







 超级会员免费看
超级会员免费看
python入门
1.python初步
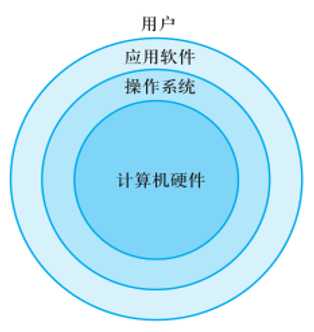
1.1 计算机基础结构
1.1.1 硬件
1944年,美籍匈牙利数学家冯·诺依曼提出计算机基本结构。

五大组成部分:运算器、控制器、存储器、输入设备、输出设备。
– 运算器:按照程序中的指令,对数据进行加工处理。
– 控制器:根据程序需求,指挥计算机的各个部件协调工作。
通常将运算器和控制器集成在中央处理器(CPU)中。

– 存储器:保存各类程序的数据信息。
内存RAM – 容量小,速度快,临时存储数据
硬盘HDD – 容量大,速度慢,永久存储数据

输入设备:外界向计算机传送信息的装置。
例如:鼠标、键盘、扫描仪…
输出设备:计算机向外界传送信息的装置。
例如:显示器、音响、打印机…

1.1.2 软件
操作系统:
– 管理和控制计算机软件与硬件资源的程序。
– 隔离不同硬件的差异,使软件开发简单化。
– Windows,Linux,Unix。
应用软件:为了某种特定的用途而被开发的软件。
软件:程序 + 文档。
– 程序是一组计算机能识别和执行的指令集合。
– 文档是为了便于了解程序所需的说明性资料。
1.2 程序
程序,就是一组发给计算机执行的指令。
大家应该都听说过计算机只认识机器指令,也就是一大堆0101…类型的数据。
我们发出的指令怎么才能让计算机听懂并执行呢?例如:
1234+3*876
这就涉及到编程语言了。
常见的编程语言比如: C 、 C++、 JAVA、python …。程序可以由这样的编程语言来实现。
打个比方,就像你小的时候学了一门语言 ——英语。
学会了英语我们就可以使用英语来写文章。你的文章就能够被会英语的国际友人看懂,领略到你的文采。
假如你学会了python这门外语,那就可以写类似于如下的作文了。
list1 = 'May the Force be with you'.split(" ")
list2 = []
for item in list1:
list2.insert(0, item)
print(" ".join(list2))
以上这个东西电脑就能看懂吗?不会的,它只能保证懂python的人看懂。
计算机之所以能够认识你用python编写的指令,得益于python解释器(一个软件),它可以把我们写的python程序翻译成计算机能懂的二进制指令。

所以,在开始python编程之前,我们需要在自己的电脑上安装python解释器。
官网: https://www.python.org。
在它的官网上就能下载到各个版本的python解释器了。
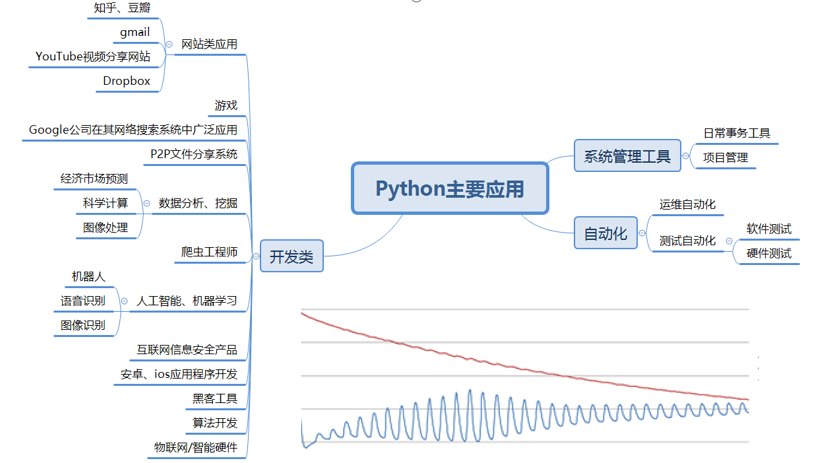
顺便提一句python的主要使用场景。
1.3开发环境的安装
要解决的三个诉求:
1) 能够把python程序翻译为电脑能够识别的机器指令 : 安装python解释器
2) 方便的编写python代码
3) 虚拟环境的管理

-
anaconda安装
官网:https://www.anaconda.com/
安装包下载地址:https://www.anaconda.com/download#downloads
-
安装步骤
#激活base 虚拟环境 conda activate base #换源 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple #测试 pip config list pip install requests -
conda基本命令
#环境本质上就是靠环境变量来实现的 conda info --env #查看已有环境 conda create --name <环境名称> #创建环境 conda create --name <环境名称> python=<Python版本号> conda activate <环境名称> #激活环境 conda deactivate #停用环境包名称 conda install/remove <包名称> #很少使用练习:创建python3.8.1的环境 并激活
conda create --name lang python=3.8.1 conda info --env conda activate lang -
-
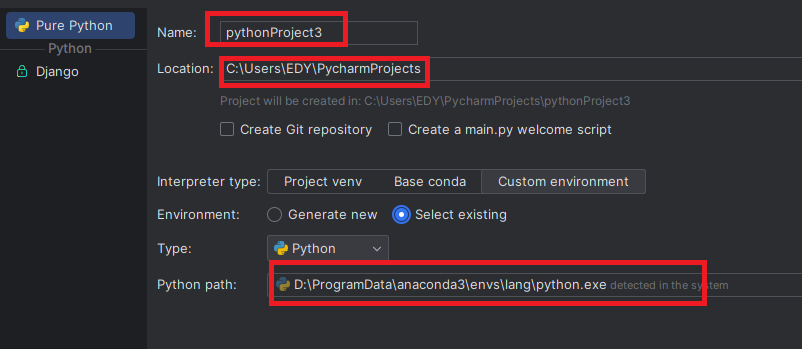
pycharm安装
官网:https://www.jetbrains.com.cn/
windows环境安装包下载地址:https://www.jetbrains.com.cn/pycharm/download/download-thanks.html?platform=windows&code=PCC
Linux环境安装包下载地址:https://www.jetbrains.com.cn/pycharm/download/download-thanks.html?platform=linux&code=PCC

1.4 第一个程序
-
交互式开发
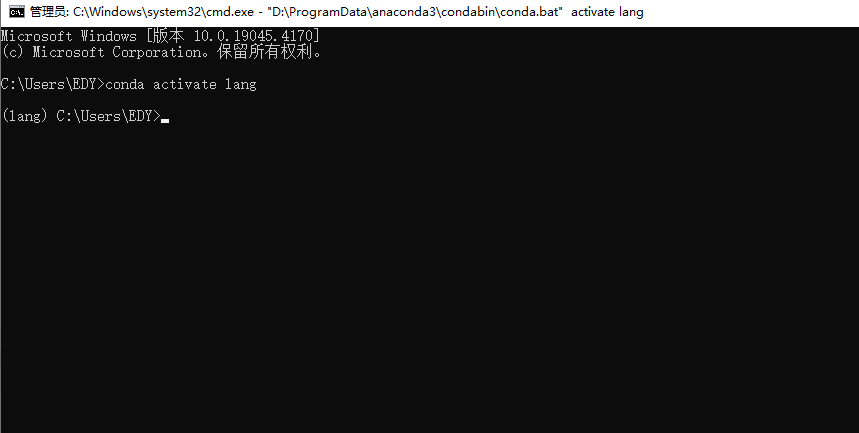
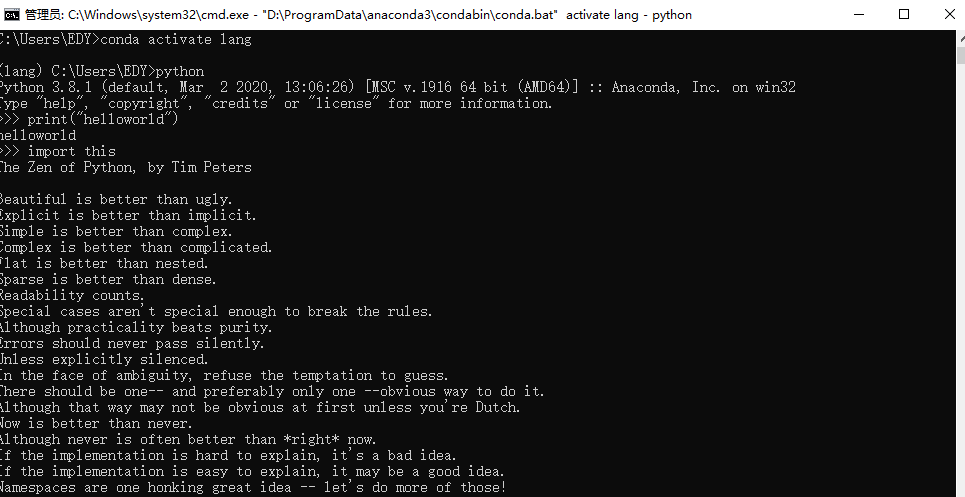
-
脚本式开发
在 pycharm中新建hello.py文件。
print("helloworld!")
注释
单行注释, #
多行注释, 以’‘’ 或者"““开头 ,以’''或者””"结尾
函数
表示一个功能,函数定义者是提供功能的人,函数调用者是使用功能的人。
- print(数据) 作用:将括号中的内容显示在控制台中
print("你好")
print("世界")
- 变量 = input(“需要显示的内容”) 作用:将用户输入的内容赋值给变量
name = input("请输入姓名:")
age = input("请输入年龄:")
print(name + "的年龄是:" + age + ".")
以上两个函数都属于内建函数, 内建函数都属于builtins.py。可以通过help(‘builtins’)查看内建函数的说明。
字符串
python 中被引号(’ '或者" ")包围就是字符串了。
核心编程
2.变量和简单数据类型
2.1 数据
程序运行时需要处理的数据分为两大类:
- 数字型
- 整数
- 浮点数
- 复数
- 字符串型
python中为了支持这些数据的处理,内置了以下的数据类型:
-
int 整型
10, 3, 5, -100
十进制:每位用十种状态计数,逢十进一,写法是0~9。
num01 = 10 二进制:每位用二种状态计数,逢二进一,写法是0b开头,后跟0或者1。
num02 = 0b10
八进制:每位用八种状态计数,逢八进一,写法是0o开头,后跟0~7。
num03 = 0o10 十六进制:每位用十六种状态计数,逢十六进一,写法是0x开头,后跟09,AF,a~f
num04 = 0x10 -
float 浮点型
3.14, 6.18E-1(等同于0.618)
1.23e-2 (等同于0.0123)
-
bool 布尔类型
python内置的bool类型的常量:
True, 1 真
False, 0 假
result = input("请输入您的职业:") == "老师" print(result) # 输入老师,结果True;输入其他,结果False空值 None,是一个特殊的常量,不表示任何类型,通常用来占位
-
complex 复数类型
2+3j
-
str 字符串类型
“hello”, “abc”, ‘123’
-
list 列表
-
tuple 元组
-
dictionary 字典
-
set 集合
2.2 变量
可以理解为标签,记录以上我们讲到的各种类型数据的在内存中的存放位置。
-
定义:关联一个对象的标识符。
-
命名:必须是字母或下划线开头,后跟字母、数字、下划线。
不能使用关键字,否则发生语法错误SyntaxError。
help(‘keywords’)可以显示系统中所有关键字
-
建议命名:字母小写(变量名是区分大小写的), 见名之意, 多个单词以下划线隔开。
-
赋值:创建一个变量或改变一个变量关联的数据。
-
语法:
变量名 = 数据
变量名1 = 变量名2 = 数据
变量名1, 变量名2 = 数据1, 数据2
-
实例
# 创建变量
name01 = "孙悟空"
name02 = "唐僧"
name03 = name01 + name02
# 修改变量
name01 = "悟空"
print(name03)
# 变量赋值变量
name04 = name01
print(name04)
-
删除变量
name01 = "悟空" name02 = name01 del name01, name02del, 用于删除变量,同时解除与对象的关联。如果可能则释放对象。
每个对象记录被变量绑定(引用)的数量,当为0时被销毁。
-
注意:
在python中变量没有类型,但关联的对象有类型。
a = 100 print(type(a)) a = 3.14 print(type(a))
2.3 运算
2.3.1 类型转换
-
转int
int(数据) #example int("33") #33 int(3.14) #3 int(True)#1 -
转float
float(数据) #example float("3.14") float(123) -
转字符串
str(数据) #example str(123) str(3.14) -
转布尔
bool(数据) #example bool(None) #None为空值 返回False bool(1) bool('') #False bool(' ')#True -
混合类型自动升级
print(type(1+1.1)) #升级为精度高的
注意:字符串转换为其他类型时,必须是目标类型的字符串表达形式
print(int("10.5")) # 报错
print(float("abc"))# 报错
练习:在终端中输入商品单价、购买的数量和支付金额。计算应该找回多少钱。
效果:
请输入商品单价:12.3
请输入购买数量:4
请输入支付金额:100
应找回:?
2.3.2 运算符
表达式: Python表达式是运算符和操作数进行有意义排列所得的组合。操作数可以是值、变量、标识符等。单独的一个值或一个变量也是一个表达式。 表达式通常是让计算机做一些事情并且返回结果 。
2.3.2.1 算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 5+3 |
| - | 减 | 5-3 |
| * | 乘 | 5*3 |
| / | 除 | 5/3,结果为1.6666666666666667 |
| // | 地板除 | 5//3, 结果为1 |
| % | 取模,返回除法的余数 | 5%3,结果为2 |
| ** | 幂 | 5**3,结果为125 |
优先级: () > ** > * / % // > ±
练习:古代16两一斤,输入两数,返回古代计数的斤两。
效果:
请输入总两数:100
结果为:6斤4两
num = int(input("请输入两数: "))
jin = num // 16
# liang = num - jin * 16
liang = num % 16
print("古代为:" + str(jin) + "斤" + str(liang) + " 两")
2.3.2.2 赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | z = x+y |
| += | 加法赋值运算符 | x += y 等价于 x = x+y |
| -= | 减法赋值运算符 | x -= y 等价于 x = x-y |
| *= | 乘法赋值运算符 | x *= y 等价于 x = x*y |
| /= | 除法赋值运算符 | x /= y 等价于 x = x/y |
| %= | 取模赋值运算符 | x %=y 等价于 x = x%y |
| **= | 幂赋值运算符 | x **=y 等价于 x = x**y |
| //= | 取整除赋值运算符 | x //=y 等价于 x = x//y |
2.2.2.3 比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | x==y, 相等返回True,不等返回False |
| != | 不等于 - 比较两个对象是否不相等 | x != y , 不等返回True,相等返回False |
| > | 大于 | x > y , 大于返回True,否则返回False |
| < | 小于 | x < y ,小于返回True,否则返回False |
| >= | 大于等于 | x >= y , 大于等于返回True,否则返回False |
| <= | 小于等于 | x <=y ,小于等于返回True,否则返回False |
2.3.2.4 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 | x=10;y=20;x and y返回20 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | x=10;y=20;x and y返回10 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | x=10;y=20;not(x and y)返回False |
重点:
and, 两个参与运算的布尔类型数均为True,结果才为True 并且
结果 = A and B
A B 结果
True True True
False True False
True False False
False False False
or, 两个参与运算的布尔类型数有一个为True, 结果即为True 或者
结果 = A or B
A B 结果
True True True
False True True
True False True
False False False
2.3.2.5 身份运算符
身份运算符用于比较两个对象的存储单元 。
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y,等价于id(x) == id(y) |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y, 等价于id(x) != id(y) |
id()函数用于获取对象的内存地址。
x = 100
y = 100
x is y #返回True
id(x) == id(y) #返回True
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
>>>x = [1, 2, 3]
>>> y = x
>>> y is x
True
>>> y == x
True
>>> y = x[:]
>>> y is x
False
>>> y == x
True
2.3.2.6 位运算符(略)
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符 | |
| | | 按位或运算符 | |
| ^ | 按位异或运算符 | |
| ~ | 按位取反运算符 | |
| << | 左移动运算符 | |
| >> | 右移动运算符 |
2.3.2.7 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x=‘abcd’;y=‘ab’;y in x;返回True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x=‘abcd’;y=‘ab’;y not in x;返回False |
2.2.2.8 运算符优先级
算数运算符>比较运算符>赋值运算符>身份运算符>逻辑运算符
相同优先级一般从左到右运算
不用刻意记忆,如果担心运算符的优先级出错,就多加括号人为控制即可
3.语句
Python程序由各种语句构成。
3.1行
-
物理行:程序员编写代码的行。
-
逻辑行:python解释器需要执行的一个基本单位。
-
建议:一个逻辑行在一个物理行上。如果一个物理行中使用多个逻辑行,需要使用分号;隔开。
-
换行:
如果逻辑行过长,可以使用隐式换行或显式换行。
隐式换行:所有括号的内容换行,称为隐式换行。括号包括: () [] {} 三种
显式换行:通过折行符 \ (反斜杠)换行,必须放在一行的末尾,目的是告诉解释器,下一行也是本行的语句。
# 4个物理行 4个逻辑行
a = 1
b = 2
c = a + b
print(c)
# 1个物理行 4个逻辑行(不建议)
a = 1;b = 2;c = a + b;print(c)
# 4个物理行 1个逻辑行
# -- 换行符
d = 1+\
2+\
3+4\
+5+6
# -- 括号
e = (1+2+
3+4
+5+
6)
3.2 条件语句
3.2.1 if elif语句
作用:让程序根据条件选择性的执行语句。
语法格式:
if 条件1:
语句块1
elif 条件2:
语句块2
else:
语句块3
elif 子句可以有0个或多个。
else 子句可以有0个或1个,且只能放在if语句的最后。
score = int(input("请输入你上次考试成绩:"))
if score == 100:
print("好厉害")
elif score >= 90:
print("很棒")
elif score >= 80:
print("可以更好")
elif score >=60:
print("没有一分是浪费的")
else:
print("一起重修的学妹漂亮吗")
练习1:
中国古代对不同年龄的称谓,
弱冠(20岁),而立(30岁), 不惑(40岁),之命(50岁),花甲(60岁), 古稀(70岁), 耄耋(80岁), 期颐(100岁)
根据输入年龄,打印所处年龄阶段。
age = int(input("请输入你的年龄:"))
if age >=100:
print("期颐之年")
print("羡慕")
print("高寿之人")
elif age >=80:
print("耄耋之年")
elif age >=70:
print("古稀之年")
elif age >=60:
print("花甲之年")
elif age >=50:
print("知天命之年")
elif age >=40:
print("不惑之年")
elif age >=30:
print("而立之年")
elif age >=20:
print("弱冠之年")
else:
print("小屁孩")
3.2.2 真值表达式
if 100:
print("真值")
# 等同于
if bool(100):
print("真值")
3.2.3 条件表达式
语法格式:变量 = 结果1 if 条件 else 结果2
#example
value = 1 if input("请输入性别:") == "男" else 0
作用:根据条件(True/False) 来决定返回结果1还是结果2。
练习:
在终端中输入一个年份,如果是闰年为变量day赋值29,否则赋值28。
闰年条件:年份能被4整除但是不能被100整除,或者年份能被400整除
效果:
请输入年份:2020
2020年的2月有29天
year = 2020
days = 29 if (year%4==0 and year%100 !=0) or year%400 ==0 else 28
print(days)
3.3 循环语句
3.3.1 while语句
语法格式:
while 条件:
# 满足条件执行的语句
else:
# 不满足条件执行的语句
else子句可以省略。
在循环体内用break终止循环时,else子句不执行。
sum = 0
i = 1
while i <= 10:
sum = sum + i
i = i +1
else:
print("循环结束")
print("sum =", sum)
练习1:在终端中循环录入5个成绩,最后打印平均成绩(总成绩除以人数)
i = 0
sum = 0
while i<5:
sum += int(input("请输入一个成绩: "))
i = i + 1
print(sum/i)
练习2:程序产生1个1到100之间的随机数。让玩家重复猜测,直到猜对为止。每次提示:大了、小了、恭喜猜对了,总共猜了多少次。
import random
rd = random.randint(1, 100) #返回的是一个介于1,100 之间的随机数
while True:
guess = int(input("请输入猜测值:"))
if guess == rd:
print("恭喜你猜对了")
break #跳出while循环
elif guess < rd:
print("太小了")
else :
print("太大了")
print("程序结束")
3.3.2 for 语句
作用:用来遍历可迭代对象的数据元素。可迭代对象是指能依次获取数据元素的对象,例如:容器类型。
语法格式:
for 变量 in 可迭代对象:
# 语句块1
else:
# 语句块2
else子句可以省略。
在循环体内用break终止循环时,else子句不执行。
str1 = "helloworld"
for item in str1:
print(item)
for循环中经常会使用到range 函数。
语法格式: range(开始点,结束点,间隔)
作用:用来创建一个生成一系列整数的可迭代对象(也叫整数序列生成器),。
说明: 左闭右开, 默认开始点为0,默认间隔为1
sum = 0
for i in range(1,11):
sum += i
print(sum)
3.4跳转语句
3.4.1 break
作用:跳出当前循环, 循环内的后续代码不再执行
可以让while语句的else部分不执行。
for c in "hello":
if(c == 'l')
break
print(c)
3.4.2 continue
作用:结束本次循环 开始下次循环
# 需求:累加1-100之间能被3整除的数字
# 思想:不满足条件跳过,否则累加.
sum_value = 0
for item in range(1, 101):
if item % 3 != 0:
continue
sum_value += item
print(sum_value)
练习:1到10的奇数的累加和
sum = 0
for i in range(1,11,2): #(1,3,5,7,9)
sum += i
print(sum)
sum = 0
for i in range(1,11):
if i%2 == 0:
continue
sum += i
print(sum)
sum = 0
i = 1
while i<11:
if i%2 == 0:
i += 1
continue
sum += i
i += 1
print(sum)
3.5 空语句
pass, 是空语句,是为了保持程序结构的完整性。 没 做任何事情,一般用做占位语句。
if True:
pass
3.6循环的嵌套
练习:达到以下输出效果,该如何实现

print(“aaa”, end=’ ')
end, 决定输出完前面的字符串,追加输出的一个字符。 默认追加输出的是’\n’ (换行符)
for i in range(0,5):
for j in range(1, 11):
print(j, end=' ')
print()
i = 1
while i<6:
j = 1
while j<11:
print(j, end = ' ')
j += 1
print() #输出换行符
i += 1
4.容器类型
列表、元组、字符串属于序列容器,字典、集合属于映射容器。
4.1通用操作
4.1.1 数学运算符
-
+:用于拼接两个序列容器
-
+=:用原容器与右侧容器拼接,并重新绑定变量
-
*:重复生成容器元素
-
*=:用原容器生成重复元素, 并重新绑定变量
-
< <= > >= == !=:依次比较两个容器中元素,一但不同则返回比较结果。
l1 = list(range(1,11))
print(l1)
l2 = list("abcd")
l1 += l2
print(l1)
print(l1*3)
print(l1 == l2)
4.1.2 成员运算符
- in
- not in
作用:判断指定的元素是否在容器对象中, 返回bool类型
print("abc" in "helloworld") #False
print("abc" not in "helloworld") #True
4.1.3 索引index
给容器中每个元素一个编号,方便检索访问。
语法格式: 容器[整数]
正向索引从0开始,第二个索引为1,最后一个为len(s)-1。
反向索引从-1开始,-1代表最后一个,-2代表倒数第二个,以此类推,第一个是-len(s)。
message = "你好python"
print(message[2]) #
print(message[-2]) #
print(len(message)) #
# 注意:索引不能越界IndexError
# print(message[99])
# print(message[-99])
4.1.4 切片slice
作用:访问序列容器中的多个元素
语法:序列容器[开始索引:结束索引:步长]
说明:
结束索引不包含该位置元素,左闭右开
步长是切片每次获取完当前元素后移动的偏移量
开始、结束和步长都可以省略
message = "hello python"
print(message[2:5:1]) #
print(message[1: 5]) #
print(message[2:-4]) #
print(message[:-4]) #
print(message[:]) #
print(message[-3:]) #
print(message[:2]) #
print(message[-2:]) #
print(message[-2: 3:-1]) #
print(message[1: 1]) #
print(message[2: 5:-1]) #
# 特殊:翻转
print(message[::-1]) #
练习:
字符串: content = “忘掉今天的人将被明天忘掉”
1) 打印第一个字符、打印最后一个字符、打印中间字符
2)打印前三个符、打印后三个字符
3)判断’今天’是否在content中
4)切片打印’今天的人’
5)切片打印’忘今的将明忘’
- 倒序打印字符
4.1.5 内建函数
-
len(x) 返回序列的长度
-
max(x) 返回序列的最大值元素
-
min(x) 返回序列的最小值元素
-
sum(x) 返回序列中所有元素的和(元素必须是数值类型)
4.2 列表list
是由一系列变量组成的可变序列容器。
help(list)
4.2.1 基础操作
-
创建列表
#方式一 列表名 = [数据1, 数据2] names = ['张三', '李四', '王五'] ages = [] #空列表 #方式二 列表名 = list(可迭代对象) alpha = list("abcdefghijklmn") -
添加元素
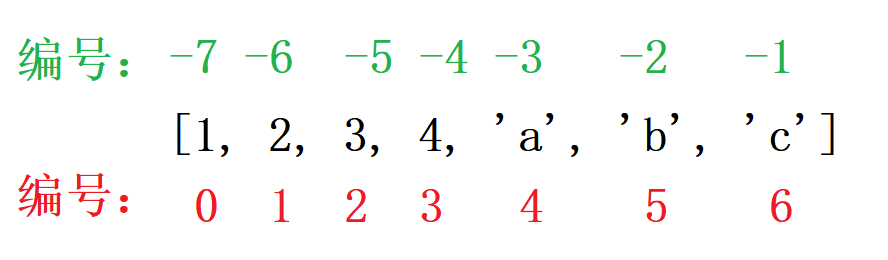
alpha.append('o') alpha.insert(1, 'A') -
定位元素
print(alpha[2])#读取 #切片 列表名[start:end:step] ALPHA = alpha[:5] #切片访问会创建一个新的列表对象 ALPHA[0] = '1' #修改 ALPHA[1:3]=['2', '3']切片访问的语法:列表名[start:stop:step ] 左闭右开
l2 = [1, 'A', 2, 3, 4, 'a', 'b', 'C'] print(l2[2:5]) #[2,3,4] print(l2[2:]) #[2, 3, 4, 'a', 'b', 'C'] print(l2[-4:-1]) #[4, 'a', 'b'] print(l2[-1:-4:-1])#[4, 'a', 'b'] print(l2[2::2]) #[2, 4, 'b'] -
遍历列表
for c in alpha: print(c) i=0 while i<len(alpha): print(alpha[i]) i += 1 for i in range(len(alpha)-1, -1, -1): #逆序 print(alpha[i]) -
删除元素
#方式一: 按元素删除 alpha = list("abcdefghijklmn") alpha.remove('a') #方式二: 按索引/切片删除 del alpha[0] del alpha[:6] print(alpha)
练习: 建立一个班级学生姓名列表,尝试插入新学生,删除部分学生
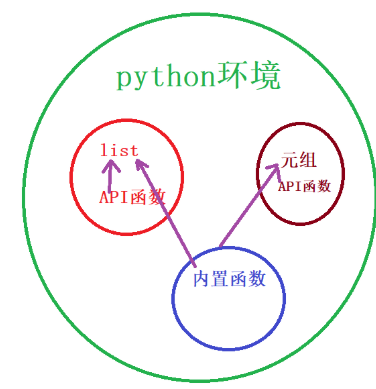
4.2.2 列表中提供的API函数
l1 = ['a', 'b', 'c']
l1.append('d') #['a', 'b', 'c', 'd']
l2 = l1.copy() #['a', 'b', 'c', 'd']
print(l1.count('a'))
l1.insert(1, '123')
print(l1) #['a', '123', 'b', 'c', 'd']
l1.extend(('123')) #
print(l1) #['a', '123', 'b', 'c', 'd', '1', '2', '3']
print(l1.index('123')) #1
print(l1.pop()) #3
print(l1) #['a', '123', 'b', 'c', 'd', '1', '2']
l1.reverse() #逆序
print(l1) #['2', '1', 'd', 'c', 'b', '123', 'a']
print(len(l1)) #7
l1.clear() #[]
4.2.3 深拷贝和浅拷贝
浅拷贝:复制过程中,只复制一层变量,不会复制深层变量绑定的对象的复制过程。
深拷贝:复制整个依赖的变量。
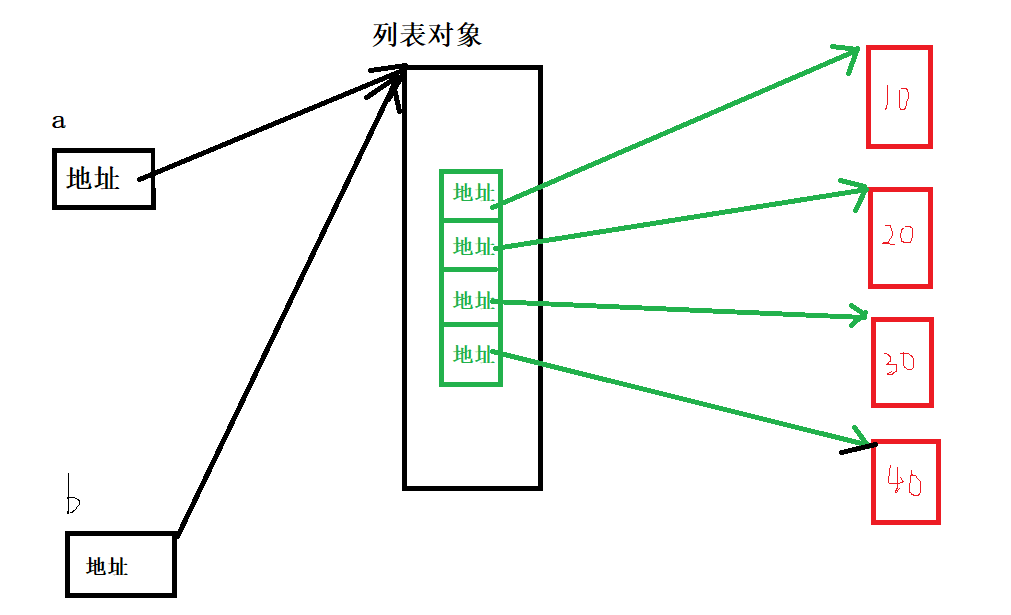
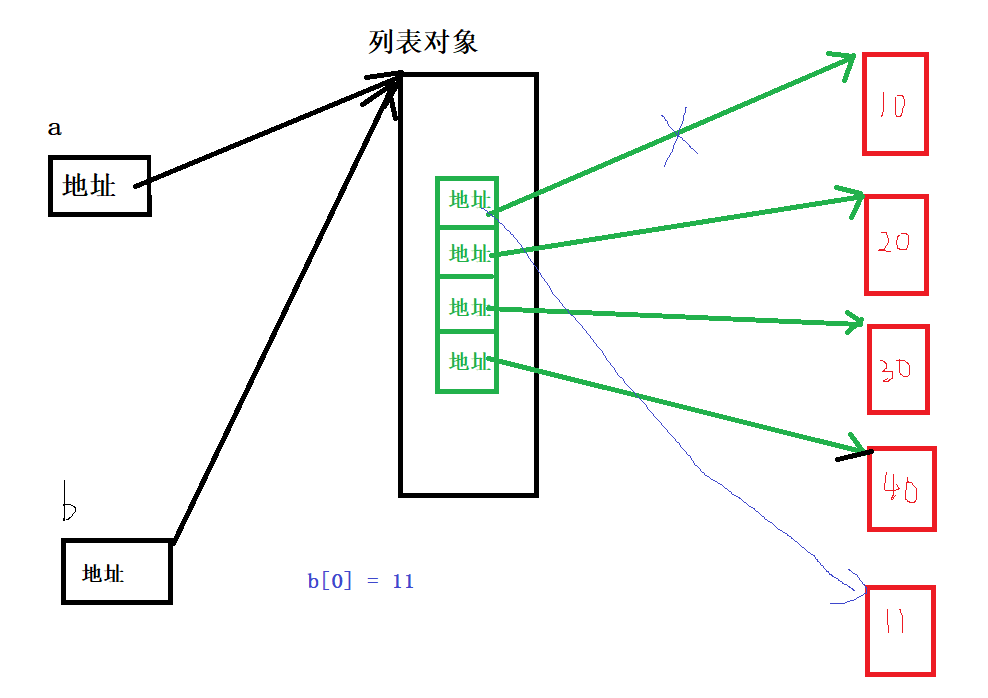
a = list(range(10,50,10))
b = a
b[0] = 11
print(a)#[11, 20, 30, 40]?
a = 10
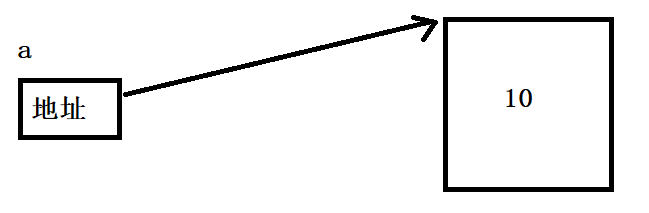
a = 10
b = a
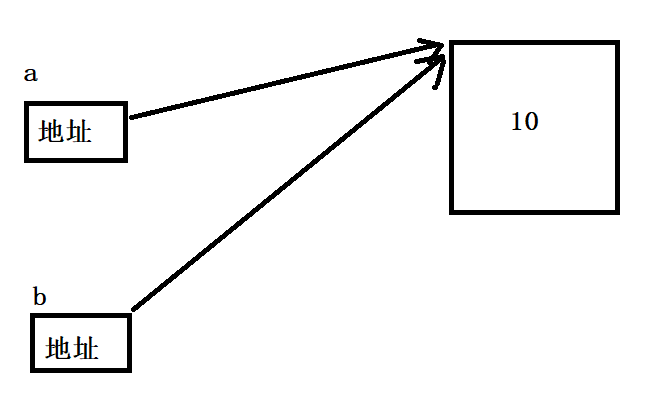
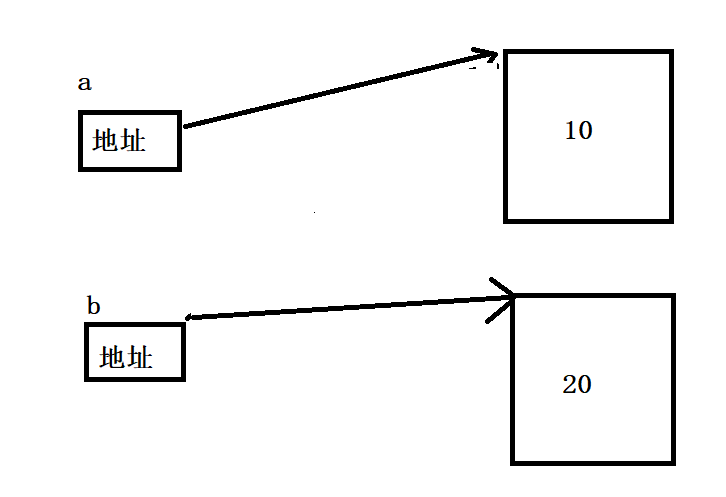
a = 10
b = a
b = 20
a = list(range(10,50,10))
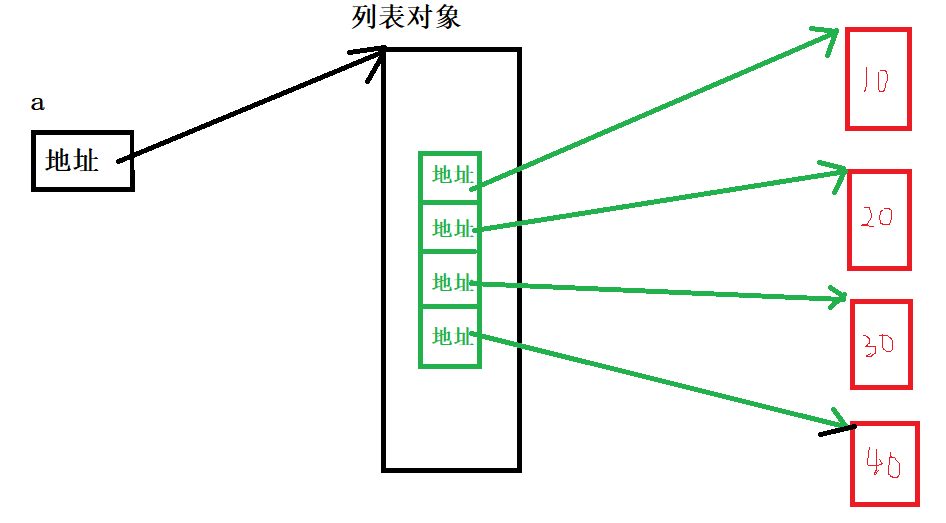
a = list(range(10,50,10))
b = a
a = list(range(10,50,10))
b = a
b[0] = 11
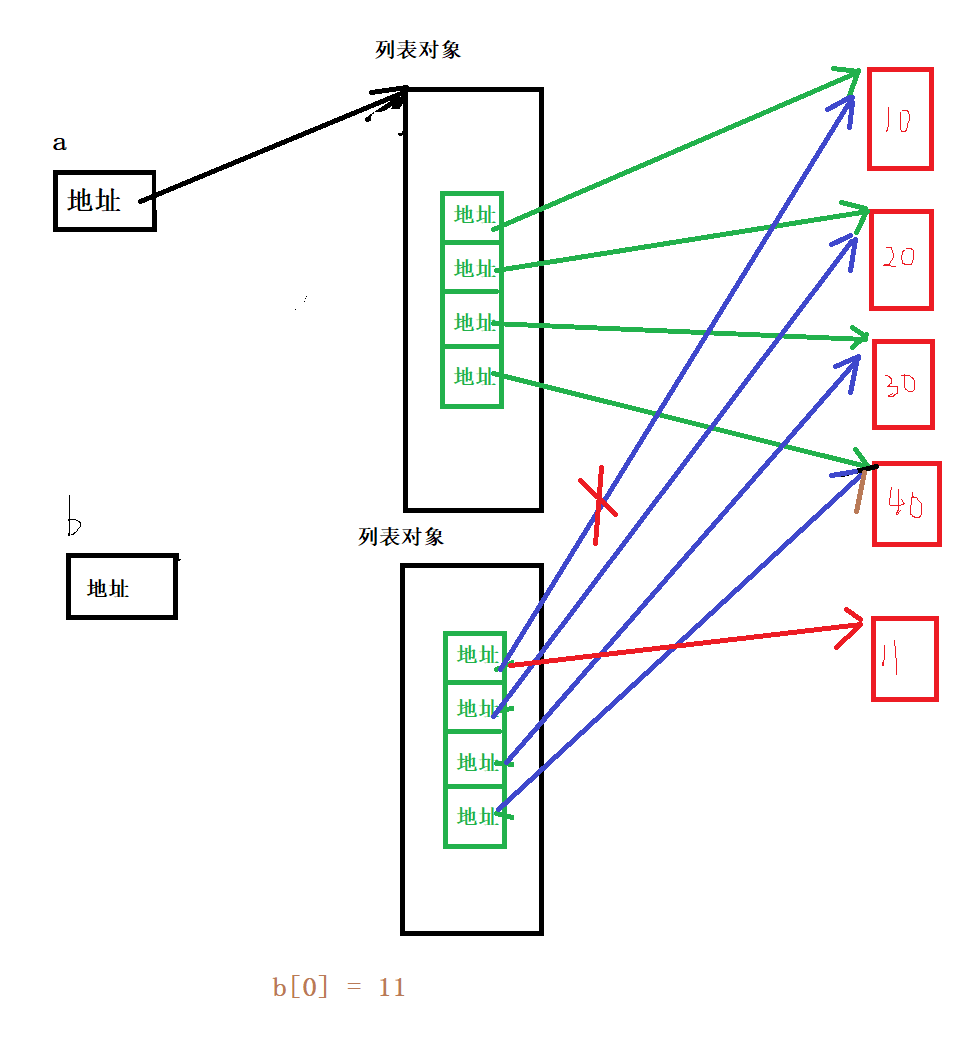
a = list(range(10,50, 10))
print(a)
b = a[:] #拷贝
b[0] = 11
print(a)
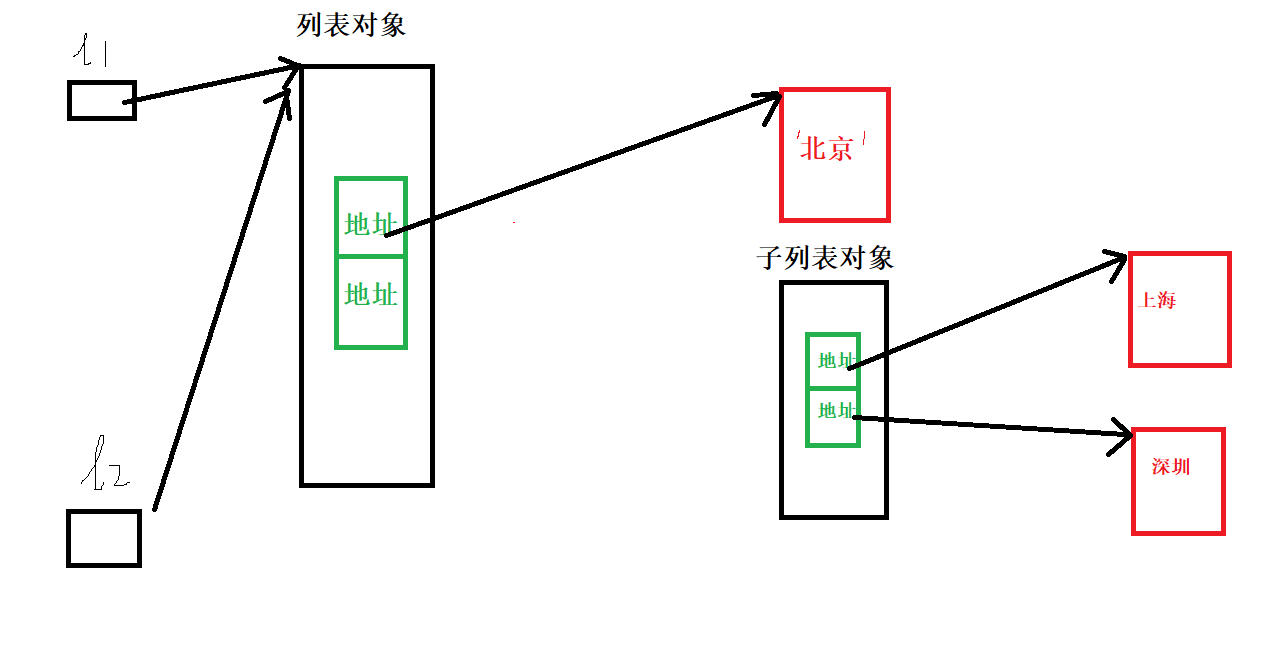
l1 = ['北京', ['上海', '深圳']]
# print(len(l1))
l2 = l1
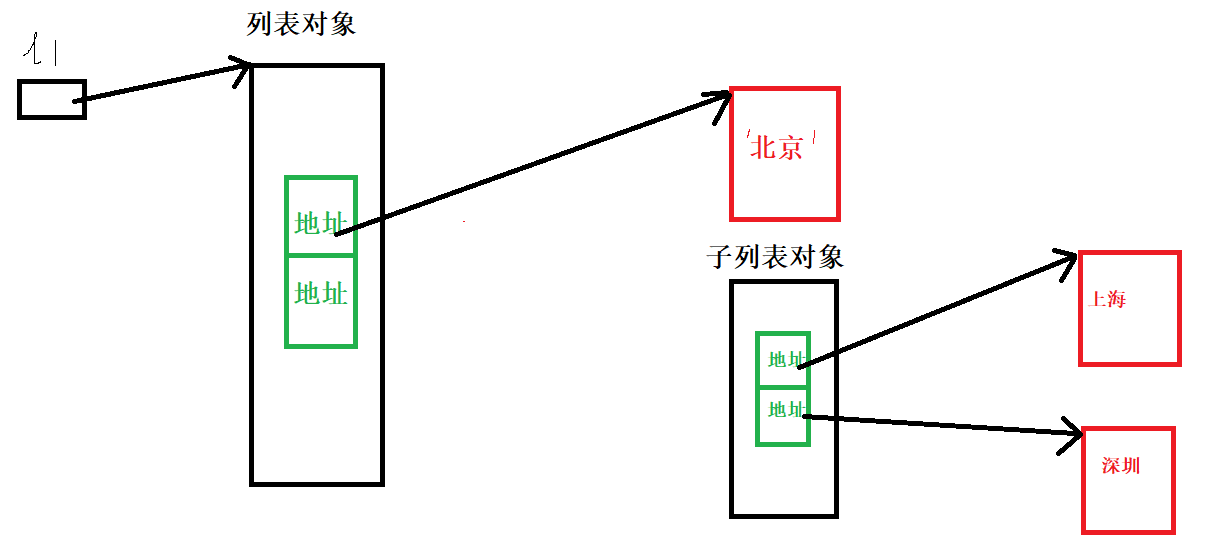
l1 = ['北京', ['上海', '深圳']]
# print(len(l1))
l2 = l1
l2[0] = '首都'
print(l1) #['首都', ['上海', '深圳']]
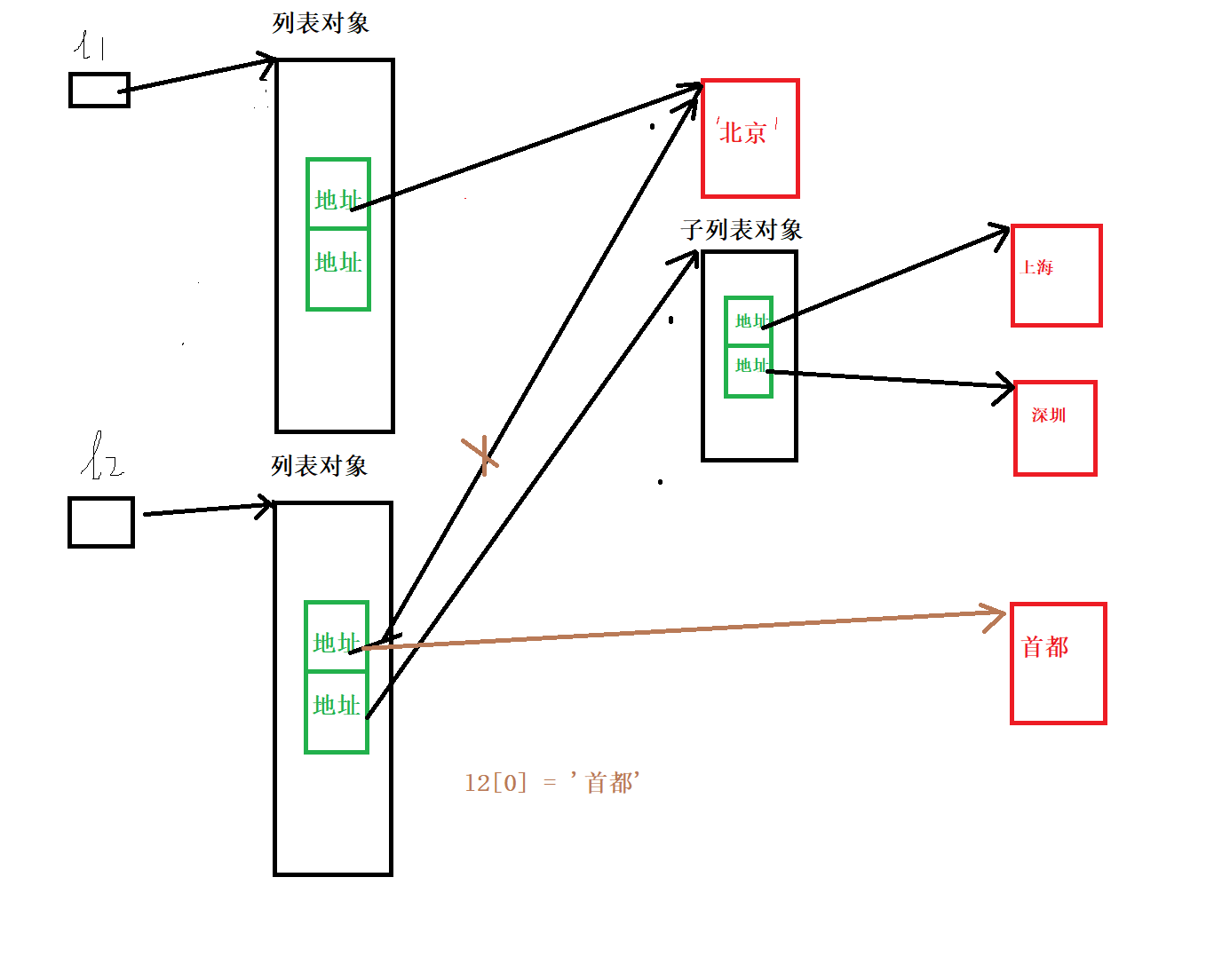
l1 = ['北京', ['上海', '深圳']]
# print(len(l1))
l2 = l1[:] #拷贝
l2[0] = '首都'
print(l1) #['北京', ['上海', '深圳']]
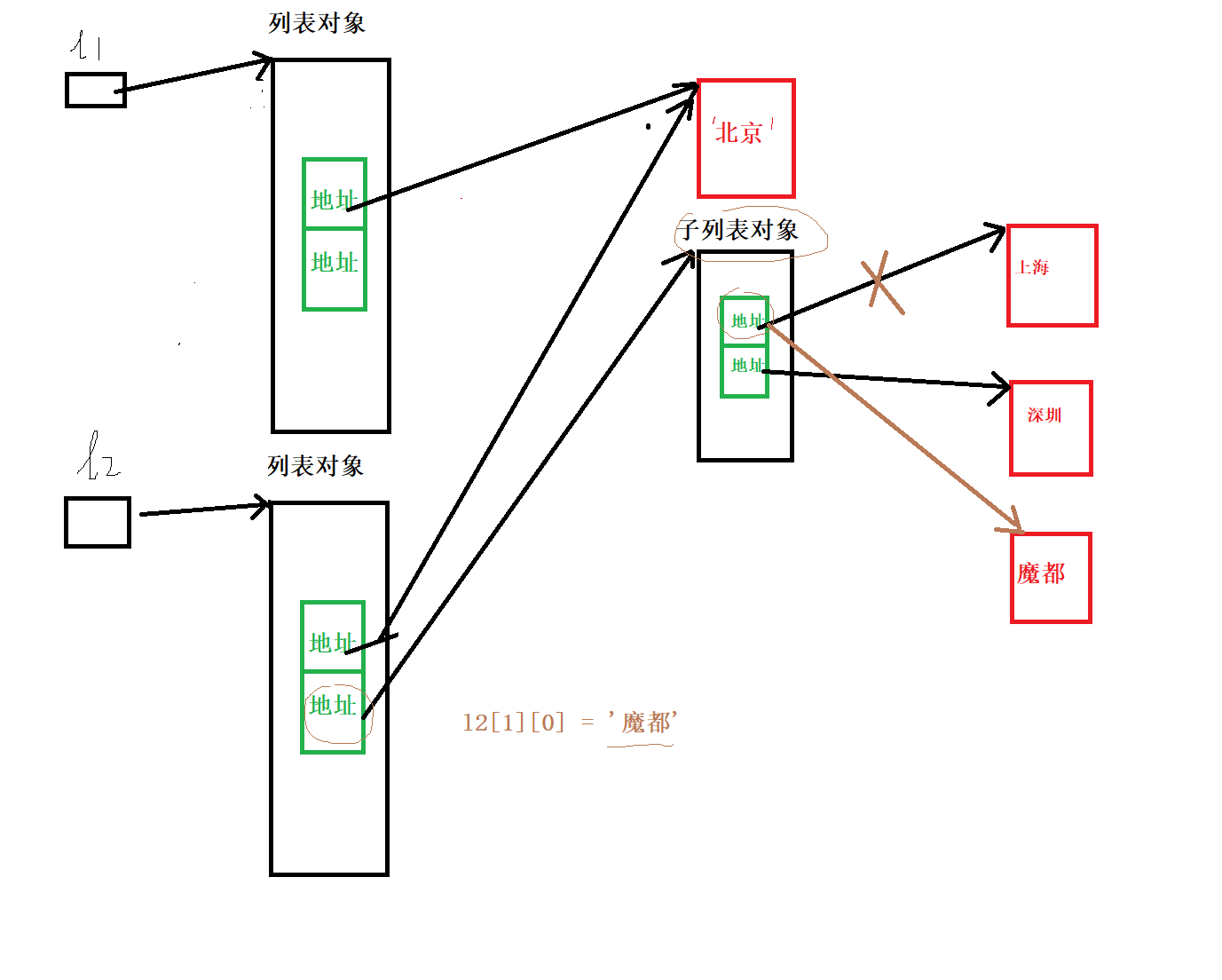
l1 = ['北京', ['上海', '深圳']]
# print(len(l1))
l2 = l1[:] #浅拷贝
l2[1][0]= '魔都'
print(l1) #['北京', ['魔都', '深圳']]
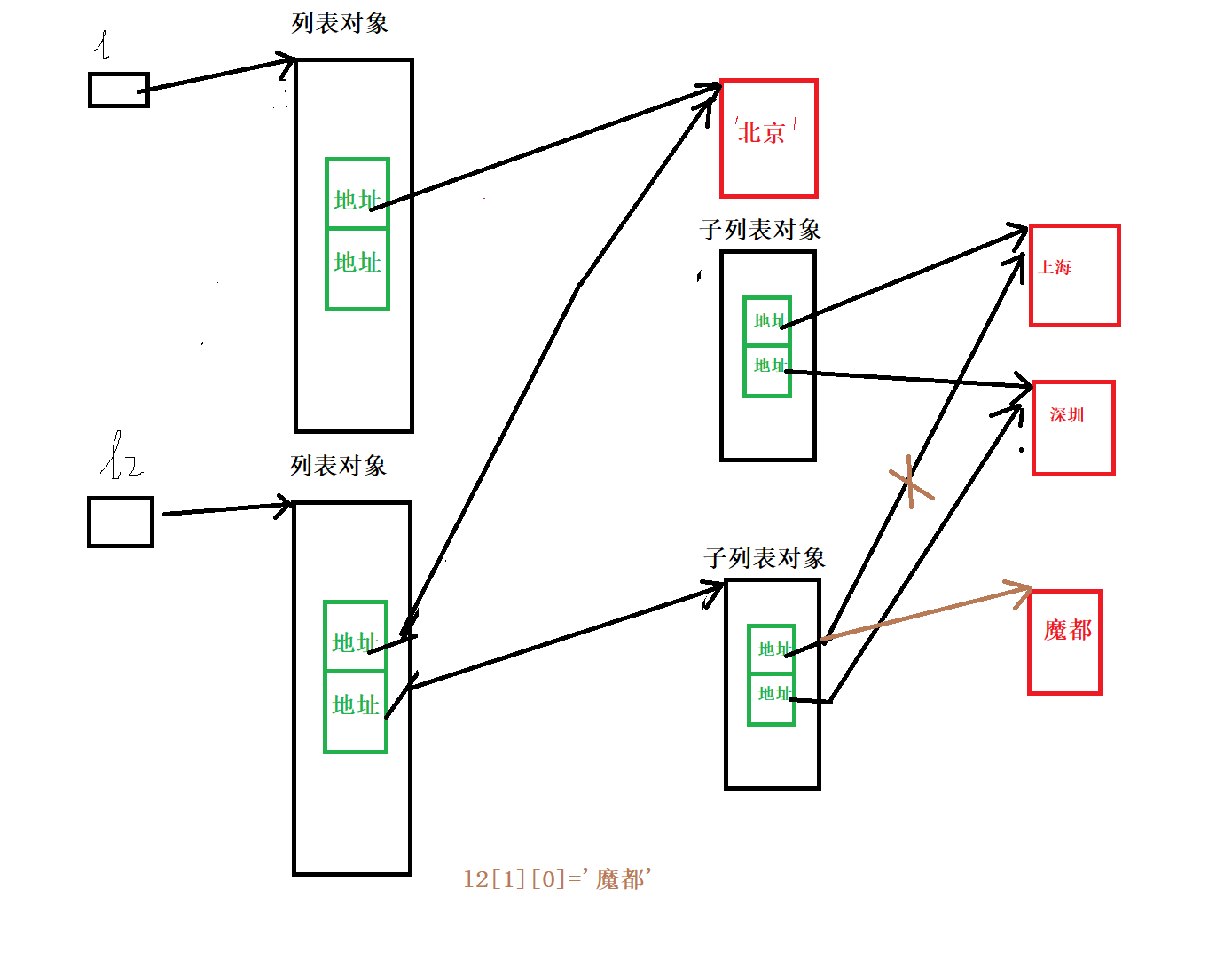
import copy
l1 = ['北京', ['上海', '深圳']]
# print(len(l1))
l2 = copy.deepcopy(l1) #深拷贝
l2[1][0]= '魔都'
print(l1) #['北京', ['上海', '深圳']]
4.2.4 列表推导式
定义:使用简易方法,将可迭代对象转换为列表。
语法:
列表名称 = [表达式 for x in 可迭代对象 ]
列表名称 = [表达式 for x in 可迭代对象 if 条件表达式] #条件表达式为False的元素会被放弃
l1 = list(range(1,101))
print(l1)
#l1中每个元素+10后放入l2列表
# l2 = []
# for i in l1:
# l2.append(i+10)
#
# print(l2)
l2 = [x+10 for x in l1]
print(l2)
#l1 中奇数放入l3列表中
l3 = [x for x in l1 if x%2 !=0]
print(l3)
练习:
生成10–30之间能被3或者5整除的数字的列表
[10, 12, 15, 18, 20, 21, 24, 25, 27]
生成5 – 20之间的数字平方的列表
[25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361]
列表推导式嵌套:
列表名= [关于x和y的表达式 for x in 可迭代对象1 for y in可迭代对象2]
l1 = list(range(1,101))
print(l1)
#l1中每个元素+10后放入l2列表
# l2 = []
# for i in l1:
# l2.append(i+10)
#
# print(l2)
l2 = [x+10 for x in l1]
print(l2)
#l1 中奇数放入l3列表中
l3 = [x for x in l1 if x%2 !=0]
print(l3)
l4 = ['a', 'b', 'c']
l5 = ['A', 'B', 'C']
# l6 = []
# for m in l4:
# for n in l5:
# l6.append(m+n)
l6 = [m+n for m in l4 for n in l5]
print(l6)
4.3元组 tuple
由一系列数据组成的不可变序列容器。不可变是指一但创建,不可以再添加/删除/修改元素。
4.3.1 基本操作
help(tuple)
-
创建元组
#方式一 元组名 = (元素1, 元素2, 元素3) t1 = (10,20,30) #方式二 元组名 = tuple( 可迭代对象 ) t2 = tuple("abcdefg") t3 = tuple(range(10)) t4 = tuple(['A', 'B', 'C']) -
获取元素

#变量 = 元组名[索引] x = t1[0] #变量 = 元组名[切片] 元组[start:stop:step] #创建方式二 t2 = tuple("abcdefg") print(t2[3]) print(t2[:5]) print(t2[2:])#('c', 'd', 'e', 'f', 'g') print(t2[::-1])#('g', 'f', 'e', 'd', 'c', 'b', 'a') print(t2[:-4:-1])#('g', 'f', 'e') -
遍历元组
t2 = tuple("abcdefg") for c in t2: print(c) for i in range(len(t2)): print(t2[i]) i = len(t2) -1 while i >= 0: print(t2[i]) i -= 1
4.3.2 元组中提供的API函数
help(tuple)
t = (1,2,3,3,5,8,3,3)
print(t.count(3)) #统计指定元素在元组中出现的次数
print(t.index(3)) #查找指定的元素在元组中第一次出现的位置 返回对应索引
print('t 中元素的个数: ', len(t))
print('t 中元素的最大值: ', max(t))
print('t 中元素的和值:', sum(t))
4.3.3 注意事项
-
小括号可以省略
t = 1,2,3 print(type(t)) -
如果元组中只有一个元素,必须有逗号
t = (10,) print(type(t)) -
拆包: 多个变量 = 容器
t = 1,2,3 a,b,c = t print(f'{a} {b} {c}') *a,b = t print(f'{a} {b}')
练习:
根据给定的年月日,计算是这一年的第几天。
year = input('请输入年份:') #2024 "2024" ---->2024
year = int(year)
month =int(input('请输入月份: '))
day = int(input('请输入日:'))
days = (31,28,31,30,31,30,31,31,30,31,30,31)
sum = 0
#整月天数累加
for i in range(1, month): #(1,2,.... month-1)
sum += days[i-1]
#不够1个月的天数
sum += day
if month > 2:
if (year%4==0 and year%100 !=0) or year%400==0:
sum += 1
print(f'{year}年{month}月{day}日是该年中第{sum}天')
4.4 字符串str
由一系列字符组成的不可变序列容器,存储的是字符的编码值。
4.4.1 字符编码
我们看到的计算机中显示的每一个字符(英文、汉字、标点符号…)在计算机都有一个编号(编码)。
- ASCII编码:包含英文、数字等字符,每个字符1个字节。
- GBK编码:兼容ASCII编码,包含21003个中文;英文1个字节,汉字2个字节。
- Unicode字符集:国际统一编码,旧字符集每个字符2字节,新字符集4字节。
- UTF-8编码:Unicode的存储与传输方式,英文1字节,中文3字节。
题外话:字节byte:计算机最小存储单位,等于8 位bit。
python内置函数可以实现字符和Unicode码的相互转换。
- ord(字符):返回该字符串的Unicode码。
- chr(整数):返回该整数对应的字符。
练习:
1)在终端中录入一个内容,循环打印每个文字的编码值,直到输入quit.
while True:
content = input("请输入字符串: ")
if content == 'quit':
break
for c in content:
print(f'{c} 对应的unicode编码值为: ', ord(c))
2) 循环录入编码值打印文字,直到输入空字符串停止。
4.4.2 字面值
-
单引和双引号的区别
-
单引号内的双引号不算结束符
print('abc"123"')#abc"123" -
双引号内的单引号不算结束符
print("i'am ok") #i'am ok
-
-
三引号作用
- 允许一个字符串跨多行
- 三引号内可以包含单引号和双引号
- 作为文档字符串
4.4.2.1 转义字符
为了在字符串中写入某些特殊字符,我们引入了转义字符。转义字符是 Python 中具有特殊含义的字符,以 \ 开头。下面总结了常用的转义字符。
| 转义字符 | 描述 | 实例 |
|---|---|---|
| \(出现在行尾时) | 续行符 | >>> print(“line1 \ … line2 \ … line3”) line1 line2 line3 >>> |
| \\ | 反斜杠符号 | >>> print(“\”) \ |
| \’ | 单引号 | >>> print(‘’‘) ’ |
| \" | 双引号 | >>> print(“”“) ” |
| \b | 退格(Backspace) | >>> print(“Hello \b World!”) Hello World! |
| \000 | 空 | >>> print(“\000”) >>> |
| \n | 换行 | 光标去到下一行 |
| \r | 返回光标至首行 | |
| \t | 横向制表符 | >>> print(“Hello \t World!”) Hello World! >>> |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | print(“\110\145\154\154\157\40\12 7\157\162\154\144\41”) #Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | print(“\x48\x65\x6c\x6c\x6f\x20\x5 7\x6f\x72\x6c\x64\x21”) #Hello World! |
取消转义:原始字符串
a = r"C:\newfile\test.py"
4.4.2.2 字符串格式化
-
方式一
print ("我叫 %s 今年 %d 岁!" % ('小明', 10)) #我叫 小明 今年 10 岁!python字符串格式化符号
符 号 描述 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %u 格式化无符号整型 %o 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化浮点数字,可指定小数点后的精度 %e 用科学计数法格式化浮点数 %E 作用同%e,用科学计数法格式化浮点数 %p 用十六进制数格式化变量的地址 -
方式二
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去
name='小明' age=15 print(f'我叫 {name} 今年 {age+1} 岁')用了这种方式明显更简单了,不用再去判断使用 %s,还是 %d。
-
方式三
还有更复杂的格式化输出控制 str.format,略过。
4.4.3 字符串的切片访问

#切片访问语法: str[start:stop:step]
str1 = "abcdefghijklmn"
print(str1[0])
print(str1[len(str1)-1])
print(str1[-1])
print(str1[2:-1])
print(str1[::2])
print(str1[::-1])
#str1[0] = 'A' #语法错误 字符串属于不可以修改的序列容器
4.4.4 字符串的数学运算
l1 = [1,2,3]
t1 = (1,2,3)
s1 = '123'
print(l1 + [4])
print(t1 + (4,))
print(s1 + '4')
l1 += [4]
print(l1)
t1 += (4,) # (1,2,3) + (4,) 会形成一个新的元组, 让t1绑定到新的元组
print(t1)
s1 += '4'
print(s1)
print(l1 * 2)
print(t1 * 2)
print(s1 * 2)
print(s1 != "12344")
print(l1 == [3,4,5])
print(t1 == (1,3))
4.4.5 字符串API函数
字符串的内建函数非常多,提供了丰富的功能。
具体可以通过help(str)查询, 或者查看library.pdf文档
count(sub[, start[, end]]) #查找子串
endswith(suffix[, start[, end]]) #判断字符串是否以指定的字串结尾
find(sub[, start[, end]]) #查找字串出现的索引位置
lower(self, /) # 变成小写
upper(self, /) # 变成大写
join(self, iterable, /) #拼接字符串
split(self, /, sep=None, maxsplit=-1) #拆分字符串
s1 = "abcdaefga"
print(s1.count("a"))
print(s1.count('a', 0, 5))
print(s1.count("abc"))
print(s1.endswith("fga"))
print(s1.find("da"))
print(s1.upper())
- 列表转换为字符串
list01 = ["a", "b", "c"]
result = "-".join(list01)
print(result)#a-b-c
-
字符串转换为列表
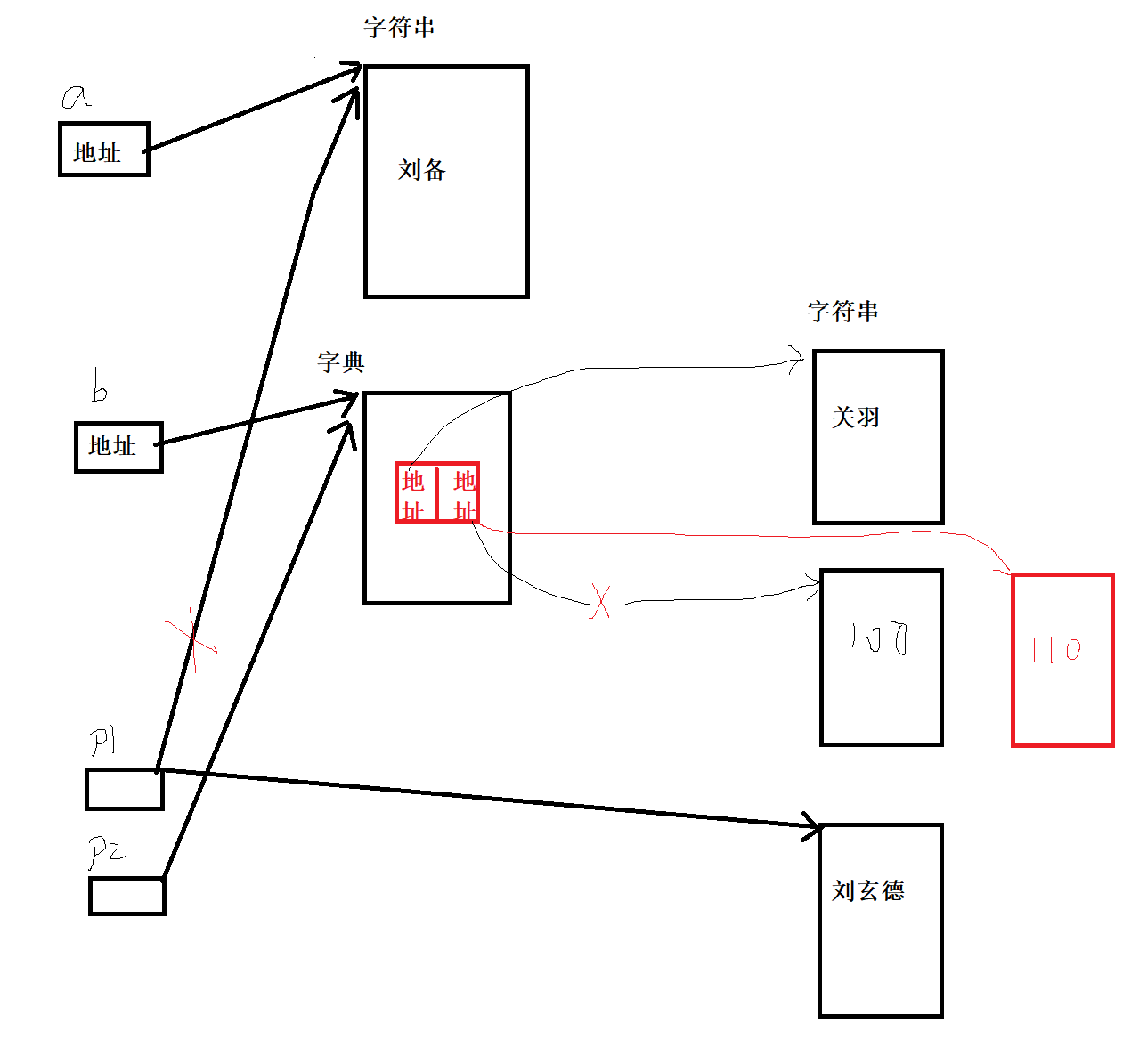
# 使用一个字符串存储多个信息 list_result = "刘备,关羽,张飞".split(",") print(list_result)
练习:
在终端中,循环录入字符串,如果录入了’quit’则结束录入,并以’_'拼接录入的所有内容.
'''
在终端中,循环录入字符串,如果录入了'quit'则结束录入,并以'_'拼接录入的所有内容.
'''
content = []
while True:
item = input("请输入字符串: ")
if item != 'quit':
content.append(item)
else :
break
str1 = '_'.join(content)
print(f'用户输入:{str1}')
练习:将下列英文语句按照单词进行翻转.
转换前: God gives us evil at the same time, also give us conquer evil weapons.
转换后:weapons. evil conquer us give also time, same the at evil us gives God
转换前:友谊就是栖于两个身体中的同一灵魂
转换后:魂灵一同的中体身个两于栖是就谊友
str1 = 'God gives us evil at the same time, also give us conquer evil weapons.'
# print(len(str1))
# print(str1[::-1])
l1 = str1.split(' ')
print(l1)
l2 = []
for i in l1:
l2.insert(0, i)
print(l2)
str2 = ' '.join(l2)
print(str2)
str3 = '友谊就是栖于两个身体中的同一灵魂'
l3 = list(str3)
print(l3)
l3.reverse() # 逆序
print(l3)
str4 = ''.join(l3)
print(str4)
4.5 字典 dict
定义:
(1) 由一系列键值对组成的可变散列容器。
(2) 键必须惟一且不可变(字符串/数字/元组),值没有限制。
语法格式:
字典名称 = {键1:值1, 键2:值2}
4.5.1 基础操作
help(dict)
-
创建字典
#方式一:{ 键1:值1, 键2:值2 } dict_lb = {"name":"刘备", "age":32, "sex":"男"} dict_gy = {"name":"关羽", "age":30, "sex":"男"} dict_zf = {"name":"张飞", "age":28, "sex":"男"} dict_empty = {} #方式二:dict( [( , ),( , )] ) , 列表元素必须能够"一分为二" d1 = dict([("age",20),("name",1)]) -
修改、添加元素
dict_lb["age"] = 35 #已有的key 就是修改 dict_lb["salary"] = 10000 #未有的key 就是添加 -
获取元素
#字典不能索引、切片 print(dict_lb["name"]) # 注意:如果没有键则报错 if "name" in dict_lb: print(dict_lb["name"]) -
遍历字典
dict_lb = {"name":"刘备", "age":32, "sex":"男"} for key in dict_lb: print(key) for key in dict_lb.keys(): print(key) for value in dict_lb.values(): print(value) for key, value in dict_lb.items(): print(key, value) -
删除元素
del dict_lb['sex'] del dict_lb #删除整个字典变量
4.5.2 字典API函数
字典作为映射容器,它是不支持数学运算、不支持索引、切片访问的。
支持in / not in 成员运算符。
clear()#清除字典中的元素
copy() #拷贝字典 注意是浅拷贝
get(key) #返回key对应的value
items() #返回所有的键值对
keys() #返回所有的key
vlaues() #返回所有的value
update()#更新字典
import copy
d1 = {1:'a', 2:'b', 3:'c'}
print(d1)
d1.clear()
print(d1)
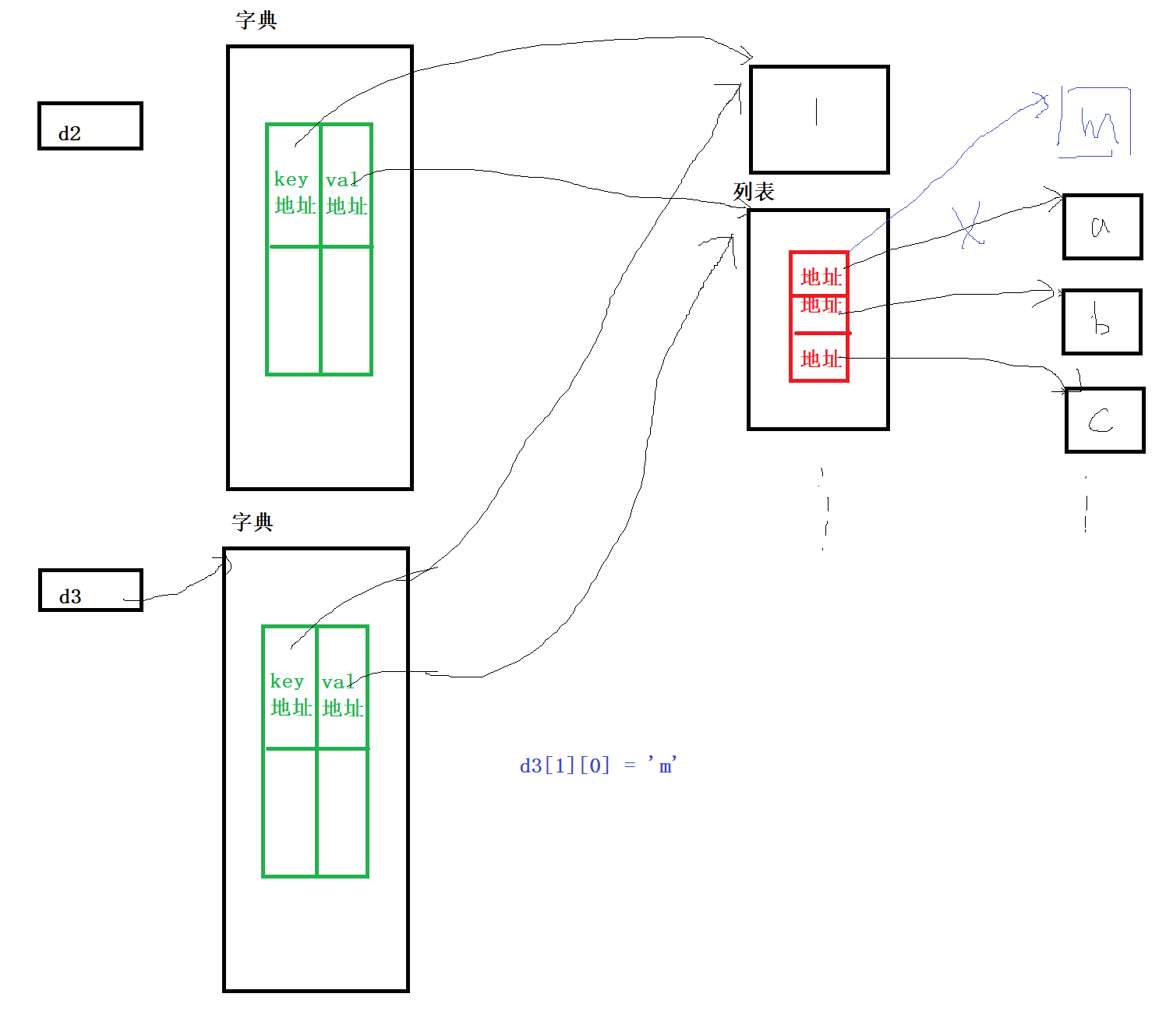
d2 = {1:['a','b','c'], 2:['A', 'B', 'C']}
d3 = d2.copy() #浅拷贝
d3[1][0] = 'm'
print(d2)
d4 = copy.deepcopy(d2)
d4[1][0] = 'n'
print(d2)
print(d4.get(2))
d4.update({3:{'name': "zhangsan"}})
print(d4)
4.5.2 字典推导式
使用简易方法,将可迭代对象转换为字典。
语法:
{键:值 for 变量 in 可迭代对象}
{键:值 for 变量 in 可迭代对象 if 条件}
name = ['zhangsan', 'lisi', 'wangwu', 'zhaoliu']
sign = ['双鱼座', '天蝎座', '水瓶座', '巨蟹座']
dict1 = {name: value for name, value in zip(name, sign)}
print(dict1)
for m, n in zip('123', 'ABC'):
print(m , ':' , n)
l1 = ['zs', 'ls', 'ww', 'zl']
l2 = list(range(20,24))
d1 = {key:val for key, val in zip(l1, l2)}
print(d1)
4.6 集合 set
由一系列不重复的不可变类型变量(元组/数/字符串)组成的可变散列容器,相当于只有键没有值的字典。
其实python还支持一种叫做冰冻集合的数据类型(forzenset), 不可以修改,不在我们的讨论范围内。
4.6.1 基础操作
help(set)
-
创建集合
#方式一 集合名 = {元素1,元素2,元素3} s1 = {1,2,3} #方式二 集合名 = set(可迭代对象) t1 = tuple(range(10)) s1 = set(t1) print(s1) s2 = set()#空集合 -
添加元素
s1.add(100) -
遍历集合
#无序,不能索引 切片 for item in s1: print(item) -
删除元素
s1.remove(100)
#创建集合
s1 = {1,2,3,3,2}
print(type(s1))
print(s1)
t1 = range(10)
s2 = set(t1)
print(s2)
s3 = set()
print(type(s3))
l1 = ['a','b','c'] * 30
s4 = set(l1)
print(len(s4))
s4.add('d')
print(s4)
s4.remove('a')
print(s4)
for i in s4:
print(i)
4.6.2 运算
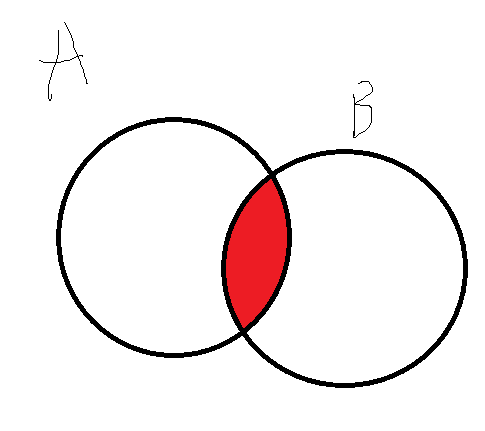
- 交集&:返回共同元素。
s1 = {1, 2, 3}
s2 = {2, 3, 4}
s3 = s1 & s2 # {2, 3}
#print(s1.intersection(s2))
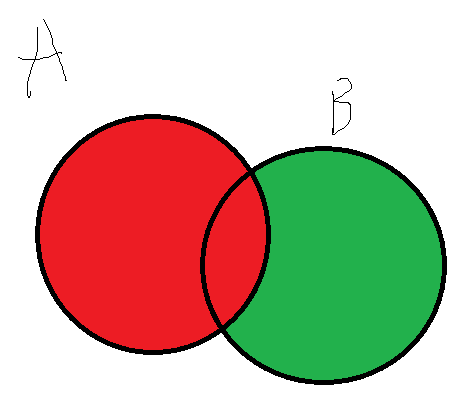
- 并集|:返回不重复元素
s1 = {1, 2, 3}
s2 = {2, 3, 4}
s3 = s1 | s2 # {1, 2, 3, 4}
- 补集-:返回只属于其中之一的元素
s1 = {1, 2, 3}
s2 = {2, 3, 4}
s1 - s2 # {1} 属于s1但不属于s2
- 补集^:返回不同的的元素
s1 = {1, 2, 3}
s2 = {2, 3, 4}
s3 = s1 ^ s2 # {1, 4} 等同于(s1-s2 | s2-s1)
- 子集<:判断一个集合的所有元素是否完全在另一个集合中
- 超集>:判断一个集合是否具有另一个集合的所有元素
s1 = {1, 2, 3}
s2 = {2, 3}
s2 < s1 # True
s1 > s2 # True
- 相同或不同== !=:判断集合中的所有元素是否和另一个集合相同。
s1 = {1, 2, 3}
s2 = {3, 2, 1}
s1 == s2 # True
s1 != s2 # False
4.6.3 集合推导式
{ 表达式 for 变量 in 可迭代对象 }
{ 表达式 for 变量 in 可迭代对象 if 条件语句 }
{ 表达式 for 变量1 in 可迭代对象1 for 变量2 in 可迭代对象2 if 条件语句}
varset = {1,2,3,4}
newset = {i<<2 for i in varset if i%2==0}
print(newset) # {8, 16}
varsl = {1,2,3}
vars2 = {4,5,6}
newset = {i+j for i in varsl for j in vars2 if i%2==0 and j%2==0}
print(newset) # {8, 6}
案例:
l1 = list(range(10))
s1 = {x+1 for x in l1}
print(s1)
s2 ={x for x in s1 if x>5}
print(s2)
s3 = {x+y for x in s1 for y in s2}
print(s3)
s4 = set()
for x in s1:
for y in s2:
s4.add(x+y)
print(s4)
5. 函数 function
函数, 用于封装一个特定的功能,表示一个功能或者行为。
函数是可以重复执行的语句块, 可以重复调用。
场景: 判断是否为闰年的逻辑 可以封装成函数
5.1 基础语法
5.1.1 定义函数
语法格式:
def 函数名(形式参数):
函数体
def 关键字:全称是define,意为”定义”。
函数名:对函数体中语句的描述,规则与变量名相同。
形式参数:函数定义者要求调用者提供的信息。
函数体:完成该功能的语句。注意缩进。
建议: 函数的第一行语句建议使用文档字符串描述函数的功能与参数。
def sum(n):
"""
功能:计算1到n的累加和
参数n:累加的最大值
"""
result = 0
for i in range(1,n+1):
result += i
return result
5.1.2 调用函数
**语法:**函数名(实际参数)
#example
num = sum(10) #10被称为实参(即实际参数)
print(num)
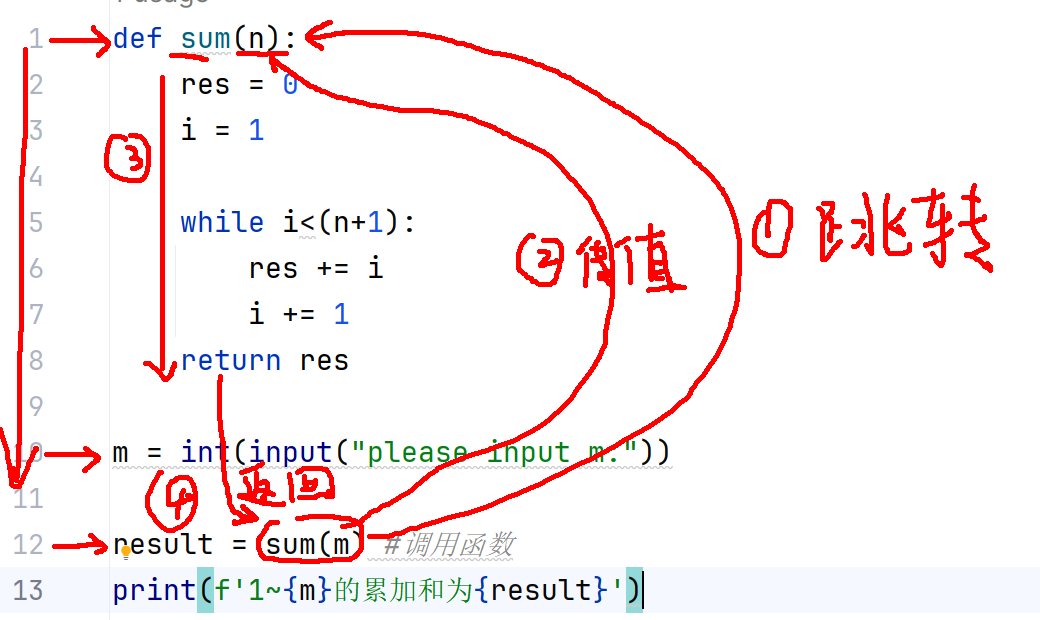
练习: 封装 判断是否为闰年的函数,并调用。
def isLeap(y):
if y%400 == 0 or (y%4==0 and y%100!=0):
return True
else :
return False
year = int(input("请输入年份: "))
if isLeap(year):
print(f'{year}年是闰年')
else:
print(f"{year}年是平年")
5.1.3 函数的返回
返回的作用:
-
告诉调用者执行结果
-
返回调用的位置顺序向下执行
语法格式: return 数据
return后没有语句,相当于返回 None。函数体没有return,相当于返回None。
def func01():
print("func01执行了")
return 100
# 1. 调用者,可以接收也可以不接收返回值
func01()
res = func01()
print(res)
# 2.在Python语言中,
# 函数没有return或return后面没有数据,
# 都相当于return None
def func02():
print("func02执行了")
return
res = func02()
print(res) # None
# 3.return可以退出函数
def func03():
print("func03执行了")
return
print("func03又执行了")
func03()
# 4. return 可以退出多层循环嵌套
def func04():
while True:
while True:
while True:
# break 只能退出一层循环
print("循环体")
return
func04()
# 可以返回多个值
def func05():
return 1, 2
def func01():
print("call func01")
return 100
#2 函数中没有写return 相当于结尾有一个return None
# 函数中写了return 相当于结尾有一个return None
def func02():
print("call func02")
#return
def func03():
print("call func03")
return #3 直接返回到调用位置去 函数中的后续代码不会被执行到
print("call func03")
def func04():
print("call func04")
return 1,2,3,4 #4 可以返回多个值 本质是返回了一个元组
#1 可以接收函数的返回值 也可以不接收
func01()
a = func02()
print(a)
func03()
b = func04()
# print(type(b))
print(b)
m,n,x,y= func04() #自动拆包
print(m,n,x,y)
print("programe end")
练习1:创建函数,根据年龄计算人生阶段,返回相应的字符串描述
练习2:定义函数,根据年月日计算是这一年的第几天。返回计算结果
5.2 可变/不可变类型在传参时的区别
传递给函数的实参分为两种类型:
- 不可变类型
- 数值型(整数,浮点数)
- 布尔值bool
- 字符串str
- 元组tuple
- 可变类型
- 列表 list
- 字典 dict
- 集合 set
不可变类型的数据传参时,函数内部不会改变原数据的值。可变类型的数据传参时,函数内部可以改变原数据。
def func01(p1, p2):
p1 = "刘玄德"
p2["关羽"] += 50
a = "刘备"
b = {"关羽": 100}
func01(a, b)
print(a) # 刘备
print(b) # {'关羽': 150}
def func01(p1, p2):
p1 = [100, 200]
p2[:] = [300, 400]
a = [10, 20]
b = [30, 40]
func01(a, b)
print(a) # [10, 20] p1改的是变量本身 而不是指向的列表
print(b) # [300, 400] p2[:]就是在访问列表了
5.3 函数参数
5.3.1 位置参数
按位置顺序实现,实参到形参的赋值。
调用函数时,给定的实参个数和位置均需和定义时相符。
def my_sub(x, y):
return x - y
my_sub(3, 2)
my_sub(3) #语法错误
my_sub(*(3,2)) #实参用*将序列拆解后与形参的位置依次对应也可以
my_sub(*[3,2])
my_sub(*"AB")
5.3.2 关键字参数
函数调用使用关键字参数来确定传入的参数值,使用关键字参数允许函数调用时参数的顺序与声明时不一致。 Python 解释器能够用参数名匹配参数值。(不按位置顺序)
def print_str(a, b, c):
print ("a 是", a)
print ("b 是", b)
print ("c 是", c)
print_str(1, 2, 3) #按位置顺序
print_str(c = 3, a = 1, b = 2) #使用关键字 就可以不按顺序了
d = {"b":2,"c":3,"a":1}
print_str(**d) #**将字典拆解变为关键字参数
5.3.3 缺省参数
def print_str(a = 1, b = 2, c=3):
print(" a是", a)
print(" b是", b)
print(" c是", c)
print_str(3, 2, 1)
print_str()
print_str(a = 3, c = 1, b = 2)
print_str(a = 3)
5.3.4 不定长参数
-
星号元组形参
# 位置实参数量可以无限 def func01(*args): # *,在形参变量中起到的作用是组包位置参数 形组实拆 print(args) func01() # 空元组 func01(1, 2, 34) # (1, 2, 34) -
双星号字典形参
# 关键字实参数量无限 def func01(**kwargs): print(kwargs) # {'a': 1, 'b': 2} func01(a=1,b=2) # func01(1,2,3) # 报错
练习:说出程序执行结果.
def func01(list_target):
print(list_target)# ?
def func02(*args):
print(args)# ?
def func03(*args,**kwargs):
print(args)# ?
print(kwargs)# ?
def func04(p1,p2,*args,p4,**kwargs):
print(p1)# ?
print(p2)# ?
print(p4)# ?
print(args)
print(kwargs)# ?
func01([1,2,3])
func02(*[1,2,3])
func03(1,2,3,a=4,b=5,c=6)
func04(10,20,111,222,p4 = 30,p5 = 40)
5.4 递归函数
递归函数: 自己调用自己的函数是递归函数。
递归函数通常通过将问题拆分为更小的、类似的子问题来解决问题。
在Python编程中,递归函数是一种常用的编程技巧。通过递归调用自身的方式,递归函数能够解决许多复杂的问题。
例如:
#求1到n的累加和
def sum(n):
if n == 1:
return 1
return n + sum(n-1)
print(sum(5))

例如:
'''
斐波那契数列: [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584]
'''
def fib(n):
if n==0 or n==1:
return 1
return fib(n-1) + fib(n-2)
fib_list = []
for i in range(20):
fib_list.append(fib(i))
print(fib_list)
练习: 使用递归求n!的阶乘。
注意:递归函数一定要有结束条件,无限递归下去,是巨大的灾难。
6.变量的作用域LEGB
变量作用域可以简单理解为变量能被访问的范围:
- 变量从创建到删除称为其生命周期
- 能被访问的范围称为作用域或可见范围
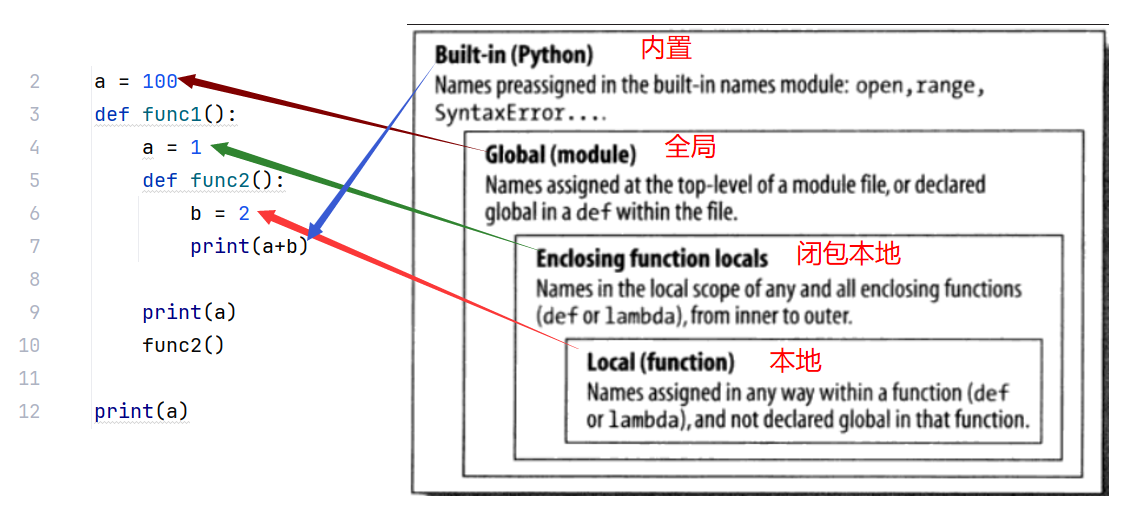
print属于builtins.py文件,属于内置作用域(B),所有.py文件都可见,可访问
a(第二行), func1属于全局作用域(G),当前.py文件中全局可访问
a (第四行)属于上一层结构中的本地作用域(E), 在func1内部可访问
b 属于本地作用域L, 仅可在func2内部访问
变量的查找顺序: 由内向外
例如,上图代码print(a+b) 执行结果为3
a = 100
def func01():
a = 1
def func02():
b = 2
print(a+b) #3
print(a) #1
func02()
func01()
-
global关键字
-
可以把一个函数内部的变量声明为全局域变量
def func(): global x #没有全局的x变量 x = 100 func() print(x) #100 -
函数内部使用全局域变量
x = 100 def func(): x = 123 func() print(x) #100x = 100 def func(): global x x = 123 func() print(x) #123 -
nonlocal关键字
作用,在内层函数修改外层嵌套函数内的变量
def func1(): x = 100 def func2(): nonlocal x x = 200 print(x) #100 func2() print(x) #200 func1()
面向对象编程
7. 面向对象与面向过程
请用程序描述如下事情:
- A同学报道登记信息
- B同学报道登记信息
- C同学报道登记信息
- A同学做自我介绍
- B同学做自我介绍
- C同学做自我介绍
stu_a = {
"name":"A",
"age":21,
"gender":1,
"hometown":"河北"
}
stu_b = {
"name":"B",
"age":22,
"gender":0,
"hometown":"山东"
}
stu_c = {
"name":"C",
"age":20,
"gender":1,
"hometown":"安徽"
}
def stu_intro(stu):
"""自我介绍"""
for key, value in stu.items():
print("key=%s, value=%d"%(key,value))
stu_intro(stu_a)#学生的自我介绍
stu_intro(stu_b)
stu_intro(stu_c)
考虑现实生活中,我们的思维方式是放在学生这个个人上,是学生做了自我介绍。而不是像我们刚刚写出的代码,先有了介绍的行为,再去看介绍了谁。
用我们的现实思维方式该怎么用程序表达呢?
stu_a = Student(个人信息)
stu_b = Student(个人信息)
stu_c = Student(个人信息)
stu_a.intro()
stu_b.intro()
stu_c.intro()
7.1 面向过程
面向过程, 分析出解决问题的步骤,然后逐步实现。
例如: 菜鸟买电脑
-
在网上查找资料
-
根据自己预算和需求定电脑的型号 MacBook 15 顶配 1W8
-
去市场找到苹果店各种店无法甄别真假 随便找了一家
-
找到业务员,业务员推荐了另外一款 配置更高价格便宜,也是苹果系统的 1W
-
砍价30分钟 付款9999
-
成交
-
回去之后发现各种问题
这种方式强调的是步骤、过程、每一步都是自己亲自去实现的
7.2 面向对象
面向对象,找出解决问题的对象,然后分配职责。
例如: 菜鸟买电脑
-
找一个靠谱的电脑高手
-
给钱交易
这种方式强调的是电脑高手, 电脑高手是处理这件事的主角,对我们而言,我们并不必亲自实现整个步骤只需要调用电脑高手就可以解决问题。
优点
-
思想层面:
- 可模拟现实情景,更接近于人类思维。
- 有利于梳理归纳、分析解决问题。
-
技术层面:
- 高复用:对重复的代码进行封装,提高开发效率。
- 高扩展:增加新的功能,不修改以前的代码。
- 高维护:代码可读性好,逻辑清晰,结构规整。
缺点
学习曲线陡峭。
8. 类和对象
面向对象编程的2个非常重要的概念:类和对象

类:拥有相同属性和行为的对象分为一组,即为一个类。(对拥有相同属性和行为对象的一个抽象)
对象:类的一个具体实例。类是创建对象实例的”模板”
类与对象的关系:

8.1 语法
8.1.1 类的构成
类(Class) 由3个部分构成
- 类的名称:类名
- 类的属性:数据成员
- 类的方法:行为成员(一系列函数)
例如:

8.1.2 定义类
class 类名:
"""
文档说明
"""
#数据成员
def __init__(self,参数):
self.实例变量 = 参数
#行为成员
说明:
1)类名所有单词首字母大写.
2)__init__ 函数也叫构造函数,创建对象时被调用,也可以省略。
3) self 变量绑定的是被创建的对象,名称可以随意。
8.1.3 实例化对象
变量 = 类名(参数)
说明:
- 变量存储的是实例化后的对象地址
2)类名后面的参数按照构造函数的形参传递
8.1.4 完整演示
class Student:
'''
学生类
'''
#数据成员
def __init__(self,name, age, sex):
self.name = name
self.age = age
self.sex = sex
#行为成员 成员方法 成员函数
def study(self):
print(f"{self.name} 正在学习")
def introduce(self):
print(f'大家好,我是{self.name}, 今年{self.age}岁')
zf = Student("张飞", 18, '男')
zf.introduce() #大家好,我是张飞, 今年18岁
8.1.5程序的内存模型

练习:创建汽车类,实例化两个对象并调用其成员函数,最后画出内存图。
数据:型号、价格、颜色、厂商
行为:行驶
8.2 实例(对象)成员
当实例化了一个对象,该对象(实例)中包含了两部分内容:
实例变量, 数据成员 /属性, 每个实例单独拥有一份
实例方法, 行为成员, 所有的实例共享一份
8.2.1 实例变量
定义: 对象 .变量名 = xxx
访问: 对象.变量名
说明:
-
主要在构造函数__init_中定义实例变量
class dog: def __init__(self, name, color): self.name = name self.color = color dog1 = dog("aaa", '12312') dog1.sex = 1 print(dog1.__dict__) dog2 = dog("bbb", '12442') print(dog2.__dict__) -
首次通过对象赋值为创建,再次赋值为修改.
class Dog: def __init__(self, name, color): self.name = name self.color = color dog1 = Dog('小强', '黄色') dog1.weight = 40 #不推荐的 print(dir(dog1)) print(dog1.__dict__) dog2 = Dog('旺财', '黑色') print(dog2.__dict__) -
每个实例存储一份,通过实例地址访问
-
作用:描述某个实例的数据。
-
python解释器内置函数dir(),可以显示给定对象的所有有效属性
-
_dict_:实例的属性,用于存储自身成员变量的字典。
-
__class__ :属性绑定创建此实例的类
-
__slots__: 限定一个类创建的实例只能有固定的属性,和__dict__互斥
class Dog:
__slots__ = ['name', 'color'] #定义类中有哪些属性
def __init__(self, name, color):
self.name = name
self.color = color
dog1 = Dog('旺财', '黄色')
dog1.weight = 40 #语法报错 因为weight属性 不在__slots__列表中
print(dog1.__dict__)
dog2 = Dog('小强', '黑色')
print(dog2.__dict__)
8.2.2 实例方法
定义
def 方法名称(self, 参数):
方法体
调用
对象.方法名称(参数)
说明
- 至少有一个形参,第一个参数绑定调用这个方法的对象,一般命名为self。
- 调用时不用在参数中指定对象,自动传递
- 无论创建多少对象,方法只有一份,并且被所有对象共享。
演示
class dog:
def __init__(self, name, color):
self.name = name
self.color = color
def eat(self, food):
print(f'{self.name} is eating {food}')
dog1 = dog("金毛", '金色')
dog1.eat("骨头")
8.3 类成员
8.3.1 类变量
定义:在类中,方法外定义的变量。
class 类名:
变量名 = 数据
调用
类名.变量名
特点
-
随类的加载而加载(python中一切皆对象,类本身也被视为对象,称作类对象)
-
存在优先于实例对象
-
只有一份,被所有实例对象共享。
作用
描述所有对象的共有数据。
class Tool:
count = 0 # 类变量
def __init__(self, name): #构造函数
self.name = name
Tool.count += 1
def __del__(self): #析构函数
Tool.count -= 1
t1 = Tool('锄头')
t2 = Tool('铁锹')
t3 = Tool('锤子')
print(f"到目前为止,程序中一共构造了{Tool.count}个工具")
del t3
print(f"销毁t3后, 还剩{Tool.count}个工具")
8.3.2 类方法
定义
@classmethod
def 方法名称(cls,参数):
方法体
调用
类名.方法名(参数)
说明
-
用于操作类属性
-
至少有一个形参,第一个形参用于绑定类,一般命名为’cls’
-
使用@classmethod修饰的目的是调用类方法时可以隐式传递类。
-
类方法中不能访问实例成员,实例方法中可以访问类成员。
实例
class ICBC:
#类变量
total_money = 10000000
#类方法
@classmethod
def print_total_money(cls):
#print(f"总行剩余钱数{ICBC.total_money}")
print(f"总行剩余钱数{cls.total_money}")
def __init__(self, name, money):
self.name = name
self.money = money
ICBC.total_money -= money
bjfh = ICBC('beijing', 80000)
shfh = ICBC('shanghai', 50000)
ICBC.print_total_money()
print(ICBC.total_money)
print(f'{bjfh.name} 现有资金: {bjfh.money}')
8.4 静态方法
定义
@staticmethod
def 方法名称(参数):
方法体
调用
类名.方法名称(参数)
# 不建议通过对象访问静态方法
class ICBC:
#类变量
total_money = 10000000
#类方法
@classmethod
def print_total_money(cls):
#print(f"总行剩余钱数{ICBC.total_money}")
print(f"总行剩余钱数{cls.total_money}")
def __init__(self, name, money):
self.name = name
self.money = money
ICBC.total_money -= money
@staticmethod
def breif():
print('中国第一大银行')
bjfh = ICBC('beijing', 80000)
shfh = ICBC('shanghai', 50000)
ICBC.print_total_money()
print(ICBC.total_money)
print(f'{bjfh.name} 现有资金: {bjfh.money}')
ICBC.breif()
说明
- 使用@ staticmethod修饰的目的是该方法不需要隐式传参数。
- 静态方法不能访问实例成员和类成员
- 与对象方法、类方法相比,省去了隐式传递self, cls的过程,节省了内存,提高的代码执行效率。
8.5 综合案例
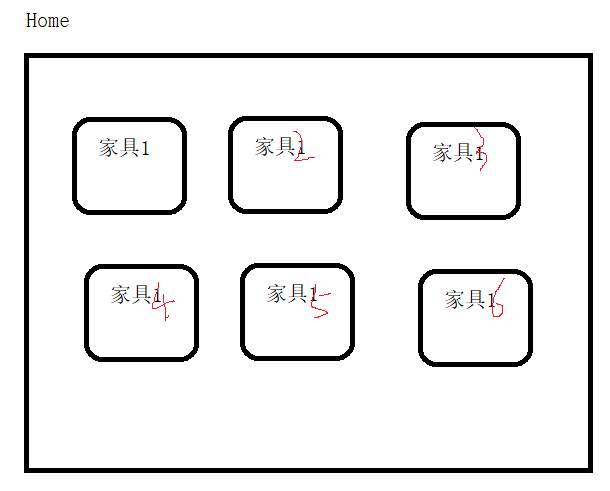
class Furniture:
'''
家具类
'''
def __init__(self,name, area):
self.name = name
self.area = area
def getArea(self):
return self.area
class Home:
'''
家类
'''
count = 0 # 类变量, 记录创建的Home的对象个数
@classmethod
def getCount(cls):
return cls.count
@staticmethod
def brief():
print('家是温馨的港湾')
def __init__(self,area):
self.area = area
self.items = [] #空列表 存储家具
Home.count += 1
def addItem(self, item):
if self.area > item.getArea():
print(f'{item.name} 放入家中')
self.area -= item.getArea()
self.items.append(item)
def showItem(self):
print("家中已经放入了: ", end='')
for i in self.items:
print(i.name, end=' ')
print()
def __del__(self):
Home.count -= 1
Home.brief() #家的简介
home1 = Home(120)
f1 = Furniture('床1', 12)
f2 = Furniture('床2', 8)
f3 = Furniture('电视', 2)
f4 = Furniture('浴缸', 20)
home1.addItem(f1)
home1.addItem(f2)
home1.addItem(f3)
home1.addItem(f4)
home1.showItem()
home2 = Home(180)
print(f'你已经有了{Home.getCount()}个家了,可以了')
9.面向对象的三大特征
9.1 封装
封装:
1)形成新的数据类型
2)隐藏细节信息。
隐藏细节,把不需要暴露给类的使用者的属性、方法改名。python类中以双下划线(_ _)开头,不以双下划线结尾的标识符为私有成员。
9.1.1 私有化属性
将数据与对数据的操作相关联, 代码可读性更高。
简化编程,使用者不必了解具体的实现细节,只需要调用对外提供的功能。
class Stu:
def __init__(self, name, age, socre):
self.name = name
self.__age = age #__age 变成了私有属性 类的外部是看不到
self.score = socre
s1 = Stu('张飞', 21, 80)
print(s1.__age) #语法会报错
私有化的本质就是改名: _类名+属性名
class Stu:
def __init__(self, name, age, socre):
self.name = name
self.__age = age #__age 变成了私有属性 类的外部是看不到 规律:_类名+属性名
self.score = socre
s1 = Stu('张飞', 21, 80)
# print(s1.__age) #语法会报错
# print(s1._Stu__age)
print(dir(s1))
9.1.1.1 外部访问私有属性的方式一
提供相应的成员方法:
class Stu:
def __init__(self, name, age, socre):
self.name = name
self.setAge(age)
self.score = socre
def getAge(self):
return self.__age
def setAge(self, newAge):
if newAge<0 or newAge>100:
raise ValueError('年龄不合法')
else :
self.__age = newAge
s1 = Stu('张飞', 21, 80)
# print(s1.__age) #语法会报错
# print(s1._Stu__age)
print(dir(s1))
s1.setAge(30)
print(s1.getAge())
9.1.1.1 外部访问私有属性的方式二
通过装饰@property 和 <attribute_name>.setter 来实现外界访问私有属性,本质和方式一是一致的。
class Stu:
def __init__(self, name, age, score):
self.name = name
self.age = age #1 私有属性正常命名
self.score = score
#如果外界需要读取该私有属性
@property #2 加读相关的装饰器
def age(self): # 3 读相关的函数名称要和私有属性保持一致
return self.__age #6 注意私有属性名称是带__的
@age.setter # 4 加写相关的装饰器
def age(self, newAge):#5 读相关的函数名称要和私有属性保持一致
if newAge<0 or newAge>100:
raise ValueError('年龄不合法')
else :
self.__age = newAge #6 注意私有属性名称是带__的
s1 = Stu('张飞', 21, 80)
num = s1.age
s1.age = 1000 # 语义错误
9.1.2 私有化方法
私有化方法的方式,同样是改名: __funcname(self, 参数)。 本质也是改名
class Stu:
def __init__(self, name, age, score):
self.name = name
self.age = age #1 私有属性正常命名
self.score = score
#私有化方法
def __pres(self,value):
return value + 5
#如果外界需要读取该私有属性
@property #2 加读相关的装饰器
def age(self): # 3 读相关的函数名称要和私有属性保持一致
return self.__pres(self.__age)
@age.setter # 加相关的装饰器
def age(self, newAge):#5 读相关的函数名称要和私有属性保持一致
if newAge<0 or newAge>100:
raise ValueError('年龄不合法')
else :
self.__age = newAge
@property
def score(self):
return self.__pres(self.__score)
@score.setter
def score(self, score):
if score > 100:
raise ValueError('成绩不合法')
else:
self.__score = score
s1 = Stu('张飞', 21, 80)
num = s1.age
print(dir(s1))
# s1.__pres(8) #语法错误
print(s1.age, s1.score)
注意:
一个下划线的属性名(例如 _x)表示这个属性是受保护的,应该被视为私有属性,尽管它仍然可以被类的实例直接访问。
两个下划线的属性名(例如 __x)表示这个属性是真正的私有属性。这意味着在类的外部无法直接访问该属性,甚至子类也不能访问它。
__x__, 双下划线开头双下划线结尾的属性, 特殊属性,特殊用途。
#__str__()函数,定义了该对象的字符串表现形式
class Stu:
def __init__(self, name, age, score):
self.name = name
self.age = age #1 私有属性正常命名
self.score = score
self._sex = '男'
#私有化方法
def __pres(self,value):
return value + 5
#如果外界需要读取该私有属性
@property #2 加读相关的装饰器
def age(self): # 3 读相关的函数名称要和私有属性保持一致
return self.__pres(self.__age)
@age.setter # 加相关的装饰器
def age(self, newAge):#5 读相关的函数名称要和私有属性保持一致
if newAge<0 or newAge>100:
raise ValueError('年龄不合法')
else :
self.__age = newAge
@property
def score(self):
return self.__pres(self.__score)
@score.setter
def score(self, score):
if score > 100:
raise ValueError('成绩不合法')
else:
self.__score = score
def __str__(self):
return f'我的名字是:{self.name}, 我今年{self.age}岁,考了{self.score}'
s1 = Stu('张飞', 21, 80)
num = s1.age
print(dir(s1))
# s1.__pres(8) #语法错误
print(s1.age, s1.score)
print(s1._sex)
str1 = str(s1)
print(str1)
9.2 继承
父类(基类、超类)、子类(派生类)。
单继承:父类只有一个(例如 Java,C#)。
多继承:父类有多个(例如C++,Python)。
Object类:任何类都直接或间接继承自 object 类。
在现实生活中,继承一般指的是子女继承父辈的财产 。

语法格式:
#如果没有出现父类,默认从object这个类派生, python中所有类的父类是object类
class 子类(父类):
pass
9.2.1 继承方法
语法:
class 父类:
def 父类方法(self):
方法体
class 子类(父类):
def 子类方法(self):
方法体
儿子 = 子类()
儿子.子类方法()
儿子.父类方法()
说明
子类直接拥有父类的方法。注意父类的私有方法子类也是不能访问的。
示例
class Person:
def say(self):
print("说话")
class Teacher(Person):
def teach(self):
self.say()
print("教学")
class Student(Person):
def study(self):
self.say()
print("学习")
t1 = Teacher()
t1.say()
t1.teach()
s1 = Student()
s1.say()
s1.study()
print(Teacher.__base__) #记录了父类
print(Student.__base__)
9.2.2 继承属性
语法
class 子类(父类):
def __init__(self,父类参数,子类参数):
super().__init__(参数) # 调用父类构造函数
self.实例变量 = 参数
说明
子类如果没有构造函数,将自动执行父类的,但如果有构造函数将覆盖父类的。此时必须通过super()函数调用父类的构造函数,以确保父类实例变量被正常创建。
示例
class Person:
def __init__(self, name="", age=0):
self.name = name
self.age = age
# 子类有构造函数,不会使用继承而来的父类构造函数[子覆盖了父方法,好像它不存在]
class Student(Person):
# 子类构造函数:父类构造函数参数,子类构造函数参数
def __init__(self, name, age, score):
# 调用父类构造函数 super(Student, self)
super().__init__(name, age)
self.score = score
p1 = Person("刘备",22)
print(p1.name)
s1 = Student("关羽", 23, 100)
print(s1.name)
print(s1.score)
9.2.3 python内置函数
-
isinstance(对象, 类型)
返回指定对象是否是某个类的对象。
-
issubclass(类型,类型)
返回指定类型是否属于某个类型。
# 对象 是一种 类型: isinstance(对象,类型)
# 老师对象 是一种 老师类型
print(isinstance(zgl, Teacher)) # True
# 老师对象 是一种 人类型
print(isinstance(zgl, Person)) # True
# 老师对象 是一种 学生类型
print(isinstance(zgl, Student)) # False
# 人对象 是一种 学生类型
print(isinstance(p, Student)) # False
# 类型 是一种 类型: issubclass(类型,类型)
# 老师类型 是一种 老师类型
print(issubclass(Teacher, Teacher)) # True
# 老师类型 是一种 人类型
print(issubclass(Teacher, Person)) # True
# 老师类型 是一种 学生类型
print(issubclass(Teacher, Student)) # False
# 人类型 是一种 学生类型
print(issubclass(Person, Student)) # False
# 是的关系
# 老师对象的类型 是 老师类型
print(type(zgl) == Teacher) # True
# 老师对象的类型 是 人类型
print(type(zgl) == Person) # False
9.2.4 方法重写
如果继承来的方法不满足要求,那在子类中可以重写该方法.如果想调用父类的同名方法,可以使用super()函数。
class A:
def fun1(self):
print('aaaaa')
class B(A):
def fun1(self):
super().fun1()
print('bbbbb')
b = B()
b.fun1()
9.2.5 多继承
定义:一个子类继承两个或两个以上的基类,父类中的属性和方法同时被子类继承下来。

示例:
# 定义一个父类
class A:
def printA(self):
print('----A----')
# 定义一个父类
class B:
def printB(self):
print('----B----')
# 定义一个子类,继承自A、B
class C(A,B):
def printC(self):
print('----C----')
obj_C = C()
obj_C.printA()
obj_C.printB()
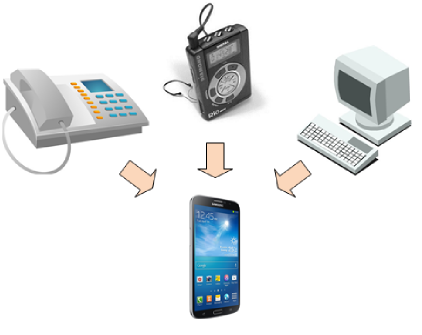
多继承带来的问题
多继承中子类对象同时调用父类同名的方法时会出现冲突,而调用顺序由方法解析顺序MRO(method resolution order)决定
class A:
def fun(self):
print('aaa')
class B:
def fun(self):
print('bbb')
class C:
def fun(self):
print('ccc')
class D(A,B,C):
def fun(self):
super(D, self).fun()
super(A, self).fun()
super(B, self).fun()
print('ddd')
d = D()
print(D.__mro__) #__mro__属性中包含了该类的父类列表
d.fun()
编程实例
class Phone:
def __init__(self, number):
self.number = number
def call(self, num):
print(f"{self.number} 打给 {num}")
class Player:
def __init__(self, name):
self.name = name
def play(self, media):
print(f'{self.name} 正在播放:{media}')
class Computer:
def __init__(self, os):
self.os = os
def run(self, app):
print(f'{self.os}操作系统上正在运行{app}程序')
class SmartPhone(Phone, Player, Computer):
def __init__(self, name):
self.name = name #手机品牌
#super().__init__()
super(SmartPhone, self).__init__(13866680009)#Phone
super(Phone, self).__init__("MP4")
super(Player, self).__init__("鸿蒙")
print(SmartPhone.__mro__)
s1 = SmartPhone("华为")
s1.call(12345)
s1.play("斗罗大陆")
s1.run('王者荣耀')
9.2.5 继承与组合
继承和组合是python面向对象编程是实现代码重用的重要手段。
继承就是Is-a的关系, 梨是一种水果
组合就是Has-a的关系, 图书馆中有图书。
class Vehicle:
'''
交通工具类
'''
def __init__(self, weight):
self.weight = weight
def load(self, goods):
print(f'装载了"{goods}"')
class Tyre:
'''
轮胎类
'''
def run(self, dest):
print(f'轮胎转动,驶向目的地{dest}')
class Truck(Vehicle): #is-a
def __init__(self, name, weight):
super().__init__(weight)
self.name = name
self.tyre = Tyre() #has-a
t1 = Truck('东风', 30)
t1.load("小米SU7")
t1.tyre.run('上海')
9.3 多态
9.3.1什么是多态
多态(polymorphism)是面向对象编程中的一个重要概念。
多态是指在有继承/派生关系的类中,调用基类对象的方法,实际能调用子类的覆盖方法的现象叫多态。
class Shape:
def draw(self):
print("Shape.draw被调用")
class Point(Shape): # 点类
def draw(self):
print("正在画一个点")
class Circle(Point):
def draw(self):
print("正在画一个圆")
def my_draw(s):
s.draw() #此处调用哪个方法在运行时确定
shape1 = Circle()
shape2 = Point()
my_draw(shape1) #正在画一个圆
my_draw(shape2) #正在画一个点
由于python是弱类型语言,变量本身没有数据类型, 所以python中刻意谈到多态的意义不是特别大 。但是python与生俱来的这种多态性对于程序设计还是非常有帮助的。
9.3.2 多态的作用
可以增加代码的灵活性,让代码更加通用,兼容性比较强。
#用户说: 用笔画一个图形
class Shape:
'''
抽象的图形类
'''
def draw(self, pen):
print('使用 ' + pen.getPen() + '画图形')
class Rect(Shape):
def draw(self, pen):
# 使用笔画具体的图形
print('使用' + pen.getPen() + '画 矩形')
class Circle(Shape):
def draw(self,pen):
print('使用' + pen.getPen() + '画 圆形')
class Pen:
def getPen(self):
return '笔'
class Maobi(Pen):
def getPen(self):
return '毛笔'
class Yuanzhubi(Pen):
def getPen(self):
return '圆珠笔'
def my_draw(s,p):
s.draw(p)
s1 = Shape()
s2 = Rect()
s3 = Circle()
p1 = Pen()
p2 = Maobi()
p3 = Yuanzhubi()
my_draw(s3,p3)
编程进阶
10. 程序结构
当项目变大后,我们把所有代码放到一个文件好?还是把代码分类放到不同文件好?
10.1 文件结构
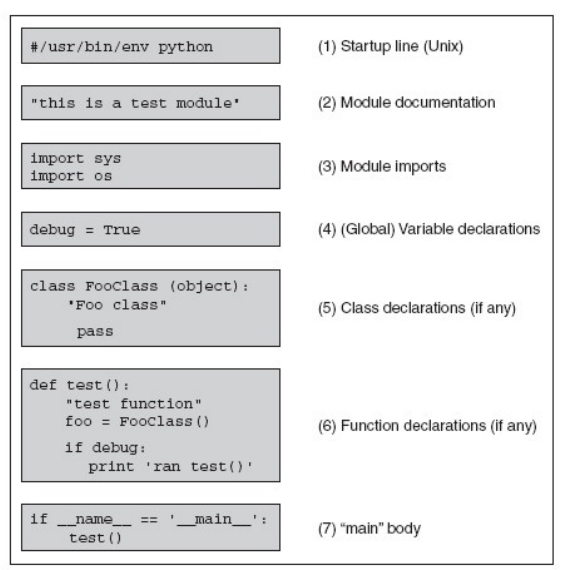
#/usr/bin/env python
'''
实现斐波那契数列相关的函数
'''
import sys #导入模块
def fib1(n): #输出一个斐波那契数列,最大值<n
a, b = 0, 1
while b < n:
print(b, end=' ')
a,b = b,a+b
print()
def fib2(n): # 返回一个列表形式的斐波那契数列
result = []
a,b = 0,1
while b < n:
result.append(b)
a,b = b, a+b
return result
if __name__ == "__main__":
fib1(100)
l1 = fib2(1000)
print(l1)
10.2 模块module
可以把函数等根据实现的功能分类,一类放到一个文件中,该文件以 .py 结尾,在Python中每个这样的文件就是一个模块(Module),文件名就是模块名。
10.2.1 模块的使用方法
10.2.1.1导入模块
方式一:将模块整体导入到当前模块中
import 模块名
或者
import 模块名 as 别名
import Fibonacci
#import Fibonacci as fb
# import fibonacci
# fibonacci.fib1(100)
import fibonacci as fib
fib.fib1(100)
这种导入方式,访问导入模块内的方法时,都应该是模块.方法名(…)
方式二:将模块内的成员导入到当前模块作用域中( 是把模块中的代码复制到了这个py脚本中,可以去掉一层名字空间 )
from 模块名 import 成员名
from 模块名 import 成员名 as 别名
from 模块名 import *
from Fibonacci import *
# from fibonacci import fib1
# from fibonacci import fib2
from fibonacci import *
fib1(100)
fib2(1000)
改导入方式的缺点:容易造成名字冲突。如果我导入了两个模块,这两个模块中存在同名的函数,那就是名字冲突
10.2.3模块的导入过程
10.2.3.1模块是怎么被找到的
模块分为三大类:
- Python内置模块(builtin)
- 第三方个模块(通常为开源),需要自己安装
- 自定义模块
当导入一个模块时,Python 解析器会按照sys.path中记录的路径进行搜索。
sys.path中一般包含:
-
当前目录
-
环境变量PYTHONPATH中所指定的路径
-
系统默认路径 ( Python安装自带的库 )
-
标准库中的site-packages目录
Python中所有加载到内存的模块都放在sys.modules,
当import一个模块时首先会在这个列表中查找是否已经加载了此模块,如果加载了则只是将模块的名字加入到正在调用import的模块的Local名字空间中。如果没有加载则从sys.path目录中按照模块名称查找模块文件,找到后将模块载入内存,并加入到sys.modules中,并将名称导入到当前的Local名字空间。
找不到模块的解决方式:
-
临时添加模块完整路径
import sys sys.path.append('xxx模块所在路径') import xxx -
将模块保存到指定位置
print(sys.path) 将xxx.py文件拷贝到lib\site-packages目录 -
设置环境变量 PYTHONPATH
10.2.3.2导入模块到底做了什么
在模块导入时,模块的所有顶层语句都会执行。如果一个模块已经导入,则再次导入时不会重新执行模块内的语句。
10.2.3.3 动态导入模块
动态导入模块: __import__ 函数根据给定的字符串名字动态导入模块
s = __import__("sys")
print(s.path)
print(dir(s))#查看模块中定义过的名字的列表(函数 变量)
print(globals())#返回全局命名空间中的名字字典
10.2.4 模块中的几个特殊属性
__file__, 包含了绝对路径的模块文件名
__doc__,文档字符串
__all__,定义可导出成员, 仅对 from xx import *有效。模块未定义__all__列表,则导入模块的全部顶层属性
__name__,模块自身的名字,可以判断是否为主模块。当该模块作为主模块(第一个运行的模块)运行时,__name__绑定"__main__",不是主模块,而是被其它模块导入时,就绑定自身真实的模块名了。
10.2.5 常用内置模块
10.2.5.1 time模块
与时间相关的模块。
python3.8.2官方汉化版文档-pdf/library.pdf: P599
import time
print('hello python world')
time.sleep(2.0) # 延迟执行2秒
print('life is short,i use python')
# 时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
print(time.time())
print(time.localtime())#本地时间
#返回以字符串表示的当地时间
print(time.strftime('%Y-%m-%d %H:%M:%S'))
10.2.5.2 random模块
随机模块。
python3.8.2官方汉化版文档-pdf/library.pdf: P314
import random
#随机生成[0,1)的数
print(random.random())
#生成[1,5]的随机整数
print(random.randint(1, 5))
#随机在序列中取元素
print(random.choice('1234hello python world'))
li = [1, 4, 7, 5, 3, 0]
# 将传入的容器进行乱序,注意1:改变的是容器本身。注意2:容器不能是元组
random.shuffle(li) # 将列表元素随机排列
print(li)
li = [1, 4, 6, 5, 18, 2, 9, 7]
print(random.sample(li, 3)) # 随机从li列表中取三个元素
10.2.5.3 os模块
python3.8.2官方汉化版文档-pdf/library.pdf:P537
本模块提供了一种使用与操作系统相关的功能。
import os
print(os.getcwd())#获取当前路径
os.chdir("C:") # 切换路径 change dir
print(os.getcwd())
os.makedirs(r'.\a\b\c\d') #递归创建文件夹
print(os.path.exists('a'))#判断指定的文件(夹是否存在)
os.removedirs(r'.\a\b\c\d') #递归删除文件夹
print(os.path.join(os.getcwd(), "happy"))#拼接路径
10.2.5.4 sys模块
与python解释器交互的模块 。
python3.8.2官方汉化版文档-pdf/library.pdf:P1679
import sys
print(sys.path)
sys.exit(1)
print(sys.version)
10.3 包package
Python中一个 .py文件可以作为一个模块,多个模块放到一起,组成一个包。
包目录下会有一个 __init__.py文件。
导入模块本质上是去执行模块.py文件, 导入包的本质是去执行包下的 __init__.py文件。
自定义包的创建与使用
my_project/
main.py
package01/
__init__.py
module01.py
module02.py
"""
package01/
module01.py
"""
def func01():
print("func01执行了")
def func02():
print("func02执行了")
"""
package01/
module02.py
"""
def func03():
print("func03执行了")
def func04():
print("func04执行了")
print(__name__)
-
如果只需要单独导入包内某个单独模块,__init__.py 为空即可
''' __init__.py '''-
形式一
""" main.py """ import package01.module01 package01.module01.func01() package01.module01.func02() -
形式二
""" main.py """ from package01 import module01 module01.func01() module01.func02() -
形式三
""" main.py """ from package01.module01 import func01 from package01.module01 import func02 func01() func02()
当__init__.py 为空时, 导入的对象为包内的某个指定模块。本质上要使得module01.py文件的顶层代码被执行。
-
'''
__init__.py
'''
from . import module01 #. 代表当前包(目录)
from . import module02
"""
main.py
"""
from package01 import * #导包内所有模块
module01.func01()
module02.func03()
"""
main.py
"""
import package01 #导包
package01.module01.func01()
package01.module02.func03()
-
若想通过from 包名 import *时限制只导特定的包内模块, 可以通过__all__列表指定包内哪些模块生效。
''' __init__.py ''' from . import module01 from . import module02 __all__ = ["module01"]
```python
"""
main.py
"""
from package01 import *
module01.func01()
module01.func02()
module02.func03()#NameError: name 'module02' is not defined
module02.func04()#NameError: name 'module02' is not defined
11. 异常处理
11.1 异常概述
(1) 定义: 异常就是程序运行时因代码的逻辑错误或用户的不合法输入导致程序无法正常运行的现象,而通常这种情况发生时我们的Python就会报错,而报出来的这个错误就被称为异常了
year = input("请输入年份:") #输入了如果非数字类型 就会产生异常
year = int(year)
print(f'你输入的年份是: {year}')
(2) 现象:当异常发生时,程序不会再向下执行,而转到函数的调用位置。
def fun1():
year = input("请输入年份:")
year = int(year)
print(f'你输入的年份是: {year}')
return year
def fun2():
fun1()
print('aaa')
def func3():
fun2()
print('bbb')
func3()
print('程序结束')

(3) 常见异常类型:
– 异常基类Exception。
– 名称异常(NameError):变量未定义。
– 类型异常(TypeError):不同类型数据进行运算。
– 索引异常(IndexError):超出索引范围。
– 属性异常(AttributeError):对象没有对应名称的属性。
– 键异常(KeyError):没有对应名称的键。
内置异常类结构:

11.2 异常的处理
(1) 语法:
try:
可能触发异常的语句
except 错误类型1 [as 变量1]:
处理语句1
except 错误类型2 [as 变量2]:
处理语句2
except Exception [as 变量3]:
不是以上错误类型的处理语句
else:
未发生异常的语句
finally:
无论是否发生异常的语句
(2) 作用:捕获异常,处理异常,将程序由异常状态转为正常流程。
(3) 说明:
as 子句是用于绑定错误对象的变量,可以省略
except子句可以有一个或多个,用来捕获某种类型的错误。
else子句最多只能有一个。
finally子句最多只能有一个,如果没有except子句,必须存在。
如果异常没有被捕获到,会向上层(调用处)继续传递,直到程序终止运行。
def fun1():
while True:
year = input("请输入年份:")
try:
year = int(year)
except ValueError:
print('输入错误')
continue
# except Exception:
# print('抓到一个错误')
# continue
else:
break
finally:
print('不管是否发生异常, 获取用户输入算是完事了')
print(f'你输入的年份是: {year}')
return year
def fun2():
fun1()
print('aaa')
def func3():
fun2()
print('bbb')
func3()
print('程序结束')
练习1:尝试在func3函数中捕获异常,并保证可以获得正确的年份数字。
练习2:创建一个函数,函数中获取用户录入的浮点数形式的学生成绩,如果录入格式不正确,处理异常,保证可以正确返回
效果: score = get_score()
print(“成绩是:%d”%score)
11.3 异常的产生(raise)
作用:抛出一个错误,让程序进入异常状态。向调用者反馈异常信息。
class Stu:
def __init__(self, name, age, score):
self.name = name
self.age = age #1 私有属性正常命名
self.score = score
#如果外界需要读取该私有属性
@property #2 加读相关的装饰器
def age(self): # 3 读相关的函数名称要和私有属性保持一致
return self.__age #6 注意私有属性名称是带__的
@age.setter # 4 加写相关的装饰器
def age(self, newAge):#5 读相关的函数名称要和私有属性保持一致
if newAge<0 or newAge>100:
raise ValueError('年龄不合法')
else :
self.__age = newAge #6 注意私有属性名称是带__的
# -- 接收 错误信息
while True:
try:
age = int(input("请输入学生的年龄:"))
score =float(input('请输入学生的成绩'))
s1 = Stu('张飞', age,score)
except Exception as e:
print(e.args)
else:
break
11.4 自定义异常类
如果内置异常不满足你的需要,完全可以自定义异常类。
class StuInfoError(Exception):
def __init__(self, desc, errno):
super().__init__(desc, errno)
self.desc = desc
self.errno = errno
class Stu:
def __init__(self, name, age, score):
self.name = name
self.age = age #1 私有属性正常命名
self.score = score
#如果外界需要读取该私有属性
@property #2 加读相关的装饰器
def age(self): # 3 读相关的函数名称要和私有属性保持一致
return self.__age #6 注意私有属性名称是带__的
@age.setter # 4 加写相关的装饰器
def age(self, newAge):#5 读相关的函数名称要和私有属性保持一致
if newAge<0 or newAge>100:
raise StuInfoError('年龄不合法', 10001)
else :
self.__age = newAge #6 注意私有属性名称是带__的
while True:
try:
age = int(input("请输入学生年龄:"))
score = float(input('请输入学生的成绩:'))
s1 = Stu('张飞', age, score)
except StuInfoError as e:
print(e.args)
print(e.desc)
print(e.errno)
except Exception as e:
print(e.args)
12.函数的重写与重载
重写( Method Overriding )和 重载(Method Overloading) 是面向对象编程时的两个重要概念。但python属于弱类型语言(对类型没有像C++、JAVA那样严格),所以去讨论函数重载没有太大的意义。
重载的定义:同一个作用域中,函数名称相同,参数不同(类型不同、个数不同、顺序不同)的函数之间构成重载关系。
如下C++代码中,在同一个作用域中存在名称相同Integer函数,但它们的参数不同,所有构成了重载关系。
class Integer{
private:
int m_i ;
public:
Integer(void){
cout << "Integer(void)" << endl;
m_i = 0;
}
Integer(int n){
cout << "Integer(int)" <<endl;
m_i = n;
}
Integer(const char *str){
cout << "Integer(const char *)" << endl;
m_i = strlen(str);
}
void print(void){
cout << m_i << endl;
}
};
而python 程序中如果出现类似情况会是一个什么效果呢?
class Integer:
def __init__(self, n):
self.data = n
def fun1(self,a):
print(a)
def fun1(self,a, b):
print(a,b)
i1 = Integer(100)
#i1.fun1(1)#语法错误
i1.fun1(1,2)
print(dir(i1))
函数重写,在子类中定义和父类同名的方法来就实现了函数的重写。
例如:
class A:
def __init__(self):
print("call A __init__")
class B(A):
def __init__(self):
super().__init__()
print("call B __init__")
b = B()
就是一个典型的函数重写。
12.1 让自定义类支持常见的内置函数操作
我们先来看一个例子。
class MyList(list):
def __init__(self, it):
super().__init__(it)
self.arr = [x for x in it]
test1 = MyList("abcdefg")
print(len(test1))
print(dir(test1))
为什么能够支持len()函数的操作呢,就是因为其从list类派生, list类中有__len__()函数的实现。
如果继承来的__len__()函数不能满足我们的需要,我们完全可以改写它。
class MyList(list):
def __init__(self, it):
super().__init__(it)
self.arr = [x for x in it]
def __len__(self):
return super().__len__() + 100
test1 = MyList("abcdefg")
print(len(test1))
print(dir(test1))
各种__xxx__()函数的作用:《Python袖珍指南 第5版.pdf》 P92
__str__, 返回该对象的字符串表示形式, 更易于非专业人来看懂的
__repr__, 返回该对象的字符串表示形式, 给专业人士看的,甚至是给python解释器看的
eval(), 属于python解释器的内置函数, 其作用是将传递给它的字符转换为python语句并执行
class Student:
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
def __str__(self):
return f'我的名字是{self.name}, 我今年{self.age}, 考试考了{self.score}'
def __repr__(self):
return 'Student("%s", %d, %f)'%(self.name, self.age, self.score)
s1 = Student("赵云", 22, 98.6)
print(dir(s1))
str1 = str(s1)
print(str1)
print(repr(s1))
# print(eval('1+2+3'))
s2 = eval(repr(s1))
print(type(s2))
s2.age = 40
print(s1)
练习: 在上面代码的基础上,让Student对象支持int(s1), 支持float(s1)操作, 分别返回age 和 score.
12.2 让自定义类支持常见的运算操作
让自定义的类生成的对象(实例)能够使用运算符进行操。使得代码更具有通用性和灵活性。
import random
def average(l):
sum = 0
for i in range(len(l)):
sum += l[i]
sum = sum/len(l)
return sum
l1 = []
l2 = []
for i in range(10):
l1.append(random.randint(100,200))
l2.append(random.random()*12)
print(l1)
print(l2)
print(average(l1))
print(average(l2))
class Student:
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
def __str__(self):
return f'我的名字是{self.name}, 我今年{self.age}, 考试考了{self.score}'
def __repr__(self):
return 'Student("%s", %d, %f)'%(self.name, self.age, self.score)
l3 = [Student('张飞', 26, 87.6), Student('赵云', 24,98.2), Student('关羽', 28, 72.7)]
print(average(l3)) #打印输出平均成绩 ???
12.2.1 算术运算符重载
可以根据所使用的操作数更改Python中运算符的含义。这种做法被称为运算符重载。
12.2.1.1正向算术运算符重载
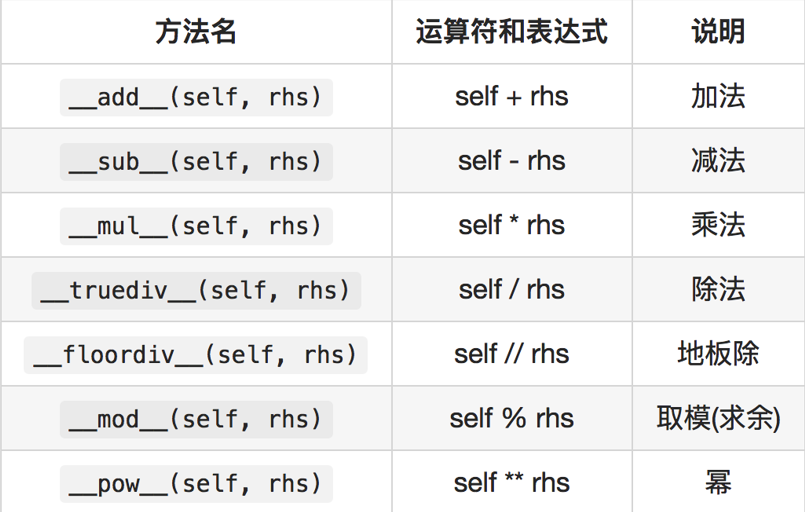
class Integer:
def __init__(self,value):
self.data = value
def __add__(self, other):
if isinstance(other, Integer):
return Integer(self.data + other.data)
elif isinstance(other, int):
return Integer(self.data + other)
else:
raise TypeError("类型不支持", type(other))
# self.data += other.data
# return self
def __sub__(self, other):
if isinstance(other, Integer):
return Integer(self.data - other.data)
elif isinstance(other, int):
return Integer(self.data - other)
else:
raise TypeError("类型不支持", type(other))
def __radd__(self, other):
return self.__add__(other)
def __rsub__(self, other):
return Integer(other - self.data)
def __str__(self):
return str(self.data)
i1 = Integer(10)
i2 = Integer(20)
print(i1 + i2)
print(i1 - i2)
print(i1 - 5)
print(5 - i1)
12.2.1.2 反向算术运算符重载方法
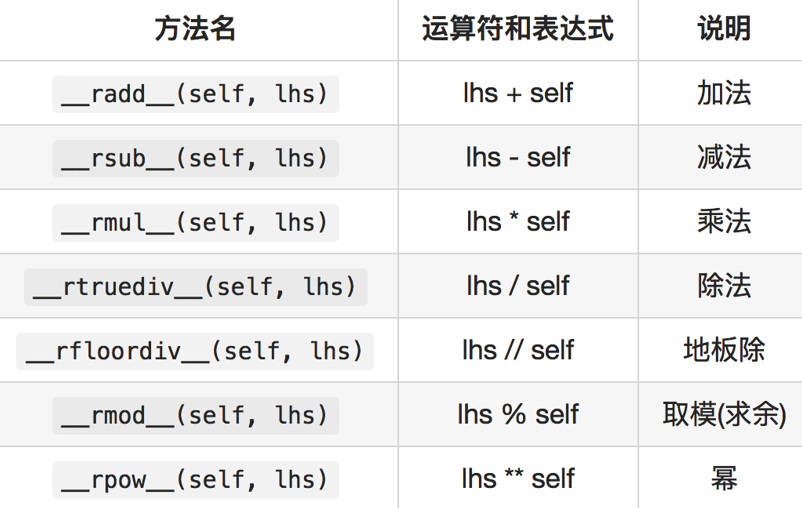
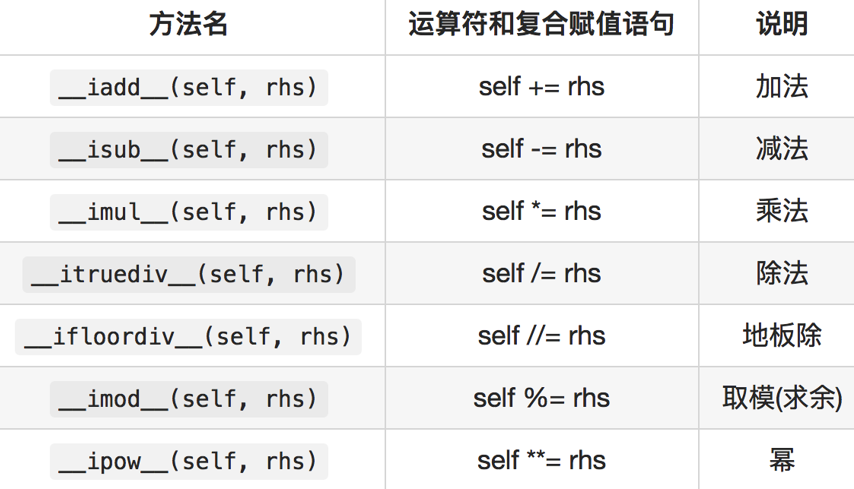
12.2.2 复合赋值算术运算符重载
12.2.3 比较运算符重载
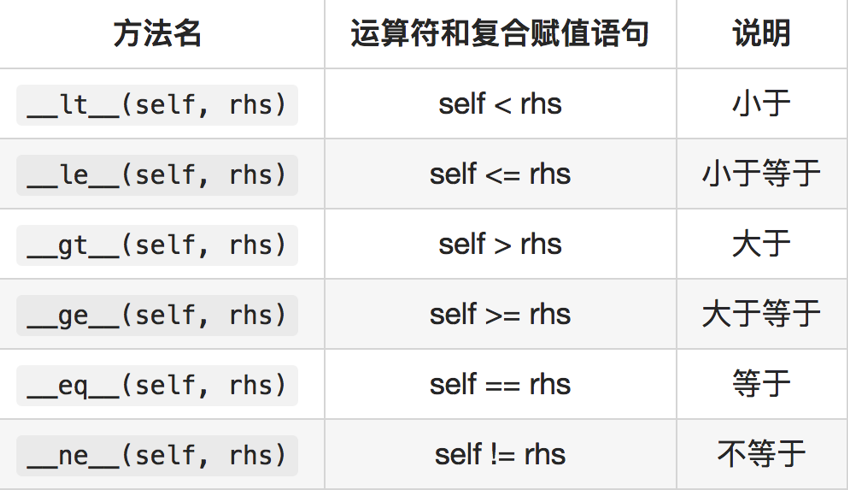
12.2.4 一元运算符重载

12.2.5 位运算符重载
12.2.5.1 正向位运算符重载方法
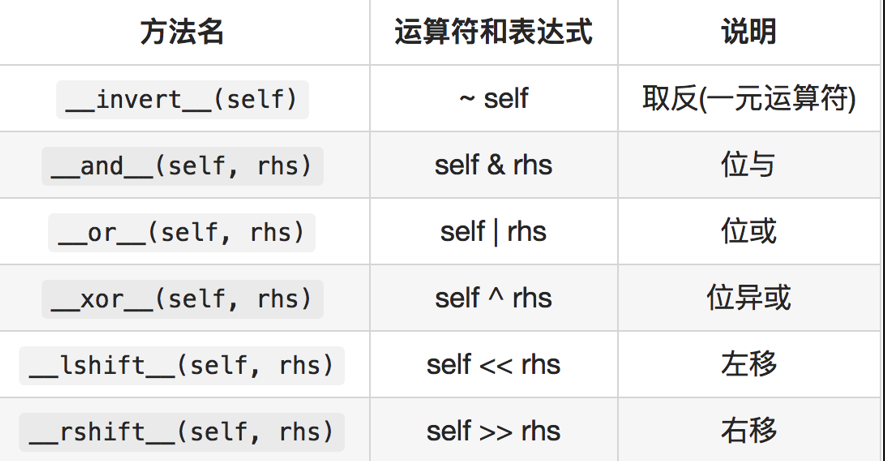
12.2.5.2 反向位运算符重载方法

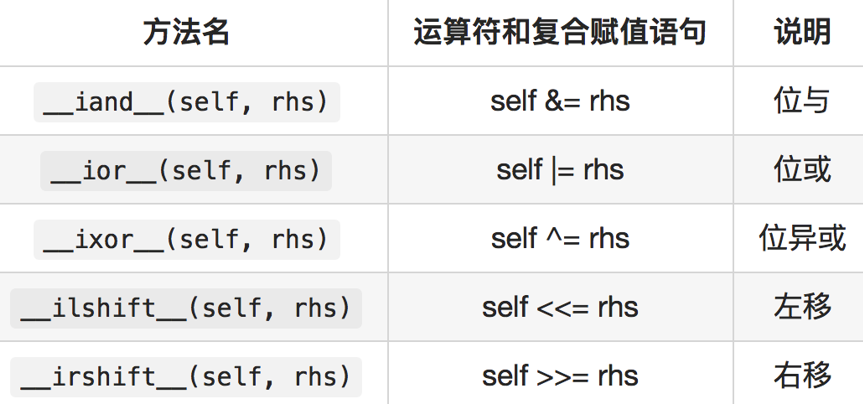
12.2.5.3 复合赋值位运算符重载方法
12.2.6 in / not in 重载

12.2.7 索引、切片运算符重载

class MyList:
def __init__(self, it):
self.arr = [x for x in it]
def __str__(self):
return str(self.arr)
def __getitem__(self, item):
if item >= len(self.arr):
raise IndexError('越界')
return self.arr[item]
def __setitem__(self, key, value):
self.arr[key] = value
def __contains__(self, item):
return item in self.arr
l1 = MyList("abcd")
print(l1)
l1[0] = 'A'
print(l1[0])
if 'm' in l1:
print('在其中')
else:
print('不在其中')
本章开头问题的解决:
import random
def average(l):
sum = 0
for i in range(len(l)):
sum += l[i]
sum = sum / len(l)
return sum
l1 = []
l2 = []
for i in range(10):
l1.append(random.randint(100, 200))
l2.append(random.random() * 12)
print(l1)
print(l2)
print(average(l1))
print(average(l2))
class Student:
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
def __str__(self):
return f'我的名字是{self.name}, 我今年{self.age}, 考试考了{self.score}'
def __repr__(self):
return 'Student("%s", %d, %f)' % (self.name, self.age, self.score)
def __add__(self, other):
if isinstance(other, int):
return Student(self.name, self.age, self.score + other)
elif isinstance(other, float):
return Student(self.name, self.age, self.score + other)
elif isinstance(other, Student):
return Student(self.name, self.age, self.score + other.score)
else:
raise TypeError('不支持的数据类型', type(other))
def __radd__(self, other):
return self.__add__(other)
def __truediv__(self, other):
return Student('平均成绩' , self.age, self.score/other)
l3 = [Student('张飞', 26, 87.6), Student('赵云', 24, 98.2), Student('关羽', 28, 72.7)]
print(average(l3))
13.迭代器与生成器
为了讲清迭代器与生成器,我们先补充一个知识:程序的调试运行。
def func():
print('call func')
if __name__ == '__main__':
i = 0
while i<10:
func()
F8: 代码一步一步向下执行,但是遇到了函数以后,不进入函数体内部,直接返回函数的最终的执行结果
F7: 代码一步一步向下执行,但是遇到了函数以后,进入到函数体内部,一步一步向下执行,直到函数体的代码全部执行完毕。
来说说迭代器与生成器吧。
这个语法主要应用于大量数据超处理的情况。大数据、人工智能都有大量的数据要处理。
试想如果我硬盘上有1000万条数据,要喂给我们搭建好的网络模型用于训练,假如网络模型每次能处理1条数据。对于数据有两种加载方式:
- 一次性把这1000万条数据加载到内存中,然后再一条一条送入模型
- 网络模型需要一条数据,那我就给它生成一条数据(从磁盘中读取一条数据)送入模型
显然后者是节省了大量的内存的。
那怎么实现需要一条数据,我就给它生成一条数据呢?答案就是“生成器”。
我们连看一个简单的例子:
def my_generator(n):
i = 0 #先从硬盘读取一条数据 (生成数据)
while i < n:
yield i #返回生成的数据
i += 1 #生成数据
gen = my_generator(5)
for i in gen:
print(i, end=' ') # 输出: 0 1 2 3 4
虽然程序的执行顺序很变态,确实达到了我们需要一条数据,产生一条数据的目的。将来我们编程中如果需要这样的业务逻辑,那咱就可以使用yield关键字来实现了。
l1 = list(range(100000000)) #模拟硬盘上有100000000条记录
def my_generator():
i = 0
while i < len(l1):
yield l1[i] # 模拟从硬盘中取一条数据(生成一条数据)
i += 1
for item in my_generator():
print(f'把第{item}条数据送入网络模型')
那它的底层原理是啥样的呢?
那就要涉及到可迭代对象、迭代器、生成器的概念了。
这块的内容,掌握分两个层级:
- 一,先学会上面的例子程序,理清执行顺序
- 二, 掌握底层原理, 面试题经常考 :什么是生成器, 与迭代器啥关系?
13.1迭代
迭代, 是指在不断重复反馈过程,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代的结果又会作为下一次迭代的初始值,为下一次迭代建立基础,最终通过不断地重复这个过程,迭代会收敛到最优解或者无限接近最优解。
可迭代对象,是指能用 iter(obj)函数 返回迭代器的对象。说的有点抽象,像字符串、列表、字典、元组、集合这些都是可迭代对象。他们都可以执行如下类似动作:
for i in [1,2,3,4,5]:
print(i)
好像我们可以不断迭代从列表这个容器中取出元素,但事实上容器并不提供这种能力,而是迭代器赋予了容器这种能力。
以上代码的实际过程类似于:
my_list = [1,2,3,4,5]
my_iterator = iter(my_list) #通过内置函数iter的调用,my_list返回了一个迭代器对象
print(next(my_iterator)) # 输出 1 本质调用了my_list.__next__函数
print(next(my_iterator)) # 输出 2
print(next(my_iterator)) # 输出 3
#for循环的原理
# for i in [1,2,3,4,5]:
# print(i)
my_list = [1,2,3,4,5]
iterator = iter(my_list) #调用的是my_list.__iter__方法
print(type(iterator))
while True:
try:
item = next(iterator) #调用iterator.__next__方法
print(item)
except :
break
如何让自定义类对象成为可迭代对象?
那就需要该自定义类中要实现 __iter__ ()方法,该方法可以返回一个迭代器对象
要返回一个迭代器对象就要定义一个迭代器类
迭代器类中要实现__next__()方法,
__next__()方法要实现能够依次返回自定义对象中一个元素, 在没有下一项数据时触发一个 StopIteration 异常的功能。
自定义类,其创建的对象是可迭代对象。
class MyIterator: #迭代器类
def __init__(self, lst):
self.lst = lst
self.cur = 0
def __next__(self): #迭代器的标志函数
if self.cur >= len(self.lst):
raise StopIteration
i = self.cur
self.cur += 1
return self.lst[i]
class MyIterable: #可迭代对象类
def __init__(self, iterable):
self.data = [x for x in iterable]
def __iter__(self): #可迭代对象的标志函数
return MyIterator(self.data) # 返回一个迭代器
L1 = MyIterable(range(10,50))
for i in L1:
print(i)
如何判断一个对象是可迭代对象:
from collections import Iterable
string="sss"
#方式一
print(isinstance(string,Iterable)) #返回True,表明字符串也是可迭代对象
#方式二
print(iter(string)) #输出<str_iterator object at 0x7f7510708af0>
迭代器的作用:每次next时产生一个数据,不用一次性把所有数据都产生(放入内存)。像我们前面经常使用的range()函数,它返回的就是一个迭代器,通过迭代器去生成数据,并返回。
# for i in range(10):
# print(i)
# iterator = iter(range(10))
iterator = range(10).__iter__() #获取到迭代器
print(type(iterator))
while True:
try:
#item = next(iterator)
item = iterator.__next__() #迭代获取可迭代对象中的一个元素
print(item)
except:
break
可以自行简单实现一个range类。
class MyRangeIterator:
def __init__(self, value):
self.num = 0
self.stop_value = value
pass
def __next__(self):
if self.num >= self.stop_value:
raise StopIteration
tmp = self.num
self.num += 1
return tmp
class MyRange:
def __init__(self, stop_value):
self.stop_value = stop_value
def __iter__(self):
return MyRangeIterator(self.stop_value)
for i in MyRange(5):
print(i)
练习: 使用迭代器遍历列表中所有元素(不能使用for)
#使用迭代器遍历列表 (不是使用for)
l1 = [1,2,3,4,5] #列表是可迭代对象
it = iter(l1) #返回迭代器
# it = l1.__iter__()
# item = next(it)
# item = it.__next__() #迭代获取一个元素
#
# print(item)
while True:
try:
item = it.__next__()
print(item)
except:
break
练习:使用迭代器遍历字典中所有元素(不能使用for)
stu = {'name': '张飞', 'age':32, 'score': 89.8}
it = iter(stu)
while True:
try:
item = it.__next__()
print(item, stu[item])
except:
break
13.2生成器generator
实现了__iter__方法的类,是可迭代对象类
实现了__next___方法的类, 是迭代器类。
实现了__iter__、__next___方法的类,就是生成器类。
class MyGenerator: #生成器类
def __init__(self, stop_value):
self.stop_value = stop_value
self.num = 0
def __iter__(self): #返回一个迭代器对象
return self
def __next__(self):
if self.num >= self.stop_value:
raise StopIteration
tmp = self.num
self.num += 1
return tmp
# gen = MyGenerator(10)
# it = iter(gen) #获取可迭代对象的迭代器
# print(it.__next__())
# print(it.__next__())
# print(it.__next__())
#for i in [0,1,2,3,4,5,6,7,8,9] 将所有的数据一次性生成放入内存
for i in MyGenerator(10): #要一个,生成一个
print(i)
生成器, 它是用来创建可迭代对象的一种方式,能够动态(循环一次计算一次返回一次)提供数据的可迭代对象。
在循环过程中,按照某种算法推算数据,不必创建容器存储完整的结果,从而节省内存空间。数据量越大,优势越明显。
以上作用也称之为延迟操作或惰性操作,通俗的讲就是在需要的时候才计算结果,而不是一次构建出所有结果。
**生成器是一种特殊的迭代器。**是一个实现了__iter__ 方法的迭代器。
Python中有两种方式来创建生成器:使用生成器表达式和使用yield关键字定义生成器函数。
13.2.1 生成器函数
yield是一个非常强大的关键字,用于构建一个生成器(generator)对象。当你在函数中使用yield时,这个函数会返回一个生成器,这个迭代器可以一次返回函数中的一个值,而不是一次性返回所有值。这种方式非常适合处理大数据集,因为它不需要在内存中存储整个数据集,而是按需生成数据。
'''
class MyGenerator: #生成器类
def __init__(self, stop_value):
self.stop_value = stop_value
self.num = 0
def __iter__(self): #返回一个迭代器对象
return self
def __next__(self):
if self.num >= self.stop_value:
raise StopIteration
tmp = self.num
self.num += 1
return tmp
gen = MyGenerator(10) #创建一个生成器对象
'''
# 使用yield定义生成器函数
#生成器函数 yield+函数的形式等价于前面设计的类
def my_generator(stop_value):
i = 0
while i < stop_value:
yield i
i += 1
# gen = my_generator(10) # 返回一个生成器对象
# print(type(gen))
for i in my_generator(10):
print(i)
-
执行过程:
- 调用生成器函数会自动创建生成器对象。
- 调用迭代器对象的__next__()方法时才执行生成器函数。
- 每次执行到yield语句时返回数据,暂时离开。
- 待下次调用__next__()方法时继续从离开处继续执行生成器函数。
-
原理: 生成迭代器对象的大致规则如下
- 将yield关键字以前的代码放在next方法中。
-
将yield关键字后面的数据作为next方法的返回值。
练习1:给定一个超大的列表 [1,2,3,4,5,6,7,8,…] 使用生成器函数的方式返回列表中的偶数。
#大的列表放了好多数据 假设这些数据是存储在了硬盘上
l1 = [1,2,3,4,5,6,7,8,9,10,11,12]
#取数据的方式一, 一次性把满足要求的所有都加载到内存
def fun1():
l2 = []
i = 0
while i < len(l1):
if l1[i] % 2 == 0:
l2.append(l1[i])
i += 1
return l2
print(fun1())
# l2 = [x for x in l1 if x%2 ==0]
#方式二 生成器函数, 需要一个 生成一个
def fun2():
i = 0
while i < len(l1):
if(l1[i] %2 == 0):
yield l1[i] #生成一个数据
i += 1 #为生成下一个数据做准备
for x in fun2():
print(x)
练习2:建立一个元素为学生对象的超大列表,使用生成器函数的方式返回学生年龄大于30的元素。
13.2.2 生成器表达式
生成器表达式使用的语法与列表推导式相似,但是它使用小括号()而不是大括号{}。 也称作元组推导式。
语法: 变量 = (表达式 for 变量 in 可迭代对象 if 条件)
gen = (x*x for x in range(10)) #生成器对象
print(gen)
print(type(gen))
#将数据一股脑都加载到了内存
print(tuple([0,1,4,9,16,25,36,49,64,81]))
#用一个生 生成一个
print(tuple(gen))
for i in gen:
print(i)
练习1:使用生成器表达式在列表中获取所有字符串.
练习2:使用生成器表达式在列表中获取所有整数,并计算它的平方.
参考答案:
list01 = [43, "a", 5, True, 6, 7, 89, 9, "b"]
gen = (x for x in list01 if isinstance(x, str))
#for i in ['a', 'b']
for i in gen:
print(i)
l1 = [1,2,'a', 'b', 44, 88, 'c']
gen = (x*x for x in l1 if isinstance(x, int))
for item in gen:
print(item)
13.2.3 内置生成器函数
13.2.3.1 枚举函数enumerate
#遍历可迭代对象时,可以将索引与元素组合为一个元组
l1 = ['a', 'b', 'c', 'd', 'e']
for item in enumerate(l1):
print(item)
for index,value in enumerate(l1):
print(index, value)
练习1: 将列表中的偶数项元素加1
l2 = list(range(100,150, 2))
print(l2)
for index,value in enumerate(l2):
if index%2 ==0 :
l2[index] = value + 1
print(l2)
练习2: 自行实现一个enumerate
def my_enumerate(iterable):
index = 0
for val in iterable:
yield (index, val)
index += 1
l3 = list(range(100,150, 2))
print(l3)
for index,value in my_enumerate(l3):
if index%2 ==0 :
l3[index] = value + 1
print(l3)
13.2.3.2 zip
list_name = ["曹操", "孙权", "刘备"]
list_age = [22, 26, 25]
# for 变量 in zip(可迭代对象1,可迭代对象2)
#将多个可迭代对象中对应的元素组合成一个个元组,生成的元组个数由最小的可迭代对象决定。
for item in zip(list_name, list_age):
print(item)
# ('曹操', 22)
# ('孙权', 26)
# ('刘备', 25)
练习1:使用学生列表封装以下三个列表中数据
list_student_name = [“刘备”, “赵云”, “孙尚香”]
list_student_age = [28, 25, 36]
list_student_sex = [“男”, “男”, “女”]
练习2: 矩阵的转置
# 应用:矩阵转置
map = [
[2, 0, 0, 2],
[4, 2, 0, 2],
[2, 4, 2, 4],
[0, 4, 0, 4]
]
# new_map = []
# for item in zip(map[0],map[1],map[2],map[3]):
# new_map.append(list(item))
# print(new_map)
# new_map = []
# for item in zip(*map):
# new_map.append(list(item))
new_map = [list(item) for item in zip(*map)]
print(new_map)
# [[2, 4, 2, 0], [0, 2, 4, 4], [0, 0, 2, 0], [2, 2, 4, 4]]
练习3: 自行编程实现 zip函数
def my_zip(*args):
#获取所有可迭代对象中元素个数的最小值
min_items = len(args[0])
i = 0
while i< len(args):
if min_items > len(args[i]):
min_items = len(args[i])
i += 1
#min_items决定了zip函数可以生成多少个元组
i = 0
while i < min_items:
res = []
for item in args:
res.append(item[i])
yield tuple(res)
i += 1
l1 = [1,2,3]
l2 = ['a', 'b', 'c']
l3 = ['A', 'B', 'C']
for item in my_zip(l1,l2,l3):
print(item)
14.函数式编程
函数式编程是一种编程范式,强调使用纯函数(无副作用、不修改状态)和函数组合来构建程序。Python作为一门多范式编程语言提供了一些函数式编程特性(由于Python允许使用变量,因此,Python不是纯函数式编程语言),如高阶函数、匿名函数和函数组合,它们可以帮助我们编写简洁、可维护的代码。
使用python函数式编程的特点:
- 函数可以赋值给变量,赋值后变量绑定函数。
- 允许将函数作为参数传入另一个函数。
- 允许函数返回一个函数。
def fun():
print('aaa')
fun() #调用函数
#l1 = [1,2,3]
var = fun #把函数fun绑定到var这个变量
var() #调用函数
14.1 函数作为参数
def fun1():
print('aaa')
def fun2(func):
print('bbb')
func()
fun2(fun1)#func = fun1 var=fun1
这个语法特性有什么用呢?
import random
def fun1(item):
if item > 30:
return True
else:
return False
def fun2(item):
if item %2 == 0:
return True
else:
return False
def fun3(item):
i = 2
while i<item:
if item % i == 0:
return False
i += 1
return True
def Filter(iterable, condition):
for item in iterable:
if condition(item):
yield item
l1 = []
i = 0
while i<100:
l1.append(random.randint(10,150))
i += 1
print(l1)
for i in Filter(l1, fun3):
print(i, end = ' ')
作用:让你的程序灵活性更高。
14.1.1 lambda 函数
Python 使用 lambda 来创建匿名函数 。 它可以具有任意数量的参数,但只能有一个表达式。
lambda 函数特点:
- lambda 函数是匿名的,它们没有函数名称,只能通过赋值给变量或作为参数传递给其他函数来使用。
- lambda 函数主体是一个单个表达式,不能是语句块,这使得它们适用于编写简单的函数。
- 表达式即为匿名函数的返回值
- 表达式不能是赋值操作
lambda 语法格式:
lambda arguments: expression
f = lambda x,y: x+y
print(f(2,3))
f = lambda: "Hello, world!"
print(f()) # 输出: Hello, world!
例如:
import random
def fun1(item):
if item > 30:
return True
else:
return False
def fun2(item):
if item %2 == 0:
return True
else:
return False
def fun3(item):
i = 2
while i<item:
if item % i == 0:
return False
i += 1
return True
def Filter(iterable, condition):
for item in iterable:
if condition(item):
yield item
l1 = []
i = 0
while i<100:
l1.append(random.randint(10,150))
i += 1
print(l1)
for i in Filter(l1, lambda x: x>50 and x<100):
print(i, end = ' ')
练习1:使用以上Filter函数 + lambda 过滤列表中所有能够被3整除的数据
高阶函数:将函数作为参数或返回值的函数。
14.1.2 内置高阶函数
- map(函数,可迭代对象):使用可迭代对象中的每个元素调用函数,将返回值作为新可迭代对象元素;返回值为新可迭代对象。
- filter(函数,可迭代对象):根据条件筛选可迭代对象中的元素,返回值为新可迭代对象。
- max(可迭代对象,key = 函数):根据函数获取可迭代对象的最大值。
- min(可迭代对象,key = 函数):根据函数获取可迭代对象的最小值。
- sorted(iterable, ***, key=None, reverse=False), 排序
class Employee:
def __init__(self, eid, did, name, money):
self.eid = eid # 员工编号
self.did = did # 部门编号
self.name = name
self.money = money
# 员工列表
list_employees = [
Employee(1001, 9002, "刘备", 60000),
Employee(1002, 9001, "诸葛亮", 50000),
Employee(1003, 9002, "曹操", 20000),
Employee(1004, 9001, "贾诩", 30000),
Employee(1005, 9001, "吕布", 15000),
]
# 1. map 映射
# 需求:获取所有员工姓名
for item in map(lambda item: item.name, list_employees):
print(item)
# 2. filter 过滤器
# 需求:查找所有部门是9002的员工
for item in filter(lambda item: item.did == 9002, list_employees):
print(item.__dict__)
# 3. max min 最值
emp = max(list_employees, key=lambda emp: emp.money)
print(emp.__dict__)
# 4. sorted
# 升序排列
new_list = sorted(list_employees, key=lambda emp: emp.money)
print(new_list)
# 降序排列
new_list = sorted(list_employees, key=lambda emp: emp.money, reverse=True)
print(new_list)
练习:前面实现的my_zip函数中有求可迭代对象中元素最小个数的逻辑
def my_zip(*args):
#获取所有可迭代对象中元素个数的最小值
min_items = len(min(*args, key = lambda item:len(item)))
#min_items决定了zip函数可以生成多少个元组
i = 0
while i < min_items:
res = []
for item in args:
res.append(item[i])
yield tuple(res)
i += 1
l1 = [1,2,3]
l2 = ['a', 'b', 'c']
l3 = ['A', 'B', 'C']
for item in my_zip(l1,l2,l3):
print(item)
14.2 函数作为返回值
14.2.1 闭包
Python中的闭包可以通过以下格式进行定义
def outer_function(x):
def inner_function(y): #闭包函数
return x + y
return inner_function
在这个例子中,outer_function就是外层函数,inner_function就是内层函数,它返回的是内层函数的引用。当我们传入一个参数x给外层函数时,它会返回一个内层函数inner_function。因为inner_function保留了外层函数中的变量x的状态,所以在调用inner_function时,我们可以继续使用这个变量。
闭包的三要素:
- 必须有内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数返回值必须是内嵌函数。
语法格式:
def 外部函数名(参数):
外部变量
def 内部函数名(参数):
使用外部变量
return 内部函数名
变量 = 外部函数名(参数)
变量(参数) #调用内部函数
这个内部函数就是被称作闭包函数:
"闭"函数指的是该函数是内嵌函数 , "包"函数指的是该函数包含对外层函数作用域名字的引用(不是对全局作用域) 。
def outer_func(x):
def inner_func(y):
return x+y
return inner_func
func = outer_func(5)
print(type(func))
print(func(3)) #8
14.2.2 函数装饰器decorator
需求:在原有用户登入、登出日志中加入,日志产生时间。
演进一:
import time
def log_time():
print(time.ctime(), end=':')
def user_login():
log_time()
print('用户登录了系统')
def user_logout():
log_time()
print('用户登出了系统')
user_login()
time.sleep(3)
user_logout()
演进二:
def log_time(func):
def wrapper():
print(time.ctime(), end=':')
func()
return wrapper
def user_login():
print('用户登录了系统')
def user_logout():
print('用户登出了系统')
#user_login = 新功能 + 旧功能
user_login = log_time(user_login)
user_logout = log_time(user_logout)
user_login()
time.sleep(3)
user_logout()
演进三:
import time
def log_time(func):
def wrapper():
print(time.ctime(), end=':')
func()
return wrapper
@log_time
def user_login():
print('用户登录了系统')
@log_time
def user_logout():
print('用户登出了系统')
user_login()
time.sleep(3)
user_logout()
演进四:
传参问题,
import time
def log_time(func):
def wrapper(name):
print(time.ctime(), end=':')
func(name)
return wrapper
@log_time
def user_login(name):
print(f'用户{name}登录了系统')
@log_time
def user_logout(name):
print(f'用户{name}登出了系统')
user_login('zhangsan')
time.sleep(3)
user_logout('zhangsan')
演进五:
参数不统一的问题
import time
def log_time(func):
def wrapper(*args, **kwargs):
print(time.ctime(), end=':')
return func(*args, **kwargs)
return wrapper
@log_time
def user_login(role,name):
print(f'{role}:{name}登录了系统')
@log_time
def user_logout(name):
print(f'用户{name}登出了系统')
user_login('管理员', 'zhangsan')
user_login(role ='管理员', name='zhangsan')
time.sleep(3)
user_logout('zhangsan')
装饰器本身就是一个闭包,它可以保留被装饰函数的状态信息,并在被装饰函数执行前后添加额外的功能。
语法格式如下:
def my_decorator(func):
def wrapper(*args, **kwargs):
print("Before the function is called.")
func(*args, **kwargs)
print("After the function is called.")
return wrapper
@my_decorator #使用my_decorator装饰了say_hello函数,使其添加了功能
def say_hello():
print("Hello, world!")
say_hello()
有了装饰器,就可以在不改变原函数的情况下给函数增加新的功能。
练习: 编写装饰器,为每个函数加上统计运行时间的功能
import time
def run_time_outer(func):
def run_time_inner(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
print(f'函数{func.__name__}运行了{end - start}秒的时间')
return run_time_inner
@run_time_outer
def fun1():
i = 0
while i < 10000:
i += 1
@run_time_outer
def fun2():
i = 0
while i < 10000:
j = 0
while j < 10000:
j += 1
i += 1
fun1()
fun2()
14.2.3 内置装饰器
- @property 与 @<attribute_name>.setter
使用@property装饰器可以将一个方法转换为同名只读属性
使用@<attribute_name>.setter装饰器可以将一个方法转换为可写属性的setter方法。
class Stu:
def __init__(self, name, age, score):
self.name = name
self.age = age #1 私有属性正常命名
self.score = score
#如果外界需要读取该私有属性
@property #2 加读相关的装饰器
def age(self): # 3 读相关的函数名称要和私有属性保持一致
return self.__age #6 注意私有属性名称是带__的
@age.setter # 4 加写相关的装饰器
def age(self, newAge):#5 读相关的函数名称要和私有属性保持一致
if newAge<0 or newAge>100:
raise ValueError('年龄不合法')
else :
self.__age = newAge #6 注意私有属性名称是带__的
s1 = Stu('张飞', 21, 80)
num = s1.age
s1.age = 1000 # 语义错误
-
@classmethod
该装饰器把一个类内函数装饰为类方法, 无需实例化可以被直接调用,但是需要接受
cls作为第一个参数传入。类方法不能调用实例属性和实例方法,只能调用类属性和类方法。但是,实例方法可以调用类属性和类方法。
class ExampleClass: class_variable = 10 @classmethod def class_method(cls, x): y = cls.class_variable + x return y print('----- 调用类方法 --------') y = ExampleClass.class_method(100) print('类方法输出:',y) print('----- 类方法调用结束 -----') -
@staticmethod
用于标记一个方法为静态方法。静态方法不接收类的实例(self)或类(cls)作为第一个参数,不需要对类实例化,可以直接被调用,但不能访问类或实例属性。
class Func: @staticmethod def add(x, y): return x + y # 使用静态方法 result = Func.add(3, 4)这些装饰器也是通过闭包来实现的。
15 文件IO
IO, input/output, 指的是数据在内部存储器和外部存储器或其他周边设备之间的输入和输出,即数据在计算机系统和外部世界之间的交换过程。
IO密集型程序, 在程序执行中有大量IO操作,而CPU运算较少。消耗CPU较少,耗时长。
计算密集型程序, 程序运行中计算较多,IO操作相对较少。CPU 消耗多,执行速度快,几乎没有阻塞。
文件,是保存在持久化存储设备(硬盘、U盘、SD卡)上的数据。从功能角度分为文本文件、二进制文件。在Python中把文件视为一种类型的对象。
15.1 字节串
在python3中引入了字节串的概念,与str不同,字节串以字节序列值表达数据。更方便处理二进制数据。因此在python3中字节串是常见的二进制数据展现形式。
-
普通的ascii编码字符串可以在前面加b转换为字节串, 例如: b’hello’
-
字符串转换为字节串方法 : str.encode()
str.encode(encoding=”utf-8”, errors=”strict”) #encoding, 编码的格式 具体支持的编码格式 可以参考 library.pdf P160 常用: utf-8 和 gb2312 -
字节串转换为字符串方法: str.decode()
bytes.decode(encoding=”utf-8”, errors=”strict”)
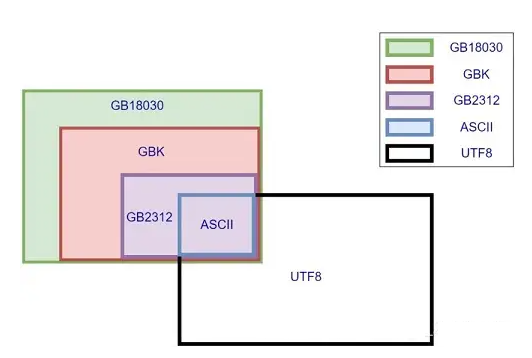
python中文本文件可以使用字符串来表达,二进制文件使用字节串来表达。
所有的字符串都可以转换为字节串,但注意不是所有的字节串都可以转换为字符串。
15.2文件基本操作
文件基本操作包括: 打开文件、 读/写文件、 关闭文件
15.2.1 打开文件
不管是读文件还是写文件,我们第一步都是要将文件打开。 成功打开文件后时候会返回一个文件对象,否则引发一个异常。
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
'''
file, 指定要打开的文件名称(包含路径)
mode, 文件打开方式,共有12种情况
buffering ,缓冲模式的设置
encoding, 文本文件的编码格式
'''
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。read |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。write |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 binary |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。append |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
不带b的操作的是字符串,读出和写入也就是字符串的形式,
带b的操作的是字节串,读出和写入也就是字节串的形式。
文本文件打开方式既可以选择文本方式也可以选择二进制方式。
像图片、音视频只能以二进制方式打开,读写的也就是字节串。
如果不知道要操作的文件是文本形式的还是二进制形式的,那就选二进制方式打开。
#r w a b练习
15.2.2 读文件
读文件的三个函数、四种方式
read(size)
#读取size个字符(字节), 如果省略size,默认取值为-1,代表读取文件所有内容
readline(size)
#每次读取一行(只对文本文件有效).如果省略size,默认为-1,就表示读一行。如果指定size,就是最多读取个数
readlines(size)
#读取文件中的每一行作为列表中的一项。如果省略size,默认为-1,则直接读取到文件末尾。如果指定size表示读取到size字符所在行为止
for line in file: #文件对象本身是一个可迭代对象
#以文本形式打开
f = open('1.txt', 'r', encoding='utf-8')
print(dir(f))
# content = f.read(-1) #读取文件的所有内容到内存
# content = f.readline(20) #读一行 如果当前行超过20个字符,那最多读取20个字符
# content = f.readlines() #读取所有行 每行作为列表中一个元素
# content = f.readlines(50)
#
# print(content)
for item in f:
print(item) #字符串
#按二进制方式打开
f = open('1.txt', 'rb')
print(dir(f))
# content = f.read(-1) #读取文件的所有内容到内存
# content = f.readline(20) #读一行 如果当前行超过20个字符,那最多读取20个字符
# content = f.readlines() #读取所有行 每行作为列表中一个元素
# content = f.readlines(50)
#
# print(content)
for item in f:
print(item) #字节串
#按二进制打开二进制文件
f = open('leader.jpg', 'rb')
content = f.read(30)
print(content)
15.2.3 写文件
写文件的两个函数
write(string)#把文本数据或者二进制数据块写入到文件中去
writelines(str_list) #将字符串列表写入到文件中去
#文本方式
f = open('1.txt', 'w', encoding='utf-8')
f.write('你好\n')
f.writelines(['abc\n', '中国\n', '好热啊\n'])
f.close()
#二进制方式
f = open('1.txt', 'wb')
f.write('你好\n'.encode())
# f.writelines(['abc\n', '中国\n', '好热啊\n'])
f.close()
练习:接收用户输入的源文件名、目标文件名, 实现文件拷贝
import sys
srcName = input('请输入源文件:')
dstName = input('请输入目标文件: ')
try:
srcFile = open(srcName, 'rb')
except Exception as e:
print(e.args)
sys.exit(-1)
dstFile = open(dstName, 'wb')
while True:
data = srcFile.read(1024)
if data:
print(data)
dstFile.write(data)
else:
break
srcFile.close()
dstFile.close()
15.2.4 关闭文件
f.close() # 关闭文件
如果不关闭文件,会占用一定的系统资源
15.3 文件操作的一些细节
15.3.1 with语法
with被称作上下文管理器。
语法格式:
with 表达式 as 变量:
语句块 #其中会使用到上面变量
try:
f = open('1.txt','r')
f.write('hello') # 这一步会引发异常
except IOError as e:
print("文件操作出错",e)
finally:
f.close()
使用 with 关键字,当离开with代码块时,系统可以自动调用f.close()方法.
with open('1.txt', 'r') as f:
f.write('hello')
打开文件就相当于上文,操作文件就相当于文中,关闭文件就相当于下文 。
with的使用在后续梯度计算时也会出现。
15.3.2 缓冲机制
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
'''
file, 指定要打开的文件名称(包含路径)
mode, 文件打开方式,共有12种情况
buffering ,缓冲模式的设置
encoding, 文本文件的编码格式
'''
flush() #强制刷新
缓冲刷新条件:
-
缓冲区满了
-
行缓冲换行时会自动刷新
with open('1.txt', 'w', buffering=1) as f: f.write('hello\n') f.write('world') print('programme over') -
程序运行结束或者close关闭文件
-
调用flush()函数
with open('1.txt', 'w') as f: f.write('hello') f.flush() f.write('world') f.flush() print('programme over')
15.3.3 文件偏移量
记录文件读写操作的位置。
正常打开文件是偏移值为0 ,每读写一次都会根据读写的长度自动调整该偏移值。
如果是追加写入打开文件,偏移位置默认就是文件的长度。
tell()# 获取文件偏移量大小
seek(offset, whence)#重新设置偏移位置
#whence 取值有三种情况
# SEEK_SET 0 定位到从文件开头算起偏移offset个字节的位置
# SEEK_CUR 1 定位到从当前位置开始计算偏移offset个字节的位置
# SEEK_END 2 定位到从文件结束开始偏移offset个字节的位置
#如果是文本方式打开的文件,whence的取值只能是SEEK_SET
#如果是二进制方式打开文件,whence三种取值都可用
import os
with open('1.txt', 'w+', encoding='utf-8') as f:
f.write("hello")
f.write('world')
f.flush()
print(f.tell())
f.seek(0, os.SEEK_SET) #定位到了文件开头位置
content = f.read()
print(f"read from 1.txt: {content}")
print("programme over")
import os
with open('1.txt', 'w+', encoding='utf-8') as f:
f.write("hello")
f.write('world')
f.seek(5, os.SEEK_SET)
f.write('python')
f.seek(0, os.SEEK_SET)
content = f.read()
print(content) #hellopython
print("programme over")
15.3.4文件管理函数
#获取文件大小
os.path.getsize(file)
#查看文件列表
os.listdir(dir)
#查看文件是否存在
os.path.exists(file)
#判断文件是否为普通文件
os.path.isfile(file)
#删除文件
os.remove(file)
import os
print(os.path.getsize('1.txt'))
print(os.listdir(r'F:\python程序设计\code\hqyj\my_project'))
print(os.path.exists('1.txt')) #True
print(os.path.isfile('1.txt')) #True
print(os.path.isfile('my_project')) #False
os.remove('2.txt')
至此,python编程的核心语法就介绍完了。这些语法已经可以满足大家后续机器学习、深度学习的内容了。当然如果你需要使用python做一些其它开发工作,比如爬虫、或者web后端,还需要补充python的网络编程、多进程/线程编程、并发程序设计、RE模块(正则表达式)等知识。
15.2.1 打开文件
不管是读文件还是写文件,我们第一步都是要将文件打开。 成功打开文件后时候会返回一个文件对象,否则引发一个异常。
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
'''
file, 指定要打开的文件名称(包含路径)
mode, 文件打开方式,共有12种情况
buffering ,缓冲模式的设置
encoding, 文本文件的编码格式
'''
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。read |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。write |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 binary |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。append |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
不带b的操作的是字符串,读出和写入也就是字符串的形式,
带b的操作的是字节串,读出和写入也就是字节串的形式。
文本文件打开方式既可以选择文本方式也可以选择二进制方式。
像图片、音视频只能以二进制方式打开,读写的也就是字节串。
如果不知道要操作的文件是文本形式的还是二进制形式的,那就选二进制方式打开。
#r w a b练习
15.2.2 读文件
读文件的三个函数、四种方式
read(size)
#读取size个字符(字节), 如果省略size,默认取值为-1,代表读取文件所有内容
readline(size)
#每次读取一行(只对文本文件有效).如果省略size,默认为-1,就表示读一行。如果指定size,就是最多读取个数
readlines(size)
#读取文件中的每一行作为列表中的一项。如果省略size,默认为-1,则直接读取到文件末尾。如果指定size表示读取到size字符所在行为止
for line in file: #文件对象本身是一个可迭代对象
#以文本形式打开
f = open('1.txt', 'r', encoding='utf-8')
print(dir(f))
# content = f.read(-1) #读取文件的所有内容到内存
# content = f.readline(20) #读一行 如果当前行超过20个字符,那最多读取20个字符
# content = f.readlines() #读取所有行 每行作为列表中一个元素
# content = f.readlines(50)
#
# print(content)
for item in f:
print(item) #字符串
#按二进制方式打开
f = open('1.txt', 'rb')
print(dir(f))
# content = f.read(-1) #读取文件的所有内容到内存
# content = f.readline(20) #读一行 如果当前行超过20个字符,那最多读取20个字符
# content = f.readlines() #读取所有行 每行作为列表中一个元素
# content = f.readlines(50)
#
# print(content)
for item in f:
print(item) #字节串
#按二进制打开二进制文件
f = open('leader.jpg', 'rb')
content = f.read(30)
print(content)
15.2.3 写文件
写文件的两个函数
write(string)#把文本数据或者二进制数据块写入到文件中去
writelines(str_list) #将字符串列表写入到文件中去
#文本方式
f = open('1.txt', 'w', encoding='utf-8')
f.write('你好\n')
f.writelines(['abc\n', '中国\n', '好热啊\n'])
f.close()
#二进制方式
f = open('1.txt', 'wb')
f.write('你好\n'.encode())
# f.writelines(['abc\n', '中国\n', '好热啊\n'])
f.close()
练习:接收用户输入的源文件名、目标文件名, 实现文件拷贝
import sys
srcName = input('请输入源文件:')
dstName = input('请输入目标文件: ')
try:
srcFile = open(srcName, 'rb')
except Exception as e:
print(e.args)
sys.exit(-1)
dstFile = open(dstName, 'wb')
while True:
data = srcFile.read(1024)
if data:
print(data)
dstFile.write(data)
else:
break
srcFile.close()
dstFile.close()
15.2.4 关闭文件
f.close() # 关闭文件
如果不关闭文件,会占用一定的系统资源
15.3 文件操作的一些细节
15.3.1 with语法
with被称作上下文管理器。
语法格式:
with 表达式 as 变量:
语句块 #其中会使用到上面变量
try:
f = open('1.txt','r')
f.write('hello') # 这一步会引发异常
except IOError as e:
print("文件操作出错",e)
finally:
f.close()
使用 with 关键字,当离开with代码块时,系统可以自动调用f.close()方法.
with open('1.txt', 'r') as f:
f.write('hello')
打开文件就相当于上文,操作文件就相当于文中,关闭文件就相当于下文 。
with的使用在后续梯度计算时也会出现。
15.3.2 缓冲机制
open(file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
'''
file, 指定要打开的文件名称(包含路径)
mode, 文件打开方式,共有12种情况
buffering ,缓冲模式的设置
encoding, 文本文件的编码格式
'''
flush() #强制刷新
缓冲刷新条件:
-
缓冲区满了
-
行缓冲换行时会自动刷新
with open('1.txt', 'w', buffering=1) as f: f.write('hello\n') f.write('world') print('programme over') -
程序运行结束或者close关闭文件
-
调用flush()函数
with open('1.txt', 'w') as f: f.write('hello') f.flush() f.write('world') f.flush() print('programme over')
15.3.3 文件偏移量
记录文件读写操作的位置。
正常打开文件是偏移值为0 ,每读写一次都会根据读写的长度自动调整该偏移值。
如果是追加写入打开文件,偏移位置默认就是文件的长度。
tell()# 获取文件偏移量大小
seek(offset, whence)#重新设置偏移位置
#whence 取值有三种情况
# SEEK_SET 0 定位到从文件开头算起偏移offset个字节的位置
# SEEK_CUR 1 定位到从当前位置开始计算偏移offset个字节的位置
# SEEK_END 2 定位到从文件结束开始偏移offset个字节的位置
#如果是文本方式打开的文件,whence的取值只能是SEEK_SET
#如果是二进制方式打开文件,whence三种取值都可用
import os
with open('1.txt', 'w+', encoding='utf-8') as f:
f.write("hello")
f.write('world')
f.flush()
print(f.tell())
f.seek(0, os.SEEK_SET) #定位到了文件开头位置
content = f.read()
print(f"read from 1.txt: {content}")
print("programme over")
import os
with open('1.txt', 'w+', encoding='utf-8') as f:
f.write("hello")
f.write('world')
f.seek(5, os.SEEK_SET)
f.write('python')
f.seek(0, os.SEEK_SET)
content = f.read()
print(content) #hellopython
print("programme over")
15.3.4文件管理函数
#获取文件大小
os.path.getsize(file)
#查看文件列表
os.listdir(dir)
#查看文件是否存在
os.path.exists(file)
#判断文件是否为普通文件
os.path.isfile(file)
#删除文件
os.remove(file)
import os
print(os.path.getsize('1.txt'))
print(os.listdir(r'F:\python程序设计\code\hqyj\my_project'))
print(os.path.exists('1.txt')) #True
print(os.path.isfile('1.txt')) #True
print(os.path.isfile('my_project')) #False
os.remove('2.txt')
至此,python编程的核心语法就介绍完了。这些语法已经可以满足大家后续机器学习、深度学习的内容了。当然如果你需要使用python做一些其它开发工作,比如爬虫、或者web后端,还需要补充python的网络编程、多进程/线程编程、并发程序设计、RE模块(正则表达式)等知识。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









