






点击上方“AI公园”,关注公众号
作者:Jonathan Hui
编译:ronghuaiyang
在第二部分,我们会有一个综合的对一阶段的物体检测器的概述包括SSD和YOLO(YOLOv2和YOLOv3)。我们也会了解一些FPN,看看多尺度的金字塔特征图是如何提高准确率的,特别是对于小物体,常常在一阶段的检测器中表现的很差。然后我们会看看Focal loss和RetinaNet,了解一下如何在训练中解决类别不均衡的问题。
一阶段检测器
Faster R-CNN有一个专门的建议区域生成网络,后面接一个分类器。
基于区域的检测器很准确,但是并不是没有代价。Faster R-CNN处理速度在PASCAL VOC 2007测试集上是7FPS。像R-FCN,研究者通过减少每个ROI的操作来进行改进。
另外一方面,我们是否需要一个单独的建议区域生成的步骤呢?我们能不能直接从特征图中一步得到边界框和类别呢?
我们重新来看看滑动窗口的检测器。我们可以在特征图上进行窗口滑动来检测目标。对于不同的类型的物体,我们使用不同的形状的窗口。之前的滑动窗口的最大的问题在于我们使用窗口作为我们的最终的边界框。那样的话,我们需要许许多多的不同的形状来覆盖大多数的物体。一个更加有效的方法就是将这些窗口作为一个最初的猜测。然后我们用一个检测器从当前的滑动窗口中同步的来预测类别和边界框。
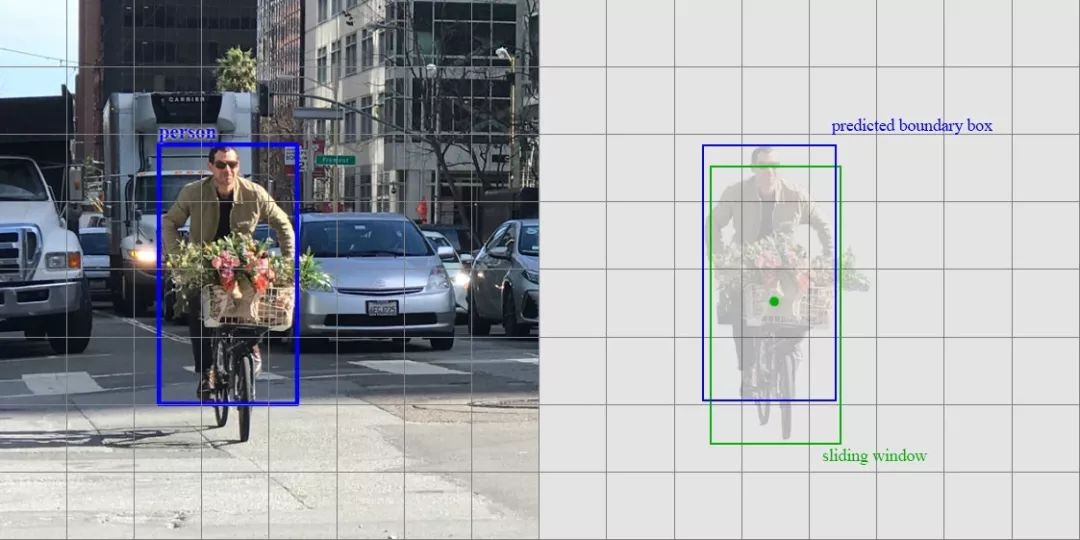
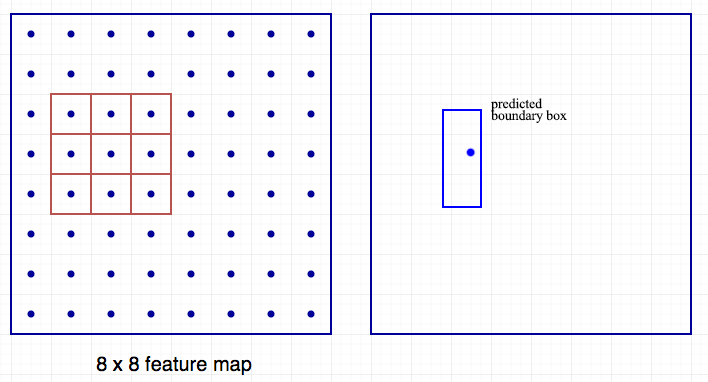
这个概念和Faster R-CNN中的anchor的概念非常的相似。但是,一阶段的物体检测器同时预测了边界框和类别。让我们快速的回顾一下。例如,我们有一个8x8的特征图,我们在每个位置做出了k个预测,也就是8x8xk个预测。

在每一个位置中,我们有k个anchors(anchors只是初始的固定的边界框的猜测),一个anchor对应一个预测。我们仔细的选择了这些anchors,每个位置使用了相同的anchor的形状。
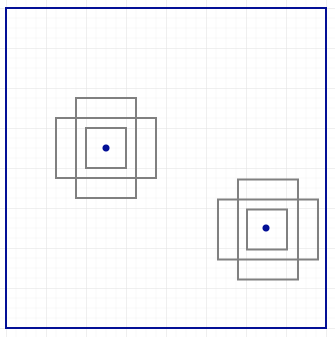
这里有4个anchors(绿色)和4个对应的预测(蓝色),每个关联到一个特定的anchor上。
在Faster R-CNN中,我们使用一个卷积核来进行5个参数的预测:4个参数预测和anchor相关的框的位置,一个是物体存在的置信度得分。所以,3x3xDx5的卷积核将特征图从 8 × 8 × D 转换成 8 × 8 × 5。
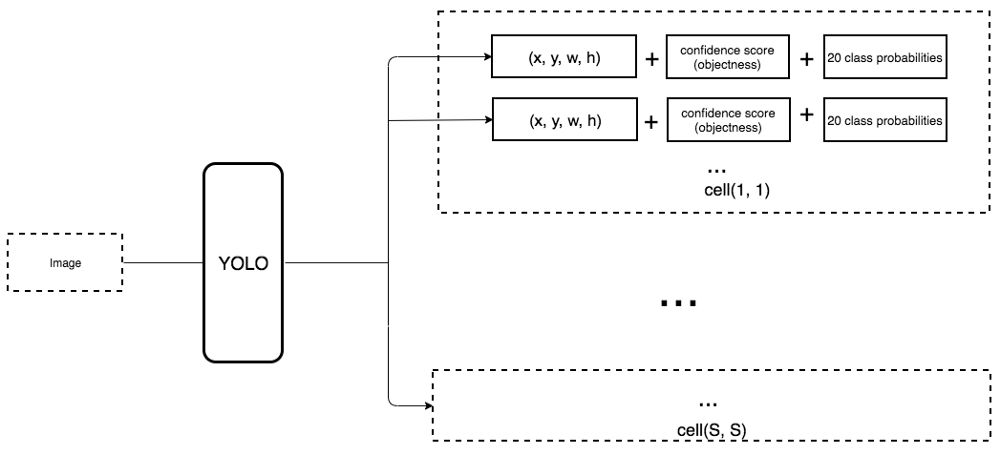
在一阶段的检测器中,卷积核同时预测了C个类别的概率(每个类别一个)。所以我们使用 3× 3× D × 25 的卷积核来将特征图从8 × 8 × D 转换成 8 × 8 × 25 这里C=20。
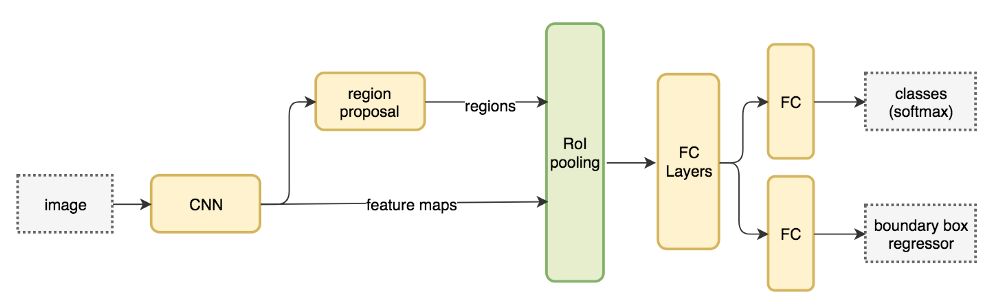
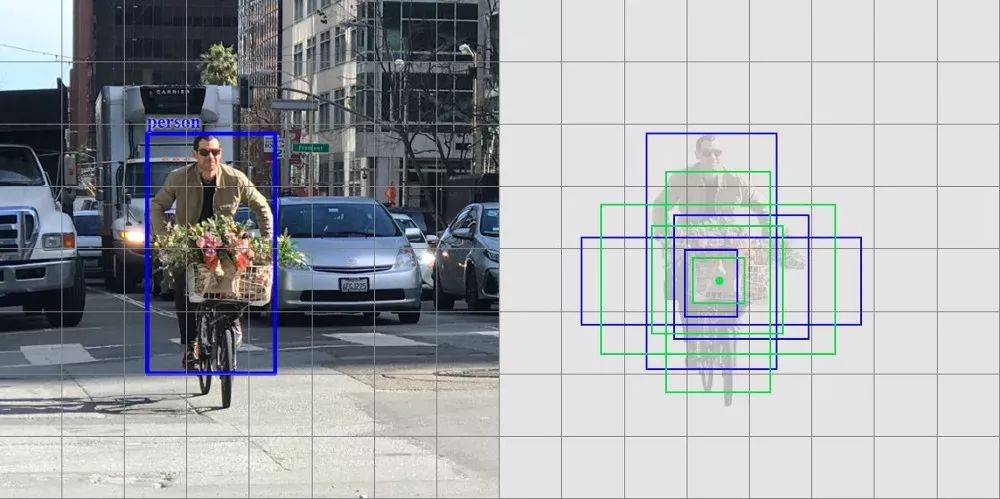
一阶段检测器常常要用准确率来换取实时性,在物体靠的很近或者很小的时候,常常出现问题。对于下面的图,左下方有9个圣诞老人,但是有一个一阶段的检测器只检测了5个。

SSD
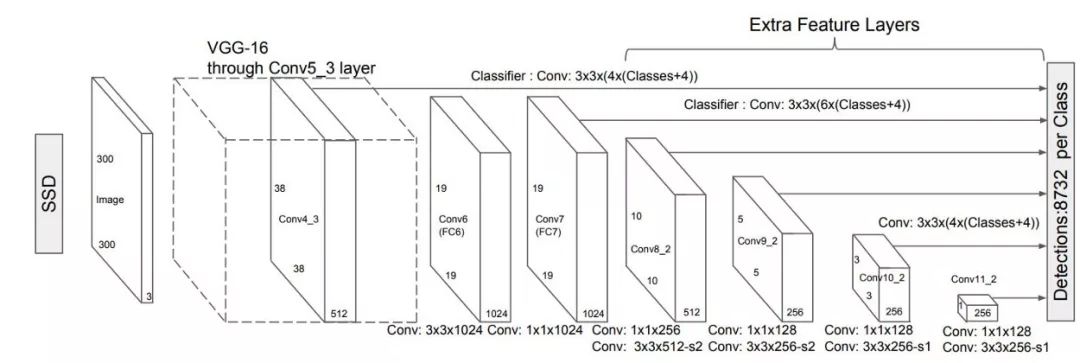
SSD是一个一阶段的检测器,使用了VGG19网络来提取特征。然后我们加上一些通用的卷积层(蓝色),再使用一个卷积核(绿色)来做预测。

但是,卷积层减少了空间维度和分辨率,所以上面的模型只能检测大物体。为了解决这个问题,我们对多个特征图独立的进行物体的检测。
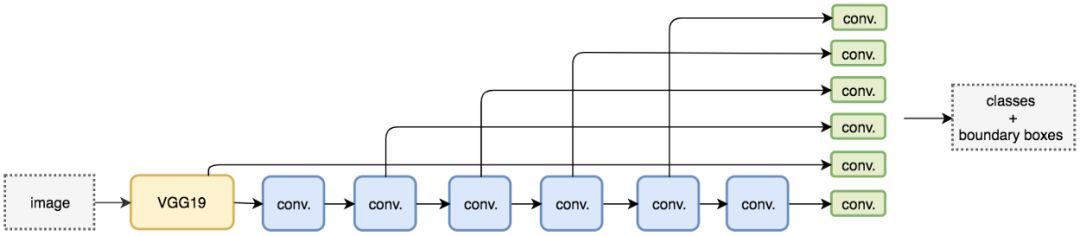
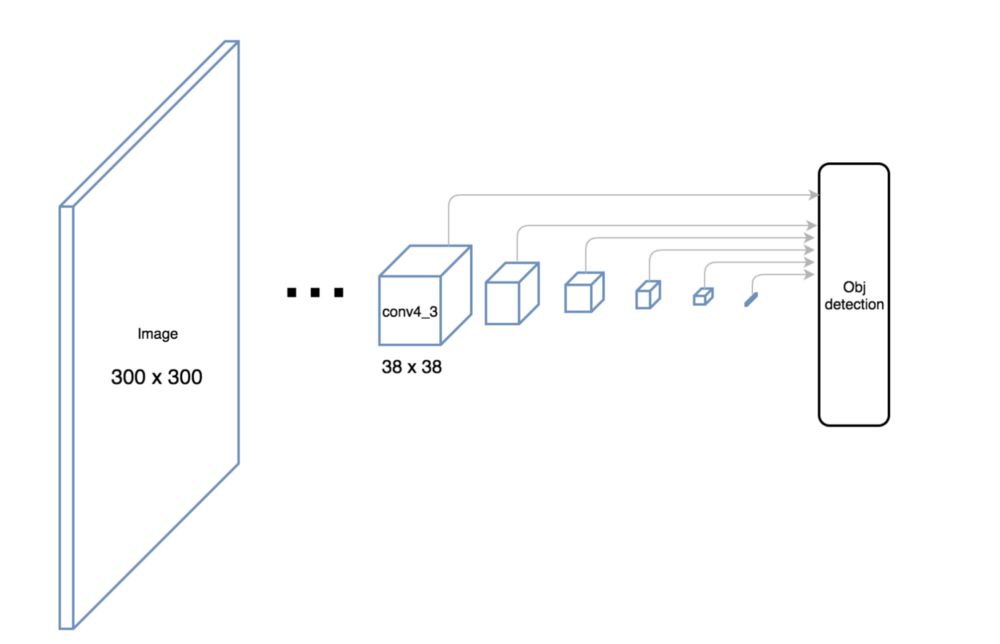
这个图显示了特征图的维度。
SSD使用的是已经是底层的卷积网络来预测物体。如果我们将图画的更加接近真实的尺寸的话,我们会发现空间分辨率降低的很厉害,在很低的分辨率下,检测小的物体是毫无机会的。如果有这样的情况存在,我们需要增加输入图像的尺寸。
YOLO
YOLO是另外一个一阶段的检测器。
YOLO使用DarkNet来进行特征提取,后面接一些卷积层。

但是,并没有使用多尺度的特征图来独立的检测物体,而是部分的将特征图展开和另一个低分辨率的特征图拼接起来。例如,YOLO将28 × 28 × 512 层转换成 14 × 14 × 2048,然后和14 × 14 ×1024 的特征图拼接。之后,YOLO 在新的14 × 14 × 3072 层上使用卷积来进行预测。
YOLO(v2)做了许多的实现来提升,将mAP从第一个版本的63.4提升到了78.6,YOLO9000可以检测9000个不同的类别的物体。
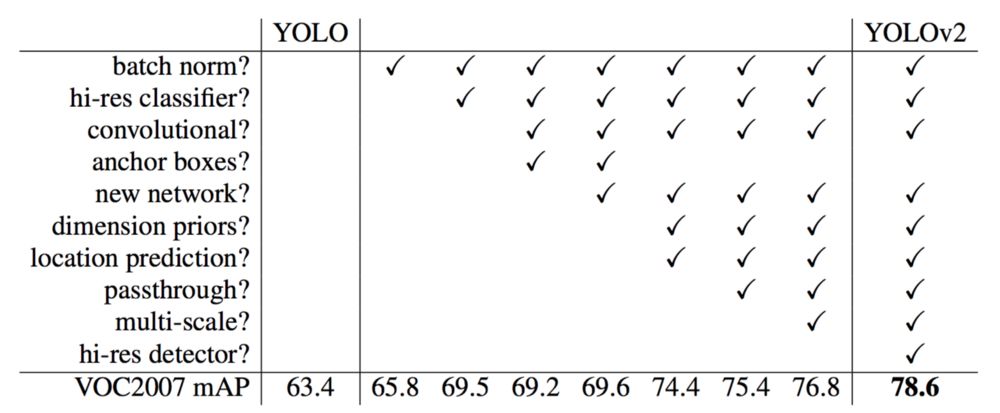
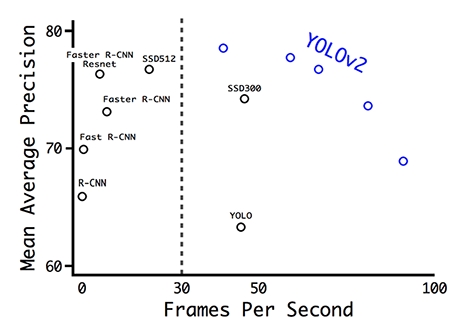
这个是YOLO文章中不同的检测器mAP和FPS的对比。YOLOv2可以使用不同的分辨率的输入图像。低分辨率图像有高的FPS但是低mAP。
YOLOv3
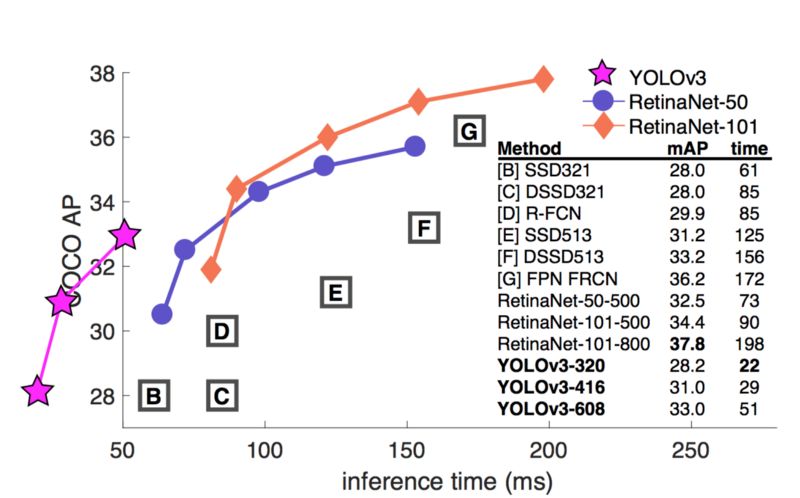
YOLOv3换成了一个更加复杂的主干网络来进行特征提取。Darknet-53主要包括了3x3和1x1的卷积核,使用了类似ResNet的跳跃连接。Darknet-53 比 ResNet-152有更小的BFLOP,但是分类准确率差不多,快2倍。

YOLOv3也增加了特征金字塔来更好的检测小物体。这里是不同检测器的准确率和速度的权衡。
特征金字塔网络 (FPN)
检测不同尺度的物体是很有难度的,特别是小物体。特征金字塔网络是一种特征提取器,通过设计特征金字塔来提升准确率和速度。它替代了如Faster R-CNN的特征提取器,生成了高质量的特征金字塔。
数据流
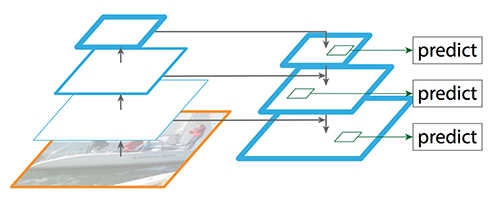
FPN由一个从底层到顶层和从顶层到底层的路径。从底层到顶层的路径是通常的卷积神经网络,用来进行特征提取。越往高层,空间分辨率越低,使用高层次的结构进行检测,语义的抽象程度每层递增。
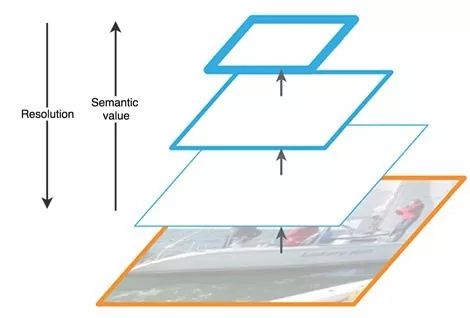
SSD使用多层特征图进行检测。但是,底层并没有用来进行物体的检测。底层虽然分辨率高,但是语义的抽象程度不够,速度也降低的很厉害。所以,SSD只是用了高层来进行检测,对小物体的效果并不是很好。
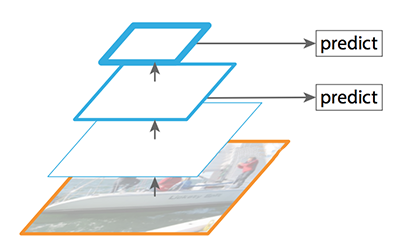
FPN提供了一个从顶层到底层的路径,来从具有丰富语义信息的层构建成高分辨率的层。
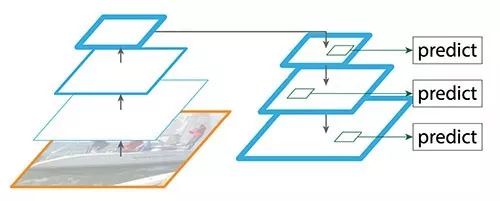
重建之后的层语义方面的信息是足够强了,但是经过了这么多的下采样和上采样之后,物体的位置不够精确。我们添加了重构的层和对应的特征图之间的连接来帮助检测器更好的预测位置。
下面是一个从底层到顶层和从顶层到底层的细节图。P2, P3, P4 和 P5是物体检测的特征图金字塔。
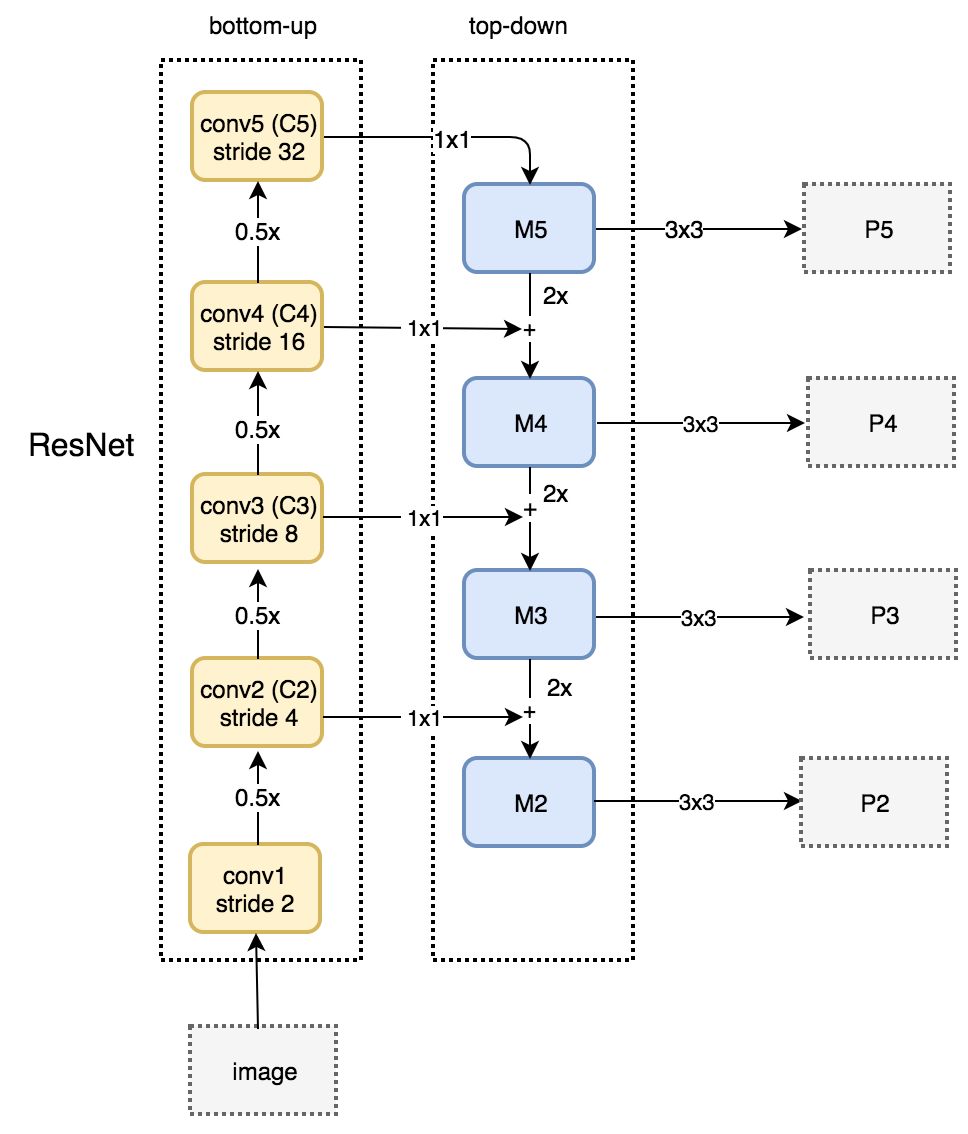
带RPN的FPN
FPN本身并不是一个物体检测器。这是一个物体检测器中的特征检测器。下面是独立的使用每一个特征图 (P2 到 P5) 来进行物体检测。
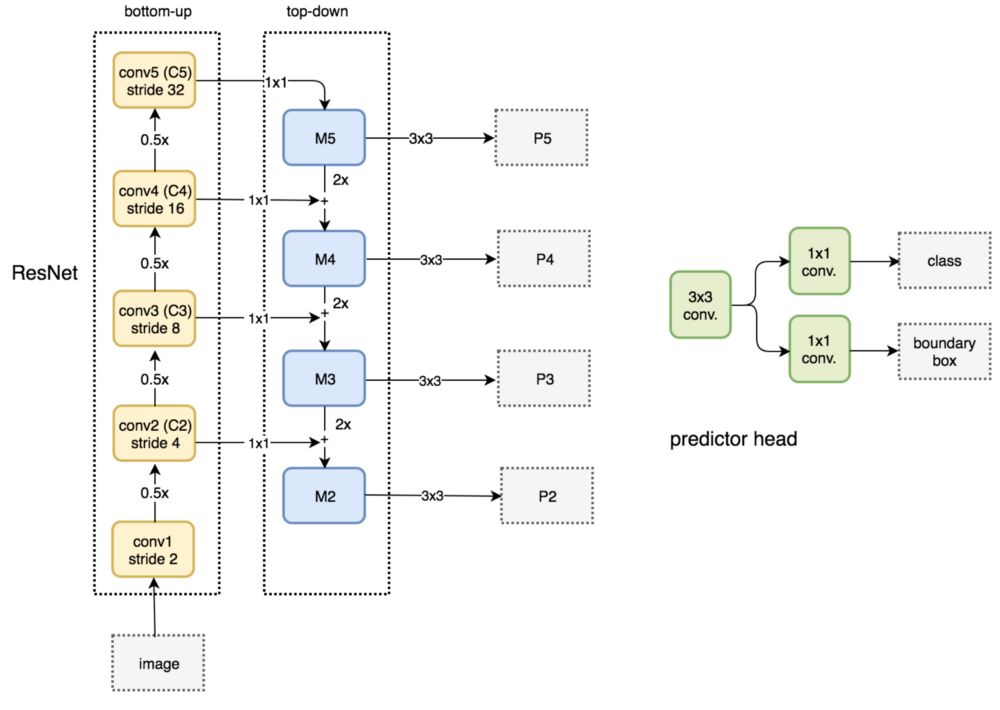
在Fast R-CNN 或者 Faster R-CNN中使用FPN
在FPN中,我们生成了特征金字塔。我们使用RPN(上面描述的)来产生ROIs。基于ROI的尺寸,我们为特征图层选择合适的尺寸来进行块的特征提取。
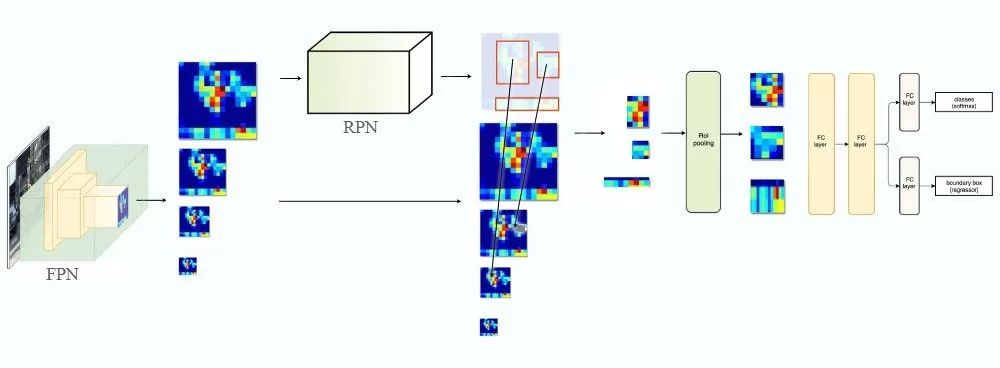
困难样本挖掘
对于大多数的检测器如SSD和YOLO,我们做出的预测比实际的物体数量要多得多。所以,负样本的数量要远远多于正样本的数量。这在训练的时候,会带来类别不均衡的问题,会对训练带来伤害。我们训练模型的时候会更偏向于学习背景空间是什么样的,而不是检测物体。然而,我们又需要负样本来学习不好的预测是什么样的。所以,对于SSD来说,我们对计算出的置信度得分进行了排序,我们选择了得分高的那些样本,确保选到的负样本和正样本的比例最多是3:1。这样使得训练更加的稳定和快速。
推理中的非极大值抑制
检测器会对同一个物体做出重叠的预测。为了解决这个问题,我们使用了非极大值抑制的方法来去掉那些低置信度的冗余的预测。我们对所有的预测按照置信度得分进行排序,然后从高到低一个一个遍历。如果有哪个预测和当前的预测是同一个类别,而且IOU大于0.5的话,我们就将它从列表中移除。
Focal loss (RetinaNet)
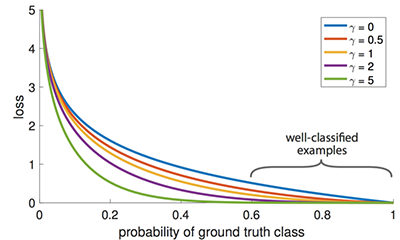
类别不均衡会对最后的结果有影响。SSD在训练的时候对物体和背景进行了重新的采样,所以不会被图像的背景带偏。Focal loss使用了另外的一个方法来减少已训练好的类别的loss。所以,每当模型在检测背景方面已经训练的很好了的时候,Focal loss会减小背景的损失,会把训练的重点放在物体检测上。我们从交叉熵损失开始,对高置信度的类别加上一个权重来减小交叉熵。

例如,γ = 0.5,focal loss对于训练的很好的类别的样本会将loss趋近于0。
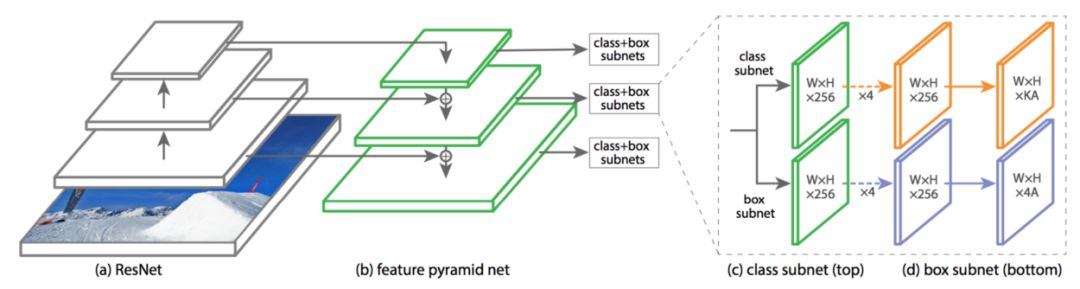
这是基于ResNet利用了FPN的RetinaNet,使用了Focal loss。
本文可以任意转载,转载时请注明作者及原文地址。

请长按或扫描二维码关注我们















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









