






上方“AI公园”,关注公众号
作者:Holden Bridge
编译:ronghuaiyang

NBA的超级明星不仅是生活中的大人物,他们的追随者也不局限于在球场上。Twitter提供了一个专业的赛场,为垃圾话,个人政治观点提供了出口,同时增长了巨大的粉丝群体。我们想要深入的看一下:
探索一下工资,twitter追随者,以及其他NBA统计数据之间的关系
我们可不可以使用机器学习,给定一个球员,通过Twitter的追随者数量来预测工资
NBA的球员现在是怎用用Twitter的
数据
我们从Kaggle的公开数据库中拿到了数据。我们的数据集叫做NBA社交影响力,在 这里下载。

一旦我们发现了有最多的twitter跟随者的球员,我们需要看看是不是这些名字也在最高收入的球员名单上。
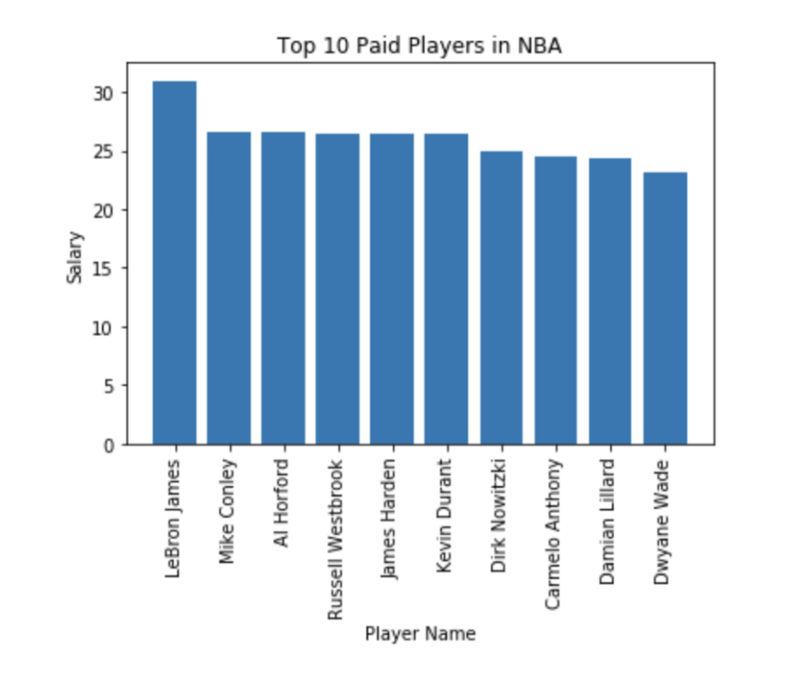
10个里面,有6个两个名单上都有。我们之后会进一步看看,是否整个NBA都有这样的一个关系。
使用线性回归通过Twitter跟随者数量预测收入:
目的是使用线性回归来构建一个交互式预测模型
第一步是决定将哪些统计量放到我们的模型里,我们做了许多变量的散点图,希望能够找到最显著的正相关的变量。
探索性数据分析:
刚开始考虑是什么因素使得球员能够获得最高的收入的时候,我们首先考虑的是得分,助攻,篮板还有年龄作为影响球员收入的统计量。然后我们做了这些变量的散点图。所有的下面这些都是非常强的正相关的关系。
场均得分
场均助攻
场均篮板
球员年龄
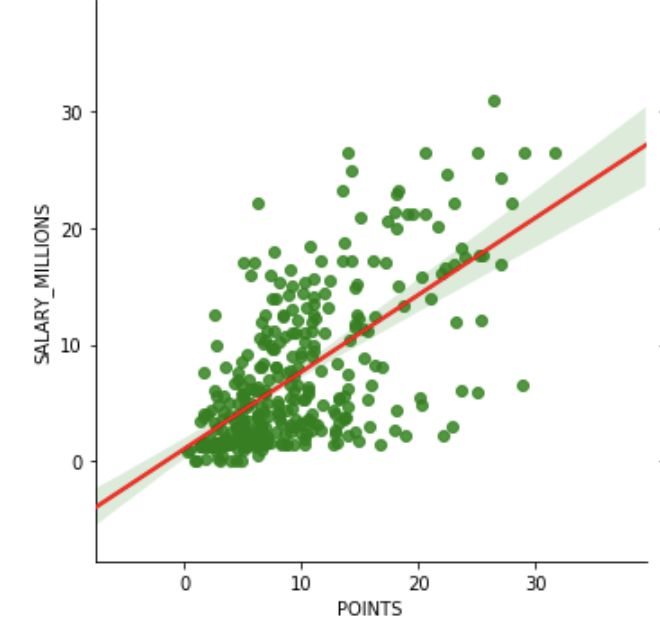
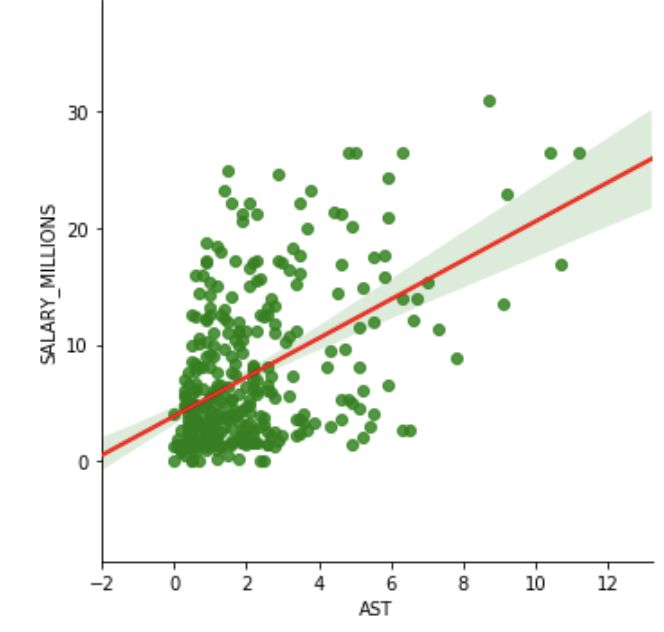
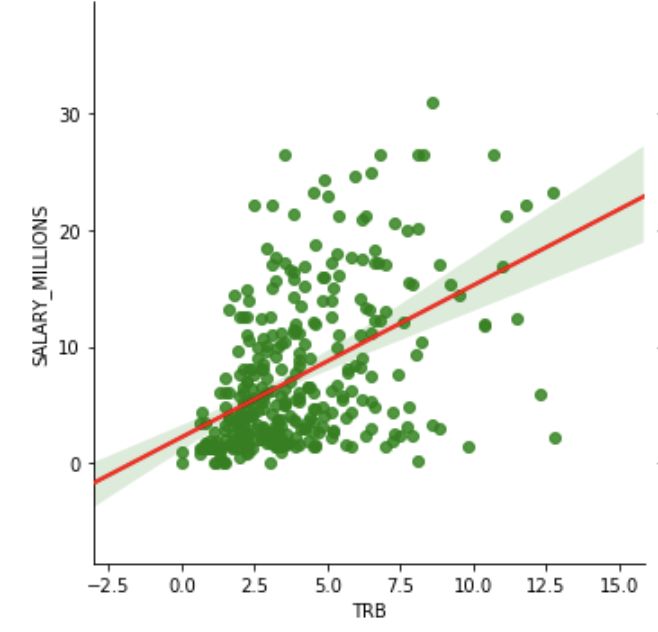
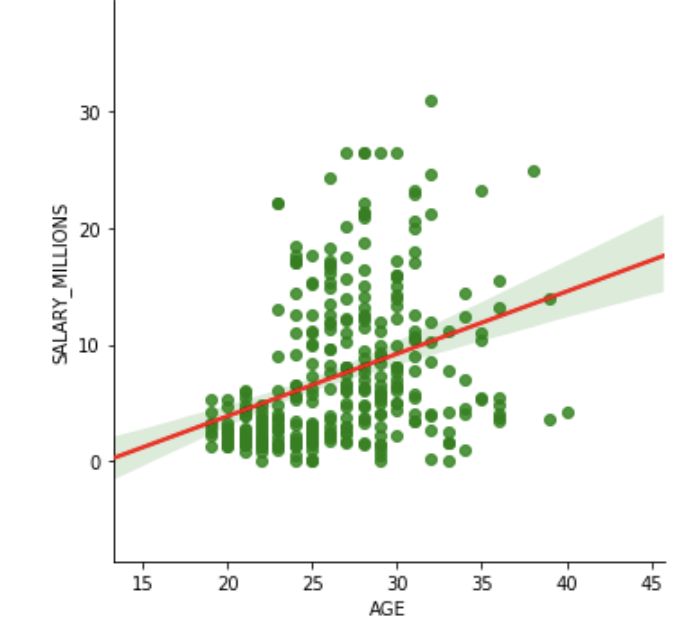
使用这些结果,我们可以构建一个模型基于这4个非常重要的因素来预测球员的工资。我们使用Python的statsmodels来构建线性回归模型。
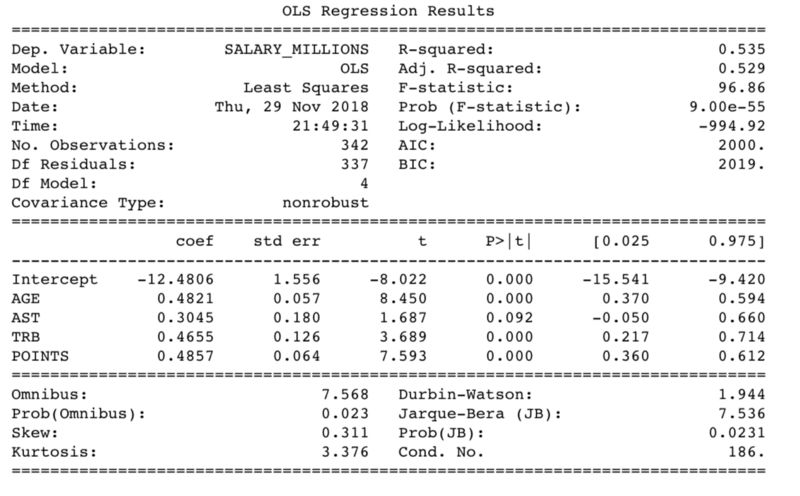
正如你看到的,模型中的变量具有的P值基本都是0,表示这些变量非常显著,只有助攻的P值有点高0.092。但是,考虑到助攻在NBA中的重要性,我们在模型中还是保留了。
如何解释这些数字
每个变量(年龄,助攻,篮板,得分)都有一个系数,用这个系数乘上输入的变量的数字。例如,球员#1是25岁,场均18分,6助攻,5.3篮板。他的工资可以这样计算:
Salary = (25 * 0.4821) + (18 * 0.4857) + (6 * 0.3045) + (5.3 * 0.4655)- 12.4806
Twitter从何而来?
原来我们想用同样的统计量像预测球员工资一样来预测球员的Twitter的跟随者数量。但是,这样几乎不可能,因为没有一个变量对于球员的Twitter跟随者数量是显著的,不过我们的确有一个发现:

球员的Twitter跟随者数量和球员的工资是强正相关的关系
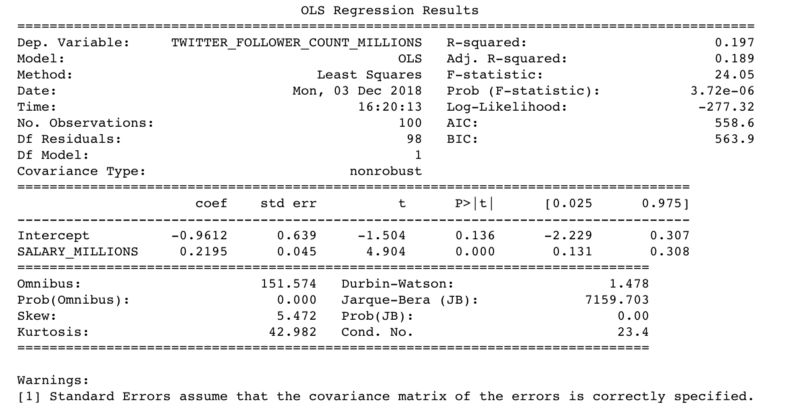
计算Twitter的跟随者数量:
我们使用4个变量,年龄,得分,助攻,篮板
我们用第一个模型计算球员的工资
我们使用球员工资作为输入,用第二个模型计算球员的Twitter跟随者数量
例子:Age- 25, Points- 18, Assists- 6, Rebounds- 5.3
预测工资 = $12.58 million
使用模型#2- Twitter跟随者数量 = (12.58 * 0.2195)- 0.9612
预测Twitter跟随者数量= 1.80 million
预测一个球员的工资很难,看看很低的R方值就知道了。我们的计划是使用球员的统计信息,如得分,助攻,篮板,年龄来计算工资,再用工资来计算球员的Twitter跟随者数量。我们做了一个工具,可以输入一个假设的球员的数据,计算球员的工资和Twitter的跟随者数量。
点击这里查看NBA球员Twitter跟随者数量计算器
计算一个球员的Twitters跟随者数量很有难度,不过,我们可不可以用机器学习来提升我们的方案呢。
使用机器学习来预测工资和Twitter跟随者数量:
在用机器学习之前,我们做了一个相关性的热力图,帮助我们确认哪些变量可以丢掉,哪些需要保留。

机器学习预测工资
根据我们从热力图收集的信息和模型完成之后的一些测试,我们决定了在计算工资时丢掉除了下面的之外的其他的统计量。
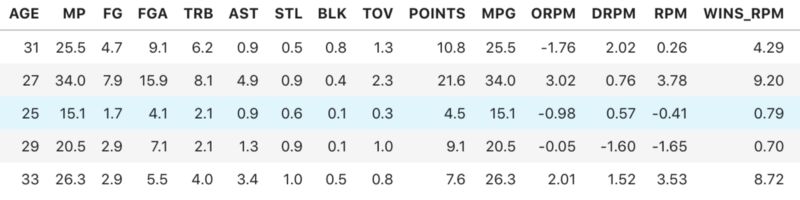
这些统计量对于工资都是正相关的,这些数据我们在做线性回归的时候都会用到,但是我们还用到了更多的数据,来给模型更多的信息。我们还决定预测工资的最佳方法是预测一个工资的范围,每个范围的区间是5百万美元,不这样做的话,几乎不可能得到比较准确的预测。我们可以看看我们的模型对于区间的预测效果怎么样。跑了几个不同的模型,我们发现随机森林分类器准确率最高。我们跑了多次,每次机会都在50%到60%之间,这比瞎猜显然要好多了,为什么不能进一步优化模型了呢,有几个原因。主要的是,我们的数据集太有限了,没有拿到所有的NBA的球员。另外一个原因是,NBA的球员的表现并不完全和工资相匹配。新秀合同有4年,如果新秀球员表现的很好,那么会和工资不匹配。同样的,伤病也会让一个高工资的球员表现很差。可以这么说,我们的模型预测是球员的真实状态下的工资。
机器学习计算Twitter跟随者数量
不幸的是,我们的数据对于预测Twitter跟随者并没有什么用。我们的数据集里面并没有足够的球员有很多的Twitter跟随者,很多只有很少的Twitter跟随者。和工资的机器学习一样,我们需要预测一个区间,但是数据集中大部分的数据Twitter跟随者都很少,所以数据是偏向少的Twitter跟随者一边的。因为这个,这个反馈并没有给我们什么有用的信息。
当前NBA的Twitter中的模式:
我们想分析一下出名的NBA球员的Twitter,那些有大量Twitter跟随者的账号。作为一个案例,我们分析了10个当前最多的Twitter跟随者的NBA球员,如下:
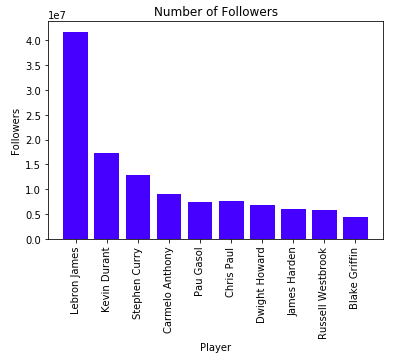
决定了我们需要分析的球员之后,我们试着假设是什么吸引人们关注这些球员。当然,NBA球星是一个主要的因素,这个我们没办法关联到数据上,但是这个并不能完全解释这个top10的名单。 Dwight Howard在走下坡路,Pau Gasol大部分时间是个角色球员, Blake Griffin依然打的很好,过去几个赛季一直伤病困扰。另外, Carmelo Anthony逐渐淡出NBA。那么还有什么其他的原因导致了这些球员这么受欢迎呢?我们拉了最近的1000天的球员的Twitter,决定分析一下球员的tweet,账号多长时间了,有多少好友,有多少人关注,最后进行一个情感的分析,看看是不是受得了这么多人的关注。
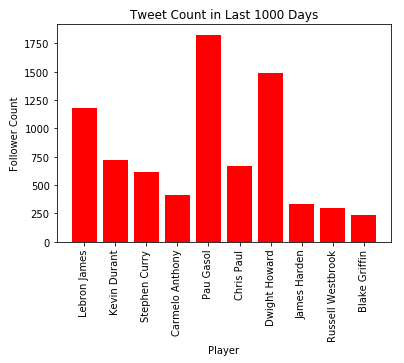
我们的一个想法是,多少人关注这个球员的一个潜在的因素是他们在Twitter上有多活跃。你可以看到,过去1000天的tweets数量图,基本上和关注者的趋势差不多,除了 Dwight Howard 和 Pau Gasol。就像我们之前讨论的,这是两个不在当前NBA水准的样本,所以他们的持续Twitter的曝光保持了他们能够被高度关注。
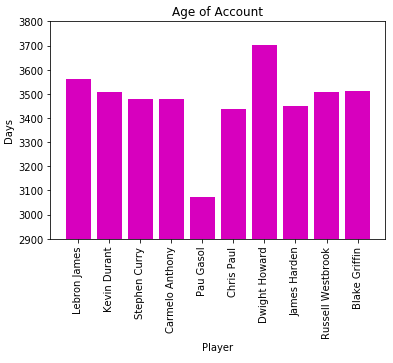
另外的一个因素是账号的时间,这给了他们更多的时间来获取关注。然后,结果并没有什么用,Pau Gasol用很少的时间积累了大量的跟随者。
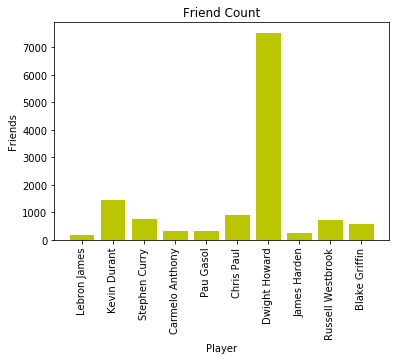
我们再看好友数量,只有Dwight Howard一枝独秀,这也解释了为什么他会有这么多的关注,考虑到他实际的比赛表现。好友越多,表示有更多的互动,传播更广。
最后,我们基于最近1000天的tweets做了一个情感分析,我们分析了每个球员的每个tweet,但是没有包括表情和链接,所以有点缺陷,情感和关注者有那么一点关系,每个球员都有一个积极情感得分。
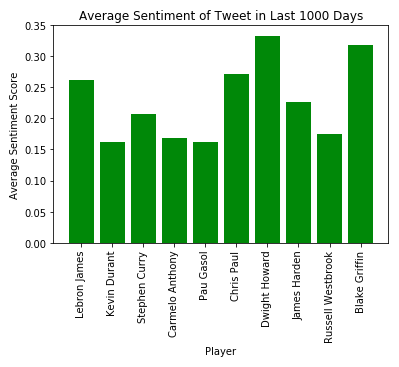
总的来说,很难确定这些球员的Twitter的跟随者的准确原因,但是数据给我我们一些有用的信息和NBA的Twitter的一些信息。每个球员除了Pau Gasol都在NBA的工资顶端,也在Twitter上非常活跃。球星的影响力,加上和球迷的亲和力,让这些球员有了巨大的关注者,而且未来还会持续的增加。
这个 工程的代码链接https://github.com/holdenbridge/Big-Data-Final-Project

往期精彩回顾
2、深度学习论文阅读路线图
3、如何构建使用Python进行数据处理的肌肉记忆
4、Image-to-Image的论文汇总
5、我们从一阶段的物体检测器SSD,YOLOv3,FPN & Focal loss (RetinaNet)中学到了什么?
6、资源|10个机器学习和深度学习的必读免费课程
7、经验之谈|别再在CNN中使用Dropout了
8、我们从region based物体检测器 (Faster R-CNN, R-FCN, FPN)中能学到些什么?
9、非常好用的Python图像增强工具,适用多个框架
10、Kaggle竞赛介绍: Home Credit default risk(一)
本文可以任意转载,转载时请注明作者及原文地址。

请长按或扫描二维码关注我们

















 2499
2499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









