







在当今快速发展的AI技术领域,大语言模型(LLM)的应用日益广泛,特别是在问答系统(QA)的构建上。传统的文本切片方法通常基于token数量进行,但在处理复杂文档时,这种方法可能会导致核心内容被切割到不同的段落,影响问答系统的效果。为了解决这一问题,本文将深入探讨如何利用KernelMemory(KM)进行QA问答切片,以实现更精准的内容划分和更丰富的问答场景。
KernelMemory简介
KernelMemory是一个强大的工具,它支持自定义编排,允许我们根据内容生成QA问答,而不是仅仅基于token数量进行切片。在KM中,我们可以添加多种处理器,如文档解析、文档切片、向量处理、总结和保存向量等。这些处理器为我们提供了文档处理的全流程支持。
https://github.com/microsoft/kernel-memorymemory.Orchestrator.AddHandler<TextExtractionHandler>("extract_text");
memory.Orchestrator.AddHandler<TextPartitioningHandler>("split_text_in_partitions");
memory.Orchestrator.AddHandler<GenerateEmbeddingsHandler>("generate_embeddings");
memory.Orchestrator.AddHandler<SummarizationHandler>("summarize");
memory.Orchestrator.AddHandler<SaveRecordsHandler>("save_memory_records");我们可以看到 这个是KM提供的默认编排,分别是文档的解析,文档的切片、向量的处理、总结、和保存向量。然后我们在做QA切片时需要保留文档解析部分,不然这部分自己解析各种文档会比较麻烦,所以我们需要写一个自定义的Handle去替换 TextPartitioningHandler
自定义QA处理器
在进行QA切片时,我们需要保留文档解析部分,以便能够处理各种格式的文档。为此,我们可以编写一个自定义的处理器来替换默认的TextPartitioningHandler。下面是一个自定义QAHandler的示例代码:
public class QAHandler : IPipelineStepHandler
{
private readonly TextPartitioningOptions _options;
private readonly IPipelineOrchestrator _orchestrator;
private readonly ILogger<QAHandler> _log;
private readonly TextChunker.TokenCounter _tokenCounter;
public QAHandler(
string stepName,
IPipelineOrchestrator orchestrator,
TextPartitioningOptions? options = null,
ILogger<QAHandler>? log = null
)
{
this.StepName = stepName;
this._orchestrator = orchestrator;
this._options = options ?? new TextPartitioningOptions();
this._options.Validate();
this._log = log ?? DefaultLogger<QAHandler>.Instance;
this._tokenCounter = DefaultGPTTokenizer.StaticCountTokens;
}
/// <inheritdoc />
public string StepName { get; }
/// <inheritdoc />
public async Task<(bool success, DataPipeline updatedPipeline)> InvokeAsync(
DataPipeline pipeline, CancellationToken cancellationToken = default)
{
this._log.LogDebug("Partitioning text, pipeline '{0}/{1}'", pipeline.Index, pipeline.DocumentId);
if (pipeline.Files.Count == 0)
{
this._log.LogWarning("Pipeline '{0}/{1}': there are no files to process, moving to next pipeline step.", pipeline.Index, pipeline.DocumentId);
return (true, pipeline);
}
foreach (DataPipeline.FileDetails uploadedFile in pipeline.Files)
{
// Track new files being generated (cannot edit originalFile.GeneratedFiles while looping it)
Dictionary<string, DataPipeline.GeneratedFileDetails> newFiles = new();
foreach (KeyValuePair<string, DataPipeline.GeneratedFileDetails> generatedFile in uploadedFile.GeneratedFiles)
{
var file = generatedFile.Value;
if (file.AlreadyProcessedBy(this))
{
this._log.LogTrace("File {0} already processed by this handler", file.Name);
continue;
}
// Partition only the original text
if (file.ArtifactType != DataPipeline.ArtifactTypes.ExtractedText)
{
this._log.LogTrace("Skipping file {0} (not original text)", file.Name);
continue;
}
// Use a different partitioning strategy depending on the file type
List<string> partitions;
List<string> sentences;
BinaryData partitionContent = await this._orchestrator.ReadFileAsync(pipeline, file.Name, cancellationToken).ConfigureAwait(false);
// Skip empty partitions. Also: partitionContent.ToString() throws an exception if there are no bytes.
if (partitionContent.ToArray().Length == 0) { continue; }
switch (file.MimeType)
{
case MimeTypes.PlainText:
case MimeTypes.MarkDown:
{
this._log.LogDebug("Partitioning text file {0}", file.Name);
string content = partitionContent.ToString();
using (HttpClient httpclient = new HttpClient())
{
httpclient.Timeout = TimeSpan.FromMinutes(10);
StringContent scontent = new StringContent(JsonConvert.SerializeObject(new QAModel() { ChatModelId = StepName, Context = content }), Encoding.UTF8, "application/json");
HttpResponseMessage response = await httpclient.PostAsync("http://localhost:5000/api/KMS/QA", scontent);
List<string> qaList = JsonConvert.DeserializeObject<List<string>>( await response.Content.ReadAsStringAsync());
sentences = qaList;
partitions = qaList;
}
break;
}
default:
this._log.LogWarning("File {0} cannot be partitioned, type '{1}' not supported", file.Name, file.MimeType);
// Don't partition other files
continue;
}
if (partitions.Count == 0) { continue; }
this._log.LogDebug("Saving {0} file partitions", partitions.Count);
for (int partitionNumber = 0; partitionNumber < partitions.Count; partitionNumber++)
{
// TODO: turn partitions in objects with more details, e.g. page number
string text = partitions[partitionNumber];
int sectionNumber = 0; // TODO: use this to store the page number (if any)
BinaryData textData = new(text);
int tokenCount = this._tokenCounter(text);
this._log.LogDebug("Partition size: {0} tokens", tokenCount);
var destFile = uploadedFile.GetPartitionFileName(partitionNumber);
await this._orchestrator.WriteFileAsync(pipeline, destFile, textData, cancellationToken).ConfigureAwait(false);
var destFileDetails = new DataPipeline.GeneratedFileDetails
{
Id = Guid.NewGuid().ToString("N"),
ParentId = uploadedFile.Id,
Name = destFile,
Size = text.Length,
MimeType = MimeTypes.PlainText,
ArtifactType = DataPipeline.ArtifactTypes.TextPartition,
PartitionNumber = partitionNumber,
SectionNumber = sectionNumber,
Tags = pipeline.Tags,
ContentSHA256 = textData.CalculateSHA256(),
};
newFiles.Add(destFile, destFileDetails);
destFileDetails.MarkProcessedBy(this);
}
file.MarkProcessedBy(this);
}
// Add new files to pipeline status
foreach (var file in newFiles)
{
uploadedFile.GeneratedFiles.Add(file.Key, file.Value);
}
}
return (true, pipeline);
}
}在这里我遇到了一个问题,就是我无法再这个QAHandle中使用依赖注入,这个生命周期与我应用程序的不同,这个后面再看如何解决,我们先使用一个变通的方式,来调用本地的API接口进行 QA问答切片,。
其实在qahandle中我们主要修改的是:
httpclient.Timeout = TimeSpan.FromMinutes(10);
StringContent scontent = new StringContent(JsonConvert.SerializeObject(new QAModel() { ChatModelId = StepName, Context = content }), Encoding.UTF8, "application/json");
HttpResponseMessage response = await httpclient.PostAsync("http://localhost:5000/api/KMS/QA", scontent);
List<string> qaList = JsonConvert.DeserializeObject<List<string>>( await response.Content.ReadAsStringAsync());
sentences = qaList;
partitions = qaList;QA问答切片的实现
在自定义的QAHandler中,我们通过调用本地API接口进行QA问答切片。这个API接口会接收文本内容,并返回一个包含问答对的列表。我们可以通过正则表达式解析这个列表,并生成对应的切片。
var kernel = _kernelService.GetKernelByAIModelID(model.ChatModelId);
varlines = TextChunker.SplitPlainTextLines(model.Context, 299);
varparagraphs = TextChunker.SplitPlainTextParagraphs(lines, 4000);
KernelFunction jsonFun = kernel.Plugins.GetFunction("KMSPlugin", "QA");
List<string> qaList = newList<string>();
foreach(var para in paragraphs)
{
var qaresult = await kernel.InvokeAsync(function: jsonFun, new KernelArguments() { ["input"] = para });
var qaListStr = qaresult.GetValue<string>().ConvertToString();
string pattern = @"Q\d+:.*?A\d+:.*?(?=(Q\d+:|$))";
RegexOptions options = RegexOptions.Singleline;
foreach (Match match in Regex.Matches(qaListStr, pattern, options))
{
qaList.Add(match.Value.Trim()); // Trim用于删除可能的首尾空格
}
}下面我们来看一看切片的提示词:
我会给你一段文本,学习它们,并整理学习成果,要求为:
1. 提出最多 25 个问题。
2. 给出每个问题的答案。
3. 答案要详细完整,答案可以包含普通文字、链接、代码、表格、公示、媒体链接等 markdown 元素。
4. 按格式返回多个问题和答案:
Q1: 问题。
A1: 答案。
Q2:
A2:生成QA切片的步骤
-
文本准备:首先,我们需要准备一段文本,这段文本将作为大模型的输入。
-
生成QA对:接着,我们通过大模型返回Q1 A1这样的问答形式。
-
正则解析:然后,我们使用正则表达式解析问答对,并生成对应的列表。
-
切片生成:最后,每个QA对应一个切片,这些切片可以在KM导入文档时使用。
使用自定义流程导入文档
_memory.Orchestrator.AddHandler<TextExtractionHandler>("extract_text");
_memory.Orchestrator.AddHandler<QAHandler>("antsk_qa");
_memory.Orchestrator.AddHandler<GenerateEmbeddingsHandler>("generate_embeddings");
_memory.Orchestrator.AddHandler<SaveRecordsHandler>("save_memory_records");这里我们创建好流程后,进行导入
var importResult = _memory.ImportDocumentAsync(new Document(fileid)
.AddFile(req.FilePath)
.AddTag(KmsConstantcs.KmsIdTag, req.KmsId)
,index: KmsConstantcs.KmsIndex , steps: new[]
{
"extract_text",
"antsk_qa",
"generate_embeddings",
"save_memory_records"
}).Result;实战应用:QA问答切片的效果测试
为了验证QA问答切片的效果,我们需要进行一系列的测试。这些测试应该包括不同类型的文档和各种场景,以便我们能够全面评估这种方法的优缺点。
测试步骤
-
选择文档:选择不同类型和长度的文档进行测试。
-
应用QA切片:对选定的文档应用QA问答切片方法。
-
效果评估:评估切片后的效果,包括问答的准确性、内容的完整性等。
-
对比分析:将QA切片的效果与传统的基于token数量的切片方法进行对比。
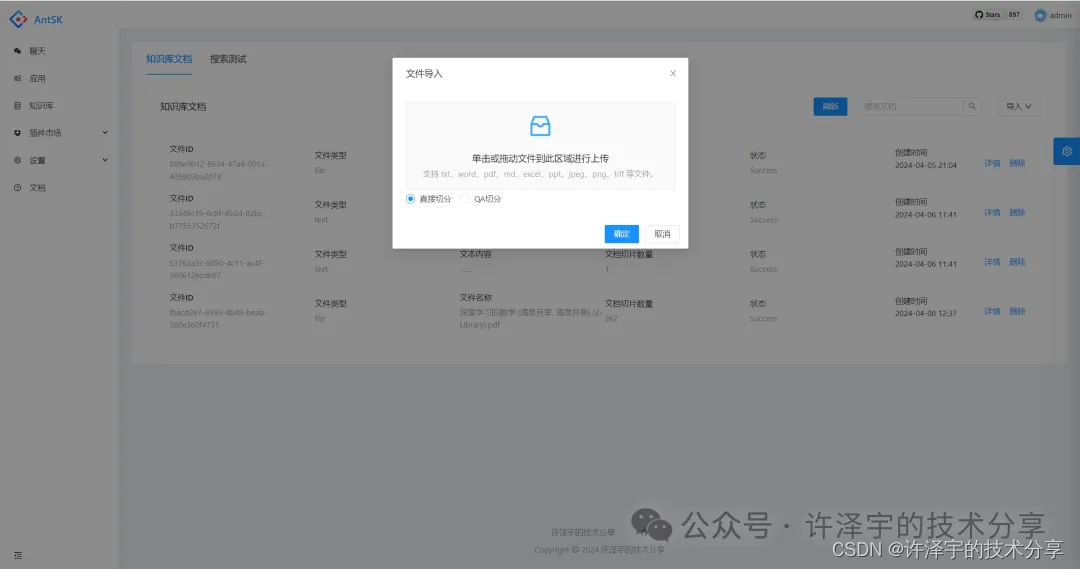
https://github.com/AIDotNet/AntSK结论
通过本文的深入分析和实战应用,我们可以看到,利用KernelMemory进行QA问答切片是一种有前景的方法。它能够根据内容生成更精准的切片,从而提高问答系统的效果。当然,这种方法并不一定适用于所有场景,具体效果还需要根据文档内容和需求场景进行测试和调整。希望本文能为.NET/AI方向的技术爱好者提供有价值的参考和启示。
另外也欢迎大家关注我的公众号<许泽宇的技术分享>,发送“进群” 加入我们的AIDotNet交流社区
附录:QA切片示例 (有LLM 理解后生成的QA)
Q1: KernelMemory是什么? A1: KernelMemory是一个强大的工具,它支持自定义编排,允许我们根据内容生成QA问答,而不是仅仅基于token数量进行切片。它提供了文档处理的全流程支持,包括文档解析、文档切片、向量处理、总结和保存向量等。
Q2: 如何自定义QA处理器? A2: 自定义QA处理器需要继承IPipelineStepHandler接口,并实现InvokeAsync方法。在这个方法中,我们可以通过调用本地API接口进行QA问答切片,从而生成更精准的文档切片。
Q3: QA问答切片的优势是什么? A3: QA问答切片的优势在于它能够根据内容生成更精准的切片,避免核心内容被切割到不同的段落。这种方法可以提高问答系统的效果,特别是在处理复杂文档时。
Q4: 如何进行QA问答切片的效果测试? A4: 进行QA问答切片的效果测试需要选择不同类型和长度的文档进行测试,应用QA问答切片方法,并评估切片后的效果,包括问答的准确性、内容的完整性等。最后,将QA切片的效果与传统的基于token数量的切片方法进行对比分析。
Q5: 什么是提示词? A5: 提示词是给大模型的输入,用于生成QA问答切片。例如,"{{$input}}"就是一个示例提示词,它告诉大模型返回Q1 A1这样的问答形式。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









