








公众号 系统之神与我同在
知识图谱构建核心问题有如下三条:
1.命名实体识别(小样本、跨语言、开放域)
2.关系的自动识别(上下位关系、开放域横向关系)
3.实体缺失属性的自动补全

1.命名实体识别(小样本、跨语言、开放域) :

传统的命名实体识别主要是识别人名、地名、机构名等,逐渐提高命名实体识别的粒度,在经过多年的发展之后, 由于深度学习模型的应用,明明体识别已经可以自动生成实体类型标签。明明体识别经历了由最初的“词典+启发式规则”到“半监督+Bootstrapping”到“监督学习+统计模型”再到深度学习模型的发展阶段。

命名实体识别的常用方法:LSTM+CNN+CRF


跨语言命名实体识别:
由于不同语言之间包含互补的实体线索,因此可以借助英文丰富资源帮助中文实体识别。例如:
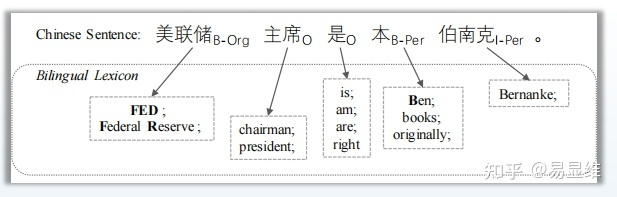
中文“本”很少作为实体,但是其英文翻译“Ben”经常作为实体。
我们可以利用双语词典作为桥梁丰富源语言语义表示,构建一个词典映射函数来学习未登录词的跨语言语义表示。

引入跨语言命名实体识别可以显著提高模型效果。
阅读理解命名实体识别:
在命名实体识别中常常会出现多个命名实体嵌套的情况:


开放域命名实体识别:
开放域命名实体的类别更多,且不限定,例如:
药品名:阿司匹林、双黄连口服液;
会议名:20国集团伦敦峰会、中央经济工作会议;
电影名:《泰囧》、《苹果》;
其类别更细,且有层次:
球队名:达拉斯小牛队、国际米兰;
企业名:微软、中石油;
高校名:哈尔滨工业大学、麻省理工学院;
这些都属于机构名。
基于多信息源的上位词抽取:
模型获取认知实体的信息类似于人类的认知过程:


通过搜索,在线百科等多个来源获取命名实体类型和上位词,无需添加任何标注。
2.关系的自动识别(上下位关系、开放域横向关系):
关系挖掘分为上下位关系挖掘和横向关系挖掘。
上下位关系挖掘:

横向关系挖掘:

基于知识库弱监督的关系抽取:

优点:
自动标注语料,数据量增多
不受领域限制,关系丰富
发现新的关系实例
缺点:知识库回标过程引入大量噪声。因此需要抗噪模型。
基于深层记忆网络的弱监督关系抽取算法:



实体关系异步抽取:
4类主要的实体关系联合抽取方法皆采用异步联合抽取。




在关系抽取过程中,会出现如下的问题:
·遍历了全部实体对建模关系(N*N遍历),造成中间冗余信息。
·关系建模反馈实体建模(“出生地”->人物),实体模型和关系模型间交互有限。
·实体模型或关系模型的错误会向下传递,因此预测时错误会累计。
由于关系扮演重要的角色,不应只作为输出层的预测类别标签,所以我们:1.采用阅读理解框架,将关系作为输入查询实体(头尾实体);2.为关系构造自然语言描述,用以语义建模。
由于重叠元组的关系类别通常是不同的,例如:(美国,总统,奥巴马),(奥巴马,出生于,檀香山市),因此采取:1.关系可以解码大多数重叠元组,以关系为驱动而非实体为驱动可以应对重叠元组问题;2.逐次输入关系描述,模型每次仅关注一种关系类别的实体关系元组抽取。
同步联合抽取模型技术层面涉及两个方面:关系问询策略和同步联合建模。
同步联合建模分为四个子任务:关系类别判定、NER识别、元组头实体识别、元组尾实体识别。

3.实体缺失属性的自动补全:
属性是刻画一个实体的重要知识,是知识图谱中重要的核心知识。在自动构建知识图谱时,实体类别与其属性类型无预先定义,需要自动获取。

例子:借助百度百科补全知识库属性
基于路径表示的属性补全:



条件性知识图谱构建:


条件性知识图谱:
·考虑条件知识
·事实与条件联系建立
·考虑实体属性
·层次化结构灵活
条件性知识图谱构建的任务:从文本中提取事实和/或条件元组。
方法:动态的多输入多输出模型。
















 1521
1521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









