






作者:姚远、叶德铭、刘知远 (欢迎转载,请标明原文链接、出处与作者信息即可)
关系抽取是自然语言处理中的一项重要任务,通过从纯文本中抽取结构化的实体关系事实,可用于自动构建和扩充知识图谱。例如,从句子「北京是中国的首都」中,可以抽取出关系事实(北京, 首都, 中国),其中北京和中国被称为实体,而首都则是他们的关系。关系抽取是知识获取的重要途径,对于深度理解自然语言和实现自动问答具有重要研究价值。
前段时间我们介绍了实体关系抽取的现状与挑战。接下来,我们将分别详细介绍在几个方面上的思考与探索。这篇就来介绍知识获取的新挑战之一:文档级实体关系抽取。
目前大多数关系抽取方法抽取单个实体对在某个句子内反映的关系,在实践中受到不可避免的限制:在真实场景中,大量的关系事实是以多个句子表达的。文档中的多个实体之间,往往存在复杂的相互关系。
以下图为例,就包括了文章中的两个关系事实(这是从文档标注的19个关系事实中采样得到的),其中涉及这些关系事实的命名实体用蓝色着色,其它命名实体用下划线标出。为了识别关系事实(Riddarhuset,country,Sweden),必须首先从句子4中抽取Riddarhuset位于Stockholm的关系事实,然后从句子1确定Stockholm是Sweden的首都,以及Sweden是一个国家,最后从这些事实推断出Riddarhuset的主权国家是瑞典。该过程需要对文档中的多个句子进行阅读和推理,这显然超出了句子级关系抽取方法的能力范围。
根据从维基百科采样的人工标注数据的统计表明,至少40%的实体关系事实只能从多个句子联合获取。因此,有必要将关系抽取从句子级别推进到文档级别。

为了加速对文档级的关系抽取的研究,我们与腾讯微信模式识别中心联合制作发布了DocRED,这是一个大规模的、人工标注的、通用的文档级关系抽取数据集。DocRED包含对超过5000篇Wikipedia文章的标注,包括96种关系类型、143,375个实体和56,354个关系事实。这在规模上超越了以往的同类精标注数据集。与传统的基于单句的关系抽取数据集相比,不同之处在于,DocRED中超过40%的关系事实只能从多个句子中联合抽取,因此需要模型具备较强的获取和综合文章中信息的能力,尤其是抽取跨句关系的能力。
DocRED是以 Wikipedia 作为语料库、以 Wikidata 作为知识图谱构建的。Wikipedia 作为互联网上的自由百科全书,因其巨大的体量和蕴含的丰富知识而备受 NLP 学者青睐。Wikidata是一个和Wikipedia紧密联系的知识图谱,存储了大量结构化知识。目前 Wikidata 中已有超过 5000 万个实体,千余种关系。
上面例子也是从DocRED抽样出来的。可以看到,DocRED基于Wikidata对Wikipedia的文章标注了命名实体和关系事实,包括句内关系和跨句关系。为了支持更多样的应用场景,DocRED还标注了实体之间的指代信息,以及关系事实对应的证据语句,因此也可以支持关系抽取外的很多文档级任务。数据集相关论文《DocRED: A Large-Scale Document-Level Relation Extraction Dataset》发表在ACL 2019上。文章对DocRED数据集的构造原理给出了详细解释,感兴趣的同学可以点击下面的论文地址阅读原文。
DocRED网址:
thunlp/DocREDgithub.com/thunlp/DocRED正在上传…重新上传取消
论文地址:
DocRED: A Large-Scale Document-Level Relation Extraction Datasetarxiv.org/abs/1906.06127
由于DocRED中至少40.7%的关系事实只能从多个句子中提取,模型需要阅读、综合文档中的所有信息来推断实体之间的关系。下表列举了DocRED中包含的文档级关系抽取的推理类型,其他剩余的0.3%为其他推理类型,例如时序推理;文章中头实体用正体表示,尾实体用斜体表示。该数据分析表明,DocRED中包含多种复杂的推理类型,包括逻辑推理、指代推理和常识推理等,因此模型需要具备多种推理能力才能有效进行文档级关系抽取。

除了人工精标注的数据集,DocRED还提供了超过10万篇的基于远程监督数据,以支持弱监督的关系抽取研究。数据分析显示,文档级的关系抽取中,通过远程监督方法产生的数据的噪音比例远高于句子级的远程监督,这表明基于远程监督的文档级关系抽取十分具有挑战性。
为了支持公平透明的定量比较,我们在Codalab开放了DocRED竞赛:
CodaLab - Competitioncompetitions.codalab.org/competitions/20717正在上传…重新上传取消
目前已经吸引超过30支队伍参加,竞赛排行榜中选手们提交的模型效果相比于论文中的基线模型已经有了明显提升,但是和人类表现相比仍然存在较大差距:
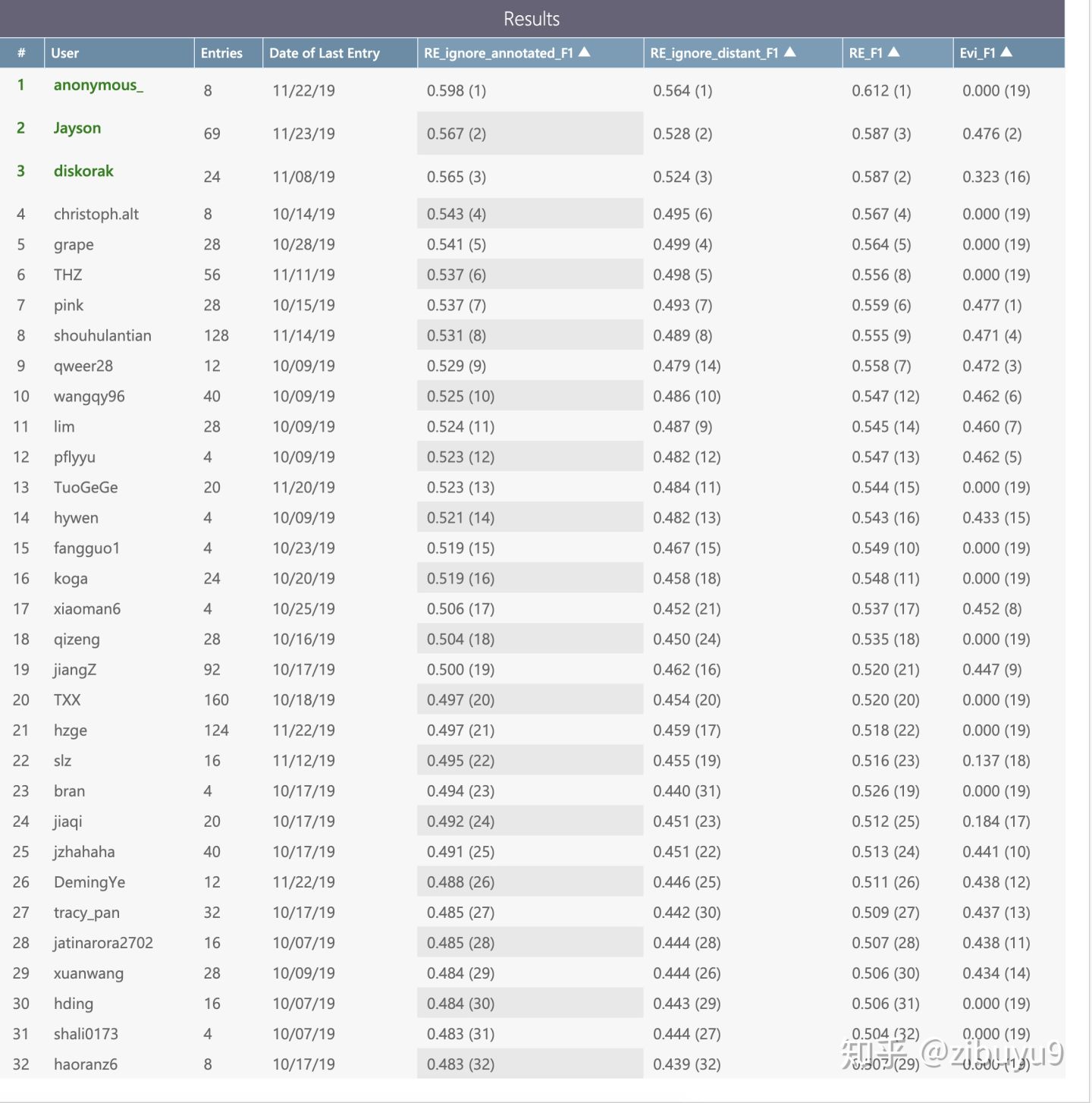
我们期待,通过构建和发布 DocRED 能够推动文档级关系抽取的研究,同时也能够支持更多的文档级自然语言处理研究。
作者简介
姚远 清华大学计算机科学与技术系博士二年级同学,主要研究方向为自然语言处理、知识图谱、关系抽取。在人工智能领域国际著名会议ACL、EMNLP上发表多篇论文。
叶德铭 清华大学计算机科学与技术系博士二年级同学,主要研究方向为自然语言处理、关系抽取、问答系统。在人工智能领域国际著名会议ACL、ECCV上发表多篇论文。
刘知远 清华大学计算机系副教授、博士生导师。主要研究方向为表示学习、知识图谱和社会计算。主页:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









