







1.引言
算法,是计算机科学中的重要概念,它是一种解决问题的方法和步骤。在计算机科学中,算法是一种用于解决问题的有限步骤的序列。作为一个程序员,掌握一些常见的算法和数据结构是非常重要的,它们可以帮助解决各种问题并优化程序的效率。
算法的重要性:
- 解决问题:算法是解决问题的关键步骤。它们提供了系统性的方法和步骤,用于处理和解决各种复杂的计算和实际问题。
- 自动化和效率提升:算法可以自动执行特定任务,减少人工操作和时间成本,提高工作效率。通过自动化处理,算法可以快速处理大规模数据和任务,提供高效的解决方案。
- 数据分析和决策支持:算法能够从大量数据中提取有价值的信息,进行数据分析和模式识别,为决策制定提供科学依据。它们可以发现数据中的隐藏模式和趋势,帮助人们做出准确的决策。
- 优化和改进:算法可以优化现有流程、系统或产品,提升性能、质量或用户体验。它们能够发现问题的瓶颈并提供改进的方案,使得系统或产品更加高效和可靠。
- 预测和预防:算法可以通过分析历史数据和模式,进行预测和预测未来事件的可能性。这对于预防潜在风险、优化资源分配和制定战略决策非常重要。
总之,算法在计算机科学和各个领域中扮演着重要的角色。它们不仅仅是计算机程序的核心,也是推动技术进步和创新的关键驱动力。算法的选择和设计对于问题的解决和结果的质量至关重要。
算法的应用场景:
- 机器学习和数据挖掘:算法在机器学习和数据挖掘中被广泛应用,用于模式识别、分类、聚类、回归分析、推荐系统等任务。这些算法可以从大量的数据中发现模式、进行预测和决策支持。
- 图像处理和计算机视觉:算法在图像处理和计算机视觉领域中发挥重要作用,如目标检测、图像识别、人脸识别、图像分割等。这些算法可以对图像和视频进行分析和处理,实现自动化的视觉任务。
- 自然语言处理:算法在自然语言处理中被广泛应用,包括文本分类、情感分析、机器翻译、信息检索等任务。这些算法可以处理和理解人类语言的文本数据,实现智能化的语言处理和交互。
- 优化和调度:算法在优化问题和调度问题中具有重要应用,如生产调度、路径规划、资源分配等。这些算法可以找到最优解决方案,提高效率和资源利用率。
- 金融和风险分析:算法在金融领域中应用广泛,如股票预测、风险评估、信用评分等。这些算法可以分析市场趋势、预测风险和支持决策制定。
- 医疗诊断和辅助:算法在医疗领域中用于辅助诊断、医学图像分析、基因组学研究等。这些算法可以帮助医生进行疾病诊断和治疗方案的制定。
- 物流和交通管理:算法在物流和交通管理中被广泛应用,如路径规划、交通流量优化、货物配送等。这些算法可以提高物流效率和交通运输的安全性。
这只是一小部分算法应用的场景,实际上,算法在各个领域都有重要的应用,推动了科技的发展和社会的进步。
程序员需要掌握算法的原因:
- 解决复杂问题:算法是解决复杂问题的基础。掌握算法可以帮助程序员设计和实现高效的解决方案,处理大规模的数据和复杂的逻辑。
- 提高效率:优秀的算法可以显著提高程序的执行效率。通过选择合适的数据结构和算法,程序员可以降低时间和空间复杂度,提高程序的性能和响应速度。
- 优化资源利用:算法可以帮助程序员优化资源的利用。合理的算法设计可以节省内存和处理器资源,提高系统的可扩展性和稳定性。
- 解决实际问题:算法是解决实际问题的核心。掌握算法可以帮助程序员分析问题、制定解决方案,并将其转化为可执行的代码。
- 理解和应用新技术:许多新兴技术和领域都依赖于算法的支持,如人工智能、机器学习、大数据分析等。掌握算法可以帮助程序员理解和应用这些新技术,拓展自己的技术领域。
- 面试和职业发展:在面试过程中,算法和数据结构是被广泛考察的内容。掌握算法可以帮助程序员在面试中展示自己的能力,并提升职业发展的机会。
总而言之,算法是程序员必备的核心技能之一。掌握算法可以提高问题解决能力、提升程序性能、应用新技术,并在职业发展中具备竞争优势。
2.常见算法分析
- 排序算法:如冒泡排序、插入排序、选择排序、快速排序、归并排序等,用于对数据进行排序。
- 搜索算法:如线性搜索、二分搜索、广度优先搜索(BFS)、深度优先搜索(DFS)、A*搜索等,用于在数据集中查找特定元素或寻找最优路径。
- 图算法:如最短路径算法(Dijkstra算法、Floyd-Warshall算法)、最小生成树算法(Prim算法、Kruskal算法)、拓扑排序算法等,用于处理图结构中的问题。
- 动态规划算法:如背包问题、最长公共子序列、最大子数组和等,用于解决具有重叠子问题性质的问题。
- 贪心算法:如霍夫曼编码、最小生成树算法(Prim算法、Kruskal算法)、任务调度等,通过每一步选择局部最优解来得到全局最优解。
- 图像处理算法:如边缘检测(Sobel算子、Canny算子)、图像分割(k-means聚类、分水岭算法)、图像识别(卷积神经网络、SIFT特征提取)等,用于处理图像数据的分析和处理。
- 机器学习算法:如线性回归、逻辑回归、决策树、支持向量机、随机森林、神经网络等,用于模式识别、分类、聚类、回归等机器学习任务。
- 数据压缩算法:如哈夫曼编码、LZW编码、LZ77算法、LZ78算法等,用于压缩和解压缩数据。
- 加密算法:如对称加密算法(DES、AES)、非对称加密算法(RSA、Diffie-Hellman)、哈希函数(MD5、SHA-1)等,用于数据加密和安全通信。
- 字符串算法
- 并行和分布式算法

3.排序算法
十大经典算法分别是:冒泡排序,插入排序,选择排序,希尔排序,快速排序,归并排序,桶排序,堆排序,计数排序,基数排序。
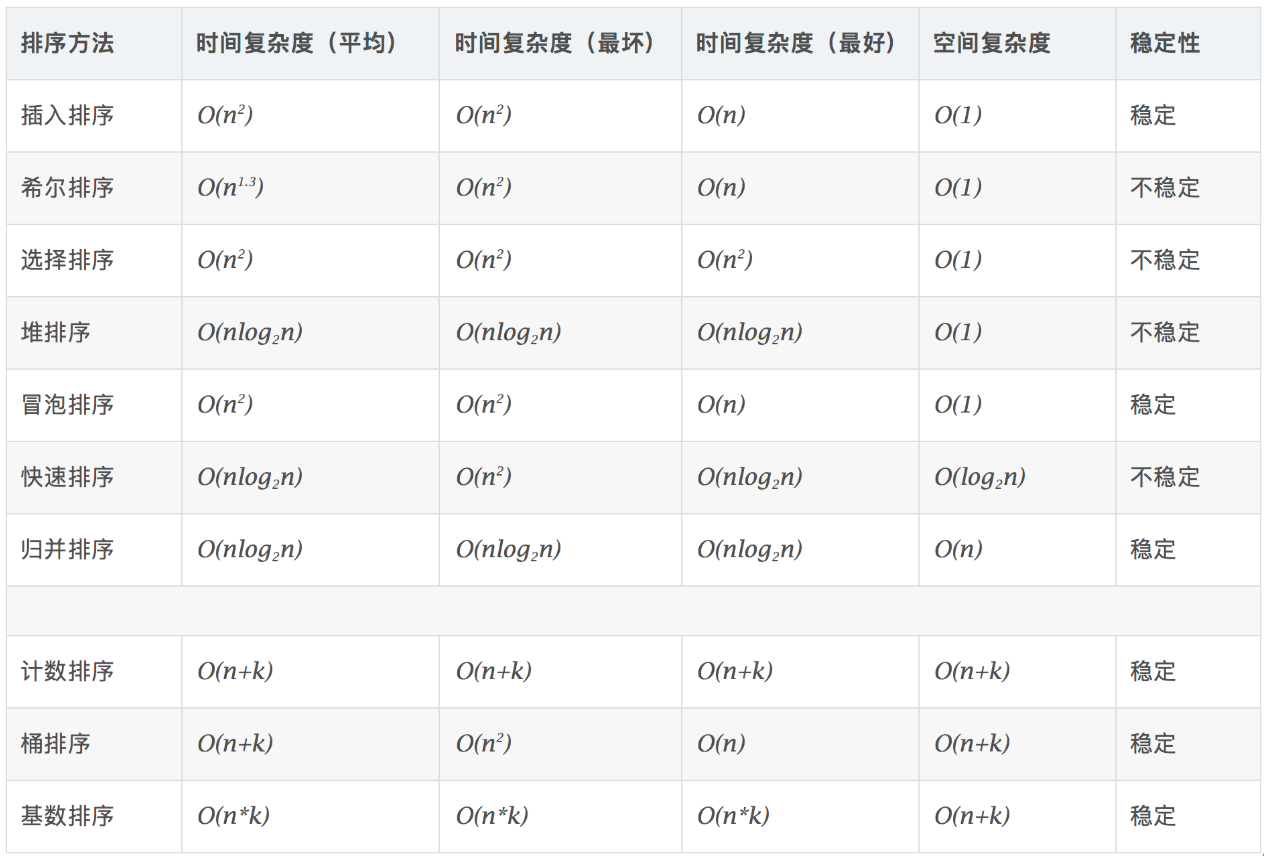
算法稳定性:
如果 a==b,排序前 a 在 b 的前面,排序后 a 在 b 的后面,只要会出现这种现象,我们则说这个算法不稳定(即使两个相等的数,在排序的过程中不断交换,有可能将后面的 b 交换到 a 的前面去)。
算法复杂度:
3.1冒泡排序
冒泡排序(Bubble Sort)是基于交换的排序,它重复走过需要排序的元素,依次比较相邻的两个元素的大小,保证最后一个数字一定是最大的,即它的顺序已经排好,下一轮只需要保证前面 n-1 个元素的顺序即可。
之所以称为冒泡,是因为最大/最小的数,每一次都往后面冒,就像是水里面的气泡一样。
3.1.1 算法描述
排序的步骤如下:
1.从头开始,比较相邻的两个数,如果第一个数比第二个数大,那么就交换它们位置。
2.从开始到最后一对比较完成,一轮结束后,最后一个元素的位置已经确定。
3.除了最后一个元素以外,前面的所有未排好序的元素重复前面两个步骤。
4.重复前面 1 ~ 3 步骤,直到都已经排好序。
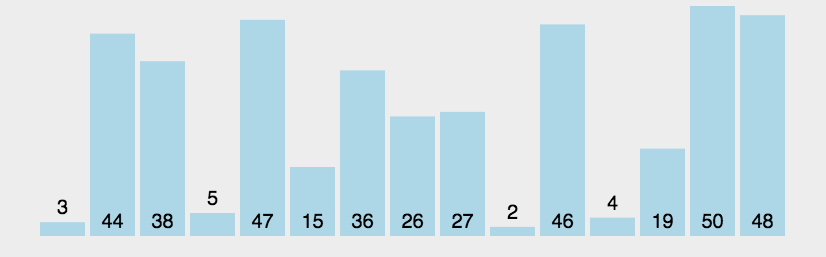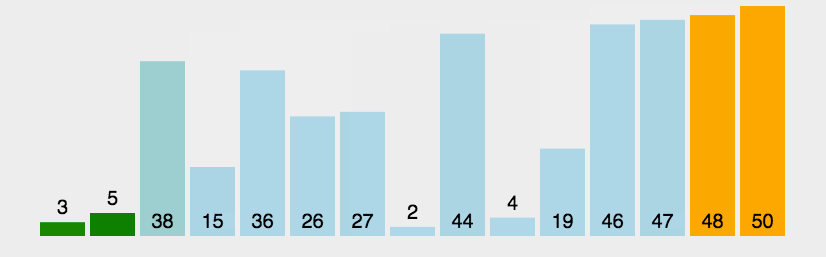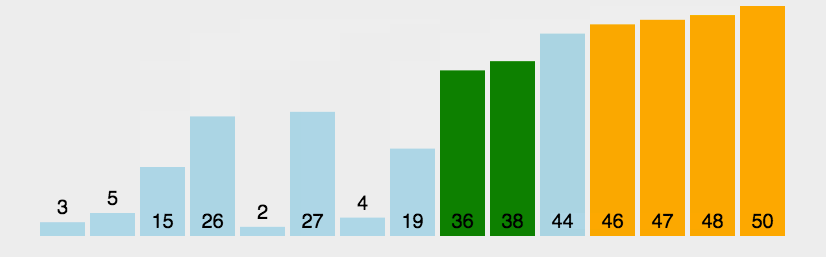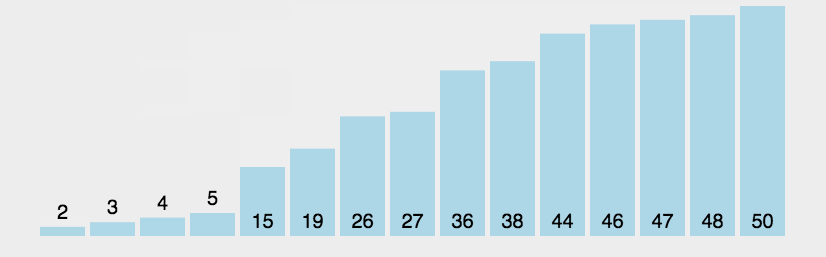
3.1.2 算法实现
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#define N 10
void bubble_sort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) { // 相邻元素两两对比
int temp = arr[j]; // 元素交换
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main() {
int arr[N] = {0};
int i = 0;
srand(time(NULL));
for(; i<N; i++){
arr[i] = random()%100;
}
printf("排序前:");
for (int i = 0; i < N; i++) {
printf("%d ", arr[i]);
}
printf("\n");
bubble_sort(arr, N);
printf("排序后: ");
for (int i = 0; i < N; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
3.2 选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
表现最稳定的排序算法之一,因为无论什么数据进去都是O( n 2 n^2 n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。
3.2.1算法描述
n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下:
- 初始状态:无序区为R[1…n],有序区为空;
- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1…i-1]和R(i…n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1…i]和R[i+1…n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
- n-1趟结束,数组有序化了。
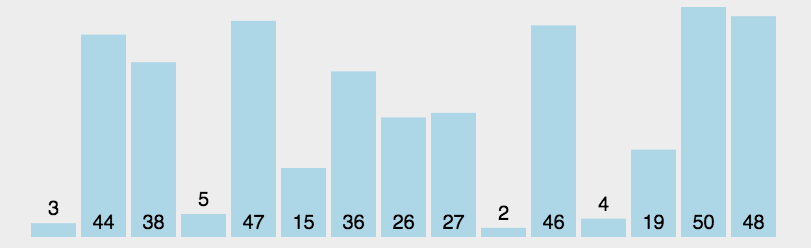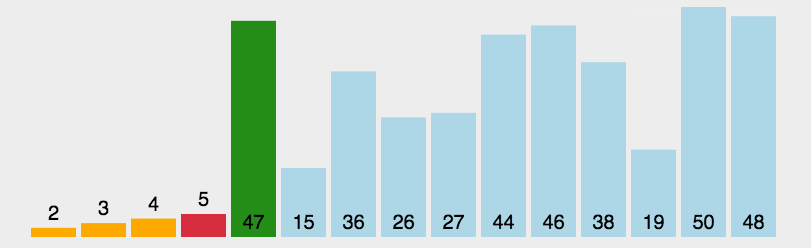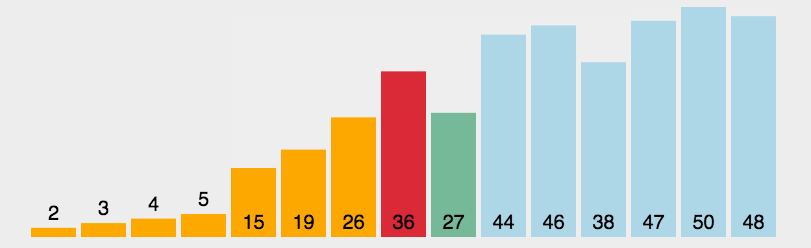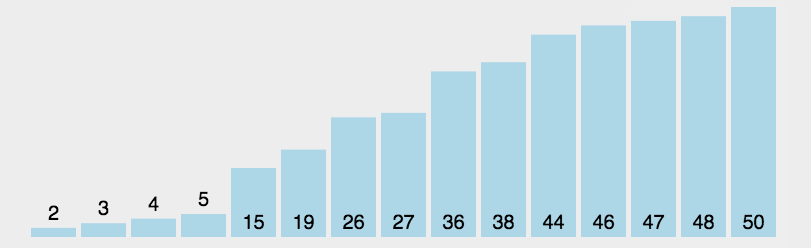
3.2.2 算法实现
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 10
void select_sort(int a[],int n){
int i,j,min,temp=0; //变量i,j用来遍历数组,min用来标记最小值的位置,temp用于交换两个变量的值
for(i=0;i<n-1;i++){ //从第1个元素开始遍历到第n-1个元素
min=i; //每一轮遍历都先将i的值赋给min,默认a[i]是最小元素
for(j=i+1;j<n;j++){ //从第i+1开始遍历,并逐一与a[i]进行比较
if(a[min]>a[j]) //若a[min]>a[j]则将j的值赋给min,用来记录当前最小元素的位置
min=j;
}
if(min!=i){ //当a[i]与待比较的元素比较完后,若min的位置与i不一致
temp=a[i]; //那么就将最小的元素a[min]与a[i]进行交换
a[i]=a[min];
a[min]=temp;
}
}
}
int main(){
int a[N]={};
int i = 0;
srand(time(NULL));
for(; i<N; i++){
a[i] = random()%100;
}
printf("排序前的数组:\n");
for(int i=0;i<N;i++) //遍历排序前的数组
printf("%d ",a[i]);
printf("\n");
select_sort(a,N); //使用选择排序算法
printf("排序后的数组:\n");
for(int i=0;i<N;i++) //遍历排序后的数组
printf("%d ",a[i]);
printf("\n");
return 0;
}
3.2.3 算法分析
表现最稳定的排序算法之一,因为无论什么数据进去都是O( n 2 n^2 n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。
与冒泡排序的区别:
-
冒泡排序是比较相邻位置的两个数,而选择排序是按顺序比较,找最大值或者最小值。
-
冒泡排序每一轮比较后,位置不对都需要换位置,选择排序每一轮比较最多只需要换一次位置。
-
冒泡排序是通过数去找位置,选择排序是给定位置去找数。
-
冒泡排序属于稳定排序,选择排序是不稳定排序 (举个例子5,8,5,2,9 我们知道第一遍选择第一个元素5会和2交换,那么原序列中2个5的相对位置前后顺序就破坏了)。
3.3 插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
选择排序是从未排序中找出最小的,排入有序序列的尾部,
插入排序是从未排序序列中随机取出一个, 插入都有序序列,保持有序序列依然有序。
3.3.1 算法描述
一般来说,插入排序都采用in-place( 即只需用到O(1)的额外空间 )在数组上实现。具体算法描述如下:
1.从第一个元素开始,该元素可以认为已经被排序;
2.取出下一个元素,在已经排序的元素序列中从后向前扫描;
3.如果该元素(已排序)大于新元素,将该元素移到下一位置;
4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
5.将新元素插入到该位置后;
6.重复步骤2~5。
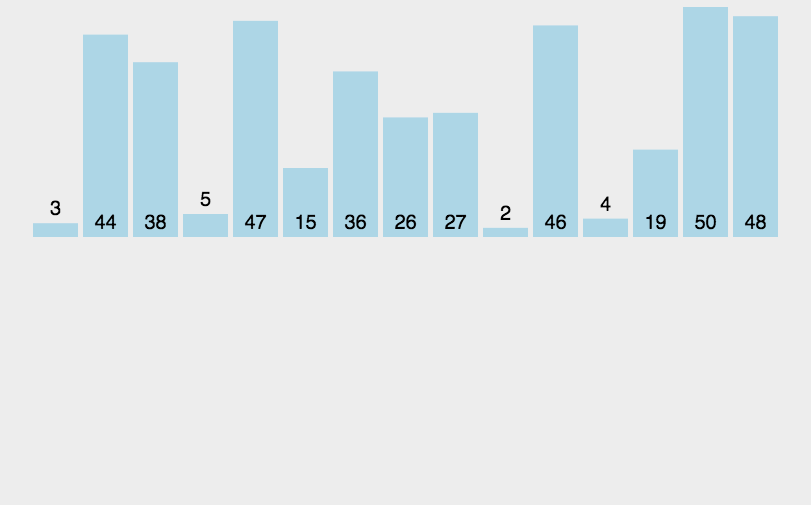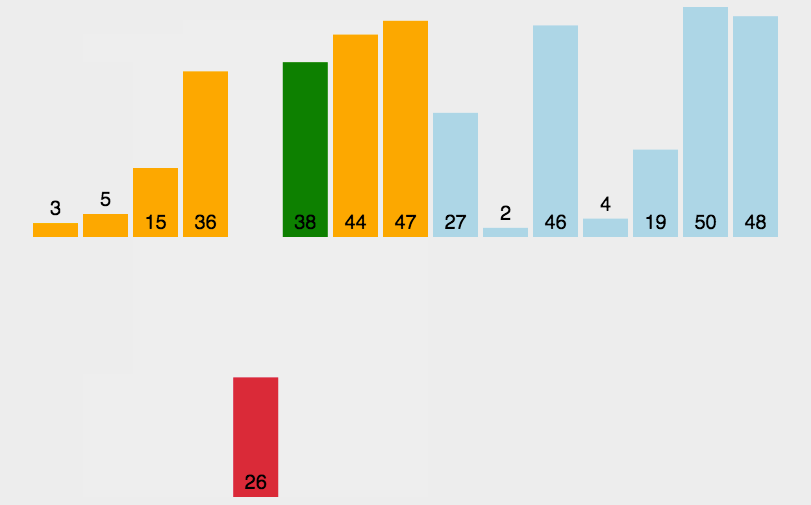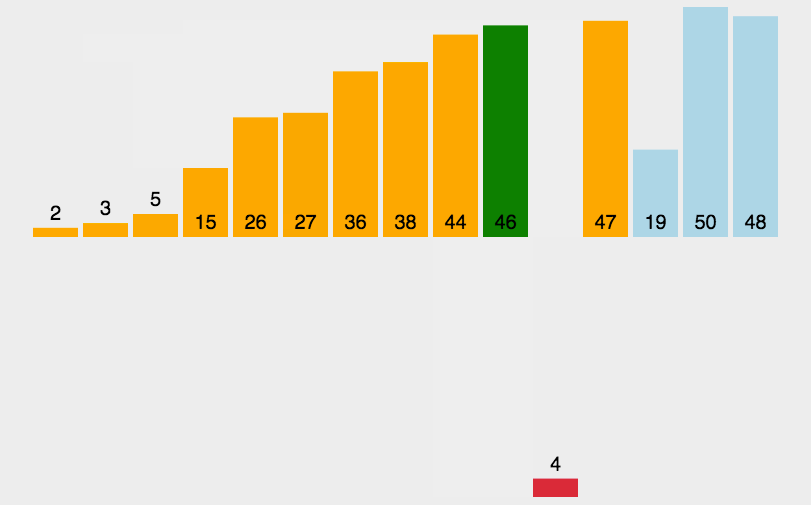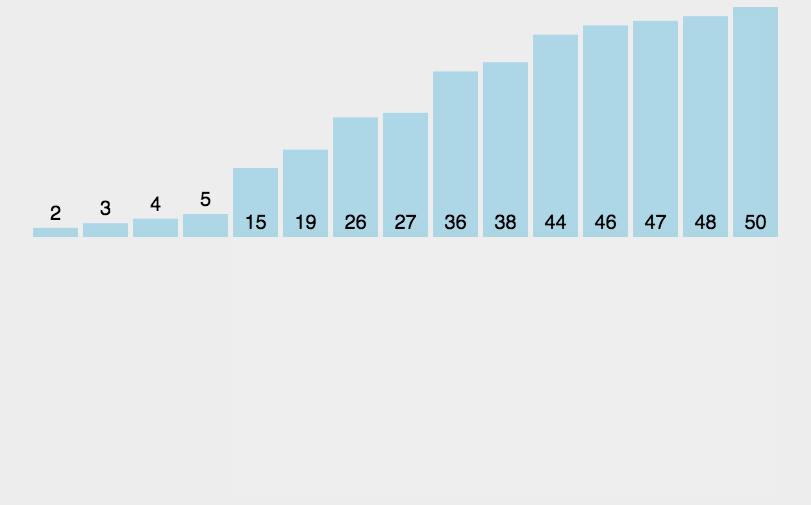
3.3.2 算法实现
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#define N 10
//插入排序
void insert_sort(int arr[], int n)
{
int i = 1;
for (i = 1; i < n; i++)
{
int end = i - 1;
int tmp = arr[i];
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}
//打印数据
void print(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[N] = {0};
int i = 0;
srand(time(NULL));
for(; i<N; i++){
arr[i] = random()%100;
}
printf("排序前:");
print(arr, N);
insert_sort(arr, N);
printf("排序后:");
print(arr, N);
return 0;
}
3.3.3 算法分析
稳定排序。
3.4 希尔排序
1959年Shell发明,第一个突破O( n 2 n^2 n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。
3.4.1 算法描述
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
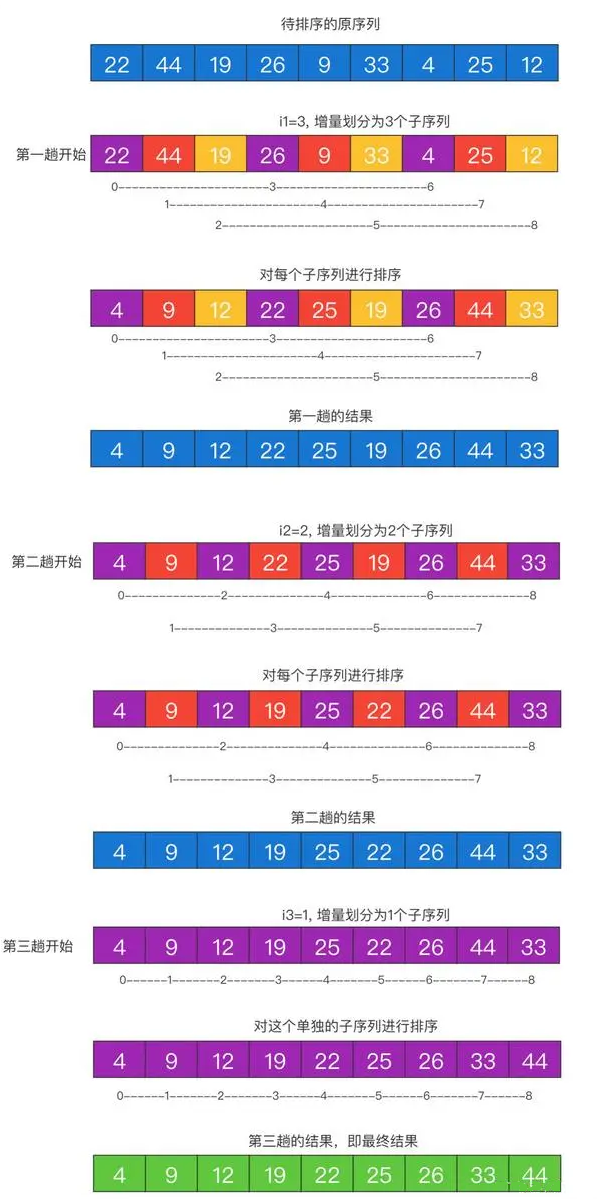
如何选择增量序列呢? 已经提出很多种增量序列,其中一种常用的增量序列可以根据公式$2^(t - k + 1) $- 1计算,参数t是一共要进行的趟数(可自行选择), 而k代表每一趟。 通过以上公式可以算出每趟的增量值(gap)。也可以使用其它方式设置趟数以及增量。下面的示例代码并未使用以上公式。
3.4.2 算法实现
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 10
//希尔排序
//由小到大
//希尔排序
void shell_sort( int array[], int length)
{
int i;
int j;
int k;
int gap; //gap是分组的步长
long int temp; //希尔排序是在直接插入排序的基础上实现的,所以仍然需要哨兵
for(gap=length/2; gap>0; gap=gap/2)//希尔排序的趟数
{
//以GAP为间隔分组
for(i=0; i<gap; i++)//有几个子序列就循环几次
{
/*
每一组做插入排序
*/
for(j=i+gap; j<length; j=j+gap)//对特定的每个子序列做插入排序
{
//如果当前元素比这一组中的前一个元素要小
if(array[j] < array[j - gap])
{
//记录当前这个更小的元素 temp
temp = array[j]; //哨兵
k = j - gap;
//把这一组中之前所有比temp小的元素都往后挪一个位置
while(k>=0 && array[k]>temp)
{
array[k + gap] = array[k];
k = k - gap;
}
//把挪出来的空位,放入temp
array[k + gap] = temp;
}
}
}
}
}
//打印数据
void print(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[N] = {0};
int i = 0;
srand(time(NULL));
for(; i<N; i++){
arr[i] = random()%100;
}
printf("排序前:");
print(arr, N);
shell_sort(arr, N);
printf("排序后:");
print(arr, N);
return 0;
}
3.4.3 算法分析
希尔排序适用于中规模数据量的排序。
3.5 归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.5.1算法描述(递归思想)
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
假如初始序列含有 n 个记录,则可以看成是 n 个有序的子序列,每个子序列的长度为 1。然后两两归并,得到 n/2 个长度为2或1的有序子序列;再两两归并,……,如此重复,直到得到一个长度为 n 的有序序列为止,这种排序方法称为 二路归并排序。
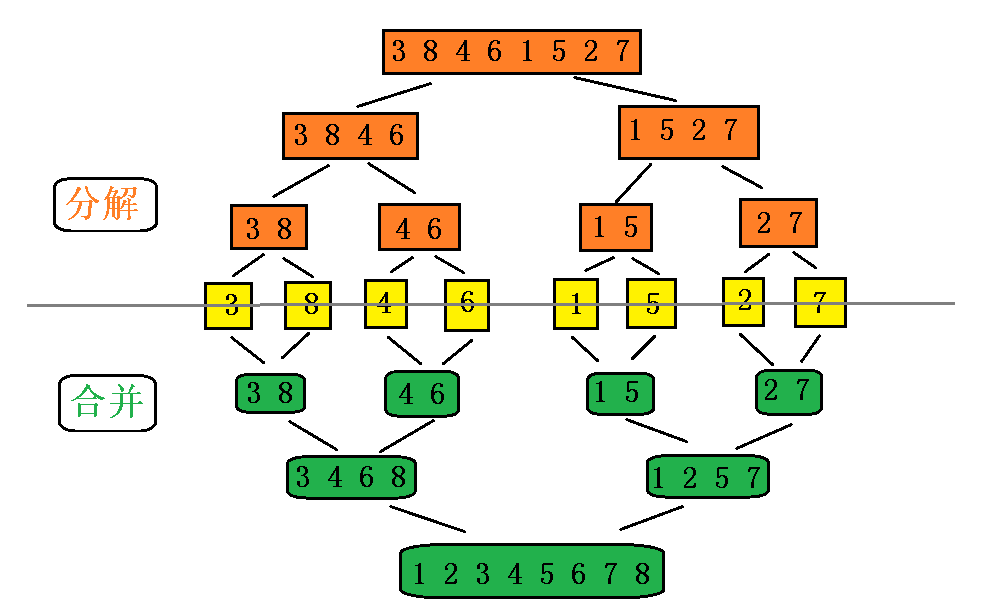
3.5.2 算法实现
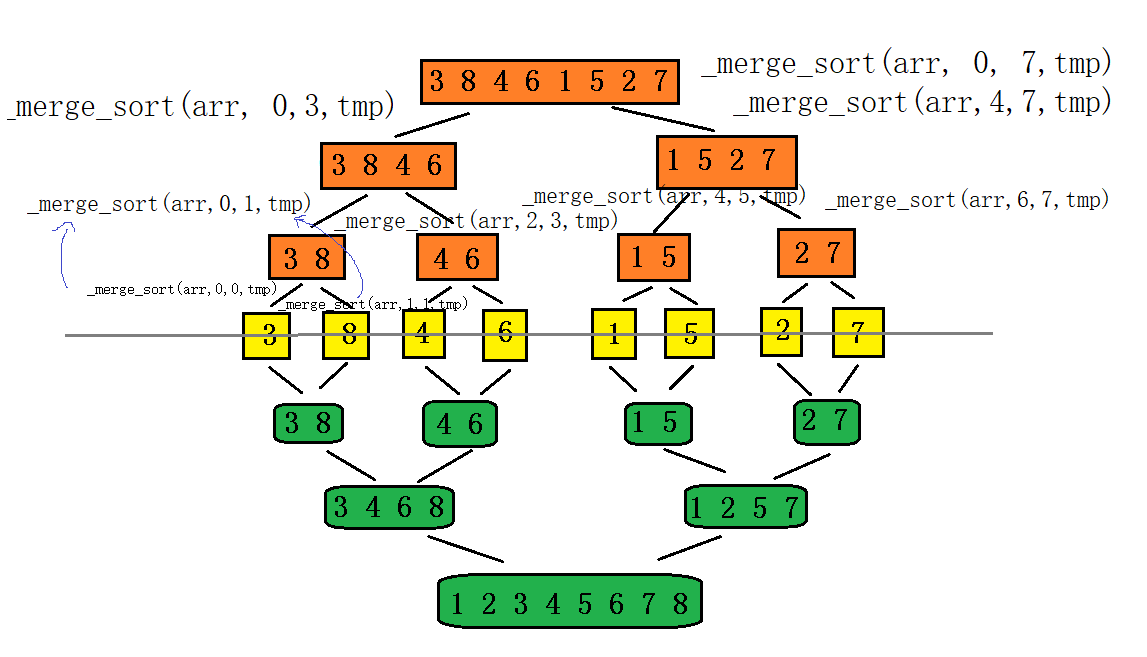
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 10
void _merge_sort(int* arr, int left, int right,int* tmp)
{
if (left >= right)//=为只有一个数,>超出范围
{
return;
}
//左右区间如果没有序,分治递归分割区间,直到最小,
int mid = (left + right) >> 1;
//区间被分为[left,mid] 和 [mid+1,right]
//开始递归
_merge_sort(arr, left, mid, tmp);
_merge_sort(arr, mid + 1, right, tmp);
//此时通过递归已经能保证左右子区间有序
//开始归并
int begin1 = left;
int end1 = mid;
int begin2 = mid + 1;
int end2 = right;
//归并时放入临时数组的位置从left开始
int index = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[index] = arr[begin1];
index++;
begin1++;
//这三行代码可以写成一行
//tmp[index++] = arr[begin1++];
}
else
{
tmp[index++] = arr[begin2++];
}
}
//循环结束,将还没遍历完的那个区间剩下的数拷贝下来
while (begin1 <= end1)
{
tmp[index++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = arr[begin2++];
}
//将排归并完的数拷贝回原数组
for (int i = left; i <=right ; i++)
{
arr[i] = tmp[i];
}
}
void merge_sort(int* arr, int n)
{
//申请一个空间用来临时存放数据
int* tmp = (int*)malloc(sizeof(int)*n);
//归并排序
_merge_sort(arr, 0, n - 1, tmp);
//释放空间
free(tmp);
}
//打印数据
void print(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[N] = {0};
int i = 0;
srand(time(NULL));
for(; i<N; i++){
arr[i] = random()%100;
}
printf("排序前:");
print(arr, N);
merge_sort(arr, N);
printf("排序后:");
print(arr, N);
return 0;
}
3.5.3 算法分析
归并排序中,用到了一个临时数组,故空间复杂度为O(N) , 归并排序的形式就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的可以得出它的时间复杂度是O( N log 2 N N\log_2N Nlog2N) 。它属于稳定排序, 性能不受输入数据是否有序的影响 , 归并排序中的比较次数是所有排序中最少的。原因是,它一开始是不断地划分,比较只发生在合并各个有序的子数组时。
3.6 快速排序
是冒泡排序的改进版,之所以“快速”,是因为使用了分治法。 在序列中随机挑选一个元素作基准, 将序列分成两部分,比基准元素小的放在左边,比基准元素大的放在右边,递归地对左右两部分进行排序。
3.6.1算法描述
以一个无序数列:4、5、8、1、7、2、6、3,我们要将它按从小到大排序。按照快速排序的思想,我们先选择一个基准元素,进行排序:

- 选取4为我们的基准元素,并设置基准元素的位置为index,设置两个指针left和right,分别指向最左和最右两个元素:

-
接着,从right指针开始,把指针所指向的元素和基准元素做比较,如果比基准元素大,则right指针向左移动,如果比基准元素小,则把right所指向的元素填入index中:
3和4比较,3比4小,将3填入index中,原来3的位置成为了新的index,同时left右移一位

-
然后,切换left指针进行比较,如果left指向的元素小于基准元素,则left指针向右移动,如果元素大于基准元素,则把left指向的元素填入index中:
5和4比较,5比4大,将5填入index中,原来5的位置成为了新的index,同时right左移一位

- 接下来,我们再切换到right指针进行比较,6和4比较,6比4大,right指针左移一位
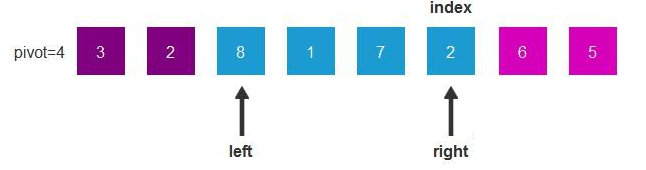
- 随着left右移,right左移,最终left和right重合
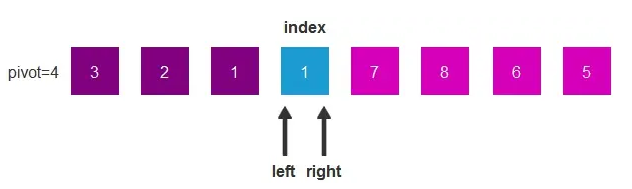
此时,我们将基准元素填入index中,这时,基准元素左边的都比基准元素小,右边的都比基准元素大,这一轮交换结束。
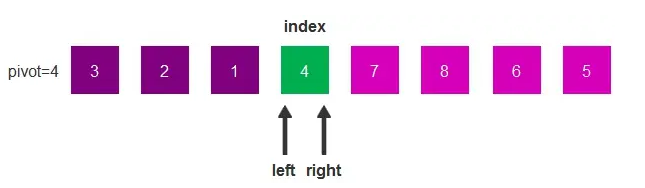
第一轮,基准元素4将序列分成了两部分,左边小于4,右边大于4,第二轮则是对拆分后的两部分进行比较
- 此时,我们有两个序列需要比较,分别是3、2、1和7、8、6、5,重新选择左边序列的基准元素为3,右边序列的基准元素为7

第二轮排序结束后,结果如下所示

-
此时,3、4、7为前两轮的基准元素,是有序的,7的右边只有8一个元素也是有序的,因此,第三轮,我们只需要对1、2和5、6这两个序列进行排序:

第三轮排序结果如下所示:

3.6.2 算法实现
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define N 10
// 参数说明:
// a -- 待排序的数组
// l -- 数组的左边界(例如,从起始位置开始排序,则l=0)
// r -- 数组的右边界(例如,排序截止到数组末尾,则r=a.length-1)
void quick_sort(int a[], int l, int r) {
if (l < r) {
int i, j, x;
i = l;
j = r;
x = a[i];
while(i<j) {
while (i<j && a[j]>x) {
j--; // 从右向左找第一个小于x的数
}
if (i < j) {
a[i++] = a[j]; // 将小于x的值放在左边
}
while (i < j && a[i] < x) {
i++; // 从左向右找第一个大于x的数
}
if (i < j) {
a[j--] = a[i]; // 将大于x的值放在右边
}
}
a[i] = x;
quick_sort(a, l, i - 1);
quick_sort(a, i+1, r);
}
}
//打印数据
void print(int arr[], int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[N] = {0};
int i = 0;
srand(time(NULL));
for(; i<N; i++){
arr[i] = random()%100;
}
printf("排序前:");
print(arr, N);
quick_sort(arr, 0, N-1);
printf("排序后:");
print(arr, N);
return 0;
}
3.6.3 算法分析
快速排序是不稳定排序。
C语言的标准库中提供了快速排序的函数,供编程者调用。
//void qsort(void *base, size_t nmemb, size_t size,int (*compar)(const void *, const void *));
# include<stdio.h>
# include<stdlib.h>
int cmp_t(const void* p1, const void* p2) {
return(*(int*)p1 - *(int*)p2);
}
int main() {
int arr[] = { 1,7,6,4,5,9,3,2,0,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_t);
int i = 0;
for (i = 0; i < sz; i++) {
printf("%d ", arr[i]);
}
return 0;
}
3.7 堆排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.7.1算法描述
3.7.2 算法实现
3.7.3 算法分析
3.8 计数排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.8.1算法描述
3.8.2 算法实现
3.8.3 算法分析
3.9 桶排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.9.1算法描述
3.9.2 算法实现
3.9.3 算法分析
3.10 基数排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.10.1算法描述
3.10.2 算法实现
3.10.3 算法分析
序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.7.1算法描述
3.7.2 算法实现
3.7.3 算法分析
3.8 计数排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.8.1算法描述
3.8.2 算法实现
3.8.3 算法分析
3.9 桶排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.9.1算法描述
3.9.2 算法实现
3.9.3 算法分析
3.10 基数排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
3.10.1算法描述
3.10.2 算法实现
3.10.3 算法分析















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









