每次只能跟踪一级方法的调用链路。
参考:Trace命令的实现原理
3.3.0 版本后,可以使用动态Trace功能,不断增加新的匹配类,参考下面的示例。
目前不支持 trace java.lang.Thread getName,参考issue: #1610 ,考虑到不是非常必要场景,且修复有一定难度,因此当前暂不修复
7.3.7 stack
很多时候我们都知道一个方法被执行,但这个方法被执行的路径非常多,或者你根本就不知道这个方法是从那里被执行了,此时你需要的是 stack 命令。
(1) 参数说明
参数名称 参数说明 class-pattern 类名表达式匹配 method-pattern 方法名表达式匹配 condition-express 条件表达式 [E] 开启正则表达式匹配,默认为通配符匹配 [n:]执行次数限制
这里重点要说明的是观察表达式,观察表达式的构成主要由 ognl 表达式组成,所以你可以这样写"{params,returnObj}",只要是一个合法的 ognl 表达式,都能被正常支持。
观察的维度也比较多,主要体现在参数 advice 的数据结构上。Advice 参数最主要是封装了通知节点的所有信息。
请参考表达式核心变量 中关于该节点的描述。
7.3.8 ognl
从3.0.5版本增加
(1) 参数说明
参数名称 参数说明 express 执行的表达式 [c:]执行表达式的 ClassLoader 的 hashcode,默认值是SystemClassLoader [classLoaderClass:]指定执行表达式的 ClassLoader 的 class name [x] 结果对象的展开层次,默认值1
7.3.9 profiler
profiler 命令支持生成应用热点的火焰图。本质上是通过不断的采样,然后把收集到的采样结果生成火焰图。
profiler 命令基本运行结构是 profiler action [actionArg]
(1)参数说明
参数名称 参数说明 action 要执行的操作 actionArg 属性名模式 [i:] 采样间隔(单位:ns)(默认值:10'000'000,即10 ms) [f:] 将输出转储到指定路径 [d:] 运行评测指定秒 [e:] 要跟踪哪个事件(cpu, alloc, lock, cache-misses等),默认是cpu
(1) 启动profiler
$ profiler start
Started [cpu] profiling
默认情况下,生成的是cpu的火焰图,即event为cpu。可以用--event参数来指定。
(2) 获取已采集的sample的数量
$ profiler getSamples 23
(3) 查看profiler状态
$ profiler status
[cpu] profiling is running for 4 seconds
可以查看当前profiler在采样哪种event和采样时间。
(4) 停止profiler
生成html格式结果
默认情况下,结果文件是html格式,也可以用--format参数指定:
$ profiler stop --format html
profiler output file: /tmp/test/arthas-output/20211207-111550.html
OK
或者在--file参数里用文件名指名格式。比如--file /tmp/result.html 。
通过浏览器查看arthas-output下面的profiler结果
默认情况下,arthas使用3658端口,则可以打开: http://localhost:3658/arthas-output/ 查看到arthas-output目录下面的profiler结果:
点击可以查看具体的结果:
图28 火焰图示例
7.3.10 代码热更新
(1) 步骤
反编译
jad --source-only com.example.demo.controller.DemoApiController > /usr/zhangzhongqiu/demo/DemoApiController.java
此处修改该java源文件内容
查看被什么类加载器加载
sc -d *DemoApiController | grep classLoader
MC用指定的classloader重新将类在内存中编译
mc -c 5910e440 /usr/zhangzhongqiu/demo/DemoApiController.java -d /usr/zhangzhongqiu/demo/data
redefine命令 将编译后的类加载到JVM
redefine /usr/zhangzhongqiu/demo/data/com/example/demo/controller/DemoApiController.class
8 实战调优 8.1 OOM问题定位及解决 Out of Memory是Java开发中常见的。现有项目如下:
8.1.1 启动运行
java -Xmx128m -Xmx128m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/mnt/hgfs/shared-files/ -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log -XX:MetaspaceSize=64M -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=3 -XX:GCLogFileSize=2m -jar tester-1.0-SNAPSHOT.jar --mock.load.mysql.data.enabled=true>demo.log &
8.1.2 启动后日志检查 启动日志正常:
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.1.18.RELEASE)
2021-12-14 03:55:53.707 INFO 4575 --- [ main] com.link.tester.Application : Starting Application v1.0-SNAPSHOT on ubuntu with PID 4575 (/mnt/hgfs/shared-files/tester-1.0-SNAPSHOT.jar started by zhangzhongqiu in /mnt/hgfs/shared-files)
2021-12-14 03:55:53.710 INFO 4575 --- [ main] com.link.tester.Application : No active profile set, falling back to default profiles: default
2021-12-14 03:55:54.840 INFO 4575 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2021-12-14 03:55:54.873 INFO 4575 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2021-12-14 03:55:54.873 INFO 4575 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/9.0.39]
2021-12-14 03:55:54.976 INFO 4575 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2021-12-14 03:55:54.977 INFO 4575 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1224 ms
2021-12-14 03:55:55.236 INFO 4575 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2021-12-14 03:55:55.417 INFO 4575 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2021-12-14 03:55:55.421 INFO 4575 --- [ main] com.link.tester.Application : Started Application in 2.038 seconds (JVM running for 2.416)
2021-12-14 03:55:59.157 INFO 4575 --- [nio-8080-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2021-12-14 03:55:59.158 INFO 4575 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2021-12-14 03:55:59.164 INFO 4575 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 6 ms
GC日志也正常:
Java HotSpot(TM) 64-Bit Server VM (25.291-b10) for linux-amd64 JRE (1.8.0_291-b10), built on Apr 7 2021 19:13:06 by "java_re" with gcc 7.3.0
Memory: 4k page, physical 8688312k(6307864k free), swap 2097148k(2097148k free)
CommandLine flags: -XX:GCLogFileSize=2097152 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/mnt/hgfs/shared-files/ -XX:InitialHeapSize=134217728 -XX:MaxHeapSize=134217728 -XX:MetaspaceSize=67108864 -XX:NumberOfGCLogFiles=3 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseGCLogFileRotation -XX:+UseParallelGC
0.380: [GC (Allocation Failure) [PSYoungGen: 33280K->3449K(38400K)] 33280K->3465K(125952K), 0.0038374 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
0.541: [GC (GCLocker Initiated GC) [PSYoungGen: 36729K->3796K(38400K)] 36748K->3823K(125952K), 0.0038038 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.633: [GC (Allocation Failure) [PSYoungGen: 37076K->4134K(38400K)] 37110K->4176K(125952K), 0.0036337 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.732: [GC (Allocation Failure) [PSYoungGen: 37414K->4758K(38400K)] 37456K->4808K(125952K), 0.0044584 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
0.815: [GC (Allocation Failure) [PSYoungGen: 38038K->4822K(38400K)] 38088K->4880K(125952K), 0.0040981 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.908: [GC (Allocation Failure) [PSYoungGen: 38102K->5094K(35328K)] 38160K->6365K(122880K), 0.0059273 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
0.988: [GC (Allocation Failure) [PSYoungGen: 35302K->4416K(36864K)] 36573K->8197K(124416K), 0.0085335 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
1.104: [GC (Allocation Failure) [PSYoungGen: 34624K->3514K(36352K)] 38405K->8184K(123904K), 0.0051545 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
1.210: [GC (Allocation Failure) [PSYoungGen: 34234K->3008K(36864K)] 38904K->8575K(124416K), 0.0064231 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
1.327: [GC (Allocation Failure) [PSYoungGen: 33728K->2336K(36864K)] 39295K->8771K(124416K), 0.0036950 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
1.445: [GC (Allocation Failure) [PSYoungGen: 32481K->1910K(36864K)] 38917K->9857K(124416K), 0.0035792 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
1.624: [GC (Allocation Failure) [PSYoungGen: 32118K->2213K(36864K)] 40065K->11019K(124416K), 0.0030660 secs] [Times: user=0.00 sys=0.01, real=0.00 secs]
1.793: [GC (Allocation Failure) [PSYoungGen: 32421K->1928K(36864K)] 41227K->11964K(124416K), 0.0030528 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
1.915: [GC (Allocation Failure) [PSYoungGen: 32136K->1809K(36864K)] 42172K->13053K(124416K), 0.0029992 secs] [Times: user=0.01 sys=0.01, real=0.00 secs]
2.088: [GC (Allocation Failure) [PSYoungGen: 32017K->1952K(36864K)] 43261K->14060K(124416K), 0.0034576 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
2.256: [GC (Allocation Failure) [PSYoungGen: 32160K->1696K(36864K)] 44268K->14599K(124416K), 0.0030879 secs] [Times: user=0.00 sys=0.01, real=0.00 secs]
6.108: [GC (Allocation Failure) [PSYoungGen: 31904K->1781K(36864K)] 44807K->15612K(124416K), 0.0035899 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
8.1.3 浏览器访问 模拟分页请求如下,将从数据库拉取数据。
http://192.168.40.129:8080/v1/tester/device/page
单条请求正常,结果如图29所示:
图29 请求单条成功示意图
8.1.4 查看堆栈分配情况
Attaching to process ID 4575, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.291-b10
using thread-local object allocation.
Parallel GC with 3 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 134217728 (128.0MB)
NewSize = 44564480 (42.5MB)
MaxNewSize = 44564480 (42.5MB)
OldSize = 89653248 (85.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 67108864 (64.0MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 30932992 (29.5MB)
used = 24050192 (22.936050415039062MB)
free = 6882800 (6.5639495849609375MB)
77.74932344081039% used
From Space:
capacity = 6815744 (6.5MB)
used = 1824256 (1.73974609375MB)
free = 4991488 (4.76025390625MB)
26.76532451923077% used
To Space:
capacity = 6815744 (6.5MB)
used = 0 (0.0MB)
free = 6815744 (6.5MB)
0.0% used
PS Old Generation
capacity = 89653248 (85.5MB)
used = 14163240 (13.507118225097656MB)
free = 75490008 (71.99288177490234MB)
15.79779909368147% used
15499 interned Strings occupying 1441504 bytes.
8.1.5 模拟100并发进行访问 模拟客户端并发访问:
@Slf4j
public class Main {
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor pool = new ThreadPoolTaskExecutor();
//设置核心线程数
pool.setCorePoolSize(100);
//最大线程数
pool.setMaxPoolSize(100);
//缓冲队列数
pool.setQueueCapacity(10000);
//线程池名前缀
pool.setThreadNamePrefix("user-");
//允许线程空闲时间(单位:默认为秒)
pool.setKeepAliveSeconds(300);
// 设置拒绝策略,当线程池阻塞队列已满时对新任务的处理。调节机制,即饱和时回退主线程执行
pool.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 等待所有任务结束后再关闭线程池
pool.setWaitForTasksToCompleteOnShutdown(true);
// 初始化
pool.initialize();
return pool;
}
public void print() {
String url = "http://192.168.40.129:8080/v1/tester/device/page";
OkHttpClient okHttpClient = new OkHttpClient();
final Request request = new Request.Builder()
.url(url)
.build();
final Call call = okHttpClient.newCall(request);
try {
Response response = call.execute();
log.info("{} run: ", response.body());
} catch (IOException e) {
log.error("Error is {}", e);
}
}
public static void main(String[] args) {
Main main = new Main();
ThreadPoolTaskExecutor threadPoolTaskExecutor = main.taskExecutor();
for(int i=0;i<10000;i++) {
threadPoolTaskExecutor.execute(()->{main.print();});
}
}
}
查看服务端日志
Exception in thread "http-nio-8080-exec-61" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-57" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-60" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-63" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-66" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-65" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-70" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-71" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-112" java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "http-nio-8080-exec-73" java.lang.OutOfMemoryError: GC overhead limit exceeded
8.1.6 服务自动dump的文件 服务自动dump文件如图30所示:
图30 OOM时服务自动dump文件
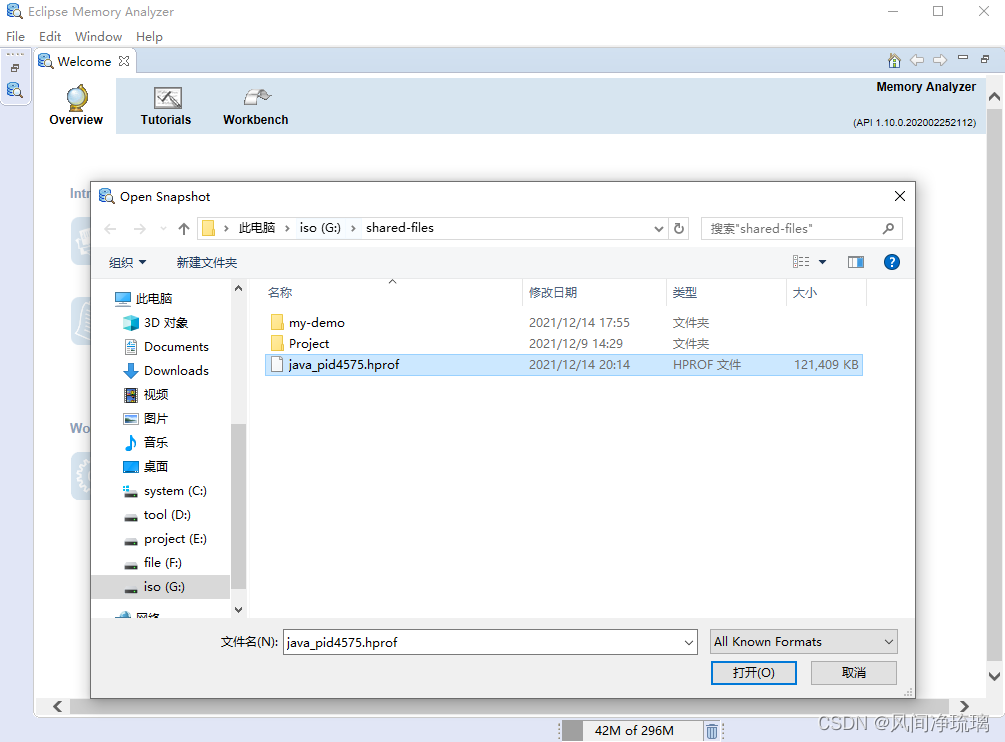
8.1.7 引入MAT进行分析 (1) 打开堆文件
图31 通过Eclipse Memory Anayzer打开了堆文件。
图31 打开堆文件
注:dump的文件太大时,可以适当增加mat的内存。
(2) 查看堆文件分析概述
Actiions
Histogram:可以列出内存中的对象,对象的个数及大小。
Dominator Tree:可以列出某个线程,以及线程下面的哪些对象占用的空间。
Top Consumers:通过图形列出最大的object。
Duplicate Classes:检测由多个类加载器加载的类。
Reports
Leak Suspects:通过MAT自动分析泄露的原因。
Top Components:列出大于总堆1%的组件的报告。
Component Report:分析属于公共根包或类加载器的对象。
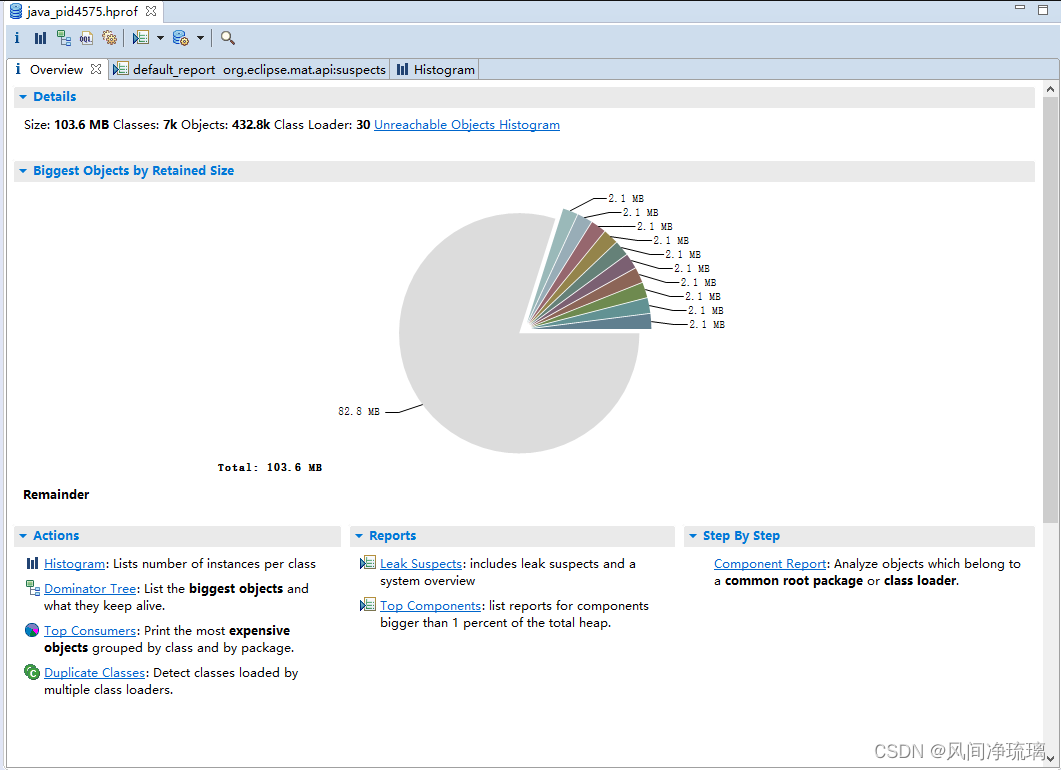
图32 分页概述页面如下,总共128MB的内存,灰色部分内部占有82.8MB。
图32 堆文件分析概述
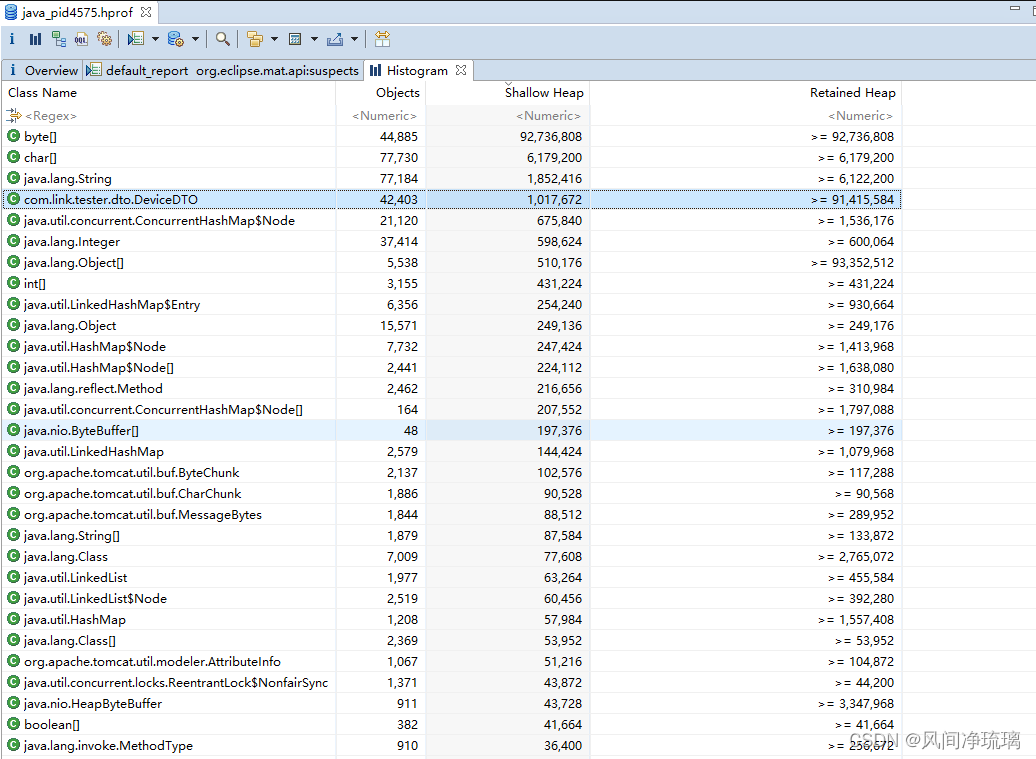
(3) Histogram分析
图33可以看见com.link.tester.dto.DeviceDTO 实例数有42403个。
图33 实例数直方图
(4) Leak Suspects风险泄露查看
图34可以查看风险泄露问题:
图34 风险泄露查看
(5) Top Components查看
图35 能看到最大组件和v1/tester/device/page有关。
图35 最大组件
(6) 总结定位
从上面的内存分析,服务端代码http线程池、使用com.link.tester.dto.DeviceDTO,且/v1/tester/device/page,可能会造成OOM。根据该信息查找代码中使用了DeviceDto对象的地方。
@RestController
@RequestMapping("/v1/tester")
public class DeviceController {
@Autowired
private Config config;
@GetMapping("/device/page")
public List<DeviceDTO> getDeviceList(){
Integer contentLenth = config.getContentLenth();
Integer pageSize = config.getPageSize();
List<DeviceDTO> list = new ArrayList<>(pageSize);
for(int i=0;i<pageSize;i++){
list.add(DeviceDTO.buildDevice(i,"name"+i,new byte[contentLenth]));
}
return list;
}
}
通过如上代码我们可以发现:
单人请求结果内存=2.1MB
客户端并发为100时,此时内存=210mb,比总内存128MB还要大。这里模拟的是数据库查询太多,OOM问题。
(7) 改进
改进的方式很多:
总内存调整到1G 修改代码,单次访问返回100条记录 列表中实体的信息按需返回
8.2 栈问题
栈溢出问题是个常见问题,下面会演示怎么抓取栈相关信息。
8.2.1 步骤 (1) top
找到cpu占用最高的进程pid
(2) ps -mp 9029 -o THREAD,tid,time | sort –rn
pid为9029的线程运行列表,找到最耗时的tid 9291
(3) printf "%x\n" 9291
得到线程9291的十六进制,为244b
(4) stack 9029|grep 244b –A 30
得到进程中cpu占用最高的栈信息
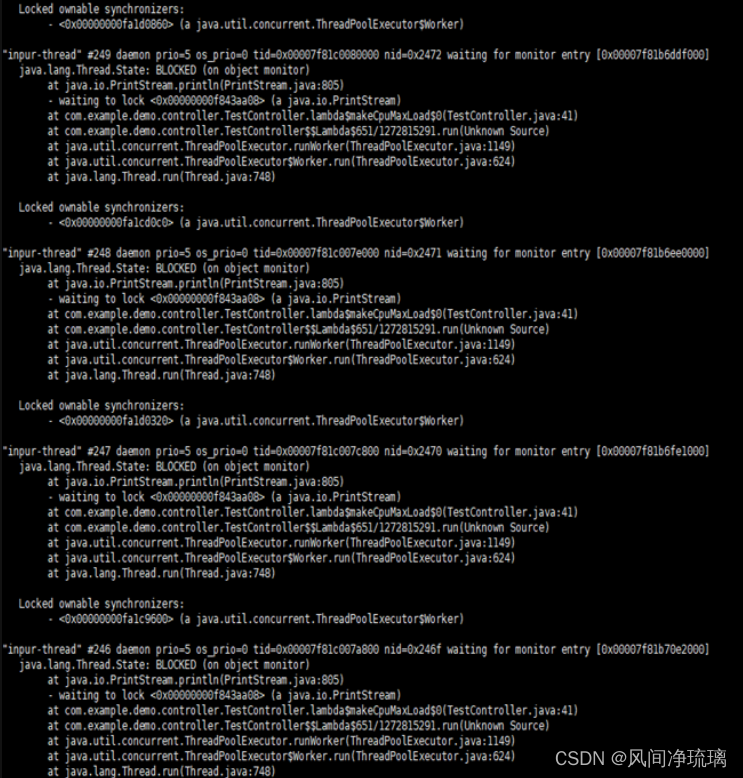
图36 可以看到业务代码Testcontroller写出了死锁,线程blocked。
图36 死锁问题示意图
8.2.2 抓取脚本
线上的线程栈情况瞬息万变,很容器错过抓取线程的最佳时机,因此使用脚本抓取相关线程信息并输出到相应的文档是一种解决方案。
抓取shell脚本内容如下:
#!/bin/bash
date=` date +%y%m%d-%H%M`
pid=`top -bn1 |grep java | awk '{print $1 "\t" $9}' |head -1 | cut -f 1`
pidCPU=`top -bn1 |grep java | awk '{print $1 "\t" $9}' |head -1 | cut -f 2`
# java home
# est -z $JAVA_HOME 是一个判断表达式,用于判断$JAVA_HOME的值是否为空字符串
if test -z $JAVA_HOME
then
JAVA_HOME='/usr/zhangzhongqiu/java/jdk1.8.0_291/'
fi
# checking pid
# jps -l可以列出本机所有java进程的pid,cut -d只切割pid这一列。
if test -z "$($JAVA_HOME/bin/jps -l | cut -d '' -f 1 | grep $pid)"
then
# 查找我们要找的进程是否存在
echo "process of $pid is not exists"
exit
fi
# line number
# 判断linenum是否为空字符串,来定义打印多少行
if test -z $linenum
then
linenum=10
fi
# 查异常代码文件
stackfile=stack$pid.dump
# 线程id
threadsfile=threads$pid.dump
# generate java stack
# 用jstack把异常代码输入到参数文件$pidpid.dump里面去
$JAVA_HOME/bin/jstack -l $pid >> $stackfile
抓取结果如图37:
图37 脚本抓取死锁信息
8.2.3 工具升级——更简单找到死锁线程
使用arthas进行快速诊断。
有时候我们发现应用卡住了, 通常是由于某个线程拿住了某个锁, 并且其他线程都在等待这把锁造成的。 为了排查这类问题, arthas提供了thread -b, 一键找出那个罪魁祸首。
如图38,可以看到使用arthas很快诊断出死锁线程。
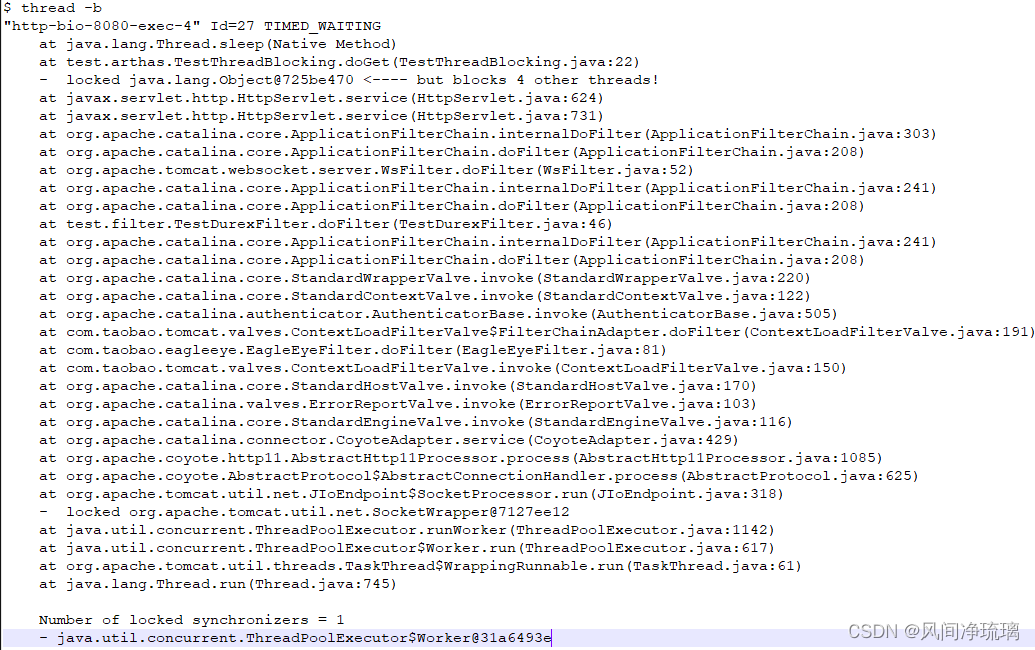
图38 arthas诊断死锁
9 参考文献
引用计算算法 可达性算法、Java引用 详解 JVM 之(4)垃圾回收算法(标记 -清除、复制、标记-整理、分代收集) java对class进行反汇编并使用汇编指令进行对应解析 JVM 内存模型概述 深入理解JVM-内存模型(jmm)和GC Java虚拟机垃圾回收(三) 7种垃圾收集器 JVM——堆外内存详解 jvm中的PermSize、MaxPermSize 常用JVM分析工具 ZGC详解 java启动参数共分为三类 Java程序内存分析:使用mat工具分析内存占用 Arthas官方使用文档












































 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









