







 Focal Loss for Dense Object Detection引入问题目前目标检测的框架一般分为两种:基于候选区域的two-stage的检测框架(比如fast r-cnn系列),基于回归的one-stage的检测框架(yolo,ssd这种),two-stage的效果好,one-stage的快但是效果差一些。本文作者希望弄明白为什么one-stage的检测器准确率不高的问题,作者给出的解释
Focal Loss for Dense Object Detection引入问题目前目标检测的框架一般分为两种:基于候选区域的two-stage的检测框架(比如fast r-cnn系列),基于回归的one-stage的检测框架(yolo,ssd这种),two-stage的效果好,one-stage的快但是效果差一些。本文作者希望弄明白为什么one-stage的检测器准确率不高的问题,作者给出的解释
Focal Loss for Dense Object Detection
引入问题
目前目标检测的框架一般分为两种:基于候选区域的two-stage的检测框架(比如fast r-cnn系列),基于回归的one-stage的检测框架(yolo,ssd这种),two-stage的效果好,one-stage的快但是效果差一些。
本文作者希望弄明白为什么one-stage的检测器准确率不高的问题,作者给出的解释是由于前正负样本不均衡的问题(感觉理解成简单-难分样本不均衡比较好)
We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause
样本的类别不均衡会带来什么问题
(1) training is inefficient as most locations are easy negatives that contribute no useful learning signal;
(2) en masse,the easy negatives can overwhelm training and lead to degenerate models.
由于大多数都是简单易分的负样本(属于背景的样本),使得训练过程不能充分学习到属于那些有类别样本的信息;其次简单易分的负样本太多,可能掩盖了其他有类别样本的作用(这些简单易分的负样本仍产生一定幅度的loss,见下图蓝色曲线,数量多会对loss起主要贡献作用,因此就主导了梯度的更新方向,掩盖了重要的信息)
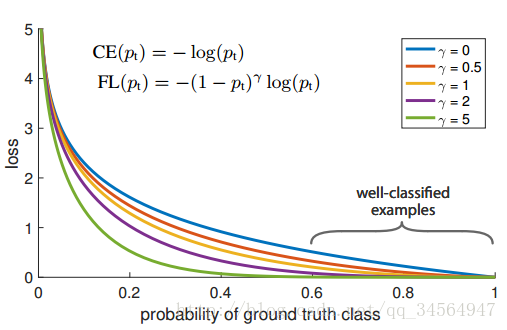
对于two-stage的检测器而言,通常分为两个步骤,第一个步骤即产生合适的候选区域,而这些候选区域经过筛选,一般控制一个比例(比如正负样本1:3),另外还通过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









