






刘知远老师曾经讲过“NLP搞事情少不了知识指导”。研究深度学习和知识如何更有效的结合成了越来越多人关注的课题了。
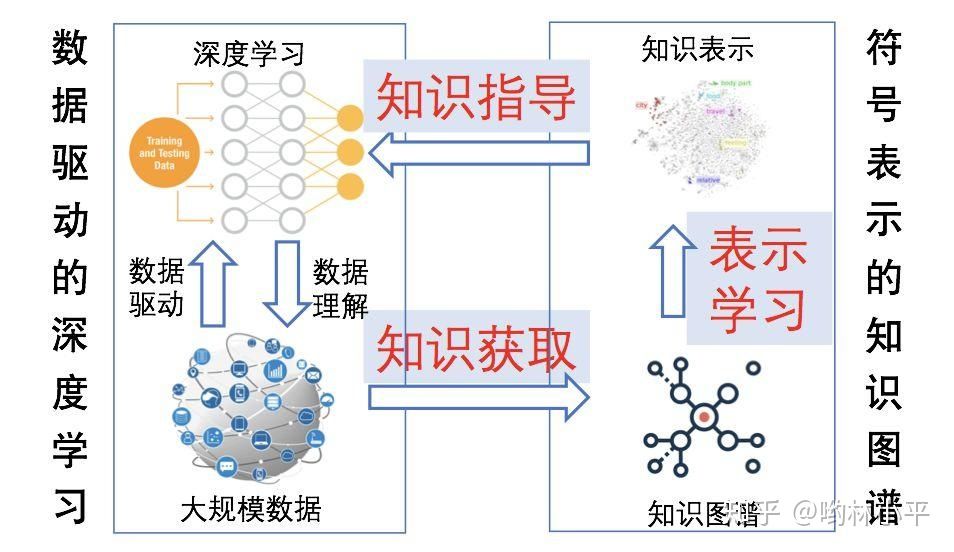
本文尝试从文本生成的角度,对融合知识的idea做了一个简单的汇总,大致有4个较为典型的方式:
- 多任务学习(生成+文本蕴含)
- 基于knowledge graph 的文本生成
- 基于memory network 的文本生成
- 结合分布-采样进行文本生成
需要提醒的是,这篇博客没有涵盖问答、对话和阅读理解等本身就以“知识”和“逻辑”为重的文本生成任务;此外我的学习笔记仅仅是抛砖引玉,很欢迎大家在评论区或私信分享你们关于如何结合知识进行text generation的idea!
1、多任务学习:不仅要说的像,而且要说得对

paper:Ensure the Correctness of the Summary: Incorporate Entailment Knowledge into Abstractive Sentence Summarization. COLING 2018
task:文本摘要
(注:这篇paper的学习笔记主要参考赛尔笔记 | 事实感知的生成式文本摘要)
生成式文本摘要的内容很多时候与原文存在事实性矛盾,于是如何在说的像(现有的seq2seq的loss设计就是为了说的“像”)的同时保有原文的知识(事实),这篇论文采用多任务学习的方式引入文本蕴含。
具体来说,就是以attention Seq2Seq为基础架构,然后将Encoder共享给文本蕴含任务,也就是使用摘要模型中的Encoder与一个softmax层组成蕴含关系分类器,并且在NLI数据集上进行训练,这样做的目的就是使摘要模型的Encoder具有蕴含意识,论文作者在做实验时采取的多任务学习方式是每在摘要数据集上迭代100次,就在文本蕴含数据集上迭代10次;同时呢,在Decoder解码的时候,对损失函数进行修改,以生成摘要的被蕴含程度(Entailment)作为奖励(Reward),采用RAML(奖励增强的极大似然)机制进行训练,使Decoder也具有蕴含意识。模型结构示意图如下:
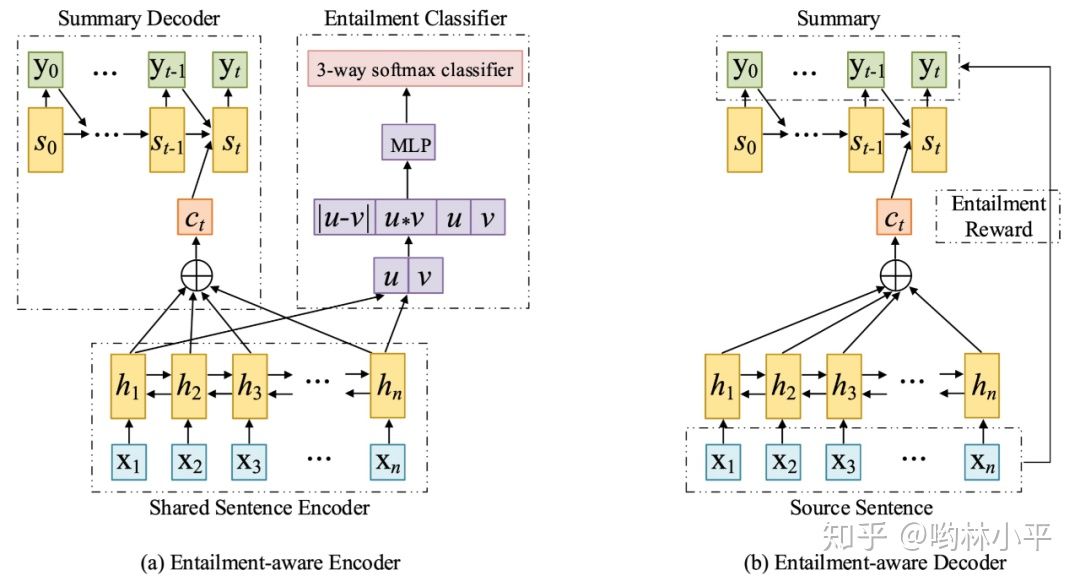
使用多任务学习框架将文本蕴含引入摘要模型结构示意图。Entailment-aware Encoder被同时用于训练文本摘要生成(图(a)左半部分)和文本蕴含识别(图(a)右半部分)。Entailment-aware Decoder采用蕴含奖励增强极大似然(Entailment RAML)的方法进行训练,如果生成的摘要能被原文蕴含,模型将会得到奖励
Entailment-aware Encoder使用BiLSTM(双向长短期记忆网络),在训练文本摘要时,采用seq2seq架构;在训练蕴含识别时,将文本蕴含数据集中的句子对(sentence pair)分别进行编码得到u和v,然后将u和v构成特征向量,传入MLP+softmax中进行蕴含预测。
Entailment-aware Decoder中,使用摘要被原文蕴含的程度作为奖励,并使用奖励增强的极大似然(Reward Augmented Maximum Likelihood, RAML)代替普通的极大似然损失函数(例如:交叉熵)进行训练,鼓励模型生成更能被原文蕴含的摘要。由于RAML解释起来篇幅较长,并且与本文主题关联不大,因此不再赘述,若读者感兴趣,可以阅读原论文Reward Augmented Maximum Likelihood for Neural Structured Prediction以及RAML在文本摘要中的应用。
2、knowledge graph+text generation,图神经网络参与文本生成
随着图神经网络近年受到越来越多人的关注,结合GNN和knowledge graph参与文本生成也有一些进展。
尽管问答对话或者阅读理解近些年已经在越来越关注深度学习如何更有效的利用知识(例如Concept Net)从而提高逻辑和可解释性,但是一些常见的文本生成任务(文本摘要、评论生成等)都没有有效的利用source中潜在蕴含的knowledge graph。所以,我整理了2个knowledge graph to text 的研究方向如下:
2.1 从长文本构建graph,然后辅助生成文本
paper:Text Generation from Knowledge Graphs with Graph Transformers. NAACL 2019
task:graph to text

作者描述的任务是从论文的标题和graph生成该论文的摘要。graph通过另一个专业域的信息抽取工具获得。
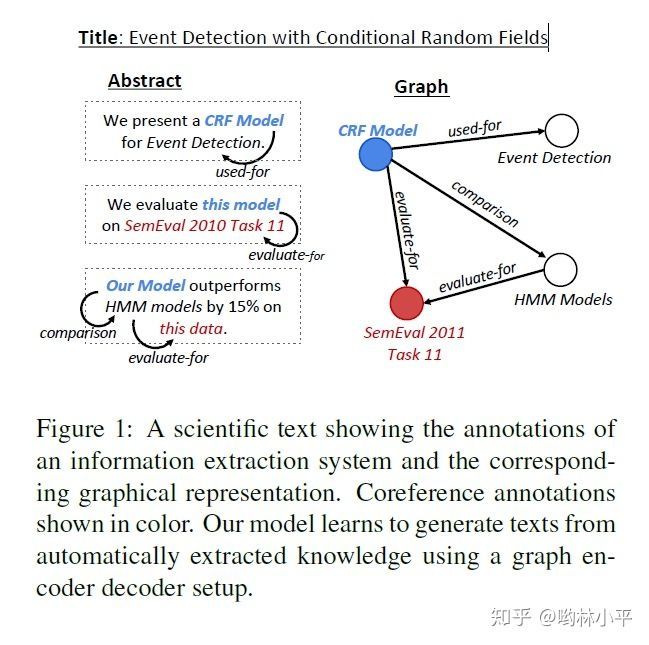
端到端模型中,构建了transformer提取graph的特征,而decoder就是普通的LSTM加attention。这篇论文我早些时候专门写了博客,感兴趣的同学可以戳下面:
哟林小平:文本生成5:Text Generation from Knowledge Graphs56 赞同 · 31 评论文章正在上传…重新上传取消
和这个思路有异曲同工之妙的另一篇paper:
paper:Boosting Factual Correctness of Abstractive Summarization with Knowledge Graph
task:文本摘要(CNN/DailyMail)
也有香侬团队写博客介绍了,这里简单分享一下和上面这篇paper的异同:一样的地方是模型架构都比较相似,都用了transformer提取文本或者knowledge graph的特征,都用IE工具(这篇直接用的openie)构建graph;这篇paper做的更好的地方是他专门分析了摘要是否存在事实性错误:

红色为生成文本的事实性错误,绿色为正确的事实
以及提出了一个事实矫正器来修改明显的知识错误:

并且用一个基于bert的文本蕴含模型(2分类模型)来判断是否存在不符合原文的知识。
详情戳下方链接(对比完你会发现model和上一篇论文的还是比较相似)
香侬科技:香侬读 | 当知识图谱遇上文本摘要:保留抽象式文本摘要的事实性知识39 赞同 · 9 评论文章正在上传…重新上传取消
类似的方向同样在评论生成上也有文章出现:
paper:Coherent Comment Generation for Chinese Articles with a
Graph-to-Sequence Model(ACL 2019)
task :comment generation
这篇paper想要表达的是很多评论无法捕捉到原文的实体(例如“蜘蛛侠好帅”中的蜘蛛侠,往往在原文中不那么起眼,会被seq2seq忽略),于是提出了构建一个graph来辅助。

我最喜欢这篇paper有很重要的一个原因是构建graph的方式非常巧妙(node就用普通的textrank,但是连边的方式让人着迷),之前也整理了博客学习:
哟林小平:文本生成11:利用graph进行文章评论生成37 赞同 · 10 评论文章正在上传…重新上传取消
此外在Story Ending Generation 也有2篇加入构建graph再辅助生成文本的paper:
1、Story Ending Generation with Incremental Encoding and Commonsense
Knowledge,AAAI 2019
2、Incorporating Structured Commonsense Knowledge in Story Completion,AAAI 2019
相同都是结合了concept net 和文本抽取出来的实体进行运算,使得生成的文本更加reasonable。感兴趣的话可以看看论文。
2.2 语义图or三元组的文本生成,graph to text 就是原本的任务
另一种graph to text的任务是,不需要你从原文本抽取和构建graph,生成的句子也不会特别长。其中有一大类叫AMR to text(AMR是一种语义结构),另一大类是triple to text。AMR超出了我的认知范围,不过还是可以看看AMR大概长什么样子:

估计做依存语法分析的朋友会更熟悉一点
如果你对AMR感兴趣,可以搜一下下面几篇paper:
Graph-to-Sequence Learning using Gated Graph Neural Networks
Structural Neural Encoders for AMR-to-text Generation
Graph Transformer for Graph-to-Sequence Learning
Graph-to-Sequence Model for AMR-to-Text Generation
triple to text其实和上面的paper任务比较相近,区别是生成的句子一般比较短,任务也更倾向于KGQA的下游过程:

哟林小平:文本生成6:GTR-LSTM A Triple Encoder for SG from RDF16 赞同 · 12 评论文章正在上传…重新上传取消
3、 以memory network 形式储存ConceptNet知识
paper : Enhancing Topic-to-Essay Generation with External Commonsense Knowledge . ACL 2019
task : topic to essay

memory network也是一种具有更强记忆的神经网络形式,作者提到的痛点是,主题到文章的生成属于信息量严重不足的一种任务形式:

所以借助conceptnet(将topic当做5query,在conceptnet中查询最近邻的一些实体作为“常识”并且补充到模型中去),作者将其存储在memory network中,并且采用了对抗训练的方法。知乎上已经有大佬做了非常详细的总结,感兴趣的同学可以移步至Enhancing Topic-to-Essay Generation ...进一步了解。
值得一提的是,ACL 2019也有一篇文本生成的paper也用到了memory network作为知识融合的手段:
4、 从带有“知识”的分布采样生成文本
paper:Long and Diverse Text Generation with Planning-based Hierarchical Variational Model(EMNLP2019)
task:data to text(淘宝广告文案生成)

这篇paper的主要任务是根据商品的属性生成符合该商品描述的广告文案:
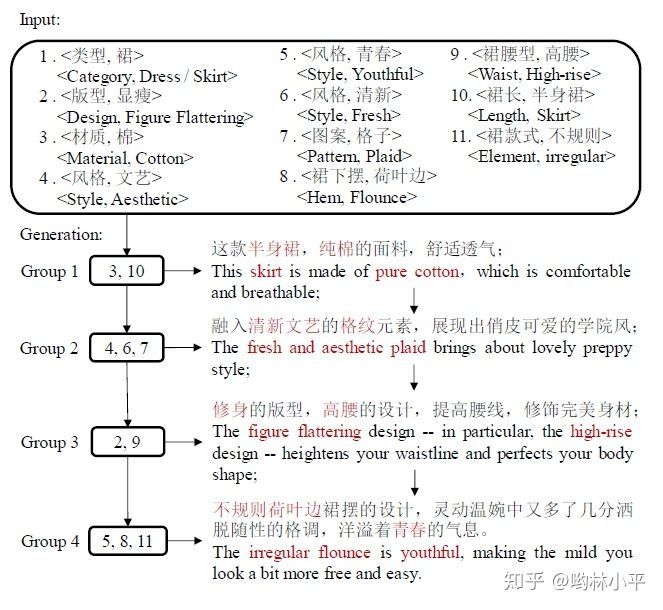
而作者为了能够从大量的训练数据中学习描述商品的表达技巧,从而生成多样化的广告文案,模型采用了vae中的分布采样方法,根据商品属性从生成特定的分布,再从中采样出一个向量作为plan decoder的初始状态:
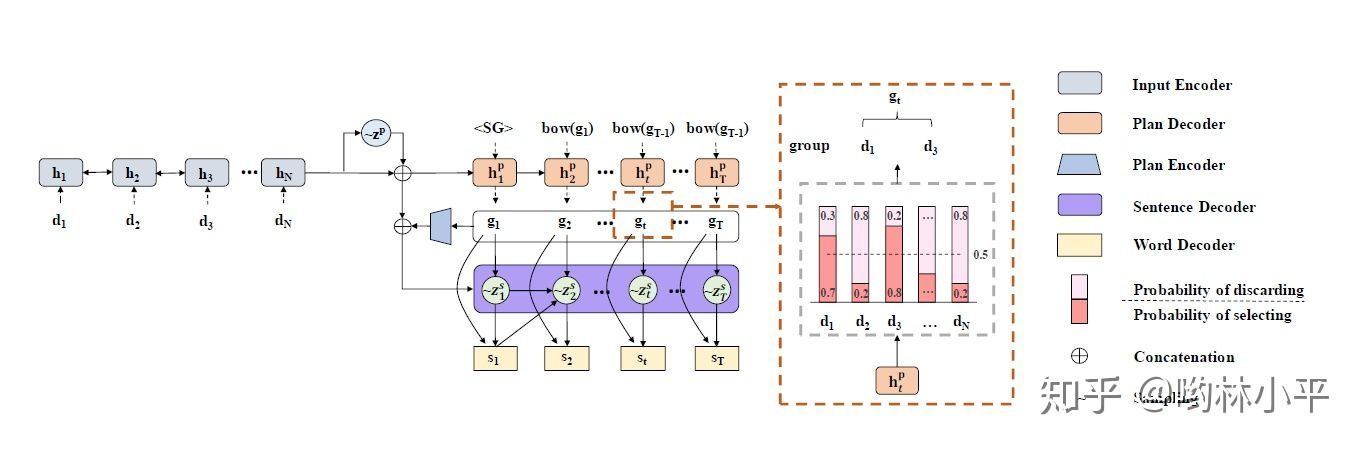
值得一提的是,使用VAE或者GAN进行文本生成也是近年来比较火热的课题,尤其是GAN在图像生成大获成功以后。笔者在研一上几乎花了大部分的时间在研究vae生成文本的工作。摸清了vae的套路之后,我总结了VAE中让文本带有知识的一种常见的思路:
不再从标准正态分布 生成句子 (这一部分的工作是用decoder,数学形式为 ),而是让文本从带有条件的分布(这里的x可以是data,graph ,语法知识,等等)采样,然后进一步生成句子
从数学形式来看,就是这么简单的东西,但是你几乎可以在很多拿vae当主菜的paper中看到这种技巧:
哟林小平:文本生成7:Long and Diverse Text Generation with PHVM60 赞同 · 16 评论文章正在上传…重新上传取消
哟林小平:文本生成4:Syntax-Infused VAE for Text Generation12 赞同 · 0 评论文章正在上传…重新上传取消
哟林小平:文本生成1:Towards Generating Long and Coherent Text27 赞同 · 18 评论文章正在上传…重新上传取消
结语
本文介绍了4种结合知识的text generation的方法,其中多任务学习的技巧在预训练模型中更为常见;结合knowledge graph的方式可以是引入外部知识(例如ConceptNet)或者在原本的任务自行构建graph,并且利用GNN提取特征;memory network有较强的记忆能力,而从分布中采样进行文本生成,除了可以很好地编码知识以外,还能根据任务不同生成多样化的文本。
参考文献
【1】赛尔笔记 | 事实感知的生成式文本摘要 https://mp.weixin.qq.com/s/Aye9FBwG-v2JO2MLoEjo0g
【2】Shao Z, Huang M, Wen J, et al. Long and Diverse Text Generation with Planning-based Hierarchical Variational Model[J]. arXiv preprint arXiv:1908.06605, 2019.
【3】Shen D, Celikyilmaz A, Zhang Y, et al. Towards Generating Long and Coherent Text with Multi-Level Latent Variable Models[J]. arXiv preprint arXiv:1902.00154, 2019.
【4】Zhang X, Yang Y, Yuan S, et al. Syntax-Infused Variational Autoencoder for Text Generation[J]. arXiv preprint arXiv:1906.02181, 2019.
【5】Yang P, Li L, Luo F, et al. Enhancing Topic-to-Essay Generation with External Commonsense Knowledge[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 2002-2012.
【6】Li W, Xu J, He Y, et al. Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model[J]. arXiv preprint arXiv:1906.01231, 2019.
【7】Zhu C, Hinthorn W, Xu R, et al. Boosting Factual Correctness of Abstractive Summarization with Knowledge Graph[J]. arXiv preprint arXiv:2003.08612, 2020.
【8】Li H, Zhu J, Zhang J, et al. Ensure the correctness of the summary: Incorporate entailment knowledge into abstractive sentence summarization[C]//Proceedings of the 27th International Conference on Computational Linguistics. 2018: 1430-1441.















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









