







Last week is my first week in this term, and I had to prepare for coming GRE. So I did not have enough time to do my project. However, I still made some progress in this period of time.
Firstly, I went on to train more robust pedestrian classifiers both on HAAR and HOG. To haar classifier, I increase the number of positive samples to 1600 which is 2 times as before. And it got better hit rate in experiment but cannot still meet my requirement. In addition, because drivers mostly see side-off pedestrians and I cannot find available side-off pedestrians database to train my hog classifiers, I took nearly 1000 pictures of side-off pedestrians by myself in different places. And then my hog classifier really reach a high hit rate of side-off pedestrians but also with many false positives. The results can be compared below:
| hog+svm | haar+adaboost |
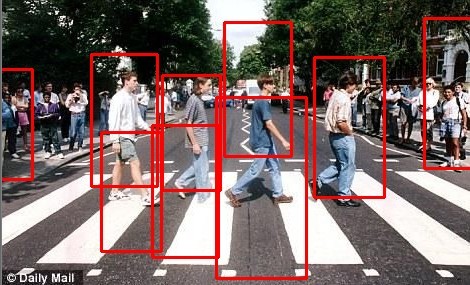 | 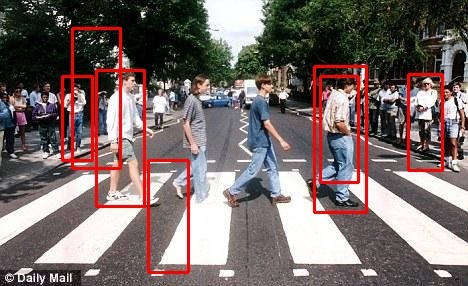 |
 |  |
 |  |
 |  |
 |  |
 |  |
 |  |
Secondly, I think we should not only see the video as a sequence of frames due to the waste of motion information. So I'm always thinking about how to use this useful and ample information. I read some papers about background modeling, optical flow and so on. Because the background in my project is moving and background modeling algorithm is too sensitive to many factors, I do not accept this method. Inspired by optical flow, I proposed my own method only in concept now. In my daily observation, I fine the background is divergent to the edge of an image which is like you throw a stone to water and generate waves around(投石入水,泛起涟漪):
According to this phenomenon, I think each pixel in an image have its own velocity toward divergent direction which have certain relationship with video recorder speed. And I demonstrate this theory below:
(The process is written in white papers not in computer due to the lack of time,please to forgive, I have to take classes recently.)



In the next week, I will take as much time as I can to improve this theory and make this theory into practice. Do you seen some error in my theory, welcome to point to my mistakes. Thanks a lot.















 50万+
50万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









