







 模型融合是通过整合多个模型的预测结果以提高整体预测准确性的方法。常见的融合策略包括模型平均、加权平均、Bagging、Boosting和Stacking。文中以糖尿病预测为例,展示了如何使用VotingClassifier进行模型融合,并比较了Bagging(如随机森林)、Boosting(如AdaBoost)的性能差异。
模型融合是通过整合多个模型的预测结果以提高整体预测准确性的方法。常见的融合策略包括模型平均、加权平均、Bagging、Boosting和Stacking。文中以糖尿病预测为例,展示了如何使用VotingClassifier进行模型融合,并比较了Bagging(如随机森林)、Boosting(如AdaBoost)的性能差异。
一、模型融合的定义
模型融合的思想是通过整合多个预测模型的预测结果来提高总体预测精度。
模型融合的潜在原理是不同的模型在不同的数据分布或特征上优势有所区别。通过结合这些模型,可以在整个数据集上实现更全面、更稳健的性能。然而,模型融合并不总是能提高预测性能。例如,如果所有模型都对同一类错误特别敏感,那么融合它们可能并不会带来太大改善。相反,如果每个模型都在不同的地方表现出优势,那么模型融合就更可能成功。
模型融合也增加了模型的复杂性,可能需要更多的计算资源和时间。
二、模型融合常见的方法
模型平均:将所有模型的预测结果求平均。如果所有模型的性能相近,那么这是一个不错的选择。然而,如果某些模型的性能比其他模型好得多,那么模型平均可能就不是最佳选择了。
加权平均:将每个模型的预测结果按照一定的权重进行平均。权重可以根据每个模型的性能来确定。
Bagging:Bagging通过从原始数据集中抽取多个样本子集(有放回),在每个子集上训练一个新的模型,然后将这些模型的预测结果进行平均或投票。Bagging可以有效地减小模型的方差,提高预测的稳定性。这是一种用于处理高方差模型的技术。
Boosting:Boosting是一个序列过程,每一步都在试图改正前一步的预测错误。常见的Boosting算法有AdaBoost和梯度提升。Boosting可以有效地减小模型的偏差,提高预测的准确性。这是一种用于处理高偏差模型的技术。
Stacking:Stacking是一种比前面几种方法更复杂的模型融合技术。它首先训练多个不同的模型,然后用这些模型的预测结果作为新的特征,训练一个新的模型(称为元学习器或者二级学习器)来进行最终的预测。这样可以有效地整合每个模型的优点,从而可能得到更好的预测性能。
三、模型融合案例
import pandas as pd
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier #投票机制
import warnings
warnings.filterwarnings('ignore')
data = "PimaIndiansdiabetes.csv"
#皮马人的医疗记录,数据集的目标是基于数据集中包含的某些诊断测量来诊断性的预测患者是否患有糖尿病。
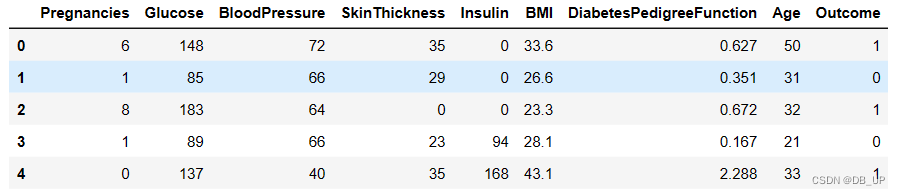
df = pd.read_csv(data,header=0)
df.head()
# 【1】Pregnancies:怀孕次数
# 【2】Glucose:葡萄糖
# 【3】BloodPressure:血压 (mm Hg)
# 【4】SkinThickness:皮层厚度 (mm)
# 【5】Insulin:胰岛素 2小时血清胰岛素(mu U / ml
# 【6】BMI:体重指数 (体重/身高)^2
# 【7】DiabetesPedigreeFunction:糖尿病谱系功能
# 【8】Age:年龄 (岁)
# 【9】Outcome:类标变量 (0或1)
array = df.values
X = array[:,0:8]
Y = array[:,8]
kfold = model_selection.KFold(n_splits=5,shuffle=True)
# 创建投票器的子模型
estimators = []
model_1 = LogisticRegression()
estimators.append(('logistic', model_1))
model_2 = DecisionTreeClassifier()
estimators.append(('dt', model_2))
model_3 = SVC()
estimators.append(('svm', model_3))
# 构建投票器融合
ensemble = VotingClassifier(estimators) #默认硬投票
#ensemble = VotingClassifier(estimators=[('lg',model_1g),('dt',model_dt),('svc',model_svm)],voting='soft',weights=[2,1,1]) #软投票,将所有模型预测样本为某一类别的概率的平均值作为标准,概率最高的对应的类型为最终的预测结果
result = model_selection.cross_val_score(ensemble,X,Y,cv=kfold) #kfold=5,输出5种结果
print(result.mean())
0.7696120872
3.1、 Bagging
from sklearn.ensemble import BaggingClassifier
dt = DecisionTreeClassifier()
num = 100
kfold = model_selection.KFold(n_splits=5)
model = BaggingClassifier(base_estimator=dt, n_estimators=num)
result = model_selection.cross_val_score(model,X,Y,cv=kfold)
print(result.mean())
0.7644003055767
3.2、RandomForest
from sklearn.ensemble import RandomForestClassifier
num_trees = 100
max_feature_num = 5
kfold = model_selection.KFold(n_splits=5)
model = RandomForestClassifier(n_estimators=num_trees,max_features=max_feature_num)
result = model_selection.cross_val_score(model,X,Y,cv=kfold)
print(result.mean())
0.7669722434428318
3.3、Adaboost
from sklearn.ensemble import AdaBoostClassifier
num_trees = 25
kfold = model_selection.KFold(n_splits=5)
model = AdaBoostClassifier(n_estimators=num_trees)
result = model_selection.cross_val_score(model, X, Y, cv=kfold)
print(result.mean())
0.75136236312706


















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









