







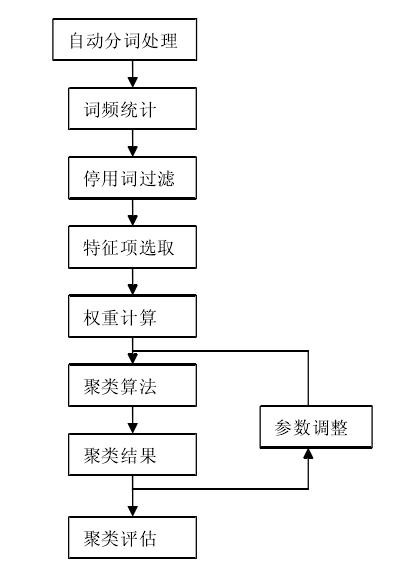
1、文本聚类的处理流程
2、将文档分词、词性标注、实体标注,去除停用词等将一片文章形成由多个词组成的向量。最后根据文档的集合,形成一个词的向量空间。行代表一片文章,列代表词。如下图:
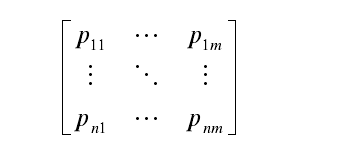
n代表n篇文章,m代表有m个单词组成向量空间
3、由于向量空间的词太多,需要降维
4、根据降维后的特征,计算每一篇文档中每一个词的权重,采用TF-IDF方式
5、有了这个数据矩阵之后,我们需要计算二二文档之间的相异度。
在算相异度之前,我们需要对降维后的矩阵进行规范化。
规范化的方法如下:
(1)最小最大规范化
(2)z分数规范化
(3)小数定标
如何计算文档之间的相异度呢?
主要是使用距离或者相关系数判断二篇文档的相似性
距离的定义:

距离的常用方法:


相关系数的定义与常用的方法:

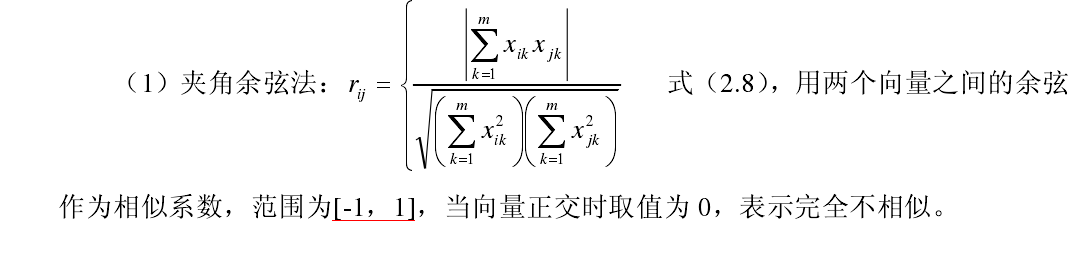

6、经过将二二对象进行计算,得到相异矩阵如下:

7、使用K-means算法将相异矩阵出入到该算法中,就可以得出不同的聚类
k-means算法如下:

8、将聚类的结果进行主题的抽取
9、评估聚类算法















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









