







一、Lucene的下载
下载链接:http://lucene.apache.org/
下载后,解压缩,如下图所示(我下载的版本是5.3.1):
开发包说明:
- core:核心jar包
- analysis:语言分析器,主要用于分词
- docs:索引文档的管理
- queryparser:查询分析器
- ……
一般情况下,需要导入:
- lucene-core-5.2.1.jar
- lucene-analyzers-common-5.2.1.jar
- lucene-queryparser-5.2.1.jar
二、Lucene实例
- Lucene创建索引的过程:通过指定的数据格式,将Lucene的Document传递给分词器Analyzer进行分词,经过分词器分词后,通过索引写入工具IndexWriter将索引写入指定的目录。
- 基于索引的查询过程:首先构建查询的Query,通过Indexsearcher进行查询,得到命中的TopDocs。TopDocs包含了命中的文档数和文档信息,通过TopDocs的scoreDoc()方法,得到对应的ScoreDoc列表,每个ScoreDoc包含一个文档编号,Indexsearcher通过文档编号就可以读取文档。
实例代码:
package com.ghs.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class LuceneTest {
private static Directory directory;
public static void main(String[] args) {
buildIndex();
termQuery();
}
/**
* 创建索引
*/
public static void buildIndex(){
try {
directory = FSDirectory.open(Paths.get("./index"));
Analyzer analyzer = new StandardAnalyzer();
Document document = new Document();
document.add(new TextField("name", "zhangsan", Store.YES));
document.add(new TextField("age","18",Store.YES));
document.add(new TextField("intorduce","My name is zhangsan,I love dog and cat!",Store.YES));
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory, config);
writer.addDocument(document);
writer.close();
} catch (Exception e1) {
e1.printStackTrace();
}
}
/**
* 检索
*/
private static void termQuery(){
Query query = new TermQuery(new Term("name", "zhangsan"));
IndexReader reader;
try {
reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs topDocs =searcher.search(query, 1000);
for(ScoreDoc scoreDoc:topDocs.scoreDocs){
int docNum = scoreDoc.doc;
Document doc = searcher.doc(docNum);
System.out.println(doc);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}运行结果:
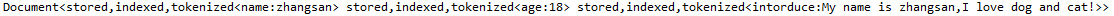
注:Lucene的不同版本有较大的区别,例如,低版本里面的一些构造方法在高版本里面就无法使用。















 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









