使用Docker搭建部署Hadoop分布式集群
在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了。
一:环境准备:
1:首先要有一个Centos7操作系统,可以在虚拟机中安装。
2:在centos7中安装docker,docker的版本为1.8.2
安装步骤如下:
<1>安装制定版本的dockeryum install -y docker-1.8.2-10.el7.centos
<2>安装的时候可能会报错,需要删除这个依赖
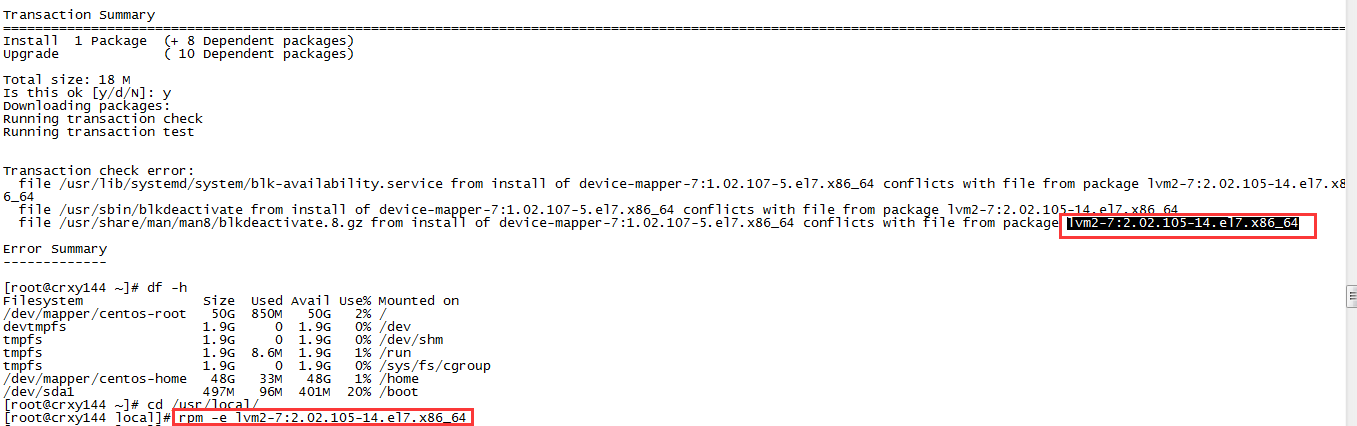
rpm -e lvm2-7:2.02.105-14.el7.x86_64
启动docker
service docker start
验证安装结果:
<3>启动之后执行docker info会看到下面有两行警告信息
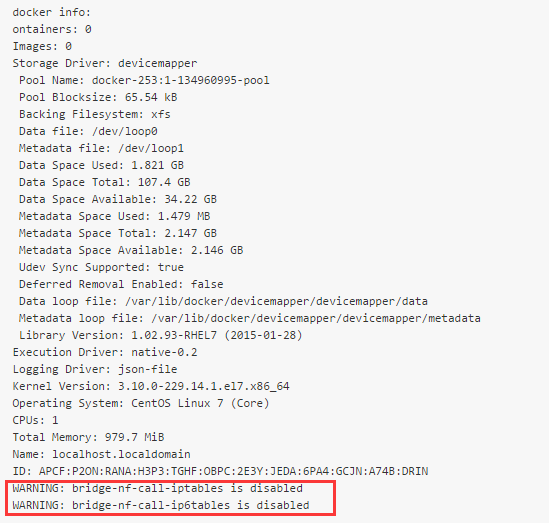
需要关闭防火墙并重启系统
systemctl stop firewalld
systemctl disable firewalld
注意:执行完上面的命令之后需要重启系统
reboot -h(重启系统)
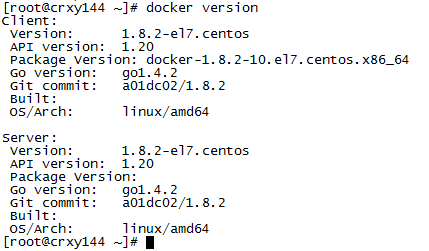
<4>运行容器可能会报错

需要关闭selinux
解决方法:
1:setenforce 0(立刻生效,不需要重启操作系统)
2:修改/etc/selinux/config文件中的SELINUX=disabled ,然后重启系统生效
建议两个步骤都执行,这样可以确保系统重启之后selinux也是关闭状态
3:需要先构建一个hadoop的基础镜像,使用dockerfile文件方式进行构建。
先构建一个具备ssh功能的镜像,方便后期使用。(但是这样对于容器的安全性会有影响)
注意:这个镜像中的root用户的密码是root
Mkdir centos-ssh-root
Cd centos-ssh-root
Vi Dockerfile
# 选择一个已有的os镜像作为基础
FROM centos
# 镜像的作者
MAINTAINER crxy
# 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
#安装openssh-clients
RUN yum install -y openssh-clients
# 添加测试用户root,密码root,并且将此用户添加到sudoers里
RUN echo "root:root" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
# 下面这两句比较特殊,在centos6上必须要有,否则创建出来的容器sshd不能登录
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
构建命令:
docker build -t=”crxy/centos-ssh-root” .
查询刚才构建成功的镜像

4:基于这个镜像再构建一个带有jdk的镜像
注意:jdk使用的是1.7版本的
Mkdir centos-ssh-root-jdk
Cd centos-ssh-root-jdk
Cp ../jdk-7u75-linux-x64.tar.gz .
Vi Dockerfile
FROM crxy/centos-ssh-root
ADD jdk-7u75-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.7.0_75 /usr/local/jdk1.7
ENV JAVA_HOME /usr/local/jdk1.7
ENV PATH $JAVA_HOME/bin:$PATH
构建命令:
docker build -t=”crxy/centos-ssh-root-jdk” .
查询构建成功的镜像

5:基于这个jdk镜像再构建一个带有hadoop的镜像
注意:hadoop使用的是2.4.1版本的。
Mkdir centos-ssh-root-jdk-hadoop
Cd centos-ssh-root-jdk-hadoop
Cp ../hadoop-2.4.1.tar.gz .
Vi Dockerfile
FROM crxy/centos-ssh-root-jdk
ADD hadoop-2.4.1.tar.gz /usr/local
RUN mv /usr/local/hadoop-2.4.1 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
构建命令:
docker build -t=”crxy/centos-ssh-root-jdk-hadoop” .
查询构建成功的镜像

二:搭建hadoop分布式集群
1:集群规划
准备搭建一个具有三个节点的集群,一主两从
主节点:hadoop0 ip:192.168.2.10
从节点1:hadoop1 ip:192.168.2.11
从节点2:hadoop2 ip:192.168.2.12
但是由于docker容器重新启动之后ip会发生变化,所以需要我们给docker设置固定ip。使用pipework给docker容器设置固定ip
2:启动三个容器,分别作为hadoop0 hadoop1 hadoop2
在宿主机上执行下面命令,给容器设置主机名和容器的名称,并且在hadoop0中对外开放端口50070 和8088
docker run --name hadoop0 --hostname hadoop0 -d -P -p 50070:50070 -p 8088:8088 crxy/centos-ssh-root-jdk-hadoop
docker run --name hadoop1 --hostname hadoop1 -d -P crxy/centos-ssh-root-jdk-hadoop
docker run --name hadoop2 --hostname hadoop2 -d -P crxy/centos-ssh-root-jdk-hadoop
使用docker ps 查看刚才启动的是三个容器

3:给这三台容器设置固定IP
1:下载pipework
下载地址:https://github.com/jpetazzo/pipework.git
2:把下载的zip包上传到宿主机服务器上,解压,改名字
unzip pipework-master.zip
mv pipework-master pipework
cp -rp pipework/pipework /usr/local/bin/
3:安装bridge-utils
yum -y install bridge-utils
4:创建网络
brctl addbr br0
ip link set dev br0 up
ip addr add 192.168.2.1/24 dev br0
5:给容器设置固定ip
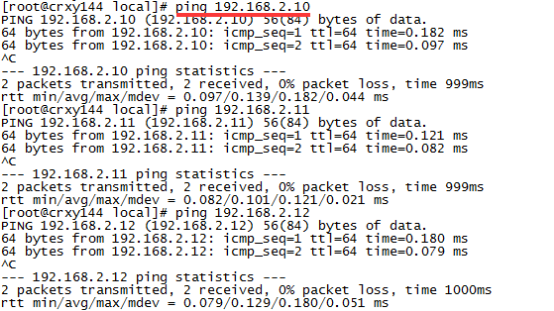
pipework br0 hadoop0 192.168.2.10/24
pipework br0 hadoop1 192.168.2.11/24
pipework br0 hadoop2 192.168.2.12/24
验证一下,分别ping三个ip,能ping通就说明没问题
4:配置hadoop集群
先连接到hadoop0上,
使用命令
docker exec -it hadoop0 /bin/bash
下面的步骤就是hadoop集群的配置过程
1:设置主机名与ip的映射,修改三台容器:vi /etc/hosts
添加下面配置
192.168.2.10 hadoop0
192.168.2.11 hadoop1
192.168.2.12 hadoop2
2:设置ssh免密码登录
在hadoop0上执行下面操作
cd ~
mkdir .ssh
cd .ssh
ssh-keygen -t rsa(一直按回车即可)
ssh-copy-id -i localhost
ssh-copy-id -i hadoop0
ssh-copy-id -i hadoop1
ssh-copy-id -i hadoop2
在hadoop1上执行下面操作
cd ~
cd .ssh
ssh-keygen -t rsa(一直按回车即可)
ssh-copy-id -i localhost
ssh-copy-id -i hadoop1
在hadoop2上执行下面操作
cd ~
cd .ssh
ssh-keygen -t rsa(一直按回车即可)
ssh-copy-id -i localhost
ssh-copy-id -i hadoop2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3:在hadoop0上修改hadoop的配置文件
进入到/usr/local/hadoop/etc/hadoop目录
修改目录下的配置文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
(1)hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7
(2)core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
(3)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
(5)修改文件名:mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6)格式化
进入到/usr/local/hadoop目录下
1、执行格式化命令
bin/hdfs namenode -format
注意:在执行的时候会报错,是因为缺少which命令,安装即可
执行下面命令安装
yum install -y which
看到下面命令说明格式化成功。

格式化操作不能重复执行。如果一定要重复格式化,带参数-force即可。
(7)启动伪分布hadoop
命令:sbin/start-all.sh
第一次启动的过程中需要输入yes确认一下。

使用jps,检查进程是否正常启动?能看到下面几个进程表示伪分布启动成功
[root@hadoop0 hadoop]
3267 SecondaryNameNode
3003 NameNode
3664 Jps
3397 ResourceManager
3090 DataNode
3487 NodeManager
(8)停止伪分布hadoop
命令:sbin/stop-all.sh
(9)指定nodemanager的地址,修改文件yarn-site.xml
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
(10)修改hadoop0中hadoop的一个配置文件etc/hadoop/slaves
删除原来的所有内容,修改为如下
hadoop1
hadoop2
(11)在hadoop0中执行命令
scp -rq /usr/local/hadoop hadoop1:/usr/local
scp -rq /usr/local/hadoop hadoop2:/usr/local
(12)启动hadoop分布式集群服务
执行sbin/start-all.sh
注意:在执行的时候会报错,是因为两个从节点缺少which命令,安装即可
分别在两个从节点执行下面命令安装
yum install -y which
再启动集群(如果集群已启动,需要先停止)
sbin/start-all.sh
(13)验证集群是否正常
首先查看进程:
Hadoop0上需要有这几个进程
[root@hadoop0 hadoop]
4643 Jps
4073 NameNode
4216 SecondaryNameNode
4381 ResourceManager
Hadoop1上需要有这几个进程
[root@hadoop1 hadoop]
715 NodeManager
849 Jps
645 DataNode
Hadoop2上需要有这几个进程
[root@hadoop2 hadoop]
456 NodeManager
589 Jps
388 DataNode
使用程序验证集群服务
创建一个本地文件
vi a.txt
hello you
hello me
上传a.txt到hdfs上
hdfs dfs -put a.txt /
执行wordcount程序
cd /usr/local/hadoop/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /a.txt /out
查看程序执行结果

这样就说明集群正常了。
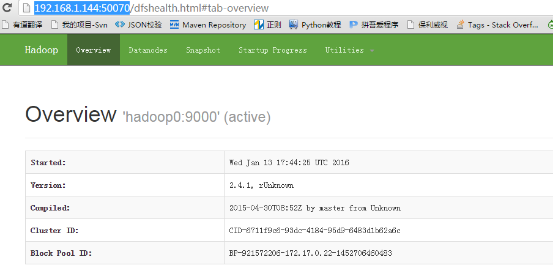
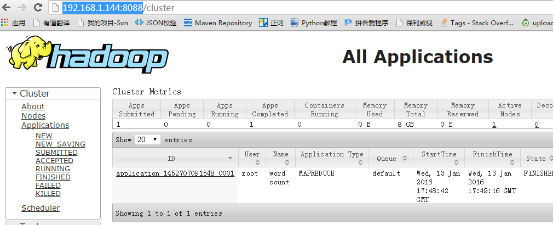
通过浏览器访问集群的服务
由于在启动hadoop0这个容器的时候把50070和8088映射到宿主机的对应端口上了
adb9eba7142b crxy/centos-ssh-root-jdk-hadoop "/usr/sbin/sshd -D" About an hour ago Up About an hour 0.0.0.0:8088->8088/tcp, 0.0.0.0:50070->50070/tcp, 0.0.0.0:32770->22/tcp hadoop0
所以在这可以直接通过宿主机访问容器中hadoop集群的服务
宿主机的ip为:192.168.1.144
http:
http:
三:集群节点重启
停止三个容器,在宿主机上执行下面命令
docker stop hadoop0
docker stop hadoop1
docker stop hadoop2
容器停止之后,之前设置的固定ip也会消失,重新再使用这几个容器的时候还需要重新设置固定ip
先把之前停止的三个容器起来
docker start hadoop0
docker start hadoop1
docker start hadoop2
在宿主机上执行下面命令重新给容器设置固定ip
pipework br0 hadoop0 192.168.2.10/24
pipework br0 hadoop1 192.168.2.11/24
pipework br0 hadoop2 192.168.2.12/24
还需要重新在容器中配置主机名和ip的映射关系,每次都手工写比较麻烦
写一个脚本,runhosts.sh
#!/bin/bash
echo 192.168.2.10 hadoop0 >> /etc/hosts
echo 192.168.2.11 hadoop1 >> /etc/hosts
echo 192.168.2.12 hadoop2 >> /etc/hosts
添加执行权限,chmod +x runhosts.sh
把这个脚本拷贝到所有节点,并且分别执行这个脚本
scp runhosts.sh hadoop1:~
scp runhosts.sh hadoop2:~
执行脚本的命令 ./runhosts.sh
查看/etc/hosts文件中是否添加成功
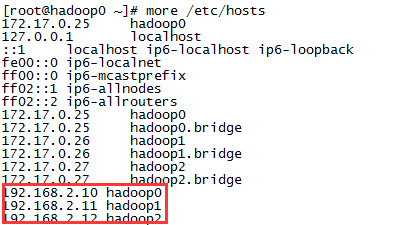
注意:有一些docker版本中不会在hosts文件中自动生成下面这些映射,所以我们才在这里手工给容器设置固定ip,并设置主机名和ip的映射关系。
172.17.0.25 hadoop0
172.17.0.25 hadoop0.bridge
172.17.0.26 hadoop1
172.17.0.26 hadoop1.bridge
172.17.0.27 hadoop2
172.17.0.27 hadoop2.bridge
启动hadoop集群
sbin/start-all.sh























 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









