











AGNES算法(自底向上层次聚类)
(1)
(2)
(3)
(4)
(5)
(1)
(2)
(3)
(1)
(2)
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
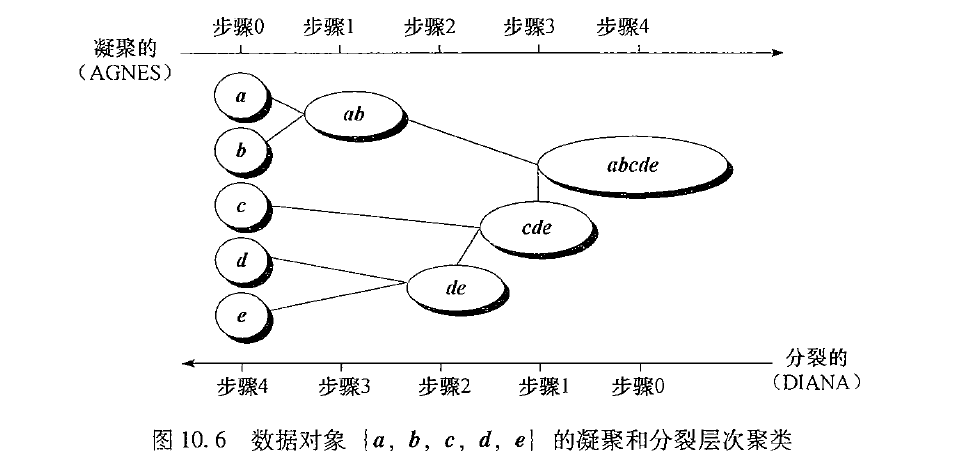
层次聚类算法的分析:
层次聚类法的优点是可以通过设置不同的相关参数值,得到不同粒度上的多层次聚类结构;在聚类形状方面,层次聚类适用于任意形状的聚类,并且对样本的输入顺序是不敏感的。
层次聚类的不足之处是算法的时间复杂度大,层次聚类的结果依赖聚类的合并点和分裂点的选择。并且层次聚类过程最明显的特点就是不可逆性,由于对象在合并或分裂之后,下一次聚类会在前一次聚类基础之上继续进行合并或分裂,也就是说,一旦聚类结果形成,想要再重新合并来优化聚类的性能是不可能的了。聚类终止的条件的不精确性是层次聚类的另一个缺点,层次聚类要求指定一个合并或分解的终止条件,比如指定聚类的个数或是两个距离最近的聚类之间最小距离阈值。















 5301
5301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









