






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Dipanjan (DJ) Sarkar
编译:ronghuaiyang
数值型数据的处理策略,非常的实用和全面。
Introduction
“有钱能使鬼推磨”是一件你不能忽视的事情,不管你是同意还是不同意。在当今数字革命时代,更贴切的说法应该是“数据让世界运转”。事实上,无论企业、公司和组织的规模和规模如何,数据都已成为它们的头等资产。任何智能系统,无论其复杂性如何,都需要由数据驱动。在任何智能系统的核心,我们都有一个或多个基于机器学习、深度学习或统计方法的算法,这些算法使用这些数据来收集知识,并在一段时间内提供智能的洞察。算法本身相当幼稚,无法在原始数据上开箱即用。因此,从原始数据中设计有意义的特征是非常重要的,这些特征可以被这些算法理解和使用。
数值型数据上的特征工程
数字数据通常以标量的形式表示数据,标量描述观察、记录或测量的结果。这里,数值数据指的是连续数据,而不是通常表示为分类数据的离散数据。数值数据也可以表示为值的向量,其中向量中的每个值或实体都可以表示特定的特征。整数和浮点数是连续数值数据中最常见和使用最广泛的数值数据类型。即使数值数据可以直接输入到机器学习模型中,在构建模型之前,你仍然需要设计与场景、问题和领域相关的特征。因此,对特征工程的需求仍然存在。让我们利用python并研究一些针对数值数据的特征工程的策略。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as spstats
%matplotlib inline原始度量
如前所述,通常可以根据上下文和数据格式将原始数字数据直接提供给机器学习模型。原始度量通常使用数值变量作为特征直接表示,而不需要任何形式的转换或工程。通常,这些特征可以指示值或计数。让我们加载一个数据集,Pokemon dataset也可以在Kaggle上找到。
poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8') poke_df.head()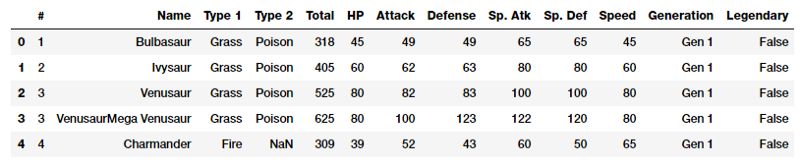
Pokémon就是口袋妖怪。。简而言之,你可以把它们想象成拥有超能力的虚构动物!这个数据集由这些字符组成,每个字符都有不同的统计信息。
数值
如果您仔细观察上图中的数据帧快照,你可以看到几个属性表示可以直接使用的数值原始值。下面的代码片段更着重地描述了其中的一些特征。
poke_df[['HP', 'Attack', 'Defense']].head()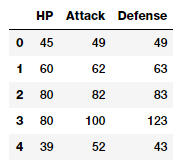
因此,您可以直接将这些属性用作上述数据框架中描述的特征。这些包括每个口袋妖怪的HP(生命值),攻击和防御统计。事实上,我们还可以计算出这些领域的一些基本统计指标。
poke_df[['HP', 'Attack', 'Defense']].describe()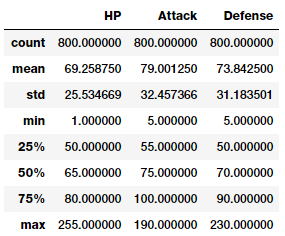
这样,您就可以很好地了解这些特性中的统计度量,比如计数、平均值、标准差和四分位数。
计数
原始度量的另一种形式包括表示特定属性的频率、计数或出现频率的特性。让我们来看一个来自millionsong dataset的数据示例,该数据描述了不同用户听过的歌曲的数量或频率。
popsong_df = pd.read_csv('datasets/song_views.csv',
encoding='utf-8')
popsong_df.head(10)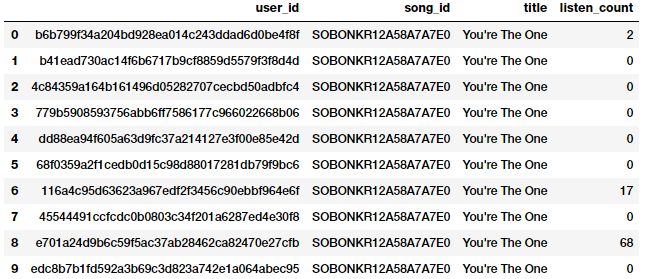
从上面的快照可以很明显地看出,“listen_count”字段可以直接用作基于频率\计数的数值特性。
二值化
通常,原始频率或计数可能与基于正在解决的问题构建模型无关。例如,如果我正在为歌曲推荐建立一个推荐系统,我只想知道一个人是否对某首歌感兴趣,或者是否听过这首歌。这并不需要听一首歌的次数,因为我更关心他/她听过的各种歌曲。在这种情况下,首选二进制特性,而不是基于计数的特性。我们可以将“listen_count”字段二进制化,如下所示。
watched = np.array(popsong_df['listen_count'])
watched[watched >= 1] = 1
popsong_df['watched'] = watched您还可以在这里使用“scikit-learn”的“Binarizer”类的“预处理”模块来执行相同的任务,而不是“numpy”数组。
from sklearn.preprocessing import Binarizer
bn = Binarizer(threshold=0.9)
pd_watched = bn.transform([popsong_df['listen_count']])[0]
popsong_df['pd_watched'] = pd_watched
popsong_df.head(11)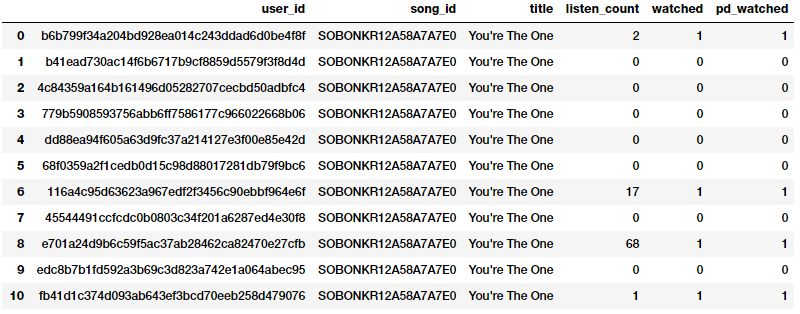
从上面的快照可以清楚地看到,这两种方法都产生了相同的结果。因此,我们得到一个二元化的特征,表明是否每个用户都听过这首歌,然后可以在相关的模型中进一步使用。
四舍五入
通常,在处理诸如比例或百分比之类的连续数字属性时,我们可能不需要具有高精确度的原始值。因此,将这些高精度百分比四舍五入到数字整数中通常是有意义的。然后,这些整数可以直接用作原始值,甚至可以用作分类(基于离散类)特征。让我们试着在一个虚拟数据集中应用这个概念,它描述了存储项及其受欢迎的百分比。
items_popularity = pd.read_csv('datasets/item_popularity.csv',
encoding='utf-8')
items_popularity['popularity_scale_10'] = np.array(
np.round((items_popularity['pop_percent'] * 10)),
dtype='int')
items_popularity['popularity_scale_100'] = np.array(
np.round((items_popularity['pop_percent'] * 100)),
dtype='int')
items_popularity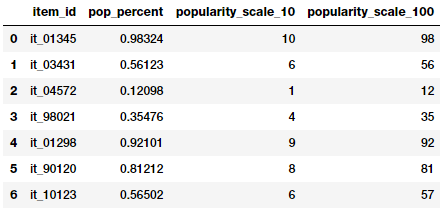
根据上面的输出,您可以猜测我们尝试了两种舍入形式。这些特性现在在1-10 *和1-100 *的范围内描述了项目的受欢迎程度。您可以根据场景和问题使用这些值作为数值或分类特征。
相互作用
监督机器学习模型通常试图将输出响应(离散类或连续值)建模为输入特征变量的函数。例如,一个简单的线性回归方程可以表示为
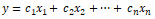
其中输入特征由变量
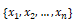
描述,权值或系数,用
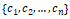
表示。预测的目标是y.
在本例中,这个简单的线性模型描述了输出和输入之间的关系,完全基于单独的输入特征。
然而,通常在一些实际场景中,尝试捕获这些特征变量之间的交互作为输入特征集的一部分是有意义的。简单描述上述具有交互特征的线性回归公式的扩展为:
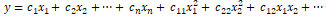
特征可以表示为:
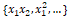
交互特征的表示。现在让我们尝试在我们的Pokemon数据集中设计一些交互功能。
atk_def = poke_df[['Attack', 'Defense']]
atk_def.head()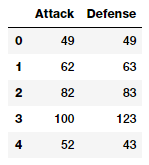
从输出数据帧中,我们可以看到我们有两个数字(连续)特征,“攻击”和“防御”。我们现在将通过利用 scikit-learn来构建第2级特征。
from sklearn.preprocessing import PolynomialFeatures
pf = PolynomialFeatures(degree=2, interaction_only=False,
include_bias=False)
res = pf.fit_transform(atk_def)
res
Output
------
array([[ 49., 49., 2401., 2401., 2401.],
[ 62., 63., 3844., 3906., 3969.],
[ 82., 83., 6724., 6806., 6889.],
...,
[ 110., 60., 12100., 6600., 3600.],
[ 160., 60., 25600., 9600., 3600.],
[ 110., 120., 12100., 13200., 14400.]])上述特征矩阵共描述了五个特征,包括新的交互特征。我们可以看到上述矩阵中每个特征的维度如下。
pd.DataFrame(pf.powers_, columns=['Attack_degree',
'Defense_degree'])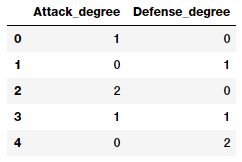
看看这个输出,我们现在从这里描述的角度知道每个特征实际上代表什么。有了这些知识,我们现在可以为每个特性指定一个名称,如下所示。这只是为了便于理解,您应该使用更好的、易于访问的和简单的名称来命名您的特征。
intr_features = pd.DataFrame(res, columns=['Attack', 'Defense',
'Attack^2',
'Attack x Defense',
'Defense^2'])
intr_features.head(5)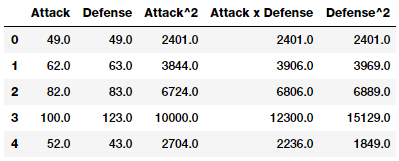
因此,上面的数据框架代表了我们的原始特征以及它们的交互特征。
分箱
处理原始的、连续的数值特性的问题是,这些特性中的值的分布常常是倾斜的。这意味着有些值将非常频繁地出现,而有些值则非常罕见。除此之外,这些特性中的值的变化范围也存在另一个问题。例如,特定音乐视频的访问量可能非常大(Despacito,有些可能非常小。直接使用这些特性会导致很多问题,并对模型产生负面影响。因此,有一些策略可以处理这个问题,包括binning和transformation。
Binning,也称为量化,用于将连续的数字特征转换为离散的特征(类别)。这些离散值或数字可以看作是原始的连续数值被绑定或分组到其中的类别或容器。每个箱子代表一个特定程度的强度,因此一个特定范围的连续数值落在它里面。结合数据的具体策略,包括固定宽度和自适应宽度相结合。让我们使用从2016 FreeCodeCamp Developer\Coder survey中提取的数据集中的数据子集,该数据集讨论了与程序员和软件开发人员有关的各种属性。
fcc_survey_df = pd.read_csv('datasets/fcc_2016_coder_survey_subset.csv',
encoding='utf-8')
fcc_survey_df[['ID.x', 'EmploymentField', 'Age', 'Income']].head()
ID.x变量基本上是每个接受调查的码农\开发人员的唯一标识符,其他字段非常容易理解。
固定宽度分箱
正如名称所示,在固定宽度binning中,我们为每个箱子都有特定的固定宽度,这些宽度通常由用户分析数据预先定义。每个库都有一个预先固定的值范围,这些值应该根据某些领域知识、规则或约束分配给该库。基于舍入的舍入是一种方法,您可以使用前面讨论过的舍入操作来存储原始值。
现在让我们考虑码农调查数据集中的“年龄”特征,并查看其分布情况。
fig, ax = plt.subplots()
fcc_survey_df['Age'].hist(color='#A9C5D3', edgecolor='black',
grid=False)
ax.set_title('Developer Age Histogram', fontsize=12)
ax.set_xlabel('Age', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)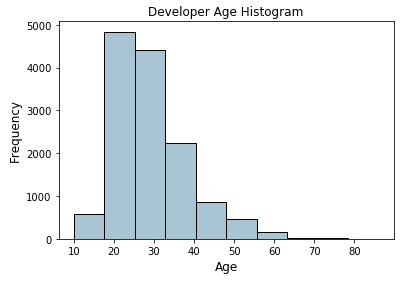
上面的直方图描述的开发人员年龄的与预期(年龄较小的开发人员)有轻微的右偏。现在,我们将根据以下方案将这些原始年龄值分配到特定的箱中。
Age Range: Bin
---------------
0 - 9 : 0
10 - 19 : 1
20 - 29 : 2
30 - 39 : 3
40 - 49 : 4
50 - 59 : 5
60 - 69 : 6
... and so on我们可以很容易地使用我们在前面的“四舍五入”部分中所学到的知识来完成这一操作,我们将这些原始年龄值四舍五入,取除以10后的值。
fcc_survey_df['Age_bin_round'] = np.array(np.floor(
np.array(fcc_survey_df['Age']) / 10.))
fcc_survey_df[['ID.x', 'Age', 'Age_bin_round']].iloc[1071:1076]
您可以看到每个年龄对应的箱子都是根据四舍五入分配的。但如果我们需要更多的灵活性呢?如果我们想根据自己的规则\逻辑来决定和修复bin宽度,该怎么办?基于自定义范围的binning将帮助我们实现这一点。让我们使用下面的方案对开发人员的年龄进行binning定义一些定制的年龄范围。
Age Range : Bin
---------------
0 - 15 : 1
16 - 30 : 2
31 - 45 : 3
46 - 60 : 4
61 - 75 : 5
75 - 100 : 6基于这个自定义的binning方案,我们现在将为每个开发人员的年龄值标记bin,并存储bin范围和相应的标签。
bin_ranges = [0, 15, 30, 45, 60, 75, 100]
bin_names = [1, 2, 3, 4, 5, 6]
fcc_survey_df['Age_bin_custom_range'] = pd.cut(
np.array(
fcc_survey_df['Age']),
bins=bin_ranges)
fcc_survey_df['Age_bin_custom_label'] = pd.cut(
np.array(
fcc_survey_df['Age']),
bins=bin_ranges,
labels=bin_names)
# view the binned features
fcc_survey_df[['ID.x', 'Age', 'Age_bin_round',
'Age_bin_custom_range',
'Age_bin_custom_label']].iloc[10a71:1076]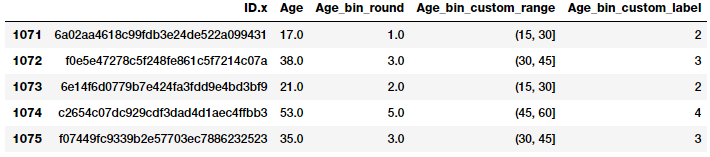
自适应Binning
使用固定宽度binning的缺点是,由于我们手工决定了bin的范围,我们最终会得到不规则的bin,而这些bin并不是根据每个bin中的数据点或值来统一的。有些bin可能是密集的,而有些可能是稀少甚至是空的!在这些让数据自己说话的场景中,自适应binning是一种更安全的策略!没错,我们使用数据分布本身来决定bin的范围。
基于分位数的binning是一种很好的自适应融合策略。分位数是特定的值或切点,它有助于将特定数值字段的连续值分布划分为离散的连续桶或区间。因此,q- quantiles有助于将数值属性划分为q相等的分区。分位数的常见例子包括2-分位数称为中位数,它将数据分布划分为两个相等的分位数,4-分位数称为四分位数,它将数据划分为4个相等的分位数,10-分位数也称为十分位数,它创建10个相同宽度的分位数。现在让我们看看开发人员“收入”字段的数据分布。
fig, ax = plt.subplots()
fcc_survey_df['Income'].hist(bins=30, color='#A9C5D3',
edgecolor='black', grid=False)
ax.set_title('Developer Income Histogram', fontsize=12)
ax.set_xlabel('Developer Income', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)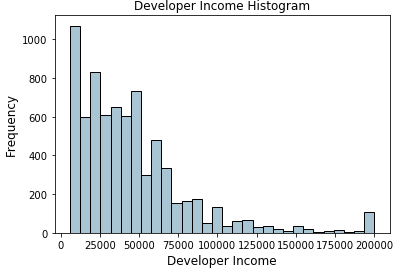
上面的分布描述了收入的右偏,较少的开发人员赚更多的钱,反之亦然。让我们采用一个4分位数或基于四分位数的自适应binning方案。我们可以很容易地得到以下四分位数。
quantile_list = [0, .25, .5, .75, 1.]
quantiles = fcc_survey_df['Income'].quantile(quantile_list)
quantiles
Output
------
0.00 6000.0
0.25 20000.0
0.50 37000.0
0.75 60000.0
1.00 200000.0
Name: Income, dtype: float64现在让我们在原始分布直方图中可视化这些分位数!
fig, ax = plt.subplots()
fcc_survey_df['Income'].hist(bins=30, color='#A9C5D3',
edgecolor='black', grid=False)
for quantile in quantiles:
qvl = plt.axvline(quantile, color='r')
ax.legend([qvl], ['Quantiles'], fontsize=10)
ax.set_title('Developer Income Histogram with Quantiles',
fontsize=12)
ax.set_xlabel('Developer Income', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)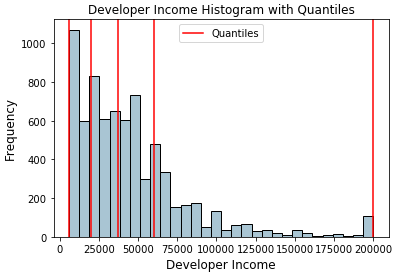
上面分布中的红线描述了四分位值和我们的潜在bins。现在让我们利用这些知识来构建基于四分位数的binning方案。
quantile_labels = ['0-25Q', '25-50Q', '50-75Q', '75-100Q']
fcc_survey_df['Income_quantile_range'] = pd.qcut(
fcc_survey_df['Income'],
q=quantile_list)
fcc_survey_df['Income_quantile_label'] = pd.qcut(
fcc_survey_df['Income'],
q=quantile_list,
labels=quantile_labels)
fcc_survey_df[['ID.x', 'Age', 'Income', 'Income_quantile_range',
'Income_quantile_label']].iloc[4:9]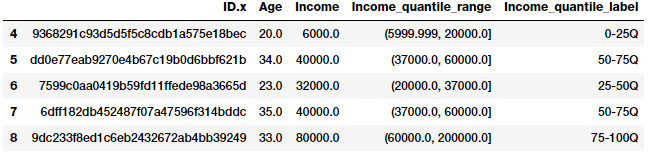
这将使您对基于分位数的自适应binning如何工作有一个很好的了解。这里需要记住的重要一点是,binning的结果导致离散值的分类特征,在任何模型中使用分类数据之前,您可能需要对分类数据进行额外的功能工程。我们将在下一部分中介绍分类数据的特征工程策略!
统计变换
我们在前面简要讨论了偏态数据分布的负面影响。现在让我们通过使用统计或数学转换来看看特征工程的另一种策略。我们将研究Log变换和Box-Cox变换。这两个转换函数都属于幂变换函数族,通常用于创建单调数据转换。它们的主要意义是帮助稳定方差,紧密地依附于正态分布,使数据独立于基于其分布的均值。
Log变换
log 变换属于幂变换函数族。这个函数可以用数学形式表示:
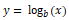
可以变换为:
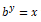
当log变换应用于偏态分布时是有用的,因为它们倾向于扩大落在较低幅度范围内的值,并倾向于压缩或减少落在较高幅度范围内的值。这使得偏态分布尽可能地趋于正态分布。我们在前面使用的开发人员“收入”特征上使用log transform。
fcc_survey_df['Income_log'] = np.log((1+ fcc_survey_df['Income']))
fcc_survey_df[['ID.x', 'Age', 'Income', 'Income_log']].iloc[4:9]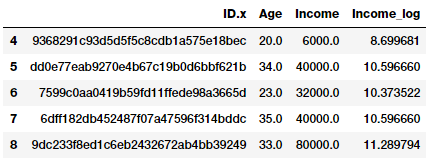
“incom_log”字段描述了log变换后的特征。现在让我们看看这个变换字段上的数据分布。
income_log_mean = np.round(np.mean(fcc_survey_df['Income_log']), 2)
fig, ax = plt.subplots()
fcc_survey_df['Income_log'].hist(bins=30, color='#A9C5D3',
edgecolor='black', grid=False)
plt.axvline(income_log_mean, color='r')
ax.set_title('Developer Income Histogram after Log Transform',
fontsize=12)
ax.set_xlabel('Developer Income (log scale)', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
ax.text(11.5, 450, r'$\mu$='+str(income_log_mean), fontsize=10)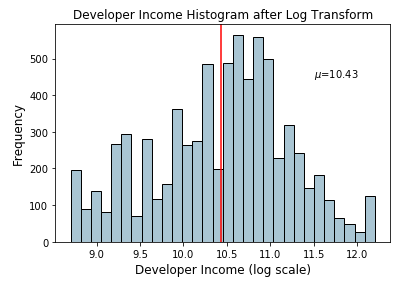
从上面的图中我们可以清楚地看到,与原始数据上的偏态分布相比,分布更接近于正态分布或者高斯分布。
Box-Cox变换
Box-Cox变换是幂变换函数族中另一种常用的函数。这个函数有一个先决条件,即要转换的数值必须为正数(类似于log transform所期望的值)。如果它们是负数,使用一个常数值进行移位。在数学上,Box-Cox变换函数可以表示为:
这样导致转换输出y是输入x和转换参数λ的函数,这样当λ= 0,结果变换是自然对数变换,就是我们前面所讨论的。最优值λ通常是使用最大似然或对数似估计来确定。现在,让我们对开发人员收入特性应用Box-Cox变换。首先,通过删除非空值,我们从数据分布中得到最优的lambda值,如下所示。
income = np.array(fcc_survey_df['Income'])
income_clean = income[~np.isnan(income)]
l, opt_lambda = spstats.boxcox(income_clean)
print('Optimal lambda value:', opt_lambda)
Output
------
Optimal lambda value: 0.117991239456现在,我们已经获得了最优λ值,让我们用Box-Cox变换的两个值λ= 0和λ=λ(最优)来变换开发人员“收入”功能。
fcc_survey_df['Income_boxcox_lambda_0'] = spstats.boxcox(
(1+fcc_survey_df['Income']),
lmbda=0)
fcc_survey_df['Income_boxcox_lambda_opt'] = spstats.boxcox(
fcc_survey_df['Income'],
lmbda=opt_lambda)
fcc_survey_df[['ID.x', 'Age', 'Income', 'Income_log',
'Income_boxcox_lambda_0',
'Income_boxcox_lambda_opt']].iloc[4:9]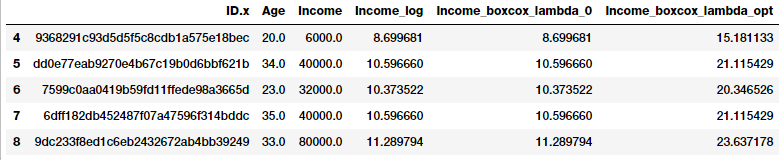
变换后的特征在上面的数据帧中进行了描述。正如我们所期望的,' incomlog '和' incomboxcoxlamba0 '具有相同的值。让我们看看“收入”特征使用最优λ变换之后的分布。
income_boxcox_mean = np.round(
np.mean(
fcc_survey_df['Income_boxcox_lambda_opt']),2)
fig, ax = plt.subplots()
fcc_survey_df['Income_boxcox_lambda_opt'].hist(bins=30,
color='#A9C5D3', edgecolor='black', grid=False)
plt.axvline(income_boxcox_mean, color='r')
ax.set_title('Developer Income Histogram after Box–Cox Transform',
fontsize=12)
ax.set_xlabel('Developer Income (Box–Cox transform)', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
ax.text(24, 450, r'$\mu$='+str(income_boxcox_mean), fontsize=10)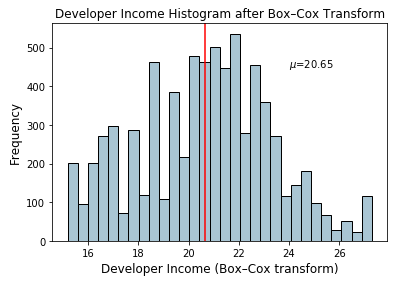
分布看起来更正常,类似于我们在log变换后得到的结果。
总结
特征工程是机器学习和数据科学的一个非常重要的方面,不应该被忽视。虽然我们有像深度学习这样的自动化特性工程方法,以及像AutoML这样的自动化机器学习框架(仍然强调它需要好的特征才能很好地工作!)。特征工程已经存在,甚至其中一些自动化方法常常需要基于数据类型、领域和要解决的问题的特定特征工程。
在本文中,我们研究了在连续数值数据上进行特征工程的常用策略。在下一部分中,我们将研究处理离散、分类数据的流行策略,然后在以后的文章中继续讨论非结构化数据类型。请继续关注!
 —
END—
—
END—
英文原文:https://towardsdatascience.com/understanding-feature-engineering-part-1-continuous-numeric-data-da4e47099a7b
想了解更多机器学习,深度学习的相关内容,请关注作者的网易云课堂:
通俗的深度学习之机器学习基础:
https://study.163.com/course/courseMain.htm?courseId=1005319006&share=2&shareId=400000000486049
通俗易懂的TensorFlow:
https://study.163.com/course/courseMain.htm?courseId=1005778001&share=2&shareId=400000000486049

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()















 1304
1304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









