








概述
该文章阐述了一种用于文档级关系抽取的方法,文章第一作者John Giorgi所在机构为多伦多大学的特伦斯·唐纳利细胞与生物分子研究中心以及向量人工智能研究所,该篇文章发表与2022年ACL(自然语言处理方向的顶级会议)。
摘要
关系抽取中,许多关系会跨越句子边界,受这一事实的影响,文档级关系提取(DocRE)越来越受到关注。DocRE需要在句子内部和句子之间进行整合,捕捉实体提及之间的复杂交互。大多数现有的方法都是基于管道的,需要实体作为输入。然而,由于共享参数和训练步骤,联合学习提取实体和关系可以提高性能和更有效。在本文中,我们开发了一种序列对序列(sequence-to-sequence, seq2rel)方法,它可以端到端地学习DocRE(实体提取、关联解析和关系提取)的子任务,取代了任务特定组件的管道。我们使用一种称为实体暗示的简单策略,将我们的方法与基于流水线的现有方法在几种流行的生物医学数据集上进行比较,在某些情况下超越了它们的性能。我们还报告了这些数据集的第一个端到端结果,以供将来比较。最后,我们证明,在我们的模型下,端到端的方法比基于管道的方法更有效。我们的代码、数据和训练过的模型获取地址:https://github.com/johngiorgi/seq2rel。在线演示demo地址:https://share.streamlit.io/johngiorgi/seq2rel/main/demo.py。
文章方法
线性化
要将seq2seq学习用于RE,必须将要提取的信息线性化为字符串。这种线性化应该具有足够的表达能力,可以为实体和关系提取的复杂性建模,而不会过于冗长。举例说明:
X: Variants in the estrogen receptor alpha (ESR1) gene and its mRNA contribute to risk for schizophrenia.
Y : estrogen receptor alpha ; ESR1 @GENE@
schizophrenia @DISEASE@ @GDA@
输入文本X表达了ESR1和schizophrenia之间的基因-疾病关联关系(GDA)。在对应的目标字符串Y中,每个关系都从其组成实体开始。分号分隔了共指提及(😉,实体以表示其类型的特殊标记(e.g.@GENE@)结束。类似地,关系用一个特殊的标记来表示它们的类型(例如@GDA@)来结束。在关系之前可以包含两个或多个实体,以支持n-ary提取。如果实体充当关系的头部或尾部的特定角色,则可以对它们进行排序。对于每个文档,可以在目标字符串中包含多个关系。输入文本中可以嵌套或不连续。
在图1中,我们提供了该模式如何用于解决各种复杂性的示例,如共同引用实体提及和n-ary关系:

建模
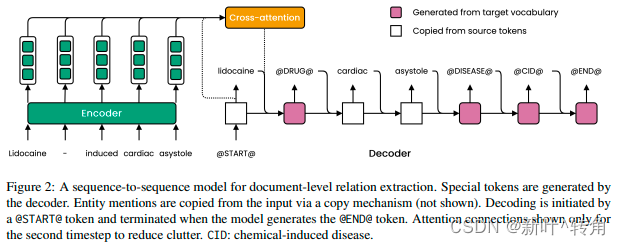
这种RE设置的主要问题是:1)模型可能通过生成源文本中没有出现的实体提及而产生“幻觉”。2)它可能生成一个不符合线性化模式的目标字符串,因此不能被解析。3)损失函数对排列敏感,强加一个不必要的解码顺序。为了解决1),我们使用了两个修改:受限目标词汇表和复制机制。为了解决2),我们对解码过程中应用的几个约束进行了实验。最后,为了解决3),我们根据它们在原文中出现的顺序来分类关系。
实体提示
虽然提出的模型可以从无注释的文本中联合提取实体和关系,但大多数现有的DocRE方法都将实体作为输入。因此,为了更公平地与现有方法进行比较,我们还提供实体作为输入,使用一种称为“实体提示”的简单策略。这涉及到当实体在目标字符串中出现时,将它们添加到源文本的前面。添加实体提示如下:
X: estrogen receptor alpha ; ESR1 @GENE@ schizophrenia @DISEASE@ @SEP@ Variants in the estrogen receptor alpha (ESR1) gene and its mRNA contribute to risk for schizophrenia.
其中特殊的@SEP@令牌划分了实体提示的结束。我们尝试了在每个提到的实体之前和之后插入标记标记的常见方法,但发现这种方法的性能更差。我们的方法在源文本中添加了较少的额外标记,并为复制机制提供了一个可聚焦的位置,即@SEP@的左侧。
实验设置
建模数据
CDR (Li et al., 2016b):BioCreative V CDR任务语料库对化学品、疾病和化学诱发疾病(CID)之间的关系进行了手动注释。它包含1500篇PubMed文章的标题和摘要,并被分成同等大小的训练集、验证集和测试集。
GDA (Wu et al., 2019):基因-疾病关联语料库包含来自PubMed文章的30192个标题和摘要,这些标题和摘要通过远程监督自动标记为基因、疾病和基因-疾病关联。测试集由1000个这样的示例组成。
DGM (Jia et al., 2019):药物-基因-突变语料库包含4606篇PubMed文章,这些文章通过远程监督自动标记了药物、基因、突变和三元药物-基因-突变关系。该数据集有三种变体:句子、段落和文档长度的文本。
DocRED (Yao et al., 2019):DocRED包含了来自维基百科的5000多个人工注释文档。有6种实体和96种关系类型,其中约40%的关系跨越了sen界限。
后记
本文提供了一种sequence-to-sequence文档级关系抽取的方法,可以处理之前seq2seq方法忽略的复杂性,如共指提及和n-ary关系。该文章有它的可取之处,但仍存在一些不足:
- 如果要与现有的pipeline提取方法比较性能的话,还需要实体提示,即在需要提取关系的文本前面列出文本中的所有相关实体。
- 由于预先训练过的编码器的输入大小限制(512令牌),我们的实验是在段落长度的文本上进行的,不能用于完整的科学论文的关系抽取。
- 编码器需要预训练,而解码器是从头开始训练。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









