






请点击上方“AI公园”,关注公众号
本文选自Kaggle
作者:Will Koehrsen
编译:ronghuaiyang
Kaggle的信用卡违约风险预测竞赛,非常有参考价值,做风控和大数据挖掘的同学可以参考一下,非常详细,非常适合入门,从数据处理到模型的构建,非常全面,文章比较长,分几次发出来,这是第二部分,主要内容是数据分析。
异常值
做EDA的时候,有个问题需要从数据中找到,就是异常数据。这些数据可能来自于输入了错误的数字,测量仪器的误差等。一个寻找异常值的方法是观察统计信息,使用 describe 方法。 DAYS_BIRTH 中的列都是负数,这是由于记录的是和目前申请日期的差值。我们乘以-1,处以每年的天数,可以看到以年为单位的统计信息。
In [14]:
Out[14]:
年龄看起来很合理,没有异常值。我们再来看看受雇佣的天数。
In [15]:
Out[15]:
这个看起来就不对了,最大的有大约1000年!
In [16]:
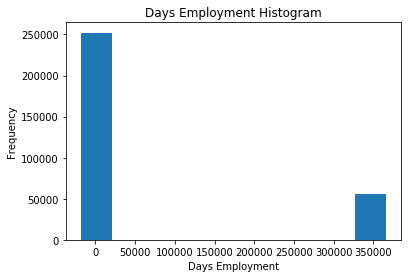
我们再看下,有异常值的人的不还款的比例。
In [17]:
这样看来,异常值比默认值不还款的比例还低。
处理异常值要考虑具体的场景,没有固定的套路。一个比较安全的做法是把异常值设为缺失值,然后进行补全。这样的话,所有的异常值都是同样的值,我们需要将这些值也赋值给相同的值,这样一来所有的这些贷款都有了共同点。这些异常值看起来还是挺重要的,我们需要告诉机器学习模型我们是不是真的补全了这些值。我们可以将这些异常值补全成np.nan,然后创建新的一列表明是否这个值是异常值。
In [18]:
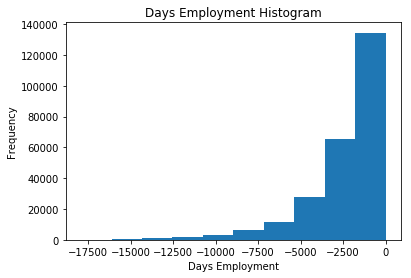
上面这个图中的分布看起来就是我们预期的差不多了,我们还新建了一列告诉模型这些值是否是原来的异常值。另外还有一些带 DAYS 的列,看起来并没有什么异常值。
有一点非常重要,所有的在训练集上的操作,我们必须在测试集上同样的做一遍。
相关性
我们已经把类别变量处理完了,接下来我们观察一下特征和target之间的相关性。我们可以计算每个变量和target之间的皮尔逊系数,使用dataframe中的.corr的方法。
相关系数并不是最佳的表达特征相关性的方法,但是可以告诉我们数据之间的可能的相关性:
.00-.19 “非常弱”
.20-.39 “若”
.40-.59 “中等”
.60-.79 “强”
.80-1.0 “非常强”
In [20]:
我们看几个比较重要的相关性:DAYS_BIRTH是正相关性最高的。这意味着客户的年龄越大,不还款的可能性越大,这是因为DAYS_BIRTH是负的,我们取了绝对值之后,相关性就变负了。
年龄在还款上的重要性
In [21]:
Out[21]:
年龄越大,不还款的可能性越小。我们看一下这个变量,首先,我们做一个年龄的直方图。
In [22]:

从直方图看来,并没有异常值,其他也看不出什么。为了可视化年龄和target之间的关系,我们做一个核密度估计(KDE)。核密度估计简单来说就是一个平滑了的直方图,我们使用seaborn的kdeplot来画这个图。
In [23]:
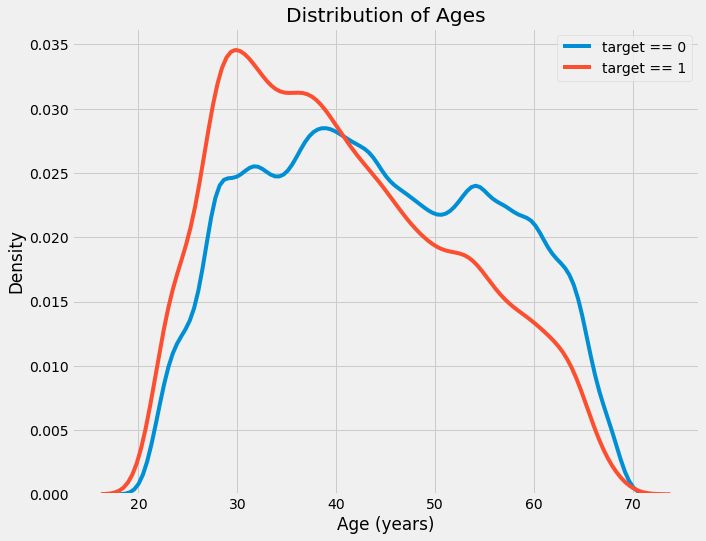
target==1的那条曲线像年轻的一端倾斜,尽管相关系不是非常大(-0.07),这个变量在机器学习中还设有有用的,因为它确实在影响target。我们从另外的角度看一下这个关系:不还款的年龄段的平均值。
我们把年龄按5年一个bin进行割,对于每个bin,我们计算target的平均值,这个告诉我们每个年龄段的不还款的比例。
In [24]:
Out[24]:
| TARGET | DAYS_BIRTH | YEARS_BIRTH | YEARS_BINNED | |
|---|---|---|---|---|
| 0 | 1 | 9461 | 25.920548 | (25.0, 30.0] |
| 1 | 0 | 16765 | 45.931507 | (45.0, 50.0] |
| 2 | 0 | 19046 | 52.180822 | (50.0, 55.0] |
| 3 | 0 | 19005 | 52.068493 | (50.0, 55.0] |
| 4 | 0 | 19932 | 54.608219 | (50.0, 55.0] |
| 5 | 0 | 16941 | 46.413699 | (45.0, 50.0] |
| 6 | 0 | 13778 | 37.747945 | (35.0, 40.0] |
| 7 | 0 | 18850 | 51.643836 | (50.0, 55.0] |
| 8 | 0 | 20099 | 55.065753 | (55.0, 60.0] |
| 9 | 0 | 14469 | 39.641096 | (35.0, 40.0] |
In [25]:
Out[25]:
| TARGET | DAYS_BIRTH | YEARS_BIRTH | |
|---|---|---|---|
| YEARS_BINNED | |||
| (20.0, 25.0] | 0.123036 | 8532.795625 | 23.377522 |
| (25.0, 30.0] | 0.111436 | 10155.219250 | 27.822518 |
| (30.0, 35.0] | 0.102814 | 11854.848377 | 32.479037 |
| (35.0, 40.0] | 0.089414 | 13707.908253 | 37.555913 |
| (40.0, 45.0] | 0.078491 | 15497.661233 | 42.459346 |
| (45.0, 50.0] | 0.074171 | 17323.900441 | 47.462741 |
| (50.0, 55.0] | 0.066968 | 19196.494791 | 52.593136 |
| (55.0, 60.0] | 0.055314 | 20984.262742 | 57.491131 |
| (60.0, 65.0] | 0.052737 | 22780.547460 | 62.412459 |
| (65.0, 70.0] | 0.037270 | 24292.614340 | 66.555108 |
In [26]:
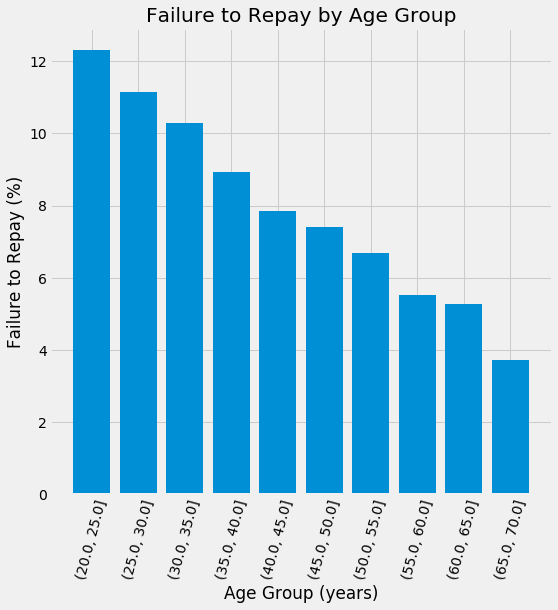
这里有个非常明显的趋势:年轻的申请者更加会不还贷款。最年轻的3个年纪的不还贷款的比例超过了10%,而年纪最大的低于5%。
这个信息银行可以直接使用:年轻的客户不愿意还贷款,可能是他们需要更加有导向性的金融计划。这个不是说银行应该拒绝年轻的客户,而是更加聪明的进行预防,帮助这些年轻的客户按时还款。
外部的数据源
3个和target负相关最强的变量是 EXT_SOURCE_1, EXT_SOURCE_2, 和 EXT_SOURCE_3。根据文档,这些特征表示“从外部数据来的归一化的分数”。我不确定这个表示什么,可能是使用其他数据累积得到的信用分数(估计是类似芝麻分之类的东西)。
我们来看看这些变量。
第一,我们可以看看 EXT_SOURCE 特征和target和自己相互之间的互相关性。
In [27]:
Out[27]:
| TARGET | EXT_SOURCE_1 | EXT_SOURCE_2 | EXT_SOURCE_3 | DAYS_BIRTH | |
|---|---|---|---|---|---|
| TARGET | 1.000000 | -0.155317 | -0.160472 | -0.178919 | -0.078239 |
| EXT_SOURCE_1 | -0.155317 | 1.000000 | 0.213982 | 0.186846 | 0.600610 |
| EXT_SOURCE_2 | -0.160472 | 0.213982 | 1.000000 | 0.109167 | 0.091996 |
| EXT_SOURCE_3 | -0.178919 | 0.186846 | 0.109167 | 1.000000 | 0.205478 |
| DAYS_BIRTH | -0.078239 | 0.600610 | 0.091996 | 0.205478 | 1.000000 |
In [28]:
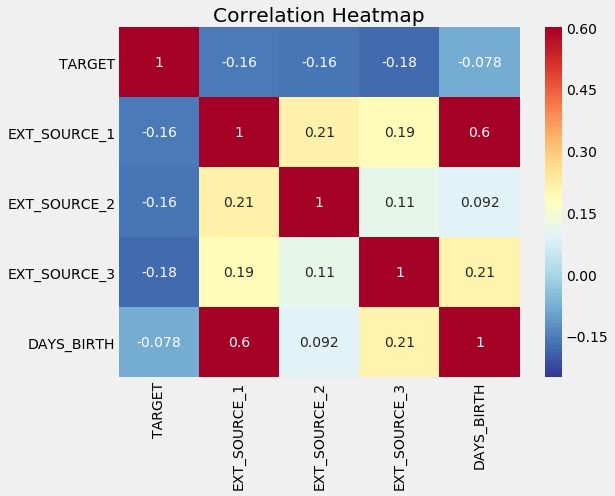
三个 EXT_SOURCE 特征和target都是负相关,这表明当 EXT_SOURCE 的值变大时,客户还款可能性变高。我们还看到DAYS_BIRTH和 EXT_SOURCE_1 是正相关的,这表明 EXT_SOURCE_1 的其中一个影响因素可能是客户的年龄。
现在我们看看用target值来标记颜色表示的这些特征的分布,这可以更好的可视化变量如何作用于target。
In [29]:
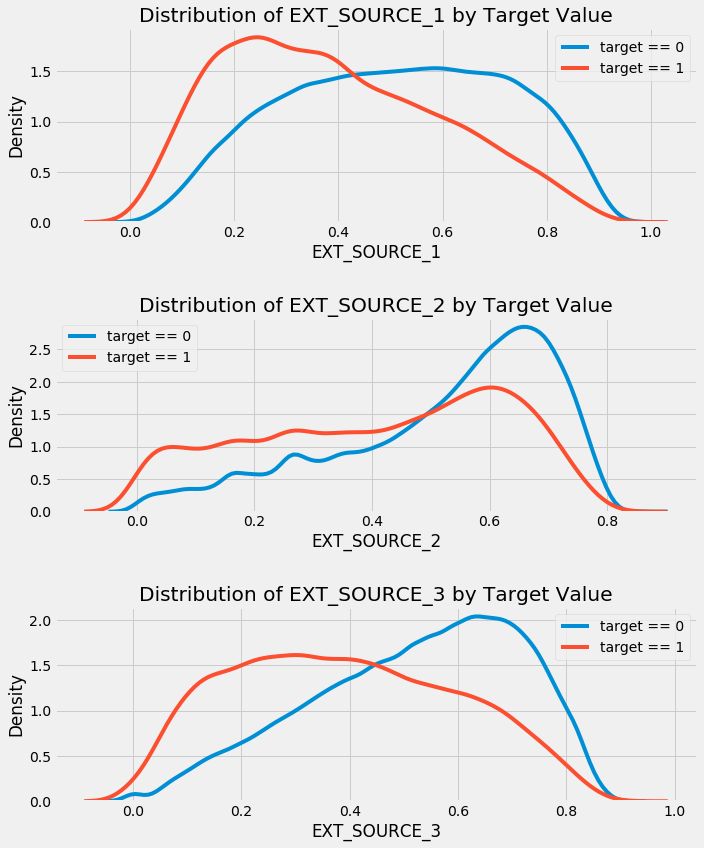
EXT_SOURCE_3 显示出了和target值之间的最大的差别。我们可以清楚的看到,这个特征和申请者还贷款之间有着某种联系。这种联系不是很强,但是仍然非常有用。
成对绘图
成对绘图是一个很好的工具,可以让我们看到多个变量对之间的相互关系以及单个变量的分布情况。这里我们使用seaborn的可视化库和PairGrid函数来创建成对的绘图,在上三角中使用散点绘图,直方图在对角线上,2D的核密度绘图和相关系数在下三角上。
如果你不理解下面的代码,没有关系!使用python绘图是很复杂的,我一般都是找个现成的代码,然后根据需要修改一下。
In [30]:
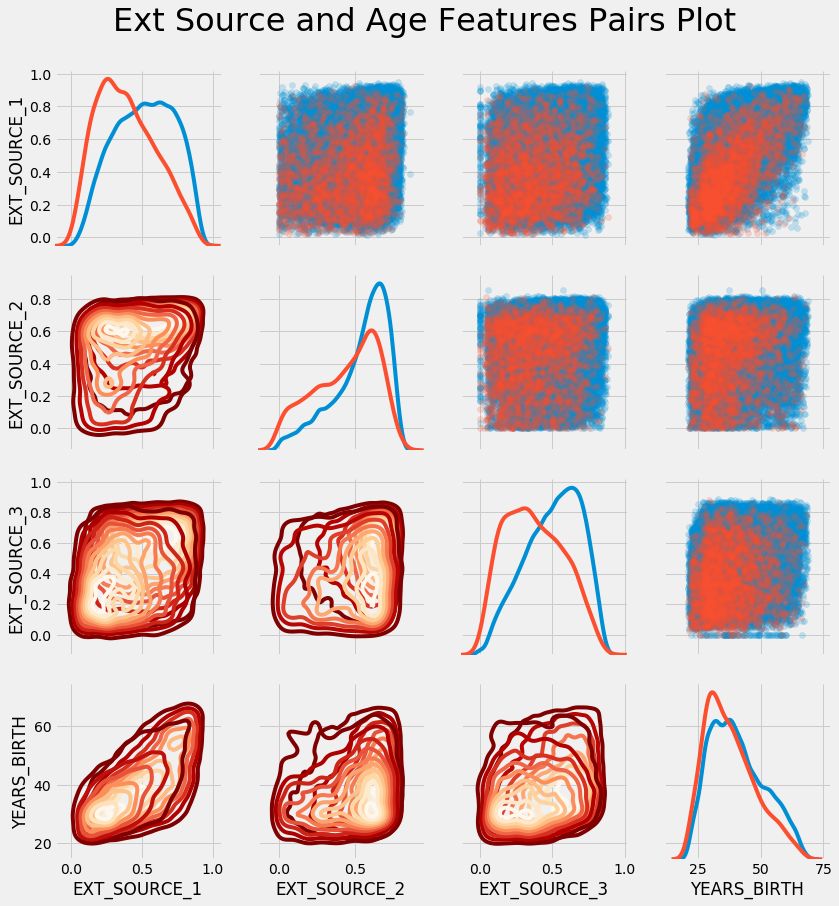
在上面的绘图中,红色表示没有还贷款,蓝色表示还了贷款。我们可以看到数据之间的不同的联系。看起来 EXT_SOURCE_1 和 DAYS_BIRTH 之间有个中等大小的正相关的线性的联系,说明这个特征可能考虑到了客户的年龄。
(未完待续)
本文可以任意转载,转载时请注明作者及原文地址。

请长按或扫描二维码关注我们















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









